一、技术解读:潜在扩散模型------高分辨率图像合成的范式革命
1.1 核心动机:破解"质量-效率-可控性"的不可能三角
在潜在扩散模型(Latent Diffusion Models, LDMs)出现之前,高分辨率图像生成领域长期存在一个"不可能三角":生成质量、计算效率、可控性难以兼得。
- GANs:能快速生成高质量图像,但训练极其不稳定,易出现模式崩溃(多样性差),且实现复杂条件的可控生成需要为不同任务设计特定架构,工程化成本极高。
- VAEs :训练稳定、架构简单,但其优化目标过度依赖像素级损失+强正则化,导致生成图像模糊、细节丢失严重,无法满足高保真生成需求。
- 像素空间扩散模型(DMs) :生成质量顶尖,并支持无需重新训练的灵活引导(如修复、上色、超分),但其在百万维度的像素空间中直接进行迭代去噪,导致训练成本 (通常需数百个GPU天)和推理成本(生成一张图需数分钟)高昂,仅能在超算中心或大厂落地,难以向研究界和普通开发者普及。
LDMs的破局思路 堪称"四两拨千斤":将复杂的图像生成任务"分而治之",做专业的事交给专业的模块 。其核心洞察是,图像的信息构成存在明显分层:一层是人类视觉难以察觉、模型建模却耗时的像素级冗余细节 (如微小的纹理噪点、像素级的色彩波动);另一层是决定图像核心内容的语义概念信息(如物体的形状、布局、类别、场景逻辑)。让一个单一模型在超高维像素空间里同时学习这两类信息,是效率低下的根本原因。
LDMs的核心创新在于将图像生成过程解耦为两个高度专门化、可独立优化的阶段:
- 感知压缩阶段 :训练一个强大的专用自编码器 ,专门负责将高维像素图像高效压缩为低维潜在表示 。这个表示就像一份高压缩比、高保真的"数字底片",在人类视觉感知上与原始图像完全等效,但数据量骤降,计算友好性大幅提升。
- 生成学习阶段 :在低维潜在空间中训练一个专用扩散模型,让其彻底摆脱像素级冗余细节的建模负担,专注于学习图像的语义概念分布和内容生成。
通过这种模块化分工与空间迁移 ,LDMs首次在不牺牲生成质量和多样性的前提下 ,实现了计算效率的数量级提升 ,并因其架构设计天然支持强大的多模态可控性,一举破解了高分辨率图像生成的"不可能三角"。
1.2 核心技术架构解析
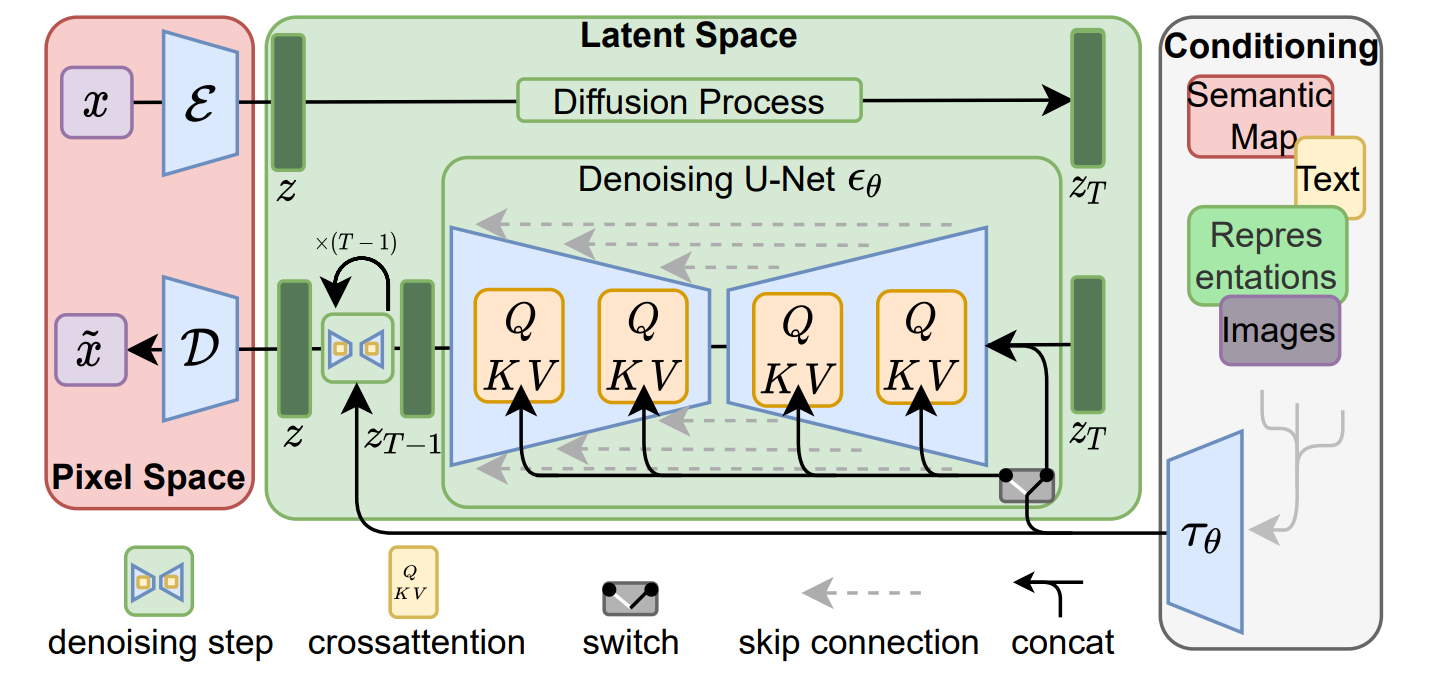
1.2.1 感知压缩:构建高质量的"数字底片"仓库
LDMs的第一阶段是一个经过极致优化的自编码器 ,其核心目标不是简单的图像压缩,而是学习一个与像素空间感知等效、适合生成任务的低维潜在空间,本质是打造一个高质量的"数字底片"仓库。
给定一张RGB像素图像 x∈RH×W×3x \in \mathbb{R}^{H \times W \times 3}x∈RH×W×3,编码器 E\mathcal{E}E 会通过卷积下采样将其编码为潜在表示 z=E(x)∈Rh×w×cz = \mathcal{E}(x) \in \mathbb{R}^{h \times w \times c}z=E(x)∈Rh×w×c,其中下采样因子 f=H/h=W/wf = H/h = W/wf=H/h=W/w 是平衡效率与质量的核心超参数(通常为 f=2mf=2^mf=2m, m∈Nm \in \mathbb{N}m∈N);解码器 D\mathcal{D}D 则通过转置卷积上采样,从潜在表示 zzz 中重建出与原图感知一致的图像 x~=D(z)≈x\tilde{x} = \mathcal{D}(z) \approx xx~=D(z)≈x。
关键设计与核心优势(对比VAE/VQGAN/传统压缩):
-
超越像素的感知重建目标:告别模糊,保留细节
传统VAE的损失函数 LVAE=∥x−D(E(x))∥22+β⋅KL(q(z∣x)∥p(z))L_{VAE} = \| x - D(E(x)) \|_2^2 + \beta \cdot KL( q(z|x) \| p(z) )LVAE=∥x−D(E(x))∥22+β⋅KL(q(z∣x)∥p(z)) 存在两大致命问题:一是像素级MSE损失 会平均化像素值,导致图像过度平滑、细节丢失;二是强KL正则化强制潜在空间服从标准正态分布,牺牲了图像的特征表达能力。
LDMs的自编码器采用复合损失函数 ,彻底摒弃了"像素级一致"的误区,转而追求视觉感知一致 ,让重建图像既保语义又保细节:
LAutoencoder=Lrecon(e.g.,L1)+λganLgan+λLPIPSLLPIPSL_{Autoencoder} = L_{recon} (e.g., L1) + \lambda_{gan} L_{gan} + \lambda_{LPIPS} L_{LPIPS}LAutoencoder=Lrecon(e.g.,L1)+λganLgan+λLPIPSLLPIPS- 基础重建损失(L1L1L1):仅作为基础约束,避免重建图像与原图出现大幅偏差,比MSE更能保留图像的边缘和细节。
- 感知损失(LLPIPSL_{LPIPS}LLPIPS) :利用预训练VGG网络提取图像的高层语义特征,比较重建图与原图在特征空间的差异,而非像素空间。这迫使模型优先保留对人类视觉最重要的语义、结构、光影信息,而非无意义的像素波动。
- 基于Patch的对抗损失(LganL_{gan}Lgan) :采用PatchGAN判别器,仅判断图像局部小区域(Patch)的真伪,而非整张图。这比传统GAN的全局判别更稳定,能有效促进局部细节的真实感(如毛发、纹理、光影),同时避免模式崩溃。
- 通俗类比:VAE像是"照着描红",只求像素轮廓的大致匹配,画出来的图呆板模糊;LDMs的自编码器如同"专业画家写生",既保物体的轮廓形似,更求光影、纹理的神似,还原的图像鲜活且细节丰富。
-
下采样因子 fff 的黄金选择:效率与质量的最优平衡
下采样因子 fff 直接决定了潜在空间的维度和细节保留能力,LDMs通过大量系统实验发现,f=4f=4f=4 或 888 是高分辨率生成的黄金值,这一选择远优于同期的VQGAN等模型:
- VQGAN为了适配自回归Transformer的序列建模,采用激进压缩 (f=16f=16f=16甚至323232),导致潜在空间丢失大量细节,生成图像存在明显的"块效应";
- LDMs的F=4/8F=4/8F=4/8属于温和压缩 ,既将数据量降至原来的1/161/161/16或1/641/641/64(如512×512512\times512512×512的图像压缩为128×128128\times128128×128或64×6464\times6464×64),实现计算效率的大幅提升,又能在潜在空间中保留生成百万像素级高保真图像所需的足够细节。
- 任务适配性 :f=4f=4f=4更适合超分辨率、图像修复等需要精细细节的任务,f=8f=8f=8更适合文生图、无条件生成等追求效率和多样性的任务,兼顾不同场景需求。
-
灵活的轻量正则化策略:适配不同生成需求
为避免潜在空间方差过大、特征分布混乱,导致后续扩散模型难以训练,LDMs设计了两种轻量正则化方案,而非VAE的强KL正则化,既保证潜在空间的平滑性,又不损失特征表达能力:
- KL正则化(KL-reg.) :对潜在表示施加轻微的KL惩罚,使其近似服从标准正态分布,惩罚强度远低于VAE。优势是潜在空间更平滑、连续性更好,能生成更多样的结果,适合文本到图像、布局到图像等需要丰富多样性的多模态任务。
- 向量量化正则化(VQ-reg.) :在解码器输入端引入向量量化层,将连续的潜在表示离散化为有限个预训练向量的组合。优势是生成结果更稳定、可控性更强,适合无条件图像生成、图像修复等对稳定性要求高的任务。
- 核心创新 :不同于VQ-VAE将量化层置于编码器后(导致编码阶段就丢失信息,形成信息瓶颈),LDMs将量化层放在解码器,让编码器尽可能保留图像特征,实现了离散化表示 与高细节保留的兼顾。
-
通用可复用性:一次训练,全场景适配
