本次安装的操作系统是Kylin X86。
- 查看JDK是否安装
bash
[root@ck02 ~]# java -version
openjdk version "1.8.0_292"
OpenJDK Runtime Environment Bisheng (build 1.8.0_292-b10)
OpenJDK 64-Bit Server VM Bisheng (build 25.292-b10, mixed mode)
#如果没有安装JDK,使用yum 安装
yum search java | grep jdk #查看JDK版本
yum install -y java-1.8.0-openjdk-devel #安装JDK8-
下载安装包
-
安装Hadoop3.2.2
bash
#在/data下创建Hadoop目录
[root@ck02 data]# mkdir hadoop
[root@ck02 data]# cd hadoop
# 把安装包上传到/data/hadoop目录下,解压
[root@ck02 hadoop]# tar -zvxf hadoop-3.2.2.tar.gz
[root@ck02 hadoop]# cd hadoop-3.2.2
[root@ck02 hadoop-3.2.2]# pwd #查看安装目录 /data/hadoop/hadoop-3.2.2
#修改环境变量
[root@ck02 hadoop-3.2.2]# vim /etc/profile #新增下面两行
export HADOOP_HOME=/data/hadoop/hadoop-3.2.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[root@ck02 hadoop-3.2.2]# source /etc/profile
#修改Hadoop配置文件
[root@ck02 hadoop-3.2.2]# cd etc/hadoop/
[root@ck02 hadoop]# vim hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.292.b10-8.ky10.x86_64
export HADOOP_HOME=/data/hadoop/hadoop-3.2.2
export HADOOP_CONF_DIR=/data/hadoop/hadoop-3.2.2/etc/hadoop
[root@ck02 hadoop]# vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>ck02</value>
<!-- 这里改成自己的主机名 -->
</property>
</configuration>
[root@ck02 hadoop]# vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
[root@ck02 hadoop]# vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ck02:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hp/temp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
