概述
本文章旨在为政务信息化开发者提供一份详细的指南,介绍如何使用 openJiuwen 开源平台,快速搭建并部署一个具备智能业务识别与分流能力的政务AI智能体(Agent)。我们将以构建一个"政务通小助手"智能体为例,完整演示从环境准备、模型配置、工作流(Workflow)编排到智能体绑定与测试的全过程。openJiuwen 通过可视化的界面,极大地降低了复杂AI应用逻辑的开发门槛,是构建智慧政务助手、智能客服、多部门业务协同应答机器人的强大工具。

第一章:环境准备与平台部署
在开始构建智能体之前,我们需要确保下载最新的openJiuwen v0.1.3版本包,并推荐使用 docker 进行容器化部署,这能保证环境的一致性和便捷性。
1.1 获取资源
- 官方代码仓库 :
https://atomgit.com/openJiuwen。这里是项目的开源地址,开发者可以查阅源代码、提交Issue或参与贡献。 - 官方网站与文档 :
https://www.openjiuwen.com。获取最新的产品信息、详细的安装指南、配置文档和社区支持。
1.2 部署安装
本节概述部署步骤,详尽说明请参阅官网安装文档。
- 下载平台 :访问 openJiuwen 下载页面,获取最新的部署包v0.1.3版本。
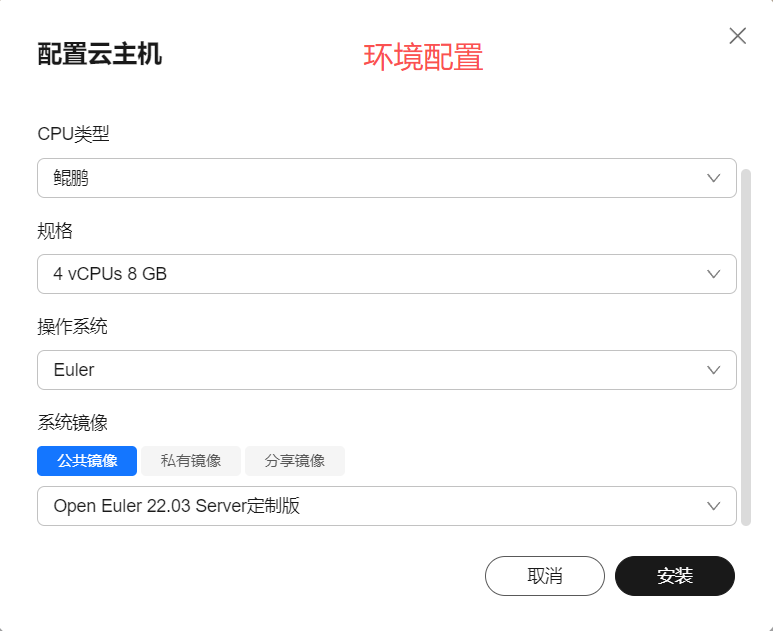
2 操作系统 :本次部署使用的是openEuler系统,配置如下
