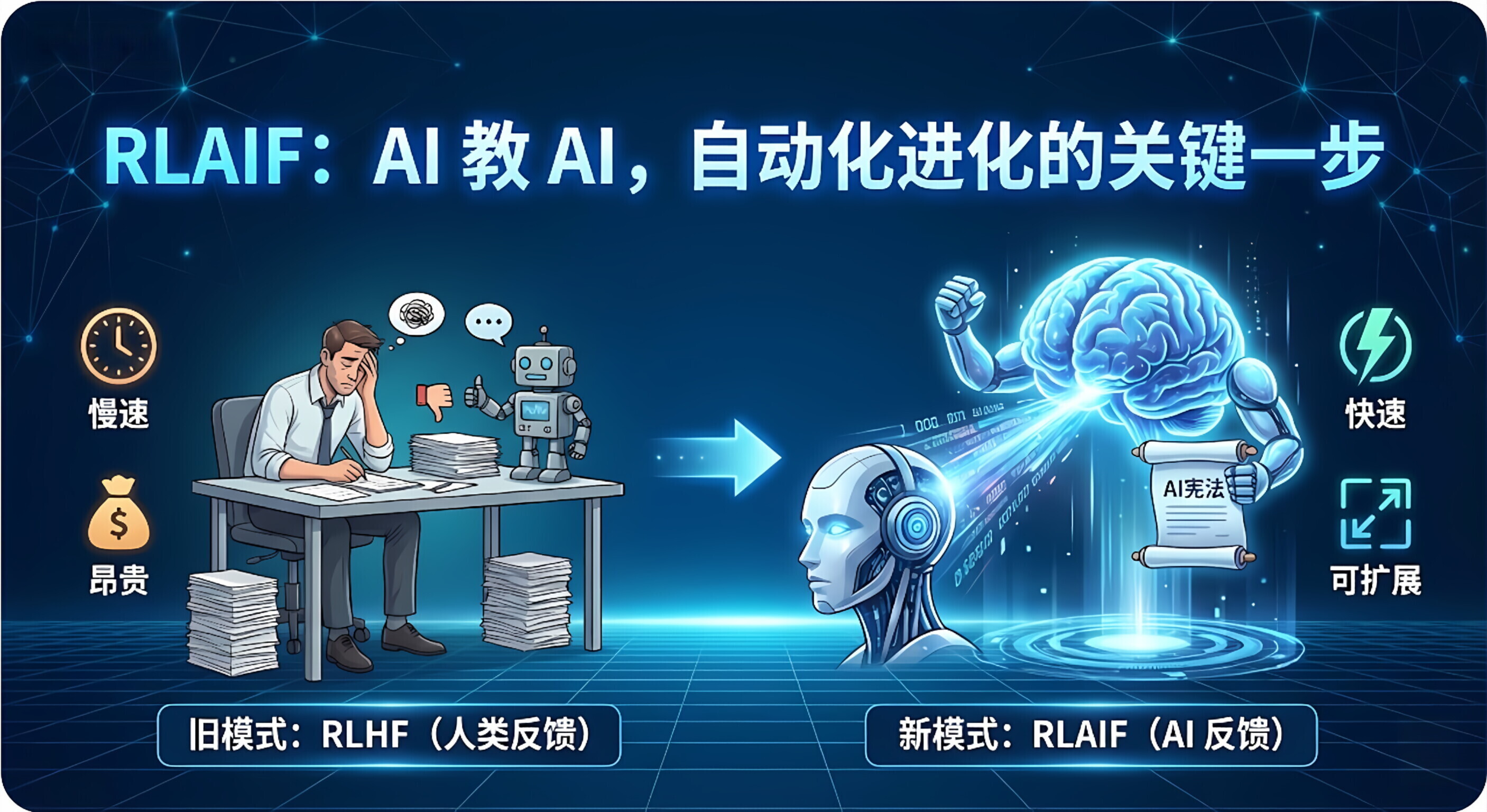
RLAIF 是 Reinforcement Learning from AI Feedback(基于 AI 反馈的强化学习)的缩写。
它是为了解决 RLHF(基于人类反馈的强化学习)太贵、太慢、太难扩展而诞生的一种技术。
简单来说,RLHF 是"人类教 AI",而 RLAIF 是"AI 教 AI"(或者叫"以AI为师")。
1.🔄 核心背景:为什么不想用人类了?
