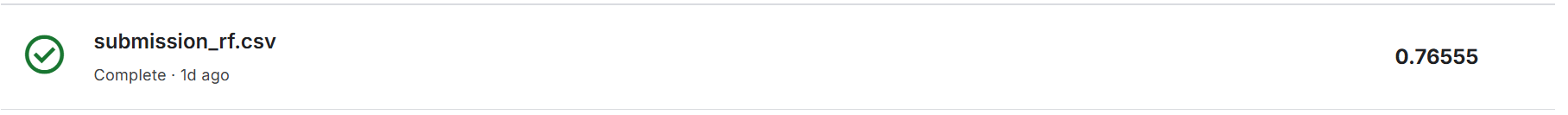之前的文章中,我们进行了机器学习和深度学习的尝试,并提到过一个问题:模型的参数如何选择会对模型的效果产生非常大的影响,因此本节内容主要讨论如何找出模型的最优参数
首先,我们明确一个问题,一般来说,不会存在一组参数,能让模型适配所有的任务;因此,我们所说的模型最优参数,都是针对当前任务对应的数据集来说的,如果更换任务,甚至说更好输入模型的特征,都有可能导致模型的最优参数发生变化。
因此,调优是一个很繁琐的任务,不过现在有了很多封装好的工具包和ai,大大降低了任务难度,大家需要多运用这些工具
机器学习调优------随机搜索
(所谓调优,当然要先知道模型有哪些可以调整的参数,不知道就问ai)
python
# 1. RandomForest调参
print("调参RandomForest...")
param_dist_rf = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
random_search_rf = RandomizedSearchCV(
RandomForestClassifier(random_state=42),
param_dist_rf,
n_iter=10,
cv=5,
random_state=42,
n_jobs=-1
)
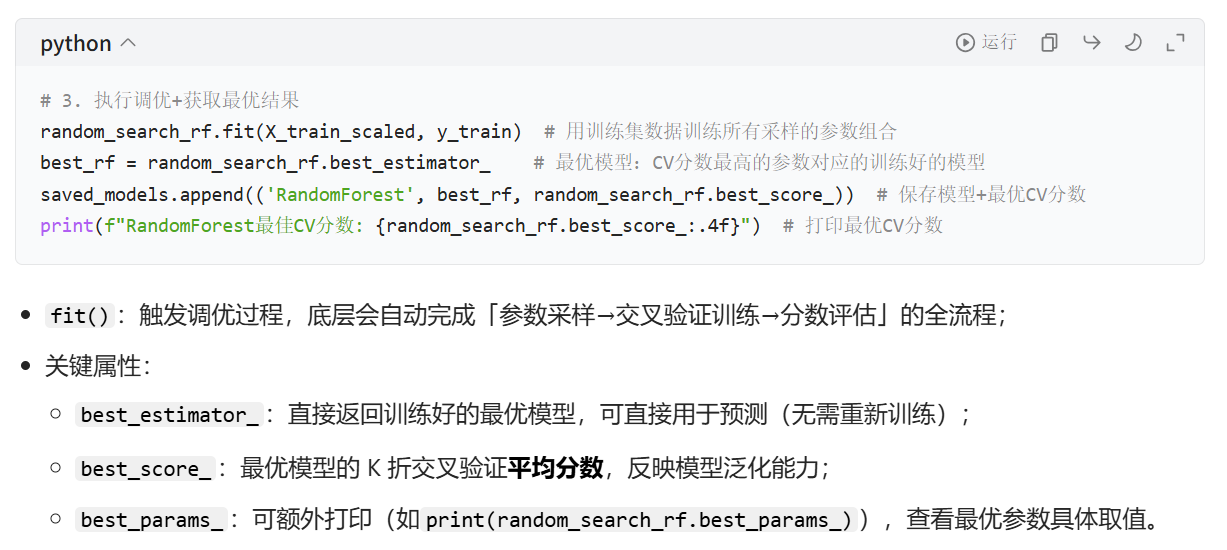
random_search_rf.fit(X_train_scaled, y_train)
best_rf = random_search_rf.best_estimator_
saved_models.append(('RandomForest', best_rf, random_search_rf.best_score_))
print(f"RandomForest最佳CV分数: {random_search_rf.best_score_:.4f}")
# 2. DecisionTree调参
print("调参DecisionTree...")