该自编码器是任务无关的通用模块,训练好后可作为独立的"图像编解码工具",服务于多个扩散模型的训练(如文生图、图生图、超分、修复可复用同一个自编码器),也可用于其他下游计算机视觉任务(如CLIP引导的图像编辑、图像检索)。这种"一次训练,多次复用"的特性,大幅降低了研发成本,是LDMs能快速落地的重要原因。
1.2.2 潜在扩散:在"精装小户型"里高效"创作"
这是LDMs的灵魂核心,也是其区别于传统像素级扩散模型的根本。其核心思想是将扩散模型的强大生成能力,从"毛坯大平层"的像素空间,搬迁到"精装小户型"的潜在空间中------空间更小、计算更高效,且无需操心"装修细节"(像素级冗余),可专注于"内容创作"(语义生成)。
传统像素级扩散模型的核心损失函数为:
LDM=Ex,ϵ∼N(0,1),t∥ϵ−ϵθ(xt,t)∥22L_{DM} = \mathbb{E}_{x, \epsilon \sim \mathcal{N}(0,1), t} \left \\\| \\epsilon - \\epsilon_{\\theta}(x_t, t) \\\|_{2}\^{2} \\rightLDM=Ex,ϵ∼N(0,1),t∥ϵ−ϵθ(xt,t)∥22
其中xtx_txt是原始像素图像xxx在扩散第ttt步的加噪版本,ϵθ\epsilon_{\theta}ϵθ是去噪U-Net,目标是精准预测添加的噪声ϵ\epsilonϵ。
LDMs将这一核心逻辑无缝迁移 至低维潜在空间,损失函数仅做操作对象的替换 ,无任何结构修改:
LLDM=EE(x),ϵ∼N(0,1),t∥ϵ−ϵθ(zt,t)∥22L_{LDM} = \mathbb{E}_{\mathcal{E}(x), \epsilon \sim \mathcal{N}(0,1), t} \left \\\| \\epsilon - \\epsilon_{\\theta}(z_t, t) \\\|_{2}\^{2} \\rightLLDM=EE(x),ϵ∼N(0,1),t∥ϵ−ϵθ(zt,t)∥22
公式深度解读与核心优势:
- z=E(x)z = \mathcal{E}(x)z=E(x) 是第一阶段得到的"数字底片",ztz_tzt 是zzz在扩散过程第ttt步的加噪版本,扩散的前向加噪、反向去噪过程与像素空间完全一致;
- 两个公式在数学形式上完全一致,意味着LDMs可直接复用传统扩散模型的训练框架、优化策略和采样方法,无需重新设计复杂算法,降低了研发和落地成本;
- 核心质变 :操作空间的维度发生了天翻地覆的变化 。在f=8f=8f=8时,zzz的维度仅为xxx的1/641/641/64,这意味着去噪U-Netϵθ\epsilon_{\theta}ϵθ需要处理的数据量急剧减少,带来训练速度和采样速度的数量级提升 (训练成本降至原来的1/101/101/10甚至1/1001/1001/100,采样速度提升数倍)。
对比GAN/VAE/传统扩散的核心优势:
- 对比GAN :扩散模型通过逐步去噪 学习数据的真实分布,本质是基于似然的模型,能更全面地覆盖数据分布,从根源上避免了GAN的模式崩溃、训练不稳定问题,生成的图像多样性和语义一致性更优;
- 对比VAE :VAE的生成能力依赖解码器的简单上采样,表达能力有限;而LDMs的扩散模型是强大的深度生成模型,能在潜在空间中学习到更复杂的语义分布,生成的图像细节、质感远优于VAE;
- 对比传统像素扩散 :在生成质量基本持平甚至更优 的前提下,实现了训练和推理效率的数量级提升,让扩散模型从"大厂专属"走向"全民可用"。
关键实现细节:让高效生成更落地:
-
神经骨干:时间条件化U-Net------适配空间结构的最优选择
采用卷积神经网络U-Net 作为去噪骨干,而非自回归Transformer,这是LDMs针对图像生成的精准设计 :U-Net的固有归纳偏置 使其对图像的二维空间结构具有天然的契合度,通过下采样提取语义特征+上采样还原空间细节+跳跃连接保留局部信息,能高效建模图像的空间关联;而Transformer将图像视为一维序列,丢失了空间结构信息,计算成本更高。
同时,U-Net引入时间步嵌入(Time Embedding) :将扩散步数ttt通过正弦余弦编码转化为高维向量,融入U-Net的每一层,让模型能精准知晓当前的去噪进度,从而动态调整去噪策略(如前期去粗噪、后期去细噪),提升去噪精度。
-
高效采样流程:两步走,把耗时操作留在低维空间
LDMs的采样过程分为两个步骤,将最耗时的迭代去噪放在低维潜在空间,解码器仅需一次前向传播,实现了效率的质的飞跃:
- 潜在空间迭代去噪 :从标准正态分布的噪声zTz_TzT开始,利用训练好的ϵθ\epsilon_{\theta}ϵθ逐步预测并减去噪声,经过TTT步后得到干净的潜在表示z0z_0z0。此过程在低维空间进行,每一步的计算量极小,即使是1000步迭代,耗时也远低于像素空间的10步迭代。
- 解码器一步重建 :使用第一阶段训练好的解码器D\mathcal{D}D,将干净的潜在表示z0z_0z0单次前向传播即可解码为高清像素图像。解码器的上采样是纯卷积操作,速度极快。
- 进阶优化 :结合DDIM、PLMS等快速采样策略 ,可将去噪步数从1000步降至20/50步,采样速度进一步提升,让LDMs能实现近实时生成,这也是Stable Diffusion能在普通显卡上运行的关键。
1.2.3 条件机制:用"多模态蓝图"精准控制生成
为实现文生图、图生图、语义图到图像等复杂的可控生成任务,LDMs引入了基于交叉注意力(Cross-Attention) 的通用条件机制,这是其对比前代模型(GAN/VAE/传统扩散)的又一巨大飞跃,也是Stable Diffusion能支持多模态可控生成的核心原因。
条件化的核心目标函数 :
LLDM=EE(x),y,ϵ∼N(0,I),t∥ϵ−ϵθ(zt,t,τθ(y))∥22L_{LDM} = \mathbb{E}_{\mathcal{E}(x), y, \epsilon \sim \mathcal{N}(0,I), t} \left \\\| \\epsilon - \\epsilon_{\\theta}(z_t, t, \\tau_{\\theta}(y)) \\\|_2\^2 \\rightLLDM=EE(x),y,ϵ∼N(0,I),t∥ϵ−ϵθ(zt,t,τθ(y))∥22
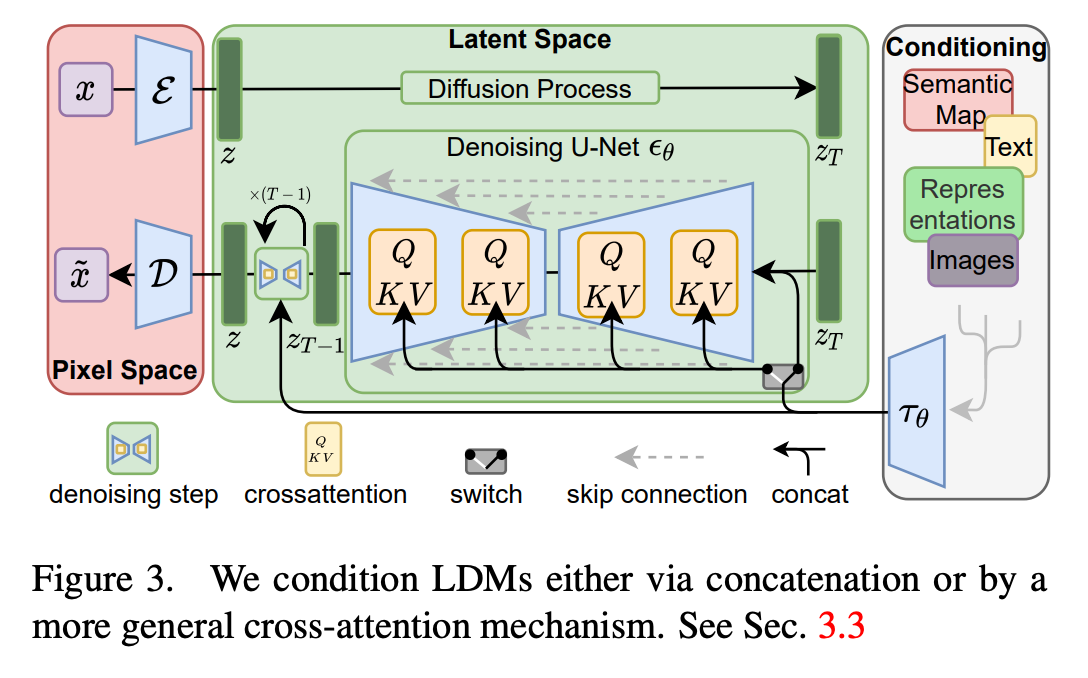
其中yyy是任意模态的条件信息(如文本提示、语义图、深度图、边缘图),τθ\tau_{\theta}τθ是领域特定编码器 (如文本用CLIP文本编码器、语义图用卷积编码器),其作用是将不同模态的条件信息映射为统一维度的中间表示 τθ(y)∈RM×dτ\tau_{\theta}(y) \in \mathbb{R}^{M \times d_{\tau}}τθ(y)∈RM×dτ,实现多模态输入的"标准化";随后,该中间表示通过交叉注意力层注入到U-Net的各个层级,实现条件信息与图像特征的深度融合。
交叉注意力机制详解:让模型"看懂蓝图,精准创作"
交叉注意力的核心公式为:
Attention(Q,K,V)=softmax(QKTd)⋅V\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d}}\right) \cdot VAttention(Q,K,V)=softmax(d QKT)⋅V
在LDMs的上下文里,该公式的每个组件都有明确的物理意义,本质是让模型根据条件信息,为图像的每个位置精准分配生成依据:
- Q=WQ(i)⋅φi(zt)Q = W_Q^{(i)} \cdot \varphi_i(z_t)Q=WQ(i)⋅φi(zt):查询(Query)向量 ,由U-Net第iii层的潜在特征φi(zt)\varphi_i(z_t)φi(zt)通过可学习投影矩阵WQ(i)W_Q^{(i)}WQ(i)映射而来,维度为RN×d\mathbb{R}^{N \times d}RN×d。NNN是潜在特征的空间位置数,ddd是注意力维度。QQQ的核心含义是:图像的这个位置,需要什么样的生成信息?