在 RLAIF 出现之前,训练大模型(如 GPT-3.5)的最后一步必须由人类介入:
-
RLHF 的瓶颈:
-
太贵:雇佣成千上万的博士或受过教育的标注员来给 AI 的回答打分,每小时要花很多美金。
-
太慢:人类要睡觉、会疲劳,标注速度赶不上 AI 的训练速度。
-
不一致:不同的人类有不同的价值观,张三觉得好的回答,李四觉得不好,导致数据"打架"。
-
于是,工程师们想:"既然现在的 AI(比如 GPT-4 )已经这么强了,为什么不让最强的 AI 来代替人类,给弱一点的 AI 打分呢?"
这就是 RLAIF。
2.⚙️ RLAIF 是怎么工作的?
它的流程和 RLHF 几乎一模一样,唯一的区别是把"人类标注员"换成了"AI 标注员"。
-
生成回答:
- 让待训练的模型(学生)针对一个问题生成两个不同的回答(回答 A 和 回答 B)。
-
AI 打分 (AI Feedback):
-
请出一个更强的模型(老师,或者是加载了"宪法"的同一模型),给它看这两个回答。
-
Prompt 指令:"请根据'有用性'和'无害性'原则,判断回答 A 和回答 B 哪个更好?"
-
老师 AI:"我认为回答 A 更好,因为回答 B 包含了一些不准确的信息。"
-
-
强化学习:
- 利用这个反馈信号(Reward Signal)来调整学生模型的参数,鼓励它多生成像回答 A 那样的内容。
3.⚖️ RLHF vs. RLAIF
|------|--------------|-------------------------------------------|
| 维度 | RLHF (人类反馈) | RLAIF (AI 反馈) |
| 打分者 | 真人 (Human) | 大模型 (AI) |
| 成本 | 极高 (按小时付费) | 极低 (按 GPU 电费/Token 计费) |
| 速度 | 慢 (受限于人类生理) | 极快 (24 小时并行处理) |
| 可扩展性 | 难 (招人很难) | 易 (加显卡就行) |
| 应用案例 | ChatGPT 早期版本 | Claude (Constitutional AI), Google Gemini |
4.🧠 为什么它能行得通?
你可能会担心:"让 AI 教 AI,会不会近亲繁殖,越教越傻?"
研究表明(如 Google 和 Anthropic 的论文),只要作为"老师"的 AI 足够强,或者给它的指令 (Prompt/宪法)足够清晰,RLAIF 的效果并不比人类差,甚至在某些客观任务上比人类更稳定。
- 宪法 AI (Constitutional AI) 就是 RLAIF 的一种极致形式:我们只给 AI 一本"宪法"(原则),让 AI 根据宪法自己给自己打分,完全不需要人类介入打分过程。
5.🚀 终极意义:监管"超级智能"
RLAIF 的出现不仅仅是为了省钱,它还有一个更深远的意义:超级对齐 (Superalignment)。
-
现状:现在的 AI 水平接近人类,人类还能看懂 AI 在说什么,还能给它打分。
-
未来 :如果未来出现了比爱因斯坦聪明 1000 倍的 超级人工智能 (ASI) ,它生成的复杂方案,人类可能根本看不懂。
-
结论 :那时候,人类已经没有资格给 AI 判卷子了。我们只能依靠一个被人类信任的 AI(RLAIF)去监督另一个超级 AI。
总结
RLAIF 是 AI 迈向自动化进化的关键一步。
它把人类从繁重的"判卷子"工作中解放出来,让人类只需要负责制定"教学大纲"(编写 Prompt/宪法),剩下的教学工作,全部交给 AI 自己完成。这是 AI 工业化、规模化生产的必经之路。