param_dist_dt = {
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'criterion': ['gini', 'entropy']
}
random_search_dt = RandomizedSearchCV(
DecisionTreeClassifier(random_state=42),
param_dist_dt,
n_iter=10,
cv=5,
random_state=42,
n_jobs=-1
)
random_search_dt.fit(X_train_scaled, y_train)
best_dt = random_search_dt.best_estimator_
saved_models.append(('DecisionTree', best_dt, random_search_dt.best_score_))
print(f"DecisionTree最佳CV分数: {random_search_dt.best_score_:.4f}")这里仅介绍**RandomizedSearchCV(随机搜索交叉验证)** ,它是机器学习中高效、实用的超参数调优方法,核心是在指定超参数范围内随机采样组合,结合交叉验证筛选最优参数,专门解决网格搜索(GridSearchCV)参数组合过多、耗时过长的问题。
超参数调优的核心目标是找到一组超参数,让模型在未知数据上的泛化能力最优 ,RandomizedSearchCV 实现这一目标的逻辑分为 3 步:
- 定义参数空间 :为模型每个超参数指定一个待搜索的取值范围 / 列表(如随机森林的
n_estimators指定 100,200,300); - 随机采样参数组合 :从参数空间中随机抽取指定数量(
n_iter)的参数组合,而非遍历所有组合(这是和网格搜索的核心区别); - 交叉验证评估 :对每一组随机采样的参数,用K 折交叉验证(CV) 训练模型并计算验证分数,最终选择验证分数最高的参数组合作为最佳超参数,对应的模型为最佳估计器(best_estimator_)。
两者对比如下表,更能体现随机搜索的优势:
| 特性 | RandomizedSearchCV(随机搜索) | GridSearchCV(网格搜索) |
|---|---|---|
| 参数组合遍历方式 | 随机采样 n_iter 组 | 遍历所有组合 |
| 时间效率 | 高(采样数可控) | 低(组合数随参数维度指数增长) |
| 调优效果 | 接近最优(抽样覆盖关键组合) | 理论最优(遍历所有可能) |
| 适用场景 | 参数空间大、快速调优 | 参数空间小、追求极致调优 |
这里简要介绍一下代码内容,其实现在的ai写这种简单的调优已经很熟练了,完全可以交给ai


深度学习调优------Optuna (以MLP为例)
python
