简介:
时间:2025
会议:CVPR
作者:Ruopeng Gao,Ji Qi,Limin Wang
摘要:
传统多目标跟踪方法在目标关联阶段严重依赖人工设计的启发式规则,难以适应复杂场景
将MOT重新表述为一种 in-context 的 ID 预测问题,并构建一个端到端可训练的框架 MOTIP
不依赖复杂的匹配策略,仅使用目标级特征即可在多个数据集上达到很好的效果
创新点:
①将MOT中的目标关联问题,从传统的"相似度计算 + 匹配"重新建模为 in-context ID prediction(上下文 ID 预测)问题。
②通过"随机分配 ID 作为上下文提示"的方式,避免传统分类式 ReID 在测试阶段遇到未见 ID 的泛化问题,使训练与推理过程保持一致。
③不引入复杂的多阶段匹配,仅由 DETR 检测器、可学习 ID 字典和 Transformer 解码器组成。
④通过模拟遮挡和 ID 错误,缓解训练阶段与推理阶段间的差异,提高模型鲁棒性。
引言:
传统 Tracking-by-Detection 的局限:
①启发式方法难以泛化
②端到端方法的"新问题",detection query 和 tracking query 监督信号冲突
③ReID 的训练/推理 不一致
相关工作:
Tracking-by-Detection 方法:
TBD通常结合运动模型和外观特征进行目标关联,但关联决策本身仍依赖手工规则
MOTIP 在结构上仍保持检测与关联的解耦,但完全用可学习模型取代了人工设计的匹配决策
Tracking-by-Propagation 方法:
以 DETR 为代表, detection 与 tracking 在同一模块中处理会引入不可避免的冲突
MOTIP 同样使用 DETR 作为检测器,但其检测与关联是在两个独立模块中顺序完成的
方法:
In-context ID Prediction 的问题建模:
在传统做法中,目标关联被视为相似度计算问题,而在训练阶段使用 ID 分类监督、推理阶段再退回相似度匹配。
这一不一致性源于 ID 泛化问题:测试阶段会出现训练中未见过的新 ID。这一问题的根源在于错误地将 MOT 的 ID 当作"固定类别"。
实际上,在 MOT 中:①轨迹的 ID 数值本身并不重要②只要在时间上保持一致即可视为正确。
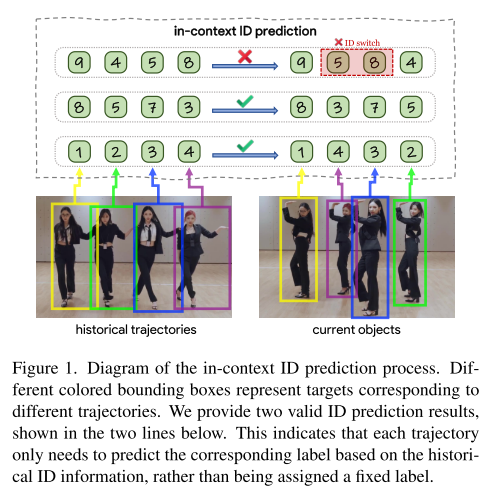
基于这一观察,提出如下建模方式:

为每条历史轨迹随机分配一个 ID 标签 :
当新一帧到来时,模型只需预测当前目标应当继承哪一个已有轨迹所携带的 ID 提示,由于 ID 仅作为上下文提示(prompt),而非全局固定语义标签,该方法在训练与推理阶段保持了预测空间的一致性,从而自然解决了 ID 泛化问题。
MOTIP 的整体架构:
MOTIP 的整体结构非常简洁,由三部分组成:
①DETR 检测器(可端到端训练;Transformer decoder 的输出 embedding 可直接作为目标级特征,无需额外 ReID 头或 RoI 操作)
②ID Dictionary:
引入一个可学习的 ID 嵌入字典:

其中,前 K 个嵌入表示轨迹身份提示, 表示新生目标(newborn)。相比 one-hot 编码,连续嵌入更利于训练,也不限制 ID 数量扩展。
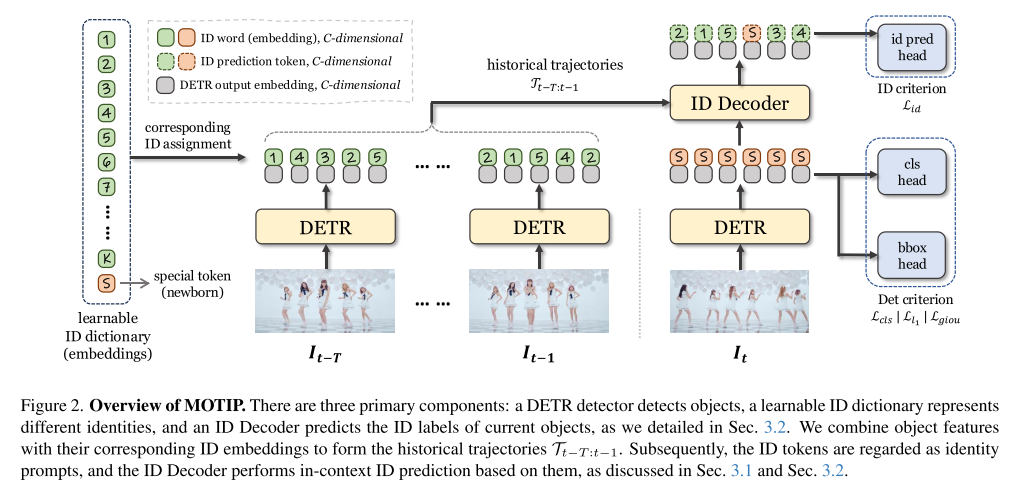
③Tracklet 构造与 ID Decoder:
对历史轨迹中每一帧的目标特征,与其对应的 ID 嵌入
进行拼接:

当前帧目标则与 special token 拼接。所有历史轨迹 token 作为 Key / Value,当前目标作为 Query,输入 Transformer Decoder,最终输出对 K+1 个 ID 的分类结果。
训练策略:
整体损失函数由检测损失与 ID 预测损失组成:

为缓解训练与推理阶段历史轨迹质量不一致的问题,提出两种轨迹增强策略,以提升了模型在复杂场景下的鲁棒性:
①随机遮挡(token dropout),模拟遮挡
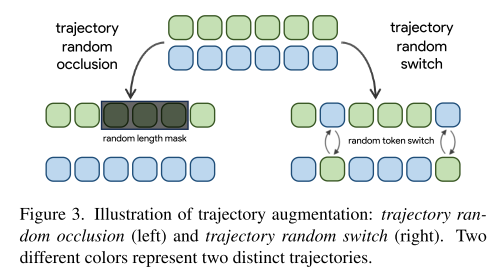
②随机 ID 交换,模拟推理阶段的 ID 错误
推理过程:
推理阶段流程极为简洁:
①对每个检测目标选择 ID 预测概率最大的标签
②若置信度不足或发生重复 ID,则标记为新生目标
③刻意未引入 Hungarian 算法,以验证模型自身的关联能力
实验:
在 DanceTrack、SportsMOT 和 BFT 等高难度数据集上进行了实验,使用 HOTA、AssA、IDF1 等指标评估性能。实验结果表明,MOTIP 在关联准确率(AssA)上取得了显著提升,尤其在遮挡频繁、目标高度相似的场景中优势明显。

结论:
本文提出将多目标跟踪重新建模为 in-context ID prediction 问题,并据此设计了简洁而有效的 MOTIP 框架。实验结果表明,即使不依赖复杂的匹配策略或启发式规则,该方法仍能在多个基准数据集上达到或超过现有最优水平。