3 安装依赖 :确保宿主机已安装 Docker 和 Docker Compose。这是运行 openJiuwen 所有服务的唯一前提。
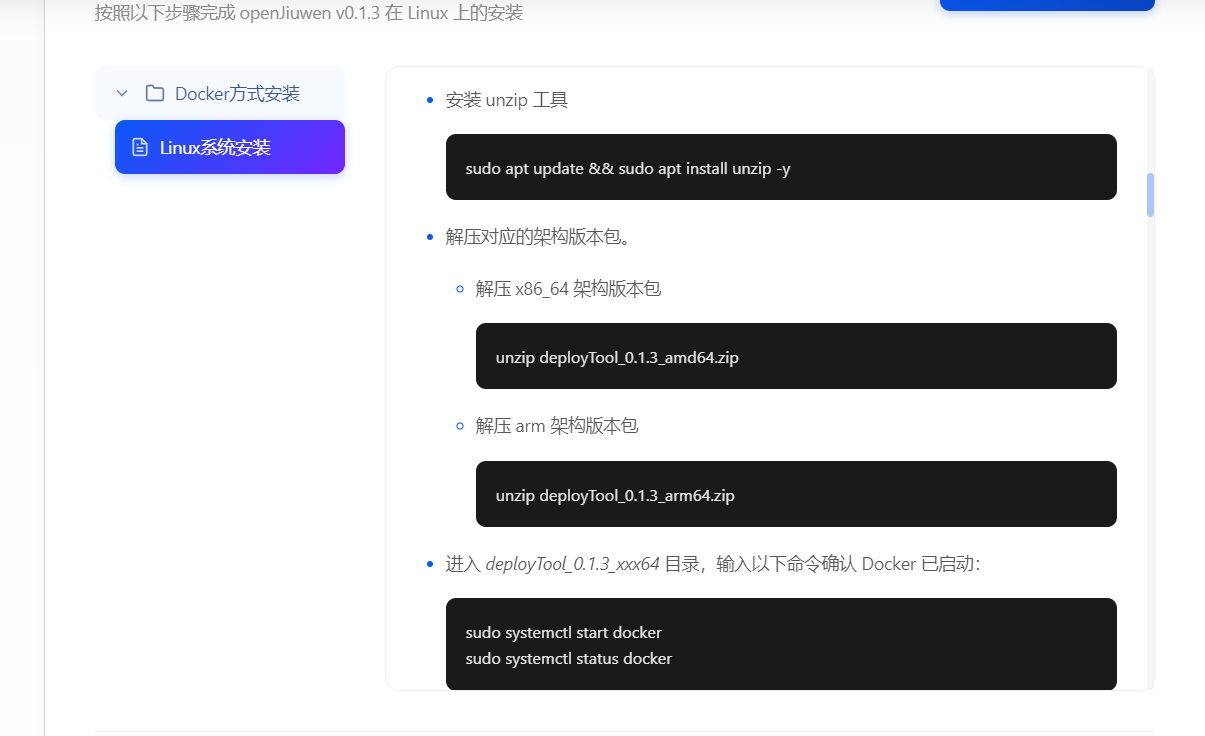
4、解压架构包 :解压对应架构包
-
启动服务 :解压部署包,进入
openJiuwen项目根目录,执行启动命令。bash./service.sh up此脚本将自动拉取所有必要的Docker镜像(包括前端、后端、数据库等)并启动容器组。
-
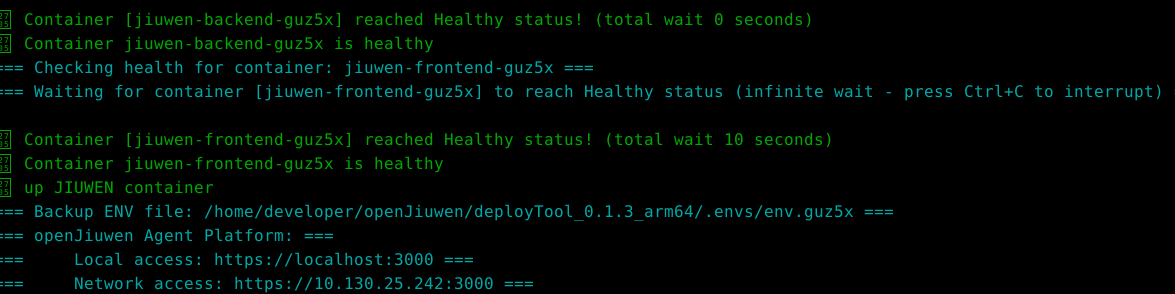
访问验证 :待所有服务启动成功后,在浏览器中访问
https://localhost:3000。首次访问可能会看到安全警告(因使用自签名证书),选择"继续前往"即可。看到登录界面,说明平台部署成功。
第二章:基础模型配置
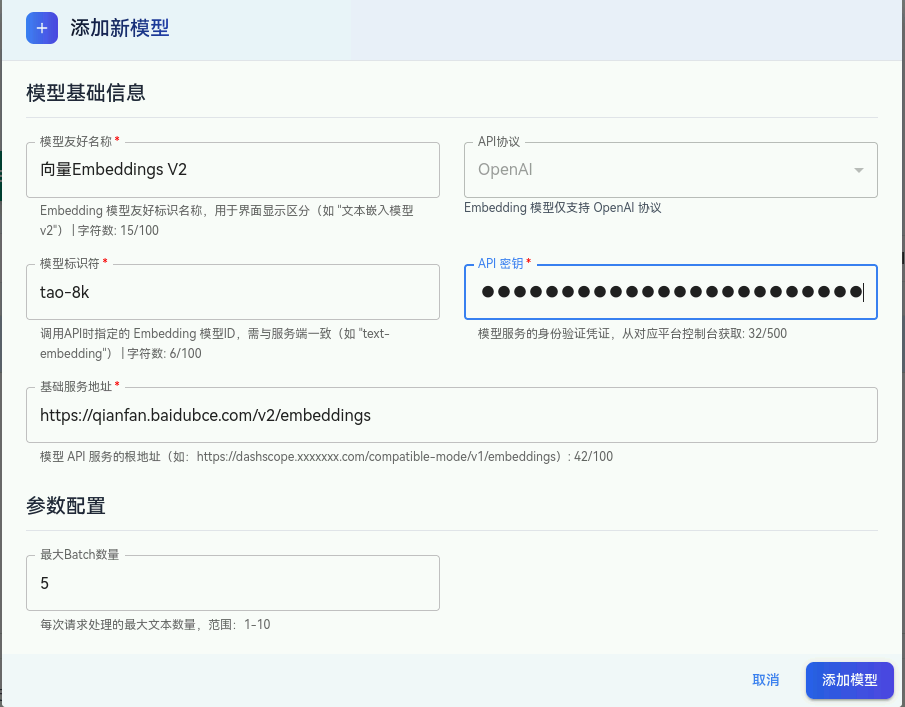
openJiuwen 的核心能力依赖于大语言模型(LLM)和嵌入模型(Embedding)。在构建工作流前,必须先在平台中配置这些模型连接。
2.1 添加 LLM 模型
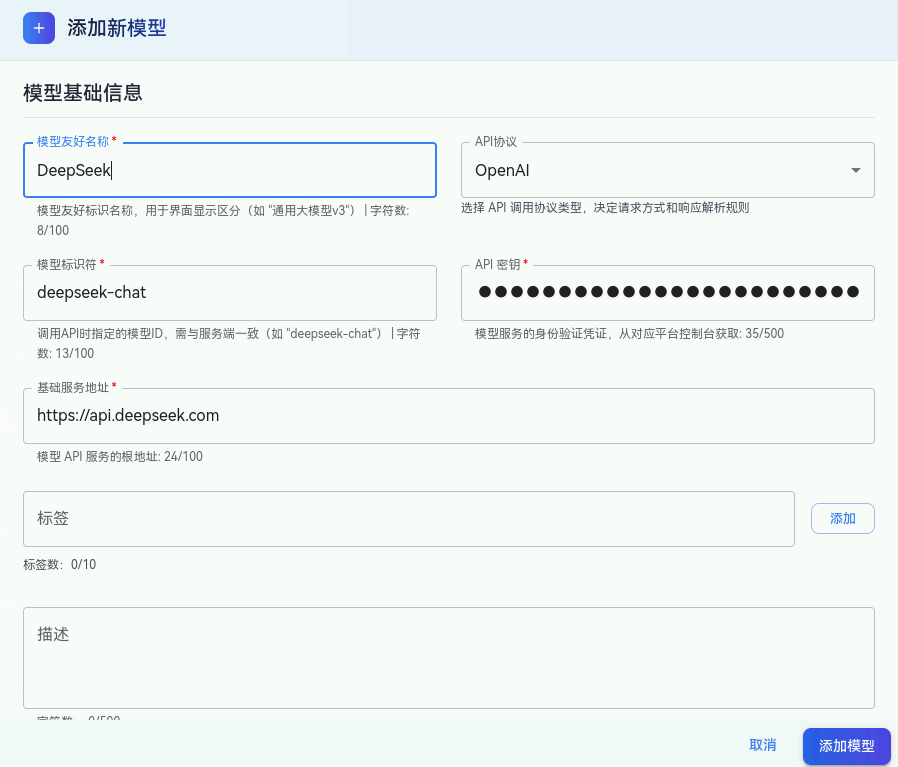
大型语言模型是智能体思考与对话的"大脑"。openJiuwen 支持对接多种开源和商业化模型API,特别适合需要理解复杂政策条款的政务场景。
- 操作路径:平台管理后台的"模型配置"模块。
- 关键配置 :根据您选择的模型提供商(如 华为、讯飞星火、文心一言、通义千问、GPT等),填写相应的