# 3. MLP调参 (Optuna)
print("调参MLP...")
# 定义TunedMLP类(全局)
class TunedMLP(nn.Module):
def __init__(self, input_size, dropout_rate):
super(TunedMLP, self).__init__()
self.fc1 = nn.Linear(input_size, 128)
self.bn1 = nn.BatchNorm1d(128)
self.dropout1 = nn.Dropout(dropout_rate)
self.fc2 = nn.Linear(128, 64)
self.bn2 = nn.BatchNorm1d(64)
self.dropout2 = nn.Dropout(dropout_rate)
self.fc3 = nn.Linear(64, 32)
self.bn3 = nn.BatchNorm1d(32)
self.dropout3 = nn.Dropout(dropout_rate)
self.fc4 = nn.Linear(32, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.dropout1(torch.relu(self.bn1(self.fc1(x))))
x = self.dropout2(torch.relu(self.bn2(self.fc2(x))))
x = self.dropout3(torch.relu(self.bn3(self.fc3(x))))
x = self.sigmoid(self.fc4(x))
return x
def objective(trial):
lr = trial.suggest_float('lr', 1e-5, 1e-1, log=True)
dropout_rate = trial.suggest_float('dropout', 0.1, 0.5)
model = TunedMLP(X_train_scaled.shape[1], dropout_rate)
optimizer = optim.Adam(model.parameters(), lr=lr)
criterion = nn.BCELoss()
# 简短训练
for epoch in range(20):
model.train()
optimizer.zero_grad()
outputs = model(X_train_tensor)
loss = criterion(outputs, y_train_tensor)
loss.backward()
optimizer.step()
# 验证准确率
model.eval()
with torch.no_grad():
y_pred_prob = model(X_val_tensor)