- K=WK(i)⋅τθ(y)K = W_K^{(i)} \cdot \tau_{\theta}(y)K=WK(i)⋅τθ(y), V=WV(i)⋅τθ(y)V = W_V^{(i)} \cdot \tau_{\theta}(y)V=WV(i)⋅τθ(y):键(Key)和值(Value)向量 ,均由编码后的条件信息τθ(y)\tau_{\theta}(y)τθ(y)通过可学习投影矩阵WK(i)W_K^{(i)}WK(i)/WV(i)W_V^{(i)}WV(i)映射而来,维度均为RM×d\mathbb{R}^{M \times d}RM×d。MMM是条件信息的单元数(如文本的单词数、语义图的类别数)。KKK的核心含义是:条件信息提供了哪些生成依据? VVV的核心含义是:每个生成依据对应的具体细节特征是什么?
交叉注意力的工作流程:从"蓝图"到"作品"的精准映射
交叉注意力层并非简单的特征拼接,而是特征级的深度融合,让条件信息能精准引导图像的每个位置生成,工作流程可分为四步,每一步都有明确的物理意义:
- 相关性计算(QKT/dQK^T/\sqrt{d}QKT/d ) :计算图像每个位置的查询向量QQQ与条件信息每个单元的键向量KKK的点积,并除以d\sqrt{d}d 做维度缩放,得到相关性矩阵 RN×M\mathbb{R}^{N \times M}RN×M。该矩阵的每个元素代表:图像的第nnn个位置,与条件信息的第mmm个单元的相关程度。比如文生图中,图像的"猫"区域与提示词中的"猫"单词相关性会趋近于1,与"狗"单词相关性趋近于0。
- 注意力权重归一化(softmax) :对相关性矩阵做softmax归一化,得到注意力权重图 RN×M\mathbb{R}^{N \times M}RN×M,权重值在0~1之间,且每行之和为1。该权重图清晰地指示了:生成图像的第nnn个位置时,模型应该重点关注条件信息的哪些单元。比如文生图中,生成猫的头部时,模型会将90%以上的注意力分配给提示词中的"猫""头部"等单词。
- 条件特征融合(⋅V\cdot V⋅V) :将注意力权重图与条件信息的值向量VVV做矩阵乘法,得到条件化的图像特征向量 RN×d\mathbb{R}^{N \times d}RN×d。该向量的核心含义是:根据条件信息,图像的第nnn个位置应该生成的具体特征。比如文生图中,该向量会融合"猫的头部是白色的、有蓝色眼睛"等细节信息。
- 引导去噪生成 :将条件化的图像特征向量送回到U-Net的解码器层,与原始的潜在特征融合,精准引导该层的去噪过程 。通过在U-Net的多个层级(浅层、中层、深层)插入交叉注意力层,实现对图像生成的全流程引导。
交叉注意力的层级设计:分层引导,兼顾布局与细节
LDMs在U-Net的浅层、中层、深层 分别插入交叉注意力层,不同层级的引导侧重点不同,实现了布局+语义+细节的全维度精准引导,这是其可控性远超前代模型的关键:
- 浅层交叉注意力 :对应图像的低维特征 ,主要关注图像的空间布局、轮廓、边缘。比如文生图中,浅层会引导"猫在沙发上"的空间位置关系,让猫出现在沙发上,而非地板上。
- 中层交叉注意力 :对应图像的中维特征 ,主要关注图像的语义类别、物体形状。比如文生图中,中层会引导"猫是布偶猫、沙发是真皮沙发"的物体类别和形状特征。
- 深层交叉注意力 :对应图像的高维特征 ,主要关注图像的细节纹理、光影色彩。比如文生图中,深层会引导"猫的毛发是蓬松的、沙发是米白色的、光影从左侧照来"的细节特征。
通用条件机制的核心威力:一个架构,适配所有模态
该条件机制为LDMs提供了一个万能的多模态接口,具有两大核心优势,使其远超GAN/VAE的条件生成能力:
- 模态无关性 :无论条件信息是文本、语义图、深度图、边缘图、布局框,只需为其设计一个简单的领域特定编码器τθ\tau_{\theta}τθ,将其映射为统一维度的中间表示,即可接入LDMs的生成流程,无需像GAN那样为每种条件设计不同的生成器/判别器架构,工程化成本极低。
- 端到端联合优化 :领域特定编码器τθ\tau_{\theta}τθ与去噪U-Netϵθ\epsilon_{\theta}ϵθ通过上述损失函数端到端联合训练,让条件信息与图像特征的融合更紧密,引导更精准,生成的图像与条件信息的一致性远高于传统的"特征拼接"方式。
这一设计的灵活性和强大性能,是Stable Diffusion能快速衍生出文生图、图生图、超分、修复、控图(OpenPose/Depth/Inpaint)等众多功能的核心原因,也是其能风靡全球的关键。
1.3 核心创新与技术价值:扩散模型的平民化与产业化
LDMs并非对扩散模型的简单修改,而是对高分辨率图像生成范式的重构 ,其核心创新并非单一技术点,而是模块化设计、空间迁移、通用条件机制的有机结合,带来了一系列里程碑式的技术价值,直接推动了扩散模型从"学术研究"走向"工业落地"和"全民可用":
- 首次实现扩散模型的效率革命 :通过将扩散模型迁移至潜在空间,在不牺牲生成质量的前提下,将训练和推理成本降至原来的1/10甚至1/100,让扩散模型能在普通消费级显卡(如RTX 3060/4090)上训练和运行,实现了扩散模型的平民化。
- 破解了图像生成的不可能三角 :首次在高分辨率图像生成中,同时实现了高生成质量、高计算效率、强多模态可控性,解决了GAN/VAE/传统扩散各自的致命缺陷,成为新一代图像生成的基准范式。
- 模块化设计的工程化价值:将图像生成解耦为感知压缩和生成学习两个独立模块,每个模块可独立优化、一次训练、多次复用,大幅降低了研发和落地成本,让开发者能快速基于预训练的自编码器,开发出不同场景的生成模型。
- 多模态可控生成的通用框架:基于交叉注意力的通用条件机制,为图像生成提供了一个模态无关的万能接口,适配文本、视觉、几何等所有模态的条件输入,成为后续所有扩散模型可控生成的标准设计。
1.4 客观局限性:技术的边界与未来方向
LDMs虽实现了图像生成的范式革命,但并非完美的技术,仍存在一些固有局限性,也为后续的研究指明了方向:
- 顺序采样仍有耗时 :尽管采样效率大幅提升,但扩散模型的顺序迭代去噪本质仍比GAN的"一步生成"耗时,即使结合快速采样策略,生成一张高清图仍需数秒,难以满足实时交互(如视频生成、游戏渲染)的需求。
- 生成质量受限于自编码器 :LDMs的生成质量存在天花板------由自编码器的重建质量决定。如果自编码器的重建图像存在细节丢失,扩散模型也无法生成超出其能力的细节。
- 高分辨率生成的显存限制:尽管潜在空间降低了计算量,但生成百万像素级(如2048×2048)的图像时,解码器的上采样仍会带来较大的显存消耗,需要依赖分层生成、拼图生成等策略。
- 条件引导的精准性仍有提升空间:文生图等任务中,模型仍可能出现"文字理解偏差""物体遗漏/多余""空间关系错误"等问题,如何提升模型对条件信息的理解能力,仍是后续的研究重点。
这些局限性也推动了后续的技术演进,如扩散模型的加速采样(DDIM/PLMS/DDPM-solver)、分层潜在扩散、高分辨率自编码器、大语言模型与扩散模型的融合(LLaMA/GLM+SD)等,让图像生成技术不断向更高效、更精准、更高清的方向发展。
最后需要明确的是,LDMs是理论基础,Stable Diffusion是LDMs的工业落地实现 :Stable Diffusion完全基于LDMs的核心架构,在其基础上做了一系列工程化优化(如模型轻量化、快速采样、多模态控图、开源生态建设),将LDMs的理论优势转化为可实际使用的产品,让普通用户能在消费级显卡上体验到高保真的多模态图像生成能力。没有LDMs的范式创新,就没有Stable Diffusion的诞生;而Stable Diffusion的开源和普及,又进一步推动了LDMs的研究和演进,形成了理论研究 与工业落地的良性循环。
二、论文翻译:High-Resolution Image Synthesis with Latent Diffusion Models (高分辨率图像合成与潜在扩散模型)
0 摘要