API Base URL、API Key以及Model Name。 - 目的 :为后续工作流中的"业务识别节点"和"各部门专业应答节点"提供可用的模型实例。
2.2 添加 Embedding 模型
嵌入模型用于将文本转换为高维向量,是实现政策文件精准检索、相似问题匹配、知识库管理等功能的基础。
- 操作路径:与LLM配置位于同一区域。
- 关键配置:填写对应模型的接入信息。
- 目的 :为后续集成各部门政策知识库、构建记忆库等需要向量化处理的节点提供支持。
第三章:构建"政务智能分流"工作流
工作流是openJiuwen的灵魂,它将多个AI处理节点通过逻辑连接起来,形成一个完整的处理管道。我们将构建一个能根据市民/企业咨询内容,自动识别业务归属并分发给不同业务科室(如耕保科、市政科等)进行智能应答的工作流。
3.1 创建与进入工作流
- 在"工作流"模块中,点击"添加工作流",为其命名,例如 "Government_Service_Routing"。
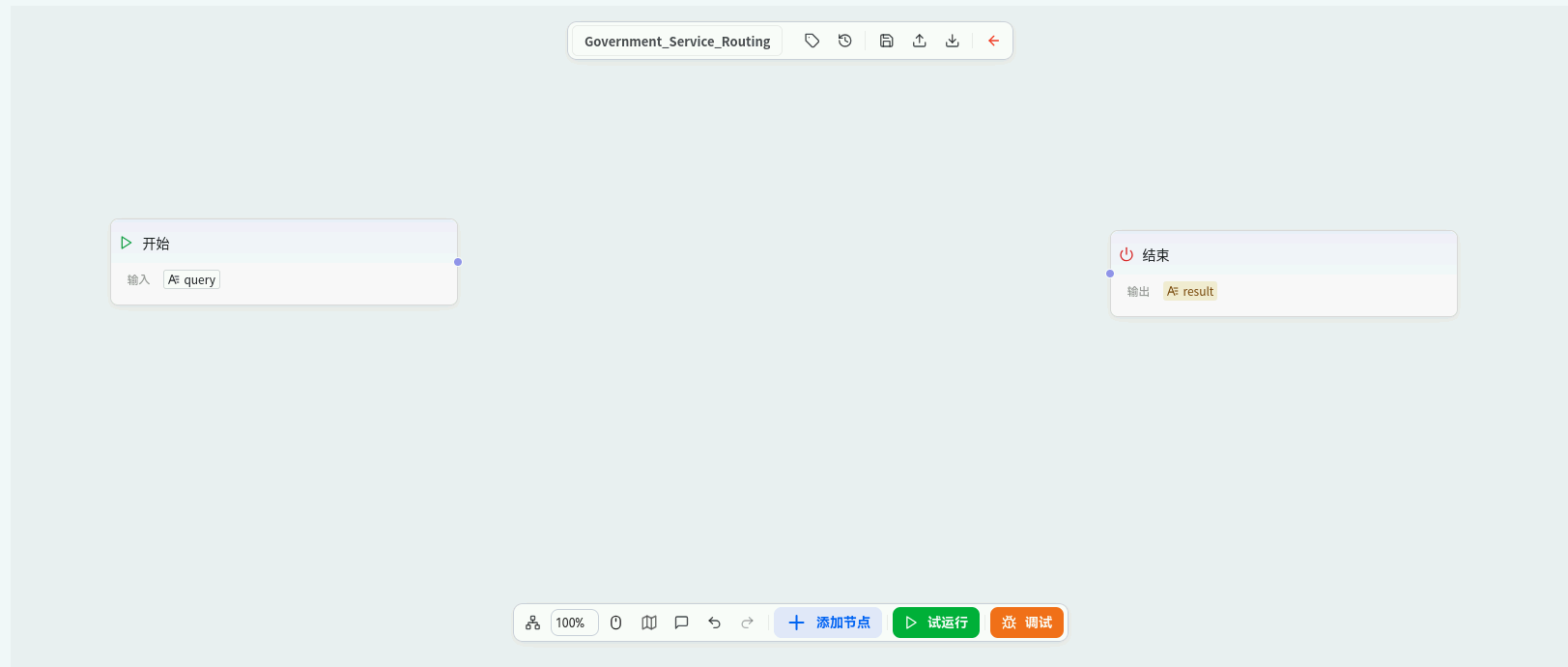
- 进入该工作流的编辑画布,这是一个可视化的拖拽编排界面。
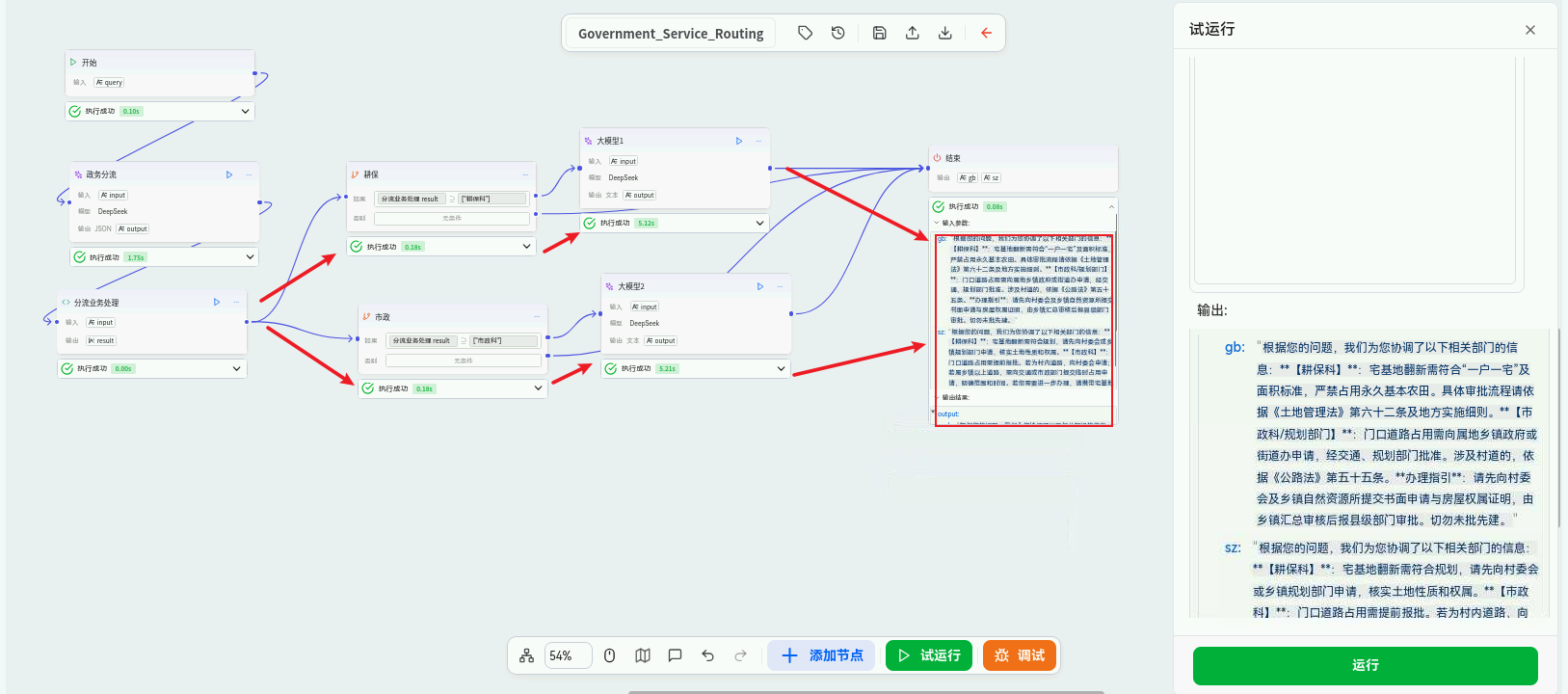
工作流编辑画布
3.2 设计工作流节点
一个高效的"政务智能分流"工作流通常包含以下逻辑层:
-
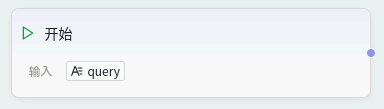
输入层(开始节点):
- 节点 :