y_pred = (y_pred_prob > 0.5).float()
acc = accuracy_score(y_val, y_pred.numpy().flatten())
return acc
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=10)
best_params = study.best_params
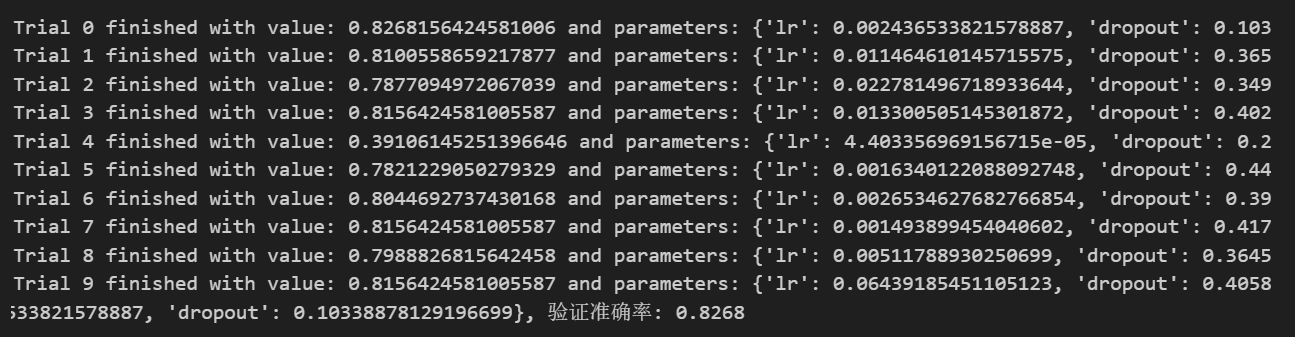
print(f"MLP最佳参数: {best_params}, 验证准确率: {study.best_value:.4f}")
# 训练最佳MLP
best_mlp = TunedMLP(X_train_scaled.shape[1], best_params['dropout'])
optimizer = optim.Adam(best_mlp.parameters(), lr=best_params['lr'])
criterion = nn.BCELoss()
for epoch in range(50): # 更长训练
best_mlp.train()
optimizer.zero_grad()
outputs = best_mlp(X_train_tensor)
loss = criterion(outputs, y_train_tensor)
loss.backward()
optimizer.step()
saved_models.append(('MLP', best_mlp, study.best_value))基于 Optuna 的贝叶斯超参数优化 ,这是深度学习调优的主流高效方法(区别于机器学习的随机搜索 / 网格搜索),核心是通过贝叶斯推理智能搜索超参数空间,用更少的试错次数找到最优超参数。
核心:Optuna 贝叶斯优化的调优原理(区别于随机 / 网格搜索)
深度学习的超参数(如学习率、dropout 率)多为连续值 / 对数分布值 ,且参数间存在隐性关联 (如学习率和 batch size 相互影响),传统的随机 / 网格搜索 "无记忆、无关联" 的采样方式效率极低。Optuna 的贝叶斯优化核心逻辑是边试错、边学习、边聚焦:
- 初始化采样:先随机试几组超参数,记录每组参数的验证效果(如 MLP 验证准确率);
- 构建概率模型:基于已试的参数和效果,构建一个「超参数→模型效果」的概率预测模型(如高斯过程、树结构 Parzen 估计器);
- 智能选下一组参数:根据概率模型,优先选择最可能提升效果的超参数组合(聚焦参数空间的 "最优潜力区域",而非盲目随机);
- 迭代优化 :重复 2-3 步,直到达到指定试错次数(
n_trials),最终选择效果最优的参数。
简单说:Optuna 会 "记住" 之前的调优结果,智能避开无效区域、聚焦最优区域,比随机搜索少用 50% 以上的试错次数就能找到更优超参数,是深度学习调优的首选工具。