[root@ck02 hadoop]# vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<!-- 副本数,生产默认3副本,测试改成1 -->
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hp/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hp/hdfs/data</value>
</property>
</configuration>
#创建hadoop用户,使用hadoop用户启动服务
[root@ck02 hadoop]# useradd hadoop
[root@ck02 hadoop]# passwd hadoop
#给Hadoop用户权限
[root@ck02 hadoop]# chown -R hadoop:hadoop /data/hadoop/hadoop-3.2.2
#创建hadoop.tmp.dir
[root@ck02 hadoop]# mkdir -p /data/hp/temp
[root@ck02 hadoop]# mkdir -p /data/hp/temp
[root@ck02 hadoop]# chown -R hadoop:hadoop /data/hp/
#切换hadoop用户启动
[root@ck02 hadoop]# su - hadoop
#配置服务器自身的ssh免密认证,为了让Hadoop脚本无交互执行
[hadoop@ck02 ~]$ ssh-keygen -t rsa
[hadoop@ck02 ~]$ cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
#启动集群前格式化NameNode
[hadoop@ck02 ~]$ hdfs namenode -format
#启动集群服务
[hadoop@ck02 ~]$ start-all.sh
[hadoop@ck02 ~]$ jps
3327073 SecondaryNameNode
3326740 DataNode
3326570 NameNode
3327499 NodeManager
3327337 ResourceManager
3999281 Jps
#验证集群
[hadoop@ck02 ~]$ hdfs dfs -put .bashrc /
[hadoop@ck02 ~]$ hdfs dfs -ls /
-rw-r--r-- 1 hadoop supergroup 138 2026-02-02 14:44 /.bashrc
#登录HDFS WebUI查看,默认端口是9870
http://ck02:9870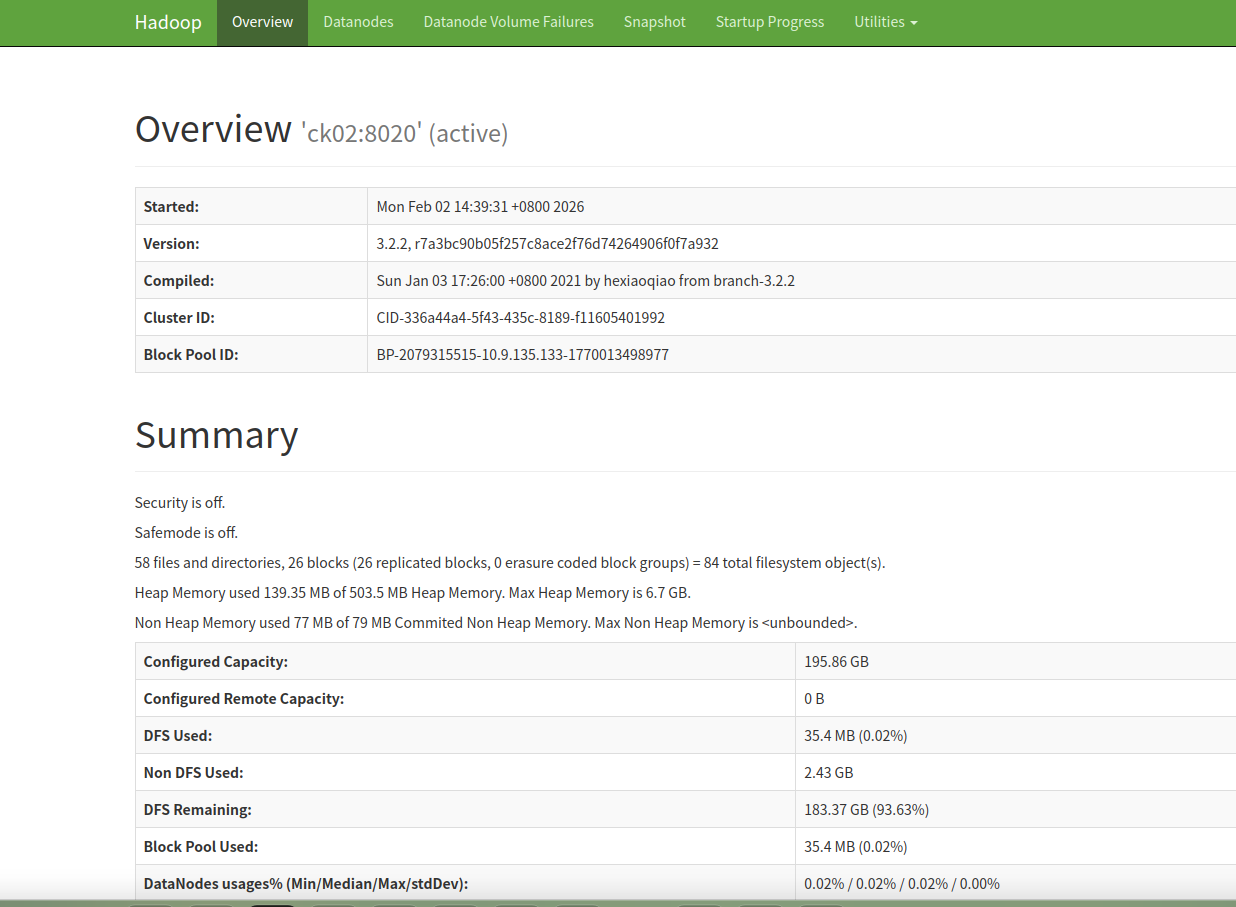
登录yarn WebUI查看,默认端口8088。
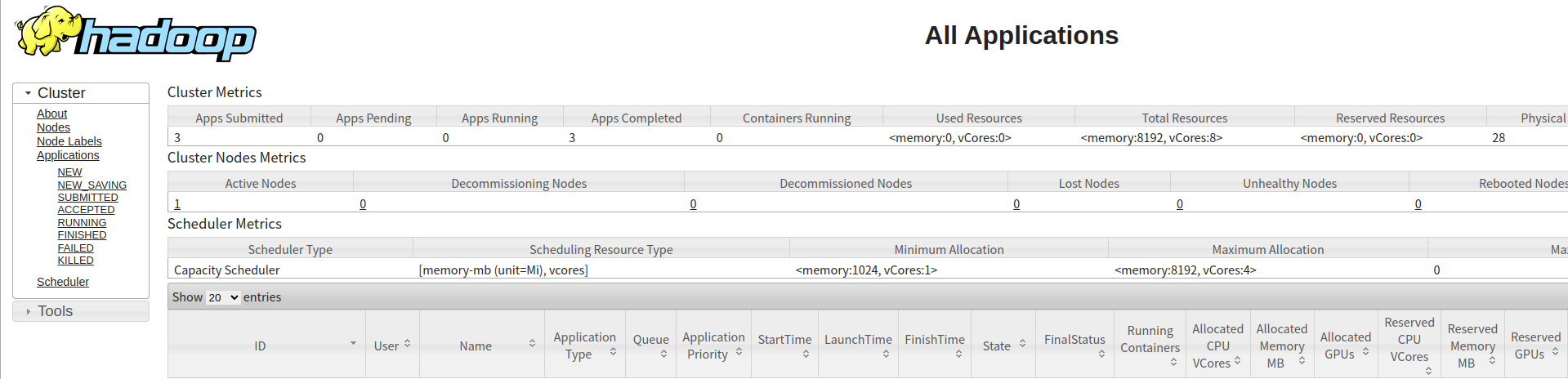
后续会出hive3.1.2的安装~