Start节点。 - 作用 :作为工作流的唯一入口,接收来自智能体的用户咨询(
User Query)。例如:"我想咨询一下宅基地确权需要哪些材料?"或"小区门口的树木倒了,向哪个部门反映?"。 - 配置 :定义输入变量名,如
query。
- 节点 :
-
业务识别与科室分类层(分类LLM节点):
- 节点 :
Large Language Model (LLM)节点。 - 作用 :这是工作流的"智能调度中心"。它深度分析用户咨询的自然语言描述,精准识别其业务类型和可能涉及的科室,支持单科室或多科室关联识别。这是实现精准分流和协同应答的关键。
- 配置 :
- 选择已配置好的LLM模型。
- 编写精炼的 系统提示词(System Prompt) ,例如:"你是一个政务业务分类专家。请分析用户咨询,判断其主要涉及以下哪个或哪几个科室:1. 耕保科(负责耕地保护、宅基地、土地规划等),2. 市政科(负责道路、绿化、排水、路灯等公共设施),3. 市场监管科,4. 社会保障科,5. 其他科室。请输出格式为JSON:
{"departments": ["科室A", "科室B"]}。若无明确对应,则为"其他科室"。" - 将开始节点的
query变量作为用户输入(User Prompt)传入。
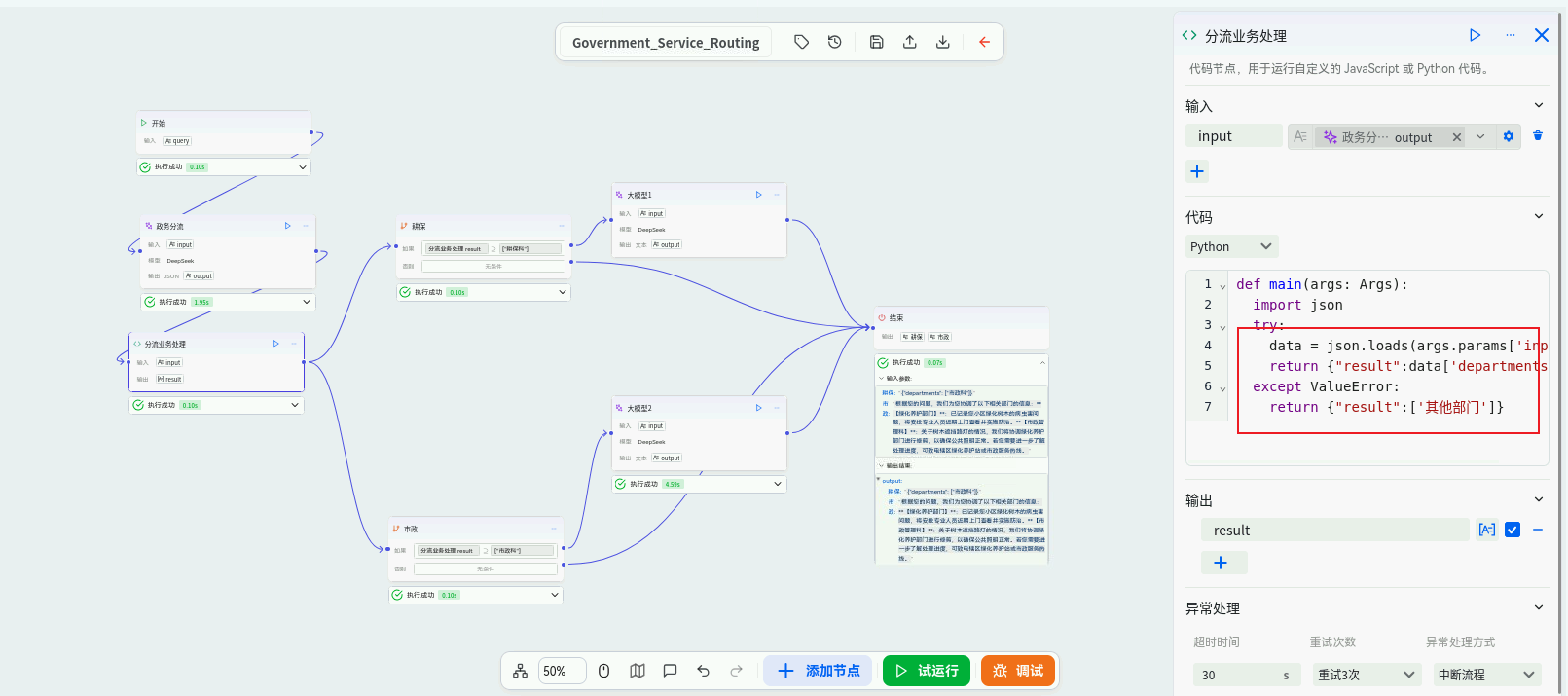
- 节点 :
-
逻辑路由与并行处理层(循环与条件节点):
- 节点组合 :
Iterator(循环) 节点 + 内部IF/Else或Switch节点。 - 作用 :接收上一步LLM输出的科室列表(如