通过将图像形成过程分解为去噪自编码器的顺序应用,扩散模型(DMs)在图像数据及其他领域实现了最先进的合成结果。此外,它们的公式允许一种引导机制来控制图像生成过程而无需重新训练。然而,由于这些模型通常直接在像素空间操作,强大DMs的优化往往消耗数百个GPU天,且推理因顺序评估而昂贵。为了在有限计算资源上实现DM训练,同时保持其质量和灵活性,我们将其应用于强大预训练自编码器的潜在空间。与先前工作相比,在这种表示上训练扩散模型首次实现了复杂度降低和细节保留之间的近最优平衡,大大提升了视觉保真度。通过将交叉注意力层引入模型架构,我们将扩散模型转变为强大且灵活的生成器,用于一般条件输入(如文本或边界框),并以卷积方式实现高分辨率合成。我们的潜在扩散模型(LDMs)在图像修复和类条件图像合成上达到了新的最先进分数,并在各种任务(包括文本到图像合成、无条件图像生成和超分辨率)上表现出高度竞争力,同时与基于像素的DMs相比显著降低了计算需求。
1 引言
图像合成是计算机视觉领域中近期发展最为惊人的方向之一,但同时也是计算需求最大的领域之一。特别是复杂自然场景的高分辨率合成,目前主要依赖于扩大基于似然的模型,这些模型在自回归变换器中可能包含数十亿参数66, 67。相比之下,GANs3, 27, 40所展现出的有前景的结果已被揭示主要局限于变异性相对有限的数据,因为它们的对抗学习过程不易扩展到对复杂多模态分布进行建模。最近,由去噪自编码器层次结构构建的扩散模型82在图像合成30, 85及其他领域7, 45, 48, 57已显示出令人印象深刻的结果,并在类条件图像合成15, 31和超分辨率72方面定义了最先进的技术。此外,与其他类型的生成模型19, 46, 69不同,即使是无条件DMs也可以轻松应用于修复和着色85或基于笔画的合成53等任务。作为基于似然的模型,它们不会像GANs那样出现模式崩溃和训练不稳定性,并且通过大量利用参数共享,它们可以对自然图像的复杂分布进行建模,而无需像AR模型67那样涉及数十亿参数。
高分辨率图像合成的民主化
DMs属于基于似然的模型类别,其模式覆盖行为使它们倾向于花费过多的容量(以及计算资源)来建模数据中难以察觉的细节16, 73。尽管重新加权的变分目标30旨在通过欠采样初始去噪步骤来解决这个问题,但DMs仍然需要大量计算,因为训练和评估这样的模型需要在RGB图像的高维空间中进行重复的函数评估(和梯度计算)。例如,训练最强大的DMs通常需要数百个GPU天(例如,15中为150-1000个V100天),并且在输入空间的噪声版本上进行重复评估也使得推理成本高昂,因此在单个A100 GPU上产生5万个样本大约需要5天15。这对研究界和普通用户来说有两个后果:首先,训练这样的模型需要大量的计算资源,只有该领域的一小部分人能够获得,并且会留下巨大的碳足迹65, 86。其次,评估一个已经训练好的模型在时间和内存上也很昂贵,因为相同的模型架构必须顺序运行大量步骤(例如,15中为25-1000步)。
为了提高这个强大模型类别的可访问性,同时减少其显著的资源消耗,需要一种能够降低训练和采样计算复杂度的方法。因此,在不损害其性能的情况下降低DMs的计算需求是增强其可访问性的关键。
转向潜在空间
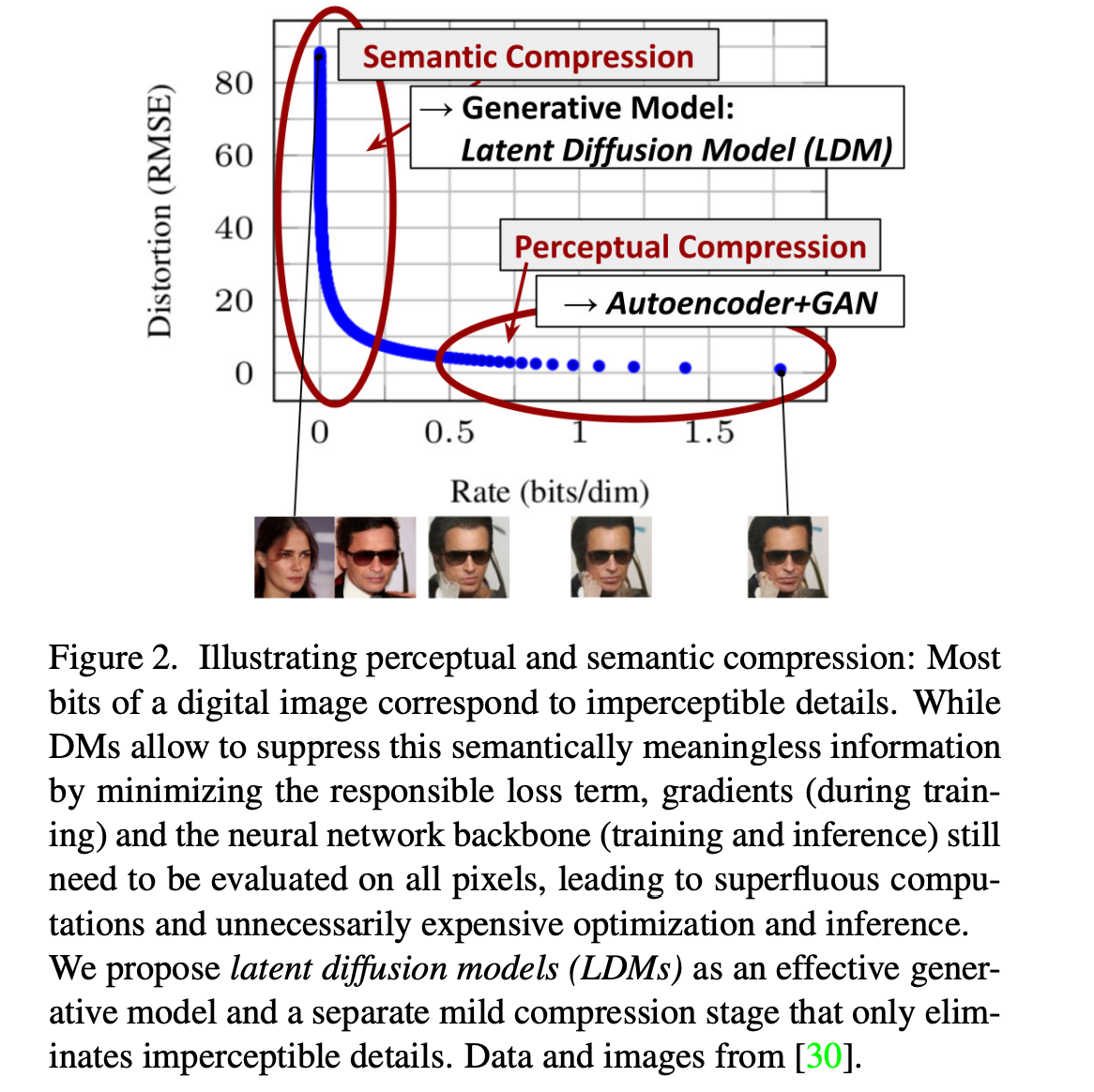
我们的方法始于分析像素空间中已训练的扩散模型:图2展示了一个已训练模型的率失真权衡。与任何基于似然的模型一样,学习可以大致分为两个阶段:首先是感知压缩阶段,该阶段去除高频细节,但仍学习很少的语义变化。在第二阶段,实际的生成模型学习数据的语义和概念构成(语义压缩)。因此,我们的目标是首先找到一个感知上等价但计算上更合适的空间,在该空间中我们将训练扩散模型以进行高分辨率图像合成。
遵循常见实践11, 23, 66, 67, 96,我们将训练分为两个不同的阶段:首先,我们训练一个自编码器,它提供一个较低维(因此更高效)的表示空间,该空间在感知上与数据空间等价。重要的是,与先前的工作23, 66相比,我们不需要依赖过度的空间压缩,因为我们在学习到的潜在空间中训练DMs,该空间在空间维度方面展现出更好的缩放特性。降低的复杂度还使得通过单次网络前向传播即可从潜在空间高效生成图像。我们将得到的模型类别称为潜在扩散模型(LDMs)。
这种方法的一个显著优势是,我们只需要训练一次通用的自编码阶段,因此可以将其重用于多个DM训练或探索可能完全不同的任务81。这使得能够高效探索大量用于各种图像到图像和文本到图像任务的扩散模型。对于后者,我们设计了一种架构,将变换器连接到DM的UNet主干71,并支持任意类型的基于令牌的条件机制,见第3.3节。
总之,我们的工作做出了以下贡献:
(i) 与纯粹的基于变换器的方法23, 66相比,我们的方法能更优雅地扩展到更高维度的数据,因此可以 (a) 在比先前工作(见图1)提供更逼真和详细重建的压缩水平上工作,并且 (b) 可以高效地应用于百万像素图像的高分辨率合成。
(ii) 我们在多个任务(无条件图像合成、修复、随机超分辨率)和数据集上实现了有竞争力的性能,同时显著降低了计算成本。与基于像素的扩散方法相比,我们还显著降低了推理成本。
(iii) 我们表明,与先前同时学习编码器/解码器架构和基于分数的先验的工作93不同,我们的方法不需要精细地权衡重建和生成能力。这确保了极其逼真的重建,并且只需要对潜在空间进行很少的正则化。
(iv) 我们发现,对于密集条件的任务,如超分辨率、修复和语义合成,我们的模型可以以卷积方式应用,并渲染大的、一致的~1024²像素的图像。
(v) 此外,我们设计了一个基于交叉注意力的通用条件机制,支持多模态训练。我们用它来训练类条件、文本到图像和布局到图像模型。
(vi) 最后,我们在 https://github.com/CompVis/latent-diffusion 发布了预训练的潜在扩散和自编码模型,这些模型可能适用于除DM训练之外的多种任务81。
2 相关工作
图像合成的生成模型
图像的高维特性对生成建模提出了独特的挑战。生成对抗网络(GAN)27 允许高效采样具有良好感知质量的高分辨率图像 3, 42,但难以优化 2, 28, 54 并且难以捕捉完整的数据分布 55。相比之下,基于似然的方法强调良好的密度估计,这使得优化行为更佳。变分自编码器(VAE)46 和基于流的模型 18, 19 能够高效合成高分辨率图像 9, 44, 92,但样本质量不及 GANs。虽然自回归模型(ARM)6, 10, 94, 95 在密度估计方面取得了强大性能,但计算密集的架构 97 和顺序采样过程限制了它们只能用于低分辨率图像。由于基于像素的图像表示包含几乎不可感知的高频细节 16, 73,最大似然训练会花费不成比例的能力来对其建模,导致训练时间过长。为了扩展到更高分辨率,一些两阶段方法 23, 67, 101, 103 使用 ARMs 来对压缩的潜在图像空间而不是原始像素进行建模。
最近,扩散概率模型(DM)82 在密度估计 45 和样本质量 15 方面都达到了最先进的结果。当这些模型的基础神经主干被实现为 U-Net 15, 30, 71, 85 时,其生成能力源于对类图像数据归纳偏置的天然契合。当使用重新加权的目标函数 30 进行训练时,通常能达到最佳合成质量。在这种情况下,DM 对应于一个有损压缩器,并允许在图像质量和压缩能力之间进行权衡。然而,在像素空间中评估和优化这些模型的缺点是推理速度慢和训练成本非常高。虽然前者可以通过先进的采样策略 47, 75, 84 和分层方法 31, 93 得到部分解决,但在高分辨率图像数据上的训练总是需要计算昂贵的梯度。我们通过提出的 LDMs 来解决这两个缺点,LDMs 在维度更低的压缩潜在空间上工作。这使得训练在计算上更便宜,并且几乎不降低合成质量的情况下加速了推理(见图 1)。

两阶段图像合成
为了减轻单个生成方法的缺点,大量研究 11, 23, 67, 70, 101, 103 通过两阶段方法将不同方法的优点结合到更高效和性能更好的模型中。VQ-VAEs 67, 101 使用自回归模型来学习离散化潜在空间上的表达性先验。66 通过学习离散化图像和文本表示上的联合分布,将这种方法扩展到文本到图像生成。更一般地,70 使用条件可逆网络来提供不同领域潜在空间之间的通用转换。与 VQ-VAEs 不同,VQGANs 23, 103 在第一阶段采用对抗性和感知目标,将自回归变换器扩展到更大的图像。然而,为可行的 ARM 训练所需的高压缩率(这引入了数十亿可训练参数 23, 66)限制了此类方法的整体性能,而较低的压缩率则伴随着高计算成本的代价 23, 66。我们的工作避免了这种权衡,因为我们提出的 LDMs 由于其卷积主干,能更温和地扩展到更高维的潜在空间。因此,我们可以自由选择压缩级别,以在保证高保真重建的同时(见图 1),最佳地协调学习强大的第一阶段与将过多的感知压缩留给生成扩散模型之间的平衡。