1. 定义可调参的 MLP 模型
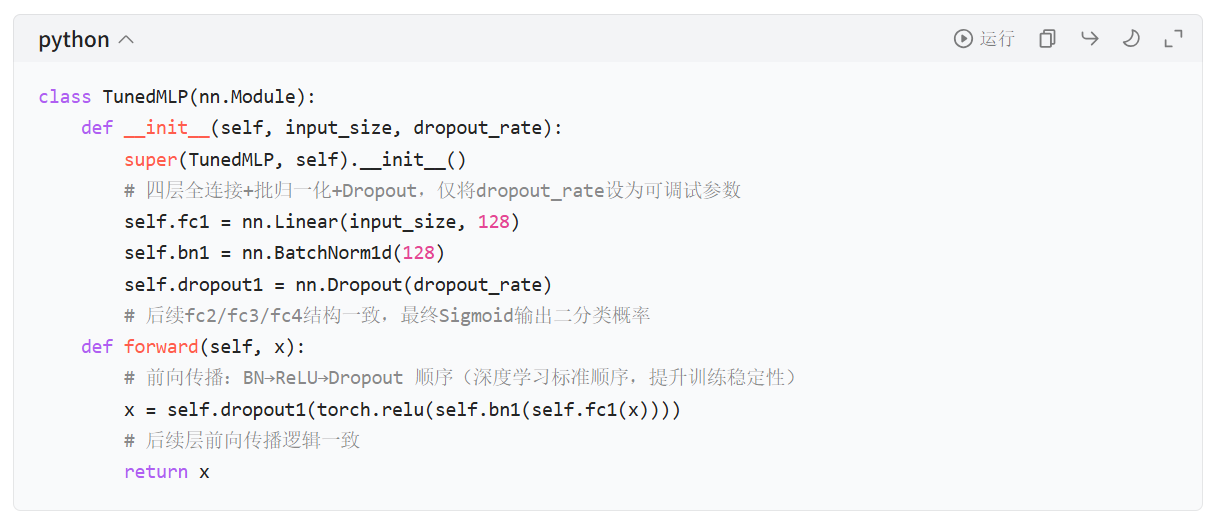
- 核心设计:将需要调优的超参数(
dropout_rate)作为模型初始化参数,非调参参数(如隐藏层维度 128/64/32)固定,简化调优空间; - 关键细节:
BatchNorm1d+ReLU+Dropout的顺序是深度学习训练的黄金顺序,能有效缓解梯度消失、抑制过拟合、提升训练稳定性; - 适用场景:二分类任务(如本例中的泰坦尼克生存预测),最终用
Sigmoid输出 0~1 的概率,符合BCELoss损失函数要求。
2. 定义 Optuna 目标函数(objective)------ 调优的核心
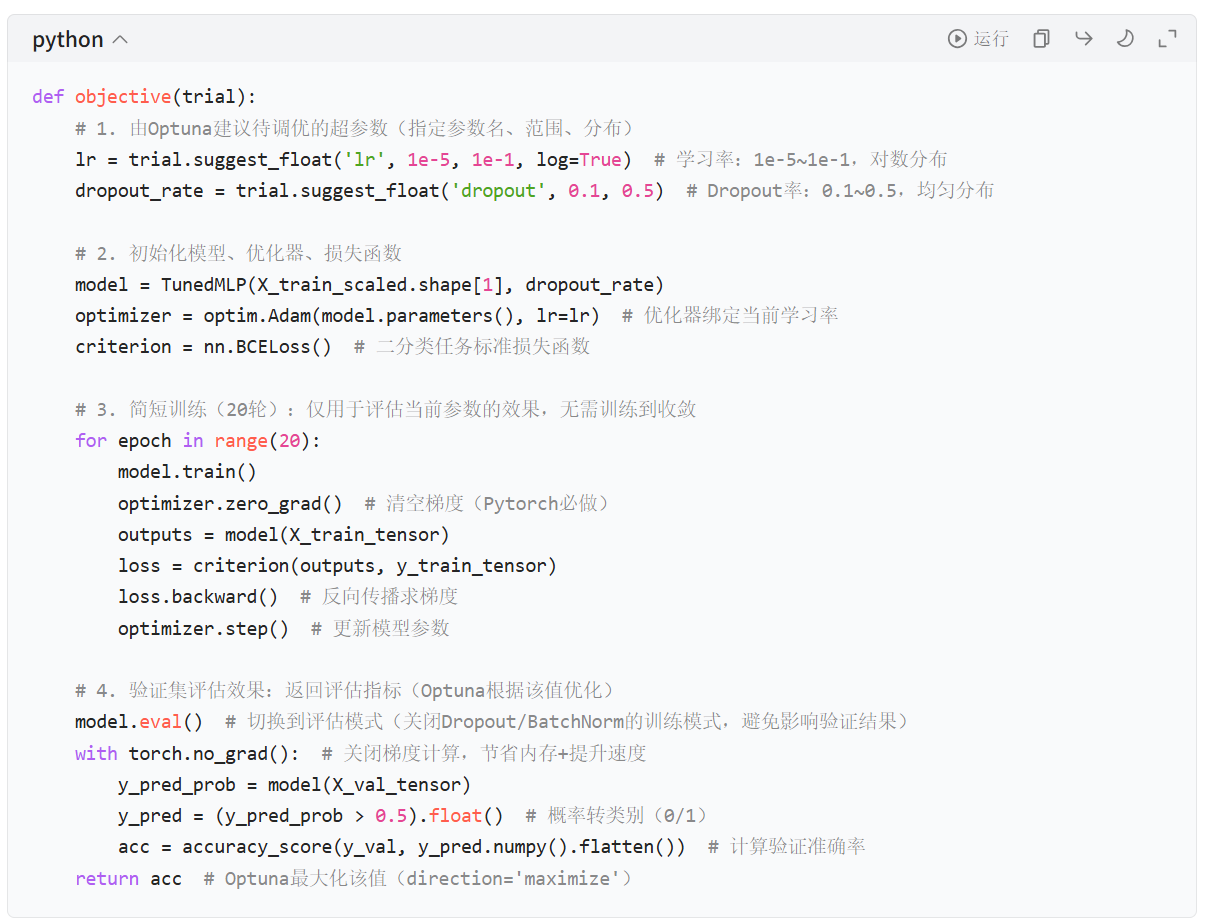
- 参数建议方法 :
trial.suggest_*系列方法,根据参数类型选择(如浮点型suggest_float、整型suggest_int、类别型suggest_categorical);- 学习率
lr设为对数分布(log=True):深度学习中学习率的有效范围是对数级的(如 1e-4 比 0.01 更优的概率远高),对数采样能更均匀覆盖有效范围; - Dropout 率设为均匀分布:0.1~0.5 的范围是 MLP 的常规有效范围,均匀采样即可。
- 学习率
- 简短训练 :仅训练 20 轮,目的是快速评估参数效果,而非追求高精度------ 调优阶段的核心是 "筛选参数",全量收敛训练放在后续,大幅提升调优效率;
- 评估规范 :必须用独立验证集(X_val/y_val) 评估,且切换
model.eval()+with torch.no_grad(),避免训练模式的 Dropout/BN 干扰验证结果,保证评估准确。
3. 启动 Optuna 超参数搜索

- 核心参数:
direction:优化方向,分类任务设maximize(最大化准确率 / AUC),回归任务设minimize(最小化 MSE/RMSE);n_trials:试错次数,小数据集(如泰坦尼克)设 10~20 即可,中等 / 大数据集可设 30~50,兼顾效率和效果;
- 关键属性:
study.best_params:返回最优参数字典,可直接用于后续模型初始化;study.best_value:返回最优参数对应的验证指标值(如准确率)。
4. 用最优参数全量训练 MLP 模型
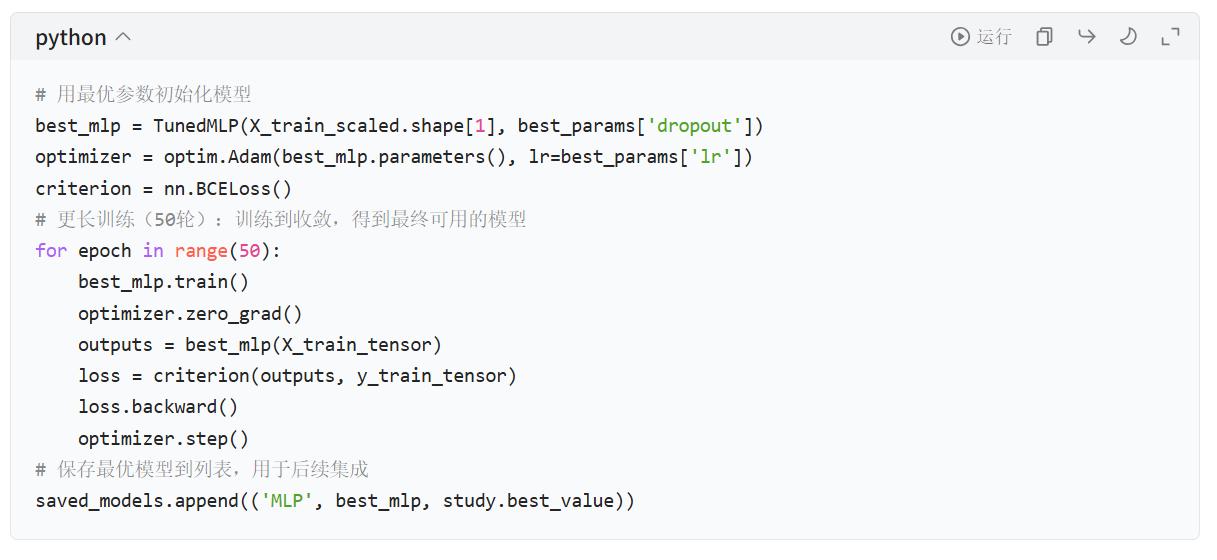
当然,深度学习调优不仅是超参数调优 ,还包含模型结构、训练策略、正则化等维度,且各维度相互影响,这是和机器学习(如随机森林)调优的本质区别。Optuna的方法也不仅限于这些,条鱼的目的在于提高模型的指标和泛化能力。
Optuna运行后输出如下
经过测试,目前RF在kaggle上表现最好