["耕保科", "市政科"]),通过循环节点遍历列表。针对每个科室,使用条件节点将其路由到对应的专业应答分支,实现并行或串行处理。 - 配置 :
Iterator节点:输入为分类LLM输出的departments数组。- 内部
Switch节点:根据当前循环项(如"耕保科")进行路由。
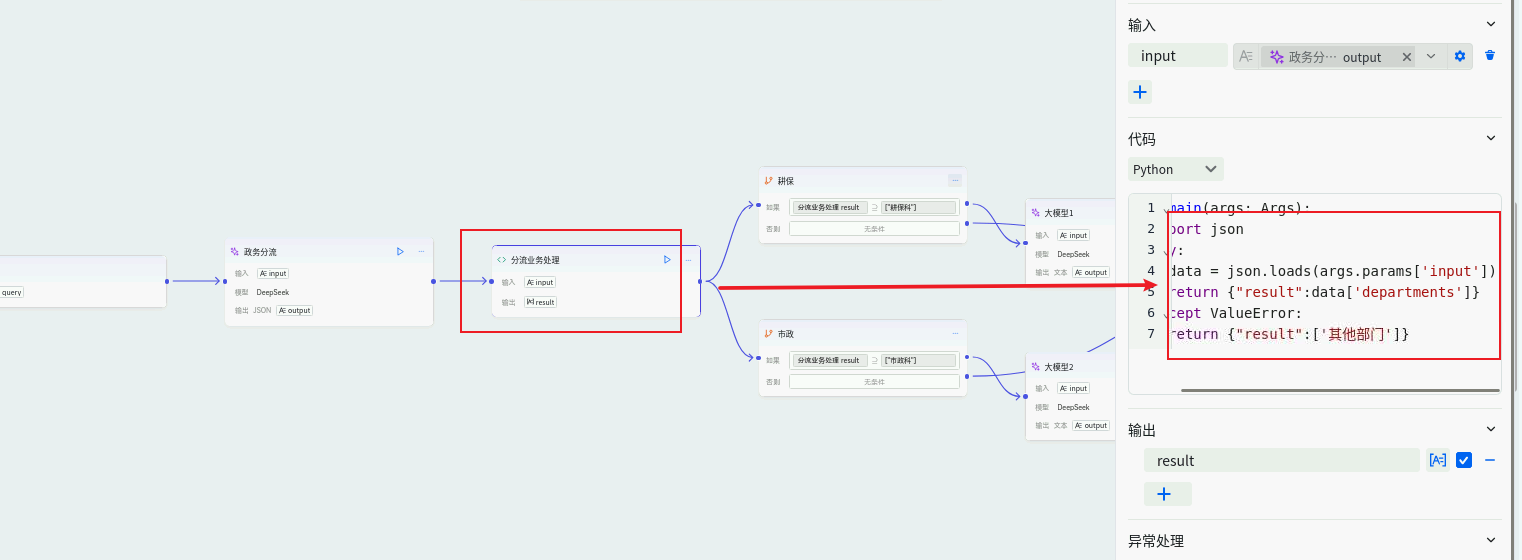
- 节点组合 :
-
科室专业应答层(多个专用LLM与知识库节点):
- 节点 :多个并联的
Large Language Model (LLM)节点,每个节点代表一个科室,并可选择挂载该科室的专属 知识库。 - 作用:在每个科室分支上,由专属的LLM节点扮演该科室政策专家的角色进行回复。知识库中预存了该科室的政策文件、办事指南、常见问题等,确保回复的专业性和准确性。
- 配置 :
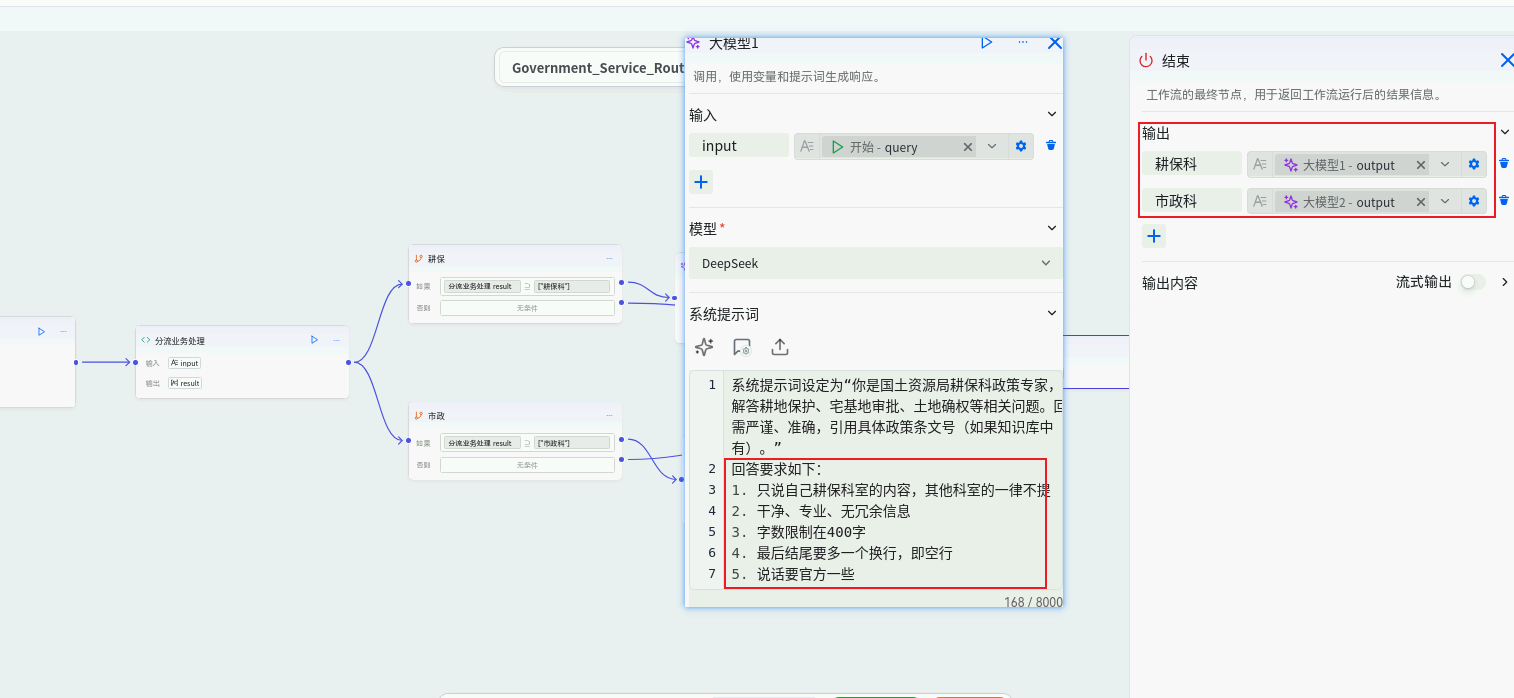
- 耕保科节点:系统提示词设定为"你是国土资源局耕保科政策专家,负责解答耕地保护、宅基地审批、土地确权等相关问题。回答需严谨、准确,引用具体政策条文号(如果知识库中有)。"
- 市政科节点:系统提示词设定为"你是市政管理科工作人员,负责解答道路维修、绿化养护、排水疏通、公共照明等市政设施相关问题。回答应具体、可操作。"
- 其他科室节点:以此类推。
- 知识库挂载 :在LLM节点前或节点设置中,添加"知识库检索"节点,并选择对应科室的知识库。