虽然存在联合 93 或分别 80 学习编码/解码模型与基于分数的先验的方法,但前者仍然需要在重建能力和生成能力之间进行困难的权衡 11,并且性能被我们的方法超越(第 4 节),而后者专注于高度结构化的图像,如人脸。
3 方法
为了降低训练扩散模型进行高分辨率图像合成的计算需求,我们观察到,尽管扩散模型允许通过欠采样相应的损失项来忽略感知上不相关的细节30,但它们仍然需要在像素空间中进行昂贵的函数评估,这导致了计算时间和能源资源的巨大需求。
我们提出通过明确分离压缩学习阶段和生成学习阶段(见图2)来规避这一缺点。为了实现这一点,我们利用一个自编码模型,该模型学习一个在感知上与图像空间等效但在计算复杂度上显著降低的空间。
这种方法提供了几个优势:(i)通过离开高维图像空间,我们获得了在计算上更高效的扩散模型,因为采样是在低维空间上执行的。(ii)我们利用了扩散模型从其UNet架构71继承的归纳偏置,这使它们对具有空间结构的数据特别有效,因此减轻了先前方法23, 66所需的激进、降低质量的压缩级别的需求。(iii)最后,我们获得了通用的压缩模型,其潜在空间可用于训练多个生成模型,并且也可用于其他下游应用,例如单图像CLIP引导的合成25。
3.1 感知图像压缩
我们的感知压缩模型基于先前的工作23,由一个自编码器组成,该自编码器通过结合感知损失106和基于patch的33对抗目标20, 23, 103进行训练。这通过强制局部真实感确保重建结果被限制在图像流形上,并避免了仅依赖像素空间损失(如L2L_{2}L2 或L1L_{1}L1 目标)引入的模糊度。
更精确地说,给定RGB空间中的图像x∈RH×W×3x \in R^{H \times W \times 3}x∈RH×W×3,编码器E\mathcal{E}E 将xxx编码为潜在表示 z=E(x)z = \mathcal{E}(x)z=E(x),解码器D\mathcal{D}D 从潜在表示重建图像,得到 x~=D(z)=D(E(x))\tilde{x} = \mathcal{D}(z) = \mathcal{D}(\mathcal{E}(x))x~=D(z)=D(E(x)),其中z∈Rh×w×cz \in R^{h \times w \times c}z∈Rh×w×c。重要的是,编码器通过因子f=H/h=W/wf = H/h = W/wf=H/h=W/w 对图像进行下采样,我们研究了不同的下采样因子f=2mf = 2^{m}f=2m,其中m∈Nm \in Nm∈N。
为了避免任意高方差的潜在空间,我们尝试了两种不同的正则化方法。第一种变体,KL-reg.,对学习到的潜在表示施加一个轻微的对标准正态分布的KL惩罚,类似于VAE46, 69;而VQ-reg.在解码器内使用一个向量量化层96。该模型可以解释为VQGAN23,但量化层被解码器吸收。因为我们后续的扩散模型被设计为与我们学习到的潜在空间z=E(x)z = \mathcal{E}(x)z=E(x)的二维结构一起工作,所以我们可以使用相对温和的压缩率并实现非常好的重建。这与先前的工作23, 66形成对比,它们依赖于学习空间z的任意一维排序来自回归地建模其分布,从而忽略了zzz的大部分固有结构。因此,我们的压缩模型更好地保留了xxx的细节(见表8)。完整的目标函数和训练细节可以在补充材料中找到。
3.2 潜在扩散模型
扩散模型82是概率模型,旨在通过逐渐去噪一个正态分布变量来学习数据分布 p(x)p(x)p(x),这对应于学习一个长度为 TTT 的固定马尔可夫链的逆过程。对于图像合成,最成功的模型15, 30, 72依赖于 p(x)p(x)p(x) 的变分下界的一个重新加权变体,这反映了去噪分数匹配85。这些模型可以解释为一系列同等加权的去噪自编码器 ϵθ(xt,t);t=1...T\epsilon_{\theta}(x_{t}, t); t=1 \ldots Tϵθ(xt,t);t=1...T,它们被训练来预测其输入 xtx_{t}xt 的去噪版本,其中 xtx_{t}xt 是输入 xxx 的噪声版本。相应的目标可以简化为(附录B):
LDM=Ex,ϵ∼N(0,1),t∥ϵ−ϵθ(xt,t)∥22,(1) L_{DM} = \mathbb{E}_{x, \epsilon \sim \mathcal{N}(0,1), t} \left \\\| \\epsilon - \\epsilon_{\\theta}(x_{t}, t) \\\|_{2}\^{2} \\right, \qquad (1) LDM=Ex,ϵ∼N(0,1),t∥ϵ−ϵθ(xt,t)∥22,(1)
其中 ttt 从 {1,...,T}\{1, \ldots, T\}{1,...,T} 中均匀采样。
潜在表示的生成建模
通过我们训练好的由 E\mathcal{E}E 和 D\mathcal{D}D 组成的感知压缩模型,我们现在可以访问一个高效、低维的潜在空间,其中高频的、难以察觉的细节被抽象掉了。与高维像素空间相比,这个空间更适合基于似然的生成模型,因为它们现在可以(i)专注于数据的重要的、语义的部分,并且(ii)在更低维、计算上更高效的空间中进行训练。
与先前在高度压缩的离散潜在空间中依赖自回归、基于注意力的变换器模型的工作23, 66, 103不同,我们可以利用我们的模型提供的图像特定归纳偏置。这包括能够主要从 2D 卷积层构建底层 UNet 的能力,并进一步使用重新加权的边界将目标聚焦于感知上最相关的部分,该边界现在表示为:
LLDM:=EE(x),ϵ∼N(0,1),t∥ϵ−ϵθ(zt,t)∥22.(2) L_{LDM} := \mathbb{E}_{\mathcal{E}(x), \epsilon \sim \mathcal{N}(0,1), t} \left \\\| \\epsilon - \\epsilon_{\\theta}(z_{t}, t) \\\|_{2}\^{2} \\right. \qquad (2) LLDM:=EE(x),ϵ∼N(0,1),t∥ϵ−ϵθ(zt,t)∥22.(2)
我们模型的神经骨干 ϵθ(∘,t)\epsilon_{\theta}(\circ, t)ϵθ(∘,t) 被实现为一个时间条件化的 UNet71。由于前向过程是固定的,ztz_{t}zt 可以在训练期间有效地从 E\mathcal{E}E 获得,并且来自 p(z)p(z)p(z) 的样本可以通过单次通过 D\mathcal{D}D 解码到图像空间。
3.3 条件机制
与其他类型的生成模型56, 83类似,扩散模型原则上能够对形式为 p(z∣y)p(z \mid y)p(z∣y) 的条件分布进行建模。这可以通过一个条件去噪自编码器 ϵθ(zt,t,y)\epsilon_{\theta}(z_t, t, y)ϵθ(zt,t,y) 来实现,并为通过输入 yyy(如文本68、语义图33, 61或其他图像到图像转换任务34)控制合成过程铺平了道路。
然而,在图像合成的背景下,将 DMs 的生成能力与除类别标签15或输入图像的模糊变体72之外的其他类型的条件信息相结合,迄今为止仍是一个未被充分探索的研究领域。
我们通过在其底层 UNet 主干中引入交叉注意力机制97,将 DMs 转变为更灵活的条件图像生成器,该机制对于学习各种输入模态的基于注意力的模型是有效的35, 36。为了预处理来自不同模态的 yyy(例如语言提示),我们引入一个领域特定的编码器 τθ\tau_{\theta}τθ,它将 yyy 投影到一个中间表示 τθ(y)∈RM×dτ\tau_{\theta}(y) \in \mathbb{R}^{M \times d_{\tau}}τθ(y)∈RM×dτ,然后通过交叉注意力层映射到 UNet 的中间层,该层实现为:
Attention(Q,K,V)=softmax(QKTd)⋅V, \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right) \cdot V, Attention(Q,K,V)=softmax(d QKT)⋅V,
其中
Q=WQ(i)⋅φi(zt),K=WK(i)⋅τθ(y),V=WV(i)⋅τθ(y). Q = W_Q^{(i)} \cdot \varphi_i(z_t), \quad K = W_K^{(i)} \cdot \tau_{\theta}(y), \quad V = W_V^{(i)} \cdot \tau_{\theta}(y). Q=WQ(i)⋅φi(zt),K=WK(i)⋅τθ(y),V=WV(i)⋅τθ(y).
