作者:来自 Elastic Jim Ferenczi, Benjamin Trent 及 Ignacio Vera Sequeiros
介绍在 Elasticsearch 中使用 Base64 编码字符串来加速向量摄取。
从向量搜索到强大的 REST API,Elasticsearch 为开发者提供了最全面的搜索工具集。深入 GitHub 上的示例 notebooks 来尝试新东西。你也可以今天就开始你的免费试用,或在本地运行 Elasticsearch。
我们正在提升 Elasticsearch 中向量的摄取速度。现在,在 Elastic Cloud Serverless 和 v9.3 中,你可以将向量以 Base64 编码字符串的形式发送到 Elasticsearch,这将为你的摄取流水线带来立竿见影的收益。
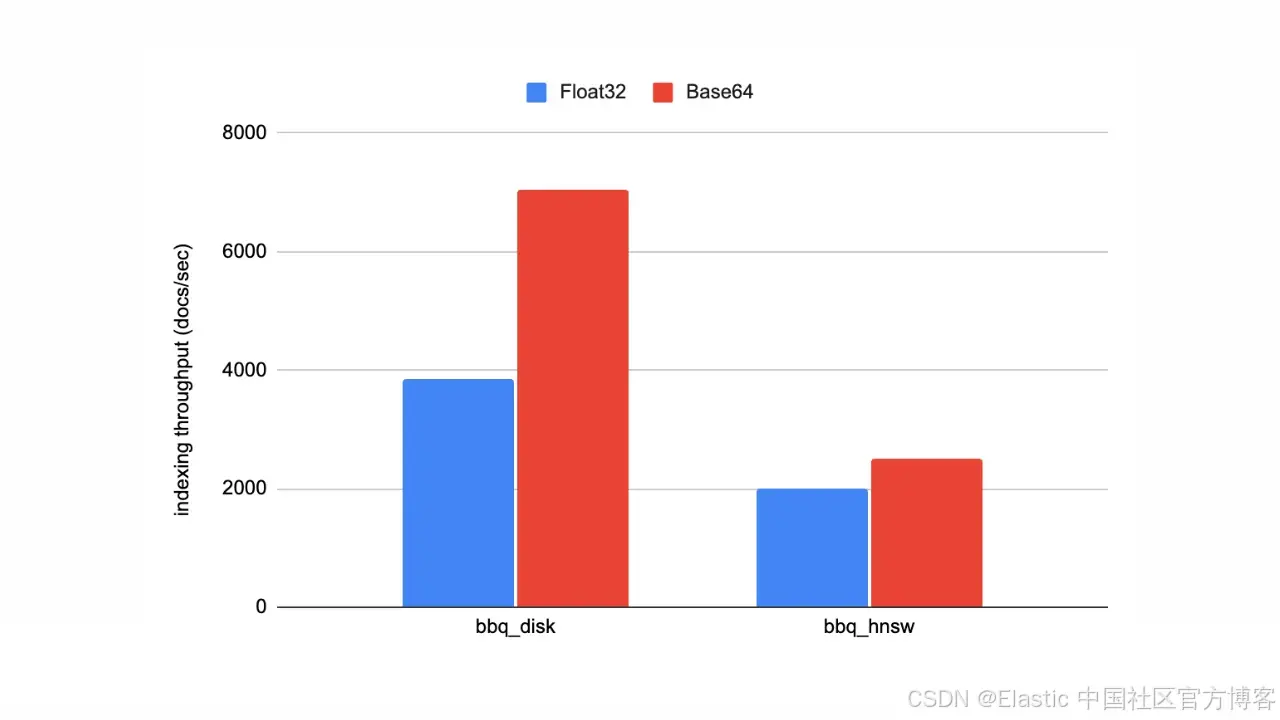
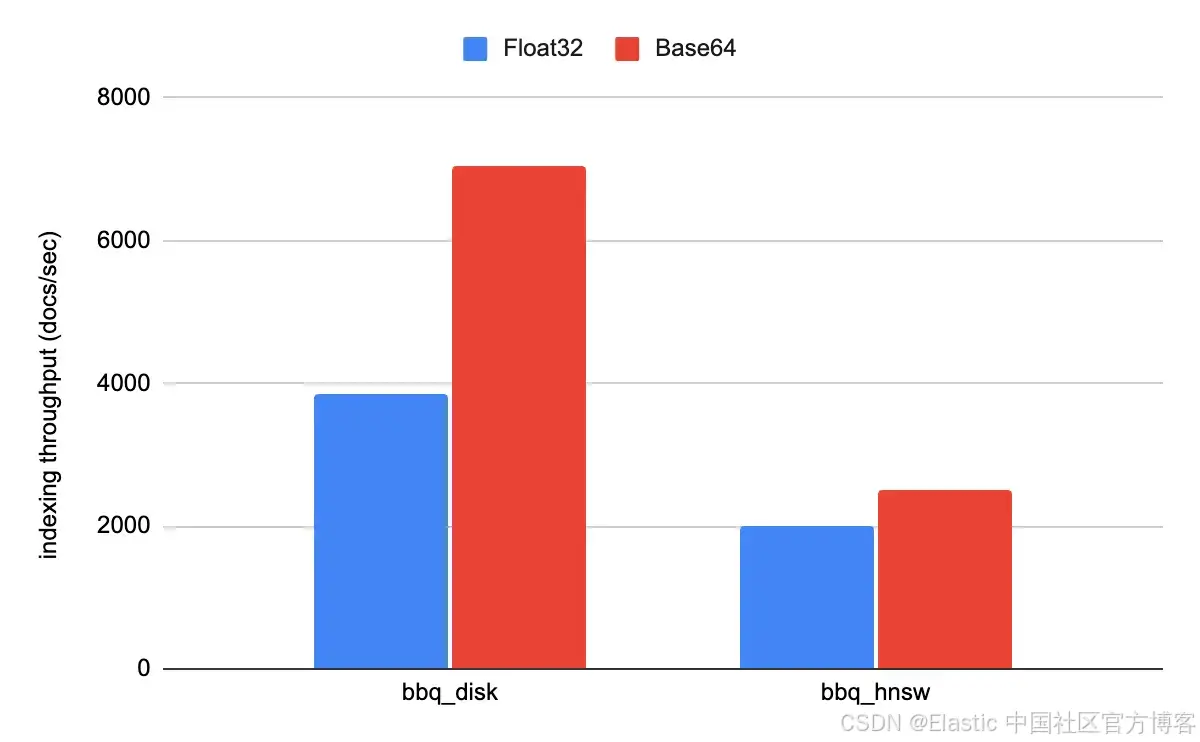
这一变化将解析 JSON 中向量的开销降低了一个数量级,这意味着在 DiskBBQ 上索引吞吐量几乎提升了 100%,在 分层可导航小世界 HNSW 工作负载中也提升了大约 20%。在这篇博客中,我们将更深入地看看 Base64 编码字符串,以及它为向量摄取带来的改进。
问题是什么?
在 Elastic,我们一直在寻找改进向量搜索能力的方法,无论是增强现有的存储格式,还是引入新的存储格式。比如,最近我们新增了一种对磁盘更友好的存储格式 DiskBBQ,并启用了基于 NVIDIA cuVS 的向量索引。