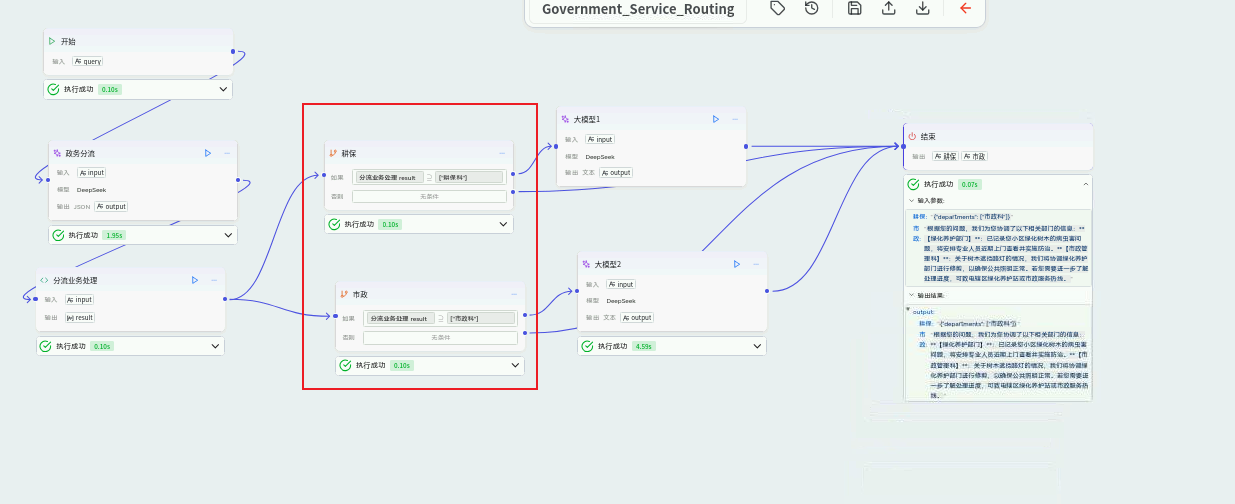
- 节点 :多个并联的
-
应答整合与格式化输出层(结束节点):
- 节点 :
End节点。 - 作用 :收集来自各个科室分支的回复,进行梳理和整合,形成结构清晰、语气统一的最终答复,返回给用户。
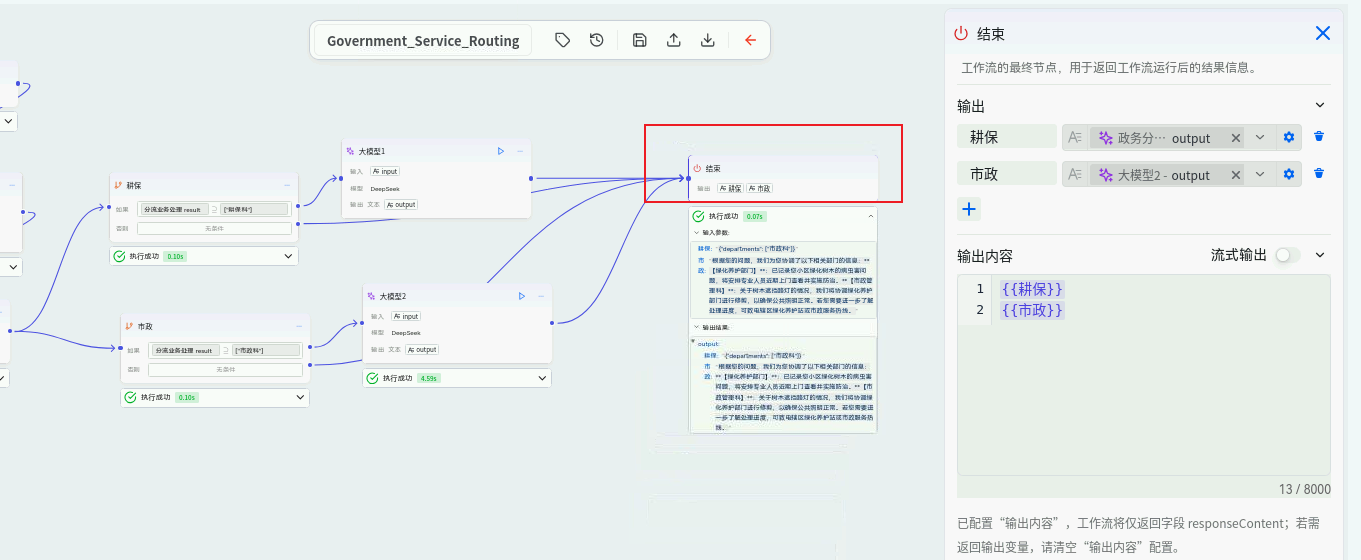
- 节点 :
3.3 工作流测试与调试
openJiuwen 提供了强大的"试运行"功能,允许在发布前对工作流进行单元测试。
-
点击画布上的 "试运行" 按钮。
-
在输入框中键入测试咨询,例如:"我家老宅翻新,涉及宅基地和门口道路占用,该怎么办?"
-
观察执行过程。您可以清晰地看到流程如何经过分类LLM(输出
{"departments": ["耕保科", "市政科"]}),如何通过循环并行或串行触发两个科室的应答节点,并最终生成整合回复。
-
调试与优化:如果输出不符合预期(如科室识别错误、回复不专业),返回检查分类LLM节点的提示词、各科室知识库的完整性,以及应答LLM的系统角色设定,进行微调。
第四章:创建与绑定政务智能体
工作流是后台的"智能处理引擎",而智能体(Agent)则是面向公众的"政务服务窗口"。我们需要创建一个智能体来暴露这个功能。
4.1 创建智能体
- 进入"智能体"模块,点击"创建智能体"。
- 填写基本信息:名称(如"政务通小助手")、描述(例如:"为您提供精准的业务咨询与智能分流服务")、选择政务风格的头像等。