这里,φi(zt)∈RN×dϵi\varphi_i(z_t) \in \mathbb{R}^{N \times d_{\epsilon}^i}φi(zt)∈RN×dϵi 表示实现 ϵθ\epsilon_{\theta}ϵθ 的 UNet 的(展平的)中间表示,而 WV(i)∈Rd×dϵiW_V^{(i)} \in \mathbb{R}^{d \times d_{\epsilon}^i}WV(i)∈Rd×dϵi, WQ(i)∈Rd×dτW_Q^{(i)} \in \mathbb{R}^{d \times d_{\tau}}WQ(i)∈Rd×dτ 和 WK(i)∈Rd×dτW_K^{(i)} \in \mathbb{R}^{d \times d_{\tau}}WK(i)∈Rd×dτ 是可学习的投影矩阵36, 97。视觉描述见图 3。
基于图像-条件对,我们然后通过以下方式学习条件 LDM:
LLDM:=EE(x),y,ϵ∼N(0,1),t∥ϵ−ϵθ(zt,t,τθ(y))∥22,(3) L_{LDM} := \mathbb{E}_{\mathcal{E}(x), y, \epsilon \sim \mathcal{N}(0,1), t} \left \\\| \\epsilon - \\epsilon_{\\theta}(z_t, t, \\tau_{\\theta}(y)) \\\|_2\^2 \\right, \qquad (3) LLDM:=EE(x),y,ϵ∼N(0,1),t∥ϵ−ϵθ(zt,t,τθ(y))∥22,(3)
其中 τθ\tau_{\theta}τθ 和 ϵθ\epsilon_{\theta}ϵθ 通过公式 (3) 联合优化。这种条件机制非常灵活,因为 τθ\tau_{\theta}τθ 可以用领域特定的专家进行参数化,例如当 yyy 是文本提示时使用(未掩码的)变换器97(见第 4.3.1 节)。
4 实验
潜在扩散模型(LDMs)为各种图像模态提供了灵活且计算上易于处理的基于扩散的图像合成方法,我们将在下文中通过实验进行实证展示。然而,首先,我们将我们的模型与基于像素的扩散模型在训练和推理方面的增益进行比较。有趣的是,我们发现,在VQ正则化的潜在空间中训练的LDMs有时能获得更好的样本质量,尽管VQ正则化的第一阶段模型的重建能力略逊于其连续对应模型,参见表8。第一阶段正则化方案对LDM训练的影响及其对分辨率>256²的泛化能力的视觉比较可以在附录D.1中找到。在E.2节中,我们列出了本节所有结果在架构、实现、训练和评估方面的详细信息。
4.1 关于感知压缩的权衡
本节分析了我们的LDMs在不同下采样因子f∈{1,2,4,8,16,32}f \in \{1, 2, 4, 8, 16, 32\}f∈{1,2,4,8,16,32}(缩写为LDM-f,其中LDM-1对应于基于像素的DMs)下的行为。为了获得可比较的测试环境,我们将本小节所有实验的计算资源固定为单个NVIDIA A100,并且所有模型训练相同的步数和参数数量。
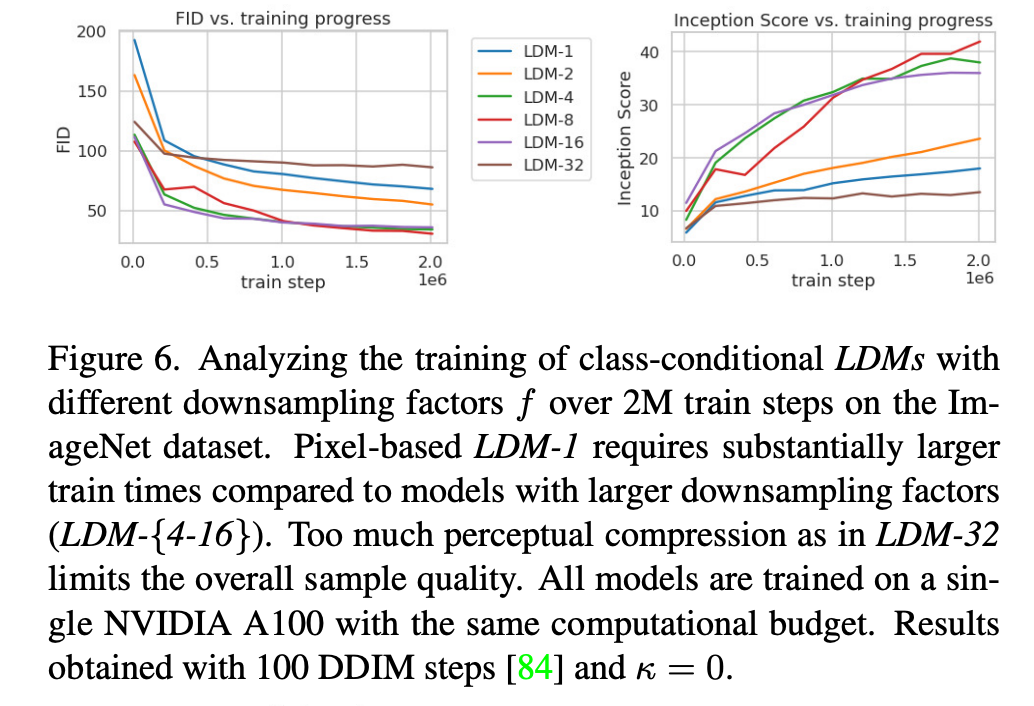
表8显示了本节比较的LDMs所使用的第一阶段模型的超参数和重建性能。图6显示了在ImageNet12数据集上,类别条件模型经过2M步训练后,样本质量随训练进度的变化函数。我们看到,i) LDM-{1,2}的小下采样因子导致训练进度缓慢,而ii) 过大的f值在相对较少的训练步数后会导致保真度停滞不前。回顾上述分析(图1和2),我们将其归因于i) 将大部分感知压缩留给了扩散模型,以及ii) 过于强烈的第一阶段压缩导致信息丢失,从而限制了可达到的质量。LDM-{4-16}在效率和感知上忠实的结果之间取得了良好的平衡,这在经过2M训练步数后,基于像素的扩散(LDM-1)和LDM-8之间38的显著FID29差距中体现出来。
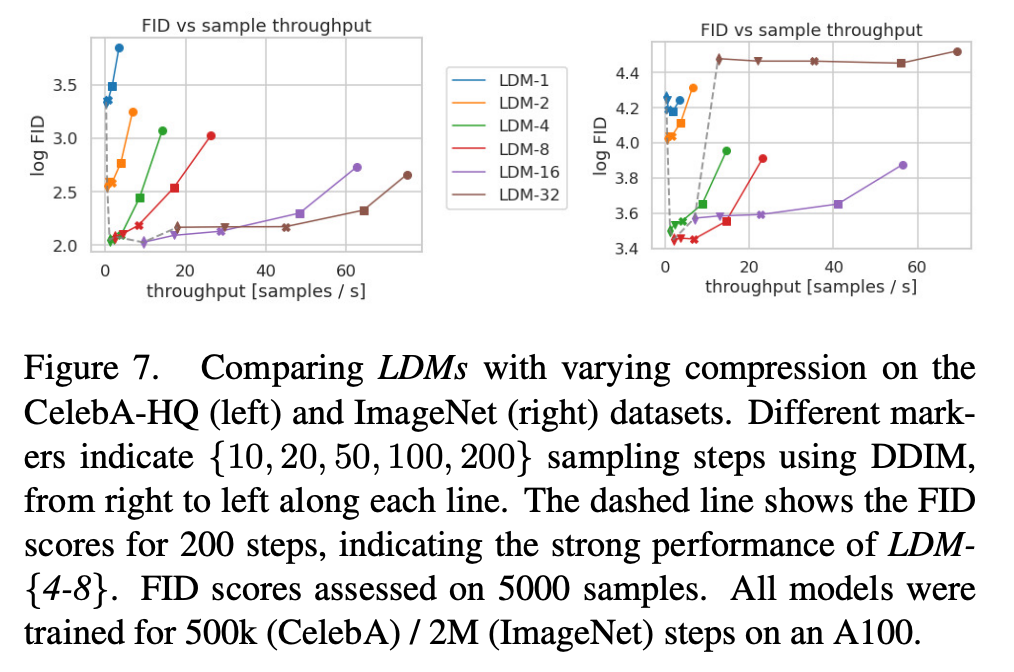
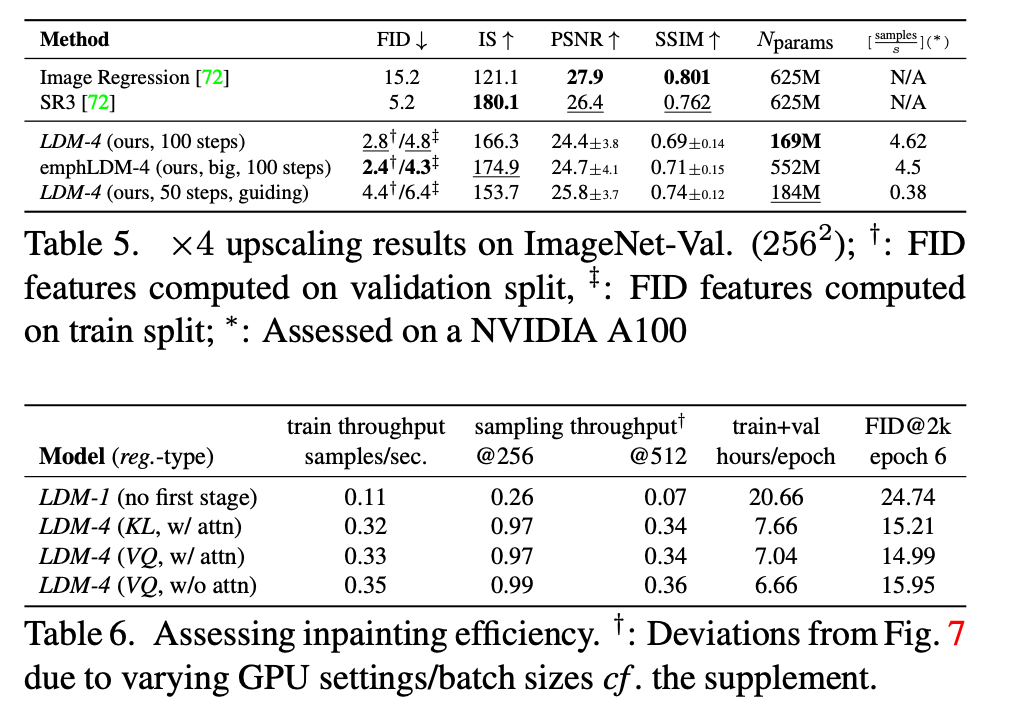
在图7中,我们比较了在CelebA-HQ39和ImageNet上训练的模型,针对不同去噪步数使用DDIM采样器84的采样速度,并将其与FID分数29进行对比绘图。LDM-{4-8}在感知压缩和概念压缩的不合适比率上优于其他模型。特别是与基于像素的LDM-1相比,它们在实现更低FID分数的同时,显著提高了样本吞吐量。像ImageNet这样的复杂数据集需要降低压缩率以避免质量下降。总之,LDM-4和-8为获得高质量合成结果提供了最佳条件。
4.2 使用潜在扩散进行图像生成