在这两种情况下,我们原本预计摄取速度会有显著提升。然而,当这些改动完全集成到 Elasticsearch 之后,提升幅度却没有达到我们的预期。对摄取过程进行的 flamegraph 分析清楚地表明了问题所在:JSON 解析已经成为主要瓶颈之一。
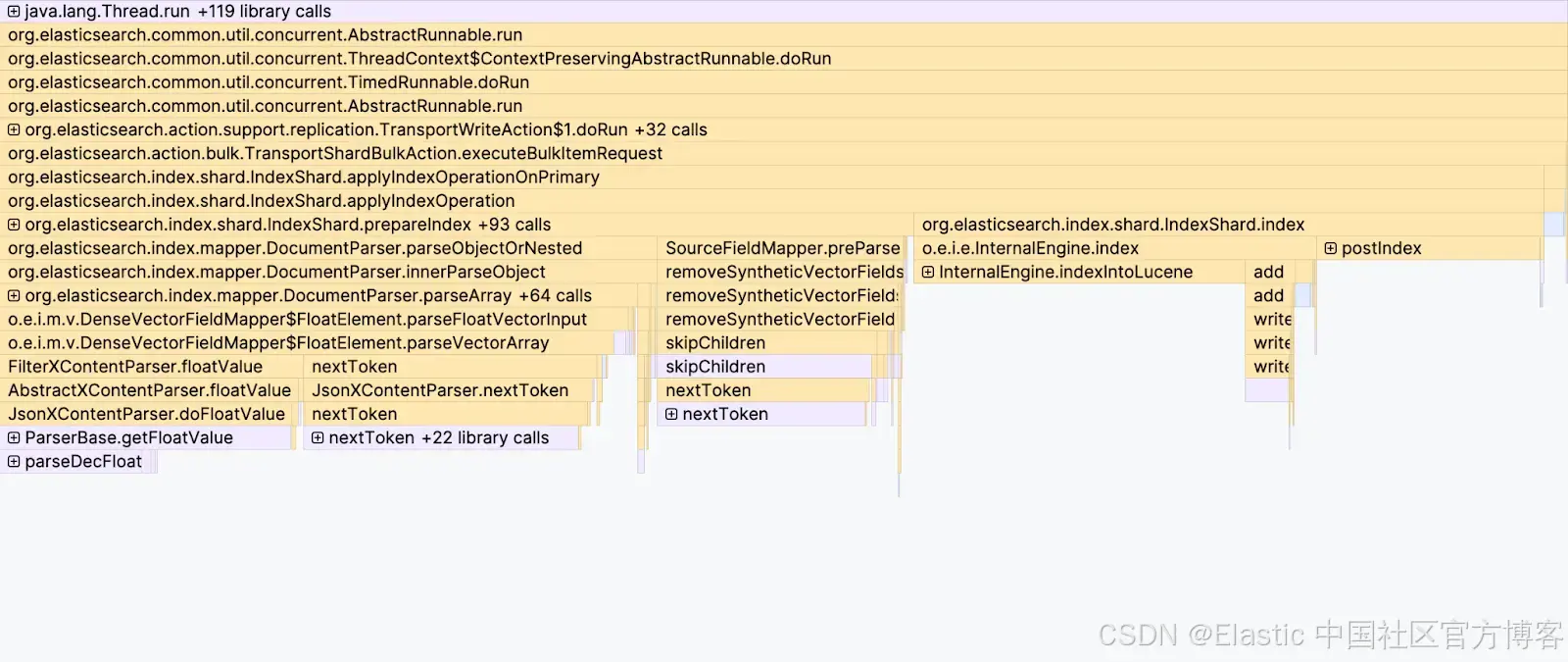
解析 JSON 需要遍历数组中的每一个元素,并将文本格式的数字转换为 32 位浮点数,这个过程开销非常大。
为什么使用 Base64 编码字符串?
解析向量最高效的方式是直接从其二进制表示读取,其中每个元素都是一个 32 位浮点值。然而,JSON 是一种基于文本的格式,在其中包含二进制数据的方式就是使用 Base64 编码字符串。Base64 只是一个将二进制数据转换为文本的编码方案。
{
"emb" : [1.2345678, 2.3456789, 3.4567891]
}我们现在可以将向量以 Base64 编码字符串的形式发送:
{
"emb" : "P54GUUAWH5pAXTwI"
}值得吗?我们的基准测试表明,值得。在解析 1,000 个 JSON 文档时,使用 Base64 编码字符串而不是浮点数组,性能提升超过一个数量级。代价是一个很小的 编码 / 解码 权衡(客户端进行 Base64 编码,服务器端为解码创建一个临时字节数组),但换来的好处是消除了昂贵的逐元素数值解析。
