我是@iFeng的小屋。
一、爬取目标
之前我分享过不少平台的爬虫,像B站、懂车帝、携程网这些,爬评论、爬数据都没问题。
很多人想研究爆款笔记、做竞品分析,或者收集素材,手动一篇篇看效率太低。所以,我写了这个小红书笔记搜索爬虫。
这个脚本它能根据你给的关键词 ,批量搜索并下载相关笔记,正文、互动数据、发布时间。
二:数据结果图展示
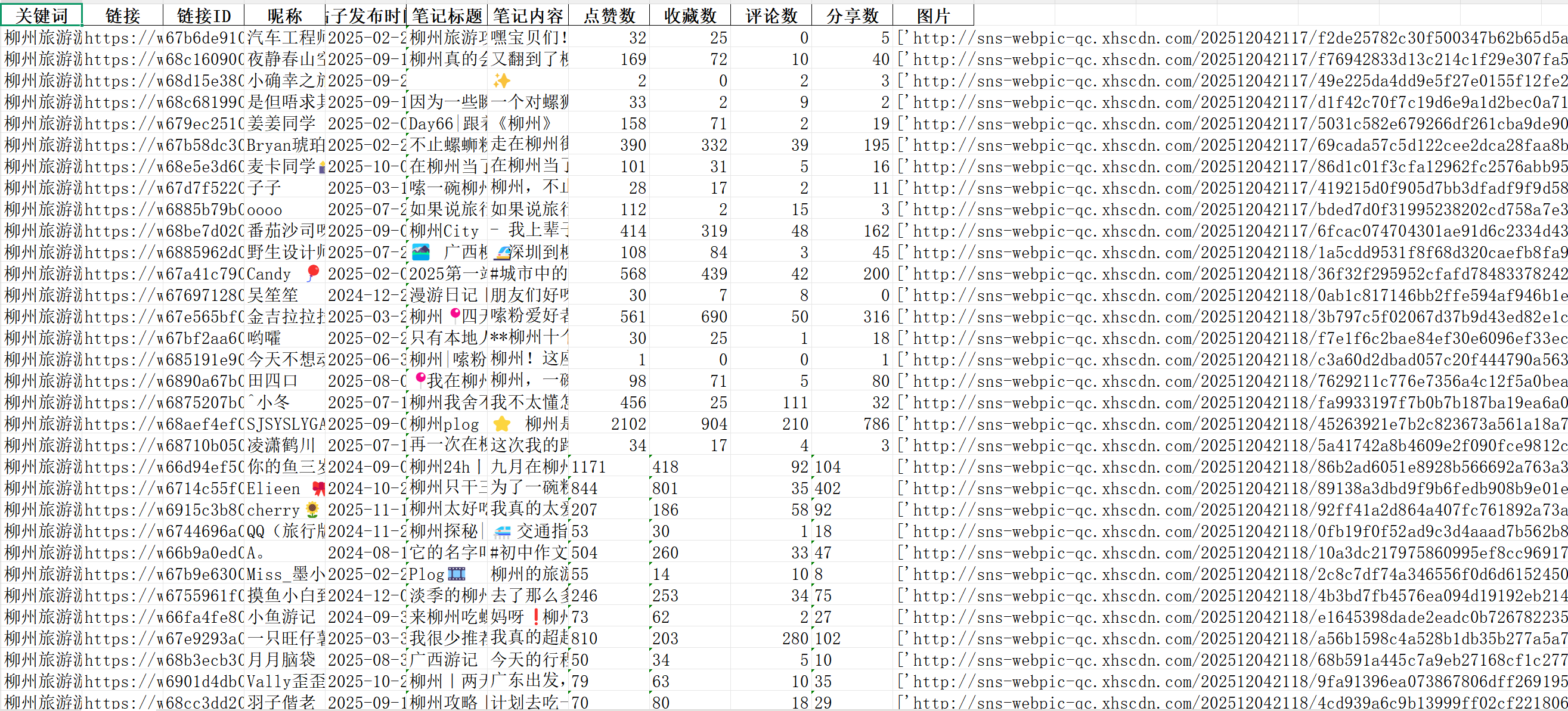
字段:关键词,链接,链接ID,昵称,帖子发布时间,笔记链接,笔记内容,点赞数,收藏数,评论数,分享数,图片链接.
所有数据自动保存为Excel文件,干净整齐,拿去即可食用!但注意一个关键词只能爬取220条评论哦(网页版)。
原理讲解:
-
核心是调用小红书的搜索接口,它是一个
POST请求。 -
你需要准备一个有效的 cookie(从网页版小红书获取),这是能拿到数据的关键。
-
通过接口拿到笔记ID列表后,再逐个去访问笔记的详情页。
三:爬虫代码讲解
导入库:
python
import requests
import pandas as pd
import json
import time
from datetime import datetime
from lxml import etree3.1 核心思路与配置
运行这个需要关键参数:cookie。这需要你登录小红书网页版,在开发者工具里抓取。
为了方便管理多个关键词和Cookie,我设计了用Excel文件来配置:
-
搜索词.xlsx:一行一个,放你想搜的关键词。 -
cookie.xlsx:一行一个,放你的cookie(程序支持多个cookie自动切换)。
python运行
3.2 关键步骤:搜索并翻页
这是向小红书搜索接口发送请求的核心,可以按"最新"、"综合"等方式排序。
python
json_data = {
'keyword': '春日穿搭', # 你的关键词
'page': 1, # 第几页
'page_size': 20, # 每页20条
'sort': 'time_descending', # 按最新排序
}
response = requests.post('https://edith.xiaohongshu.com/api/sns/web/v1/search/notes', json=json_data, headers=headers)
notes_list = response.json()['data']['items'] # 拿到笔记列表3.3 关键步骤:提取详情与图片链接
拿到笔记ID后,访问详情页,并解析那个包含所有数据的JS变量。
python
# 1. 从JS代码段中提取数据
content_raw = response_detail.text.split('window.__INITIAL_STATE__=')[1].split('</script>')[0]
parsed_data = json.loads(content_raw) # 解析成字典
# 2. 像挖宝一样,从字典里取出各种数据
note_data = parsed_data['note']['noteDetailMap'][note_id]
title = note_data['note']['title'] # 标题
liked_count = note_data['note']['interactInfo']['likedCount'] # 点赞数
# 3. 提取所有高清图片链接
image_urls = []
for image in note_data['note']['imageList']:
img_url = image['infoList'][0]['url']
image_urls.append(img_url)四、如何运行?
-
按上面说的 ,准备好
搜索词.xlsx和cookie.xlsx文件。 -
安装依赖 :
pip install requests pandas lxml openpyxl -
运行主函数
main(),程序会问你每个关键词想爬多少条,然后坐等Excel文件生成即可。 -
程序会自动帮你:读取关键词 -> 调用搜索接口 -> 翻页 -> 解析每篇笔记详情 -> 保存到表格。
五、说明
需要本文提到的完整可运行Python源码的小伙伴,我都放在了与此号同名的公主号里,大家自行获取。
持续分享Python干货中!更多爬虫源码干货,请前往主页查看。