我们在CelebA-HQ39、FFHQ41、LSUN-Churches和-Bedrooms102上训练了256²图像的无条件模型,并评估了i) 样本质量和ii) 它们使用ii) FID29和ii) 精确度与召回率50对数据流形的覆盖情况。表1总结了我们的结果。在CelebA-HQ上,我们报告了新的最先进FID分数5.11,优于之前的基于似然的模型以及GANs。我们还超过了LSGM93,后者是将潜在扩散模型与第一阶段联合训练的。相比之下,我们在固定空间中训练扩散模型,并避免了权衡潜在空间的重建质量与学习先验的困难,见图1-2。
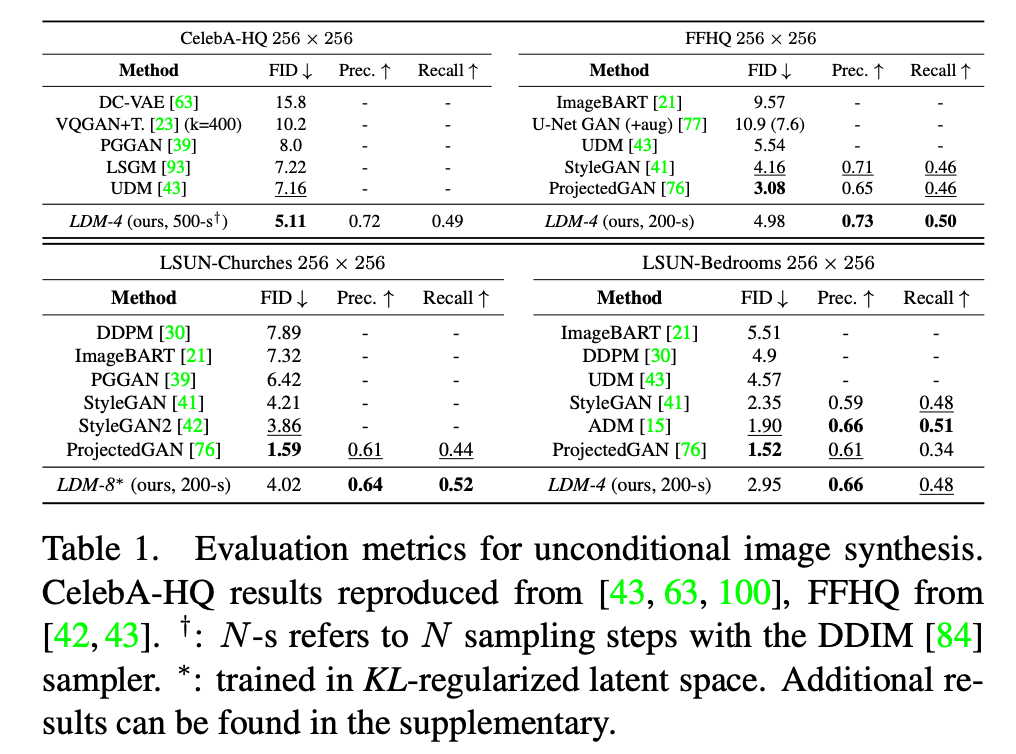
除了LSUN-Bedrooms数据集外,我们在所有数据集上的表现都优于先前的基于扩散的方法,在LSUN-Bedrooms上,我们的分数接近ADM15,尽管利用了其一半的参数并且需要少4倍的训练资源(见附录E.3.5)。
此外,LDMs在精确度和召回率方面持续改进了基于GAN的方法,从而证实了其基于模式覆盖的似然训练目标相对于对抗性方法的优势。在图4中,我们还展示了每个数据集的定性结果。

4.3. 条件潜在扩散
4.3.1 用于LDM的变换器编码器
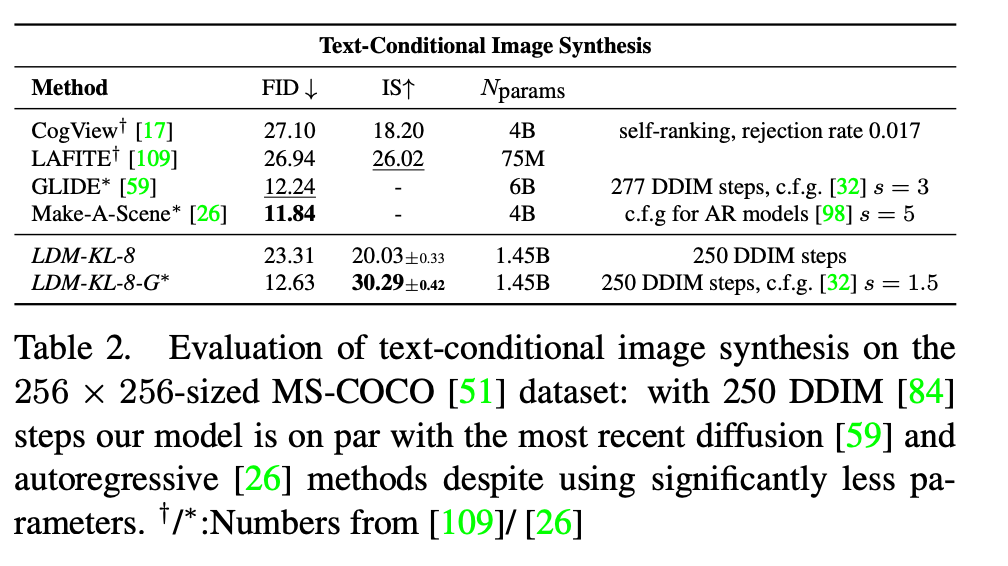
通过将基于交叉注意力的条件机制引入LDM,我们为其开启了先前在扩散模型中未被探索的各种条件模态。对于文本到图像建模,我们在LAION-400M78数据集上训练了一个拥有14.5亿参数的KL正则化LDM,该模型以语言提示为条件。我们采用BERT分词器14并将 τθ\tau_{\theta}τθ 实现为一个变换器97,以推断出一个潜在代码,该代码通过(多头)交叉注意力层映射到UNet中(第3.3节)。这种结合领域特定专家学习语言表示和视觉合成的组合,产生了一个强大的模型,能够很好地泛化到复杂的、用户定义的文本提示,参见图8和图5。为了进行定量分析,我们遵循先前的工作,在MS-COCO51验证集上评估文本到图像的生成,我们的模型优于强大的自回归17,66和基于GAN的方法109,参见表2。我们注意到,应用无分类器扩散引导 32极大地提升了样本质量,使得引导后的LDM-KL-8-G在文本到图像合成方面与最新的最先进自回归26和扩散模型59性能相当,同时显著减少了参数数量。为了进一步分析基于交叉注意力的条件机制的灵活性,我们还训练了基于OpenImages49上的语义布局合成图像的模型,并在COCO4上进行了微调,见图8。定量评估和实现细节见第D.3节。


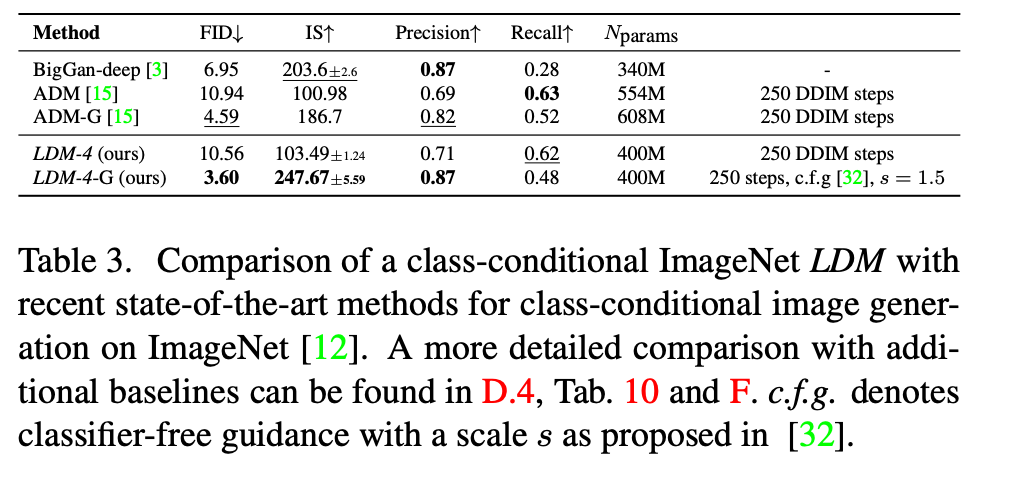
最后,遵循先前的工作3,15,21,23,我们在表3、图4和第D.4节中评估了我们在第4.1节中在ImageNet上训练的、性能最佳的类条件模型(f∈{4,8}f \in \{4,8\}f∈{4,8})。在这里,我们的性能超过了最先进的扩散模型ADM15,同时显著降低了计算需求和参数数量,参见表18。
4.3.2 超越 2562256^{2}2562 的卷积采样
通过将空间对齐的条件信息连接到 ϵ\epsilonϵ 的输入,LDM可以作为高效的通用图像到图像转换模型。我们利用这一点来训练语义合成、超分辨率(第4.4节)和修复(第4.5节)的模型。对于语义合成,我们使用与语义配对的景观图像23,61,并将语义图的下采样版本与 f=4f=4f=4 模型(VQ-reg.,参见表8)的潜在图像表示进行拼接。我们在 2562256^{2}2562 的输入分辨率(从 3842384^{2}3842 裁剪而来)上进行训练,但我们发现我们的模型能够泛化到更大的分辨率,并且当以卷积方式进行评估时,可以生成高达百万像素级别的图像(见图9)。我们利用这种特性,将第4.4节中的超分辨率模型和第4.5节中的修复模型应用于生成介于 5122512^{2}5122 和 102421024^{2}10242 之间的大图像。对于此应用,信噪比(由潜在空间的尺度引起)显著影响结果。在第D.1节中,当在以下两种情况下学习LDM时,我们说明了这一点:(i) 由 f=4f=4f=4 模型(KL-reg.,参见表8)提供的潜在空间,以及(ii) 按分量标准差重新缩放的版本。

后者与无分类器引导32结合,也使得文本条件的LDM-KL-8-G能够直接合成 >2562>256^{2}>2562 的图像,如图13所示。

4.4. 使用潜在扩散进行超分辨率