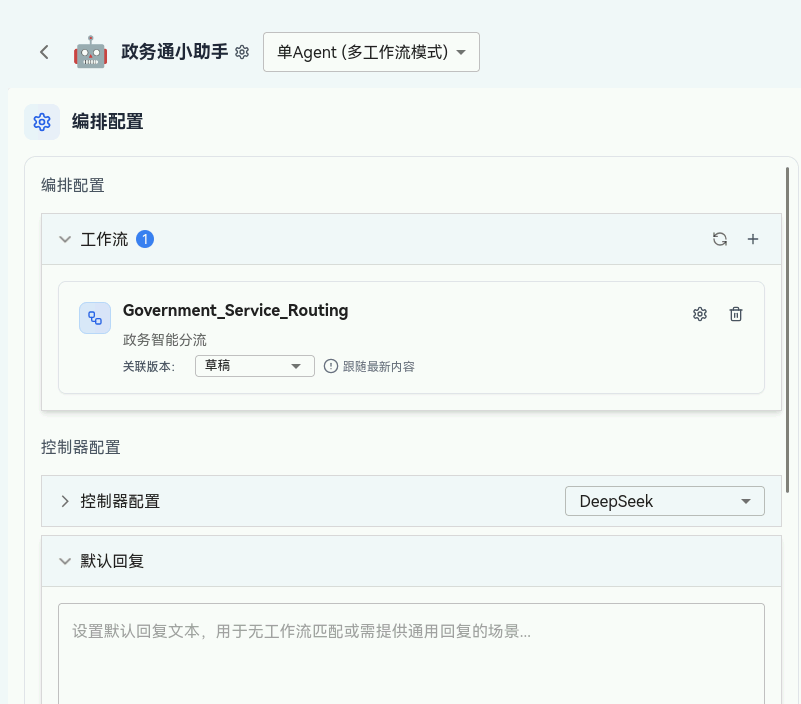
4.2 绑定工作流引擎
这是连接前端服务窗口与后台智能处理引擎的关键一步。
- 在智能体的编辑页面,找到"推理引擎"或"关联工作流"配置项。
- 从下拉列表中选择我们刚刚创建并测试通过的 "Government_Service_Routing" 工作流。
- 保存配置。这意味着所有发送给该智能体的公众咨询,都将被转发给这个工作流进行智能识别与分流处理。
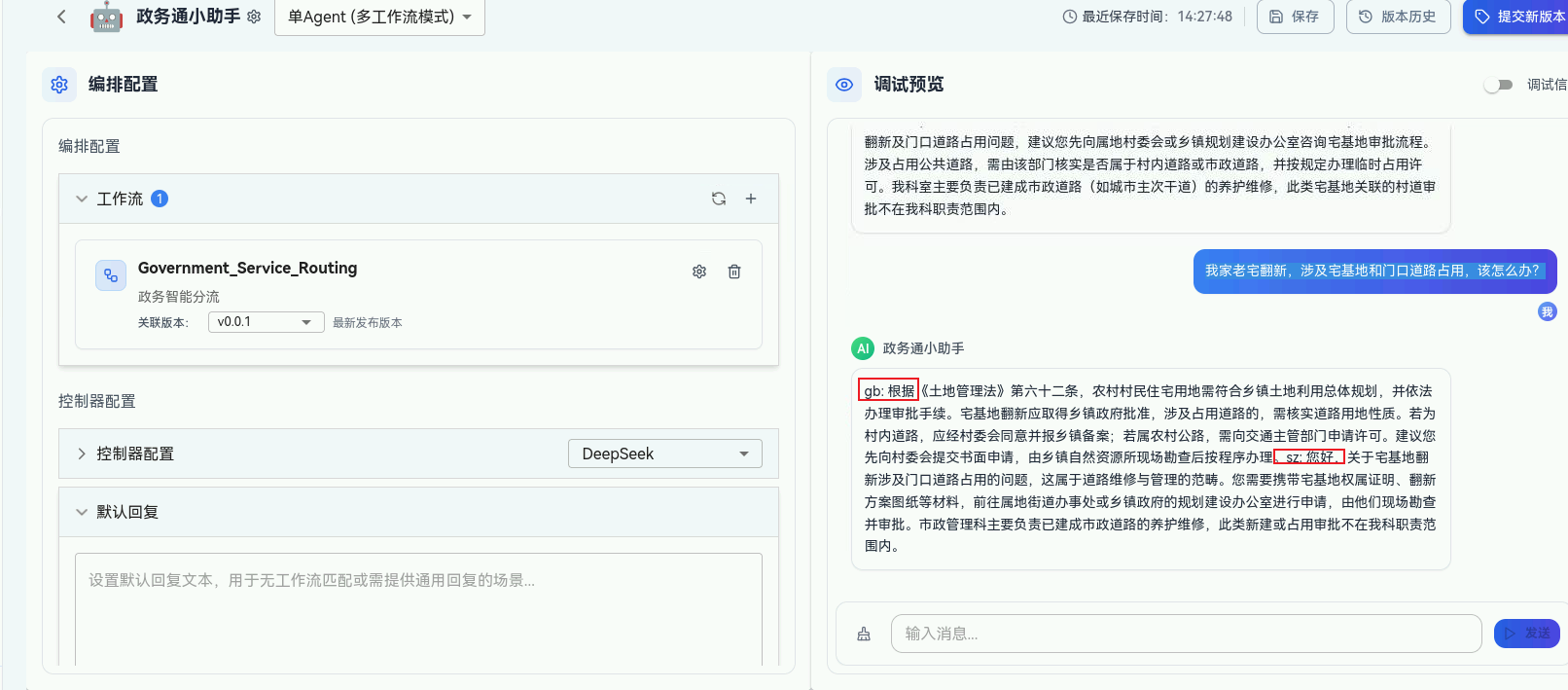
4.3 端到端测试与最终优化
-
在智能体的聊天窗口进行最终集成测试。
- 初始测试:输入"我想办理农村建房规划许可证",检查回复是否专业,是否来自耕保科,内容是否清晰。
- 多部门测试 :我家老宅翻新,涉及宅基地和门口道路占用,该怎么办?",检查回复是否同时包含了市政科,耕保科的解答,且整合得当。
-
问题诊断与修复:如果回复出现格式混乱、科室前缀残留或知识库未命中等问题,解决方案是:
- 返回工作流,检查 结束节点的输出模板,确保其能正确处理多部门输入并优雅格式化。
- 优化各科室 LLM节点的系统提示词 ,明确要求其以"本科室答复:"或直接给出纯政策解答。
-
验证修复 :再次在智能体界面进行多轮测试,确认回复精准、专业、格式统一,符合政务服务标准。

第五章:总结与拓展思考