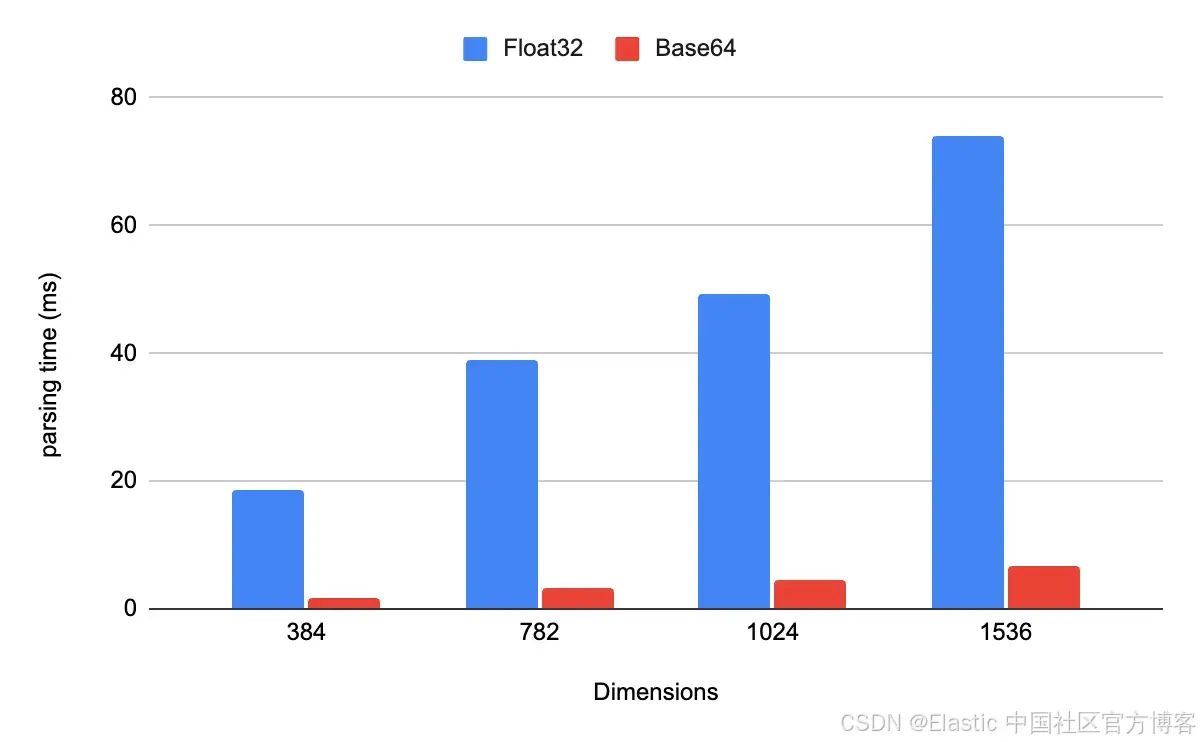
给我一些摄取数据
当我们使用不同方式运行 so_vector rally track 时,可以在实际中看到这些改进。实际提升取决于每种存储格式的索引速度。对于 bbq_disk,索引吞吐量提升大约 100%;而对于 bbq_hnsw,由于索引本身更慢,提升更接近 20%。
从 Elasticsearch v9.2 开始,向量默认会从 _source 中排除,并在内部以 32 位浮点值存储。这个行为同样适用于 Base64 编码的向量,因此在搜索时,索引格式的选择对你来说是完全透明的。
客户端支持
为向量索引增加一种新格式,可能需要对摄取流水线进行修改。为此,在 v9.3 中,Elasticsearch 官方客户端可以在 32 位浮点值向量和 Base64 编码字符串之间进行相互转换。你可能需要查看对应客户端文档,了解具体实现方式。
例如,下面是一个使用 Python 客户端实现 bulk 加载的示例代码片段:
from elasticsearch.helpers import bulk, pack_dense_vector
def get_next_document():
for doc in dataset:
yield {
"_index": "my-index",
"_source": {
"title": doc["title"],
"text": doc["text"],
"emb": pack_dense_vector(doc["emb"]),
},
}
result = bulk(
client=client,
chunk_size=chunk_size,
actions=get_next_document,
stats_only=True,
)与使用浮点数进行批量摄取的唯一区别在于,embedding 现在被包裹在 pack_dense_vector() 辅助函数中。
结论
通过将 JSON 浮点数组切换为 Base64 编码向量,我们消除了 Elasticsearch 向量摄取管道中剩余的最大瓶颈之一:数字解析。这个简单的改动带来了巨大的效果:对于 DiskBBQ 工作负载,吞吐量可提升至 2×,即使对于较慢的索引策略(如 HNSW)也能获得显著提升。
由于向量已经以二进制格式内部存储,并默认从 _source 中排除,因此这一改进在搜索时完全透明。在 v9.3 中官方客户端支持到位后,采用 Base64 编码只需对现有摄取代码进行最小改动,同时即可获得即时性能提升。
如果你要索引大量 embeddings,尤其是在高吞吐量或 serverless 环境中,Base64 编码向量现在是将数据快速高效导入 Elasticsearch 的最佳方式。有关实现细节,可参考相关 Elasticsearch issue 和 pull request:#111281 和 #135943。
原文:https://www.elastic.co/search-labs/blog/base64-encoded-strings-vector-ingestion