LDM可以通过连接(参见第3.3节)直接以低分辨率图像为条件,进行高效的超分辨率训练。在第一个实验中,我们遵循SR372,将图像退化固定为使用4倍下采样的双三次插值,并按照SR3的数据处理流程在ImageNet上进行训练。我们使用在OpenImages上预训练的 f=4f=4f=4 自编码模型(VQ-reg.,参见表8),并将低分辨率条件 yyy 和输入连接到UNet,即 τθ\tau_{\theta}τθ 是恒等映射。我们的定性和定量结果(见图10和表5)显示了具有竞争力的性能,LDM-SR在FID上优于SR3,而SR3具有更好的IS。一个简单的图像回归模型实现了最高的PSNR和SSIM分数;然而,这些指标与人类感知106的一致性不佳,并且倾向于模糊而不是未完美对齐的高频细节72。此外,我们进行了一项用户研究,比较像素基线模型与LDM-SR。我们遵循SR372的方案,向人类受试者显示一张低分辨率图像和两张高分辨率图像,并要求他们选择偏好。表4中的结果证实了LDM-SR的良好性能。PSNR和SSIM可以通过使用后置引导机制15来提升,我们通过感知损失实现了一种基于图像的引导器,详见第D.6节。

由于双三次退化过程不能很好地泛化到不遵循此预处理的图像,我们还通过使用更丰富/多样化的退化方式训练了一个通用模型LDM-BSR。结果在第D.6.1节中展示。
4.5. 使用潜在扩散进行图像修复
图像修复的任务是用新内容填充图像的掩码区域,可能是因为图像部分损坏或替换图像中现有但不希望的内容。我们评估了我们用于条件图像生成的通用方法与针对此任务的更专业的、最先进的方法相比如何。我们的评估遵循LaMa88的方案,这是一个最近的修复模型,引入了依赖快速傅里叶卷积8的专用架构。在Places108上的确切训练和评估协议在第E.2.2节中描述。
我们首先分析了第一阶段不同设计选择的效果。特别是,我们比较了LDM-1(即基于像素的条件DM)与LDM-4的修复效率,包括KL和VQ正则化,以及第一阶段没有任何注意力的VQ-LDM-4(参见表8),后者减少了高分辨率解码时的GPU内存。为了可比性,我们固定了所有模型的参数数量。表6报告了在分辨率 2562256^{2}2562 和 5122512^{2}5122 下的训练和采样吞吐量、每轮epoch的总训练时间(小时)以及六个epoch后在验证集上的FID分数。总体而言,我们观察到基于像素和基于潜在的扩散模型之间至少有2.7倍的加速,同时将FID分数提高了至少1.6倍。
表7中与其他修复方法的比较表明,我们带注意力的模型通过FID衡量,整体图像质量优于88。未掩码图像与我们的样本之间的LPIPS略高于88。我们将此归因于88只产生单个结果,该结果倾向于恢复更接近平均图像的內容,而我们的LDM产生多样化的结果,参见图21。此外,在一项用户研究(表4)中,人类受试者更倾向于我们的结果而非88的结果。
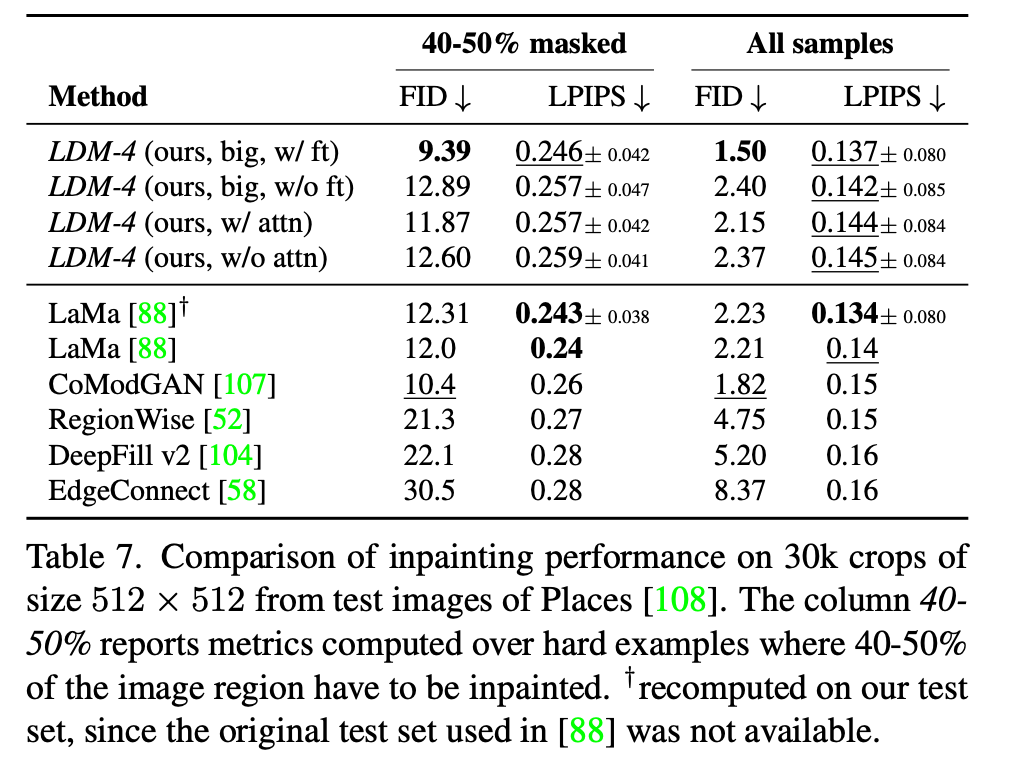
基于这些初步结果,我们还在无注意力的VQ正则化第一阶段的潜在空间中训练了一个更大的扩散模型(表7中的"big")。遵循15,该扩散模型的UNet在其特征层次结构的三个级别上使用注意力层,使用BigGAN3残差块进行上采样和下采样,并拥有3.87亿参数,而不是2.15亿。训练后,我们注意到在分辨率 2562256^{2}2562 和 5122512^{2}5122 下生成的样本质量存在差异,我们假设这是由于额外的注意力模块造成的。然而,在 5122512^{2}5122 分辨率下对模型进行半个epoch的微调,使模型能够适应新的特征统计量,并在图像修复上设定了新的最先进FID(表7中的"big, w/o attn, w/ft",图11)。

5 局限性与社会影响
局限性
尽管LDMs与基于像素的方法相比显著降低了计算需求,但其顺序采样过程仍然比GANs慢。此外,当需要高精度时,使用LDMs可能存在问题:尽管我们的f=4自编码模型(见图1)的图像质量损失非常小,但其重建能力可能成为需要在像素空间中精细精度的任务的瓶颈。我们假设我们的超分辨率模型(第4.4节)在这方面已经受到一定限制。
社会影响
像图像这样的媒体生成模型是一把双刃剑:一方面,它们支持各种创造性应用,特别是像我们这样降低训练和推理成本的方法,有可能促进该技术的普及并使其探索民主化。另一方面,这也意味着创建和传播被篡改的数据或散布错误信息和垃圾信息变得更加容易。特别是,故意操纵图像("深度伪造")在此背景下是一个普遍问题,而女性尤其受到其不成比例的影响13,24。
生成模型也可能泄露其训练数据5,90,当数据包含敏感或个人信息且未经明确同意收集时,这一问题令人极度担忧。然而,这种情况在多大程度上也适用于图像的DMs尚未完全了解。
最后,深度学习模块倾向于复制或放大数据中已存在的偏见22,38,91。虽然扩散模型比基于GAN的方法能更好地覆盖数据分布,但我们的两阶段方法(结合了对抗性训练和基于似然的目标)在多大程度上歪曲了数据,仍然是一个重要的研究问题。
关于深度生成模型的伦理考量的更一般、详细的讨论,请参见例如13。
6 结论
我们提出了潜在扩散模型,这是一种简单有效的方法,可以在不降低质量的情况下显著提高去噪扩散模型的训练和采样效率。基于此以及我们的交叉注意力条件机制,我们的实验证明,在广泛的条件图像合成任务中,与最先进的方法相比,无需特定任务架构即可获得优异的结果。