通过以上步骤,我们成功利用 openJiuwen 平台构建并部署了一个具备智能业务识别、多部门协同应答能力的政务AI智能体。这个过程充分展示了低代码AI平台在提升政务服务效率和智能化水平方面的巨大潜力。
- 核心价值:openJiuwen 将复杂的AI管道与政务业务逻辑解耦,通过可视化编排,使业务专家和开发者能共同快速构建符合实际需求的智能应用,无需陷入复杂的代码开发。
- 工作流模式 :本项目演示的 "智能识别 -> 并行路由 -> 专业应答 -> 结果整合" 是一种高度可复用的政务AI工作流模式,可轻松拓展到更多场景,如:
- "一网通办"智能导办:根据用户模糊描述,精准定位要办理的事项,并生成个性化材料清单和办理路径。
- 政策精准推送与解读:分析企业基本信息,自动匹配可享受的优惠政策,并由对应科室模型进行解读。
- 多渠道诉求智能分派:整合热线、网站、新媒体留言,统一识别后分派至12345平台或各委办局内部系统。
- 进阶优化方向 :
- 知识库深度集成:为每个科室节点集成更全面的政策法规库、案例库和办事流程库,利用RAG技术确保答复的时效性与准确性。
- 流程自动化衔接:在应答节点后,接入**工具调用(Tool Calling)**节点,对于可在线办理的业务,直接生成预填表单或跳转链接,实现"问答即办事"。
- 多轮对话与记忆:引入"对话记忆"节点,支持复杂业务的多轮咨询,能记住用户上下文(如之前提过的企业名称、地址),提供连贯服务。
- 效能评估与优化:对分类模型的准确率、各科室知识库的命中率进行监控,持续迭代提示词和知识库内容,并可通过接入更快的分类模型来优化整体响应速度。