CANN组织链接 :CANN 官方 Git 仓库
ops-nn仓库链接 :ops-nn 官方 Git 仓库
引言:AI驱动的深度优化与算子实现
随着AIGC(人工智能生成内容)技术的日渐成熟,深度学习框架的优化和算子设计成为了提升AI计算能力的重要因素之一。CANN(Compute Architecture for Neural Networks)作为华为开源的深度学习框架,提供了强大的算子库,旨在提高AI模型的训练和推理效率。而ops-nn作为CANN框架中的核心部分,负责不同算子的实现与优化,是推动高效深度学习的关键。
本文将基于CANN和ops-nn框架,对其中的技术细节进行深入剖析,并通过实际操作,展示如何通过自定义算子优化AI模型的性能。
一、CANN与ops-nn概述
CANN是华为自研的深度学习计算架构,旨在为开发者提供高效的AI计算框架。它通过高度优化的算子实现,支持多种主流神经网络结构,包括但不限于CNN、RNN、Transformer等。在CANN中,ops-nn算子库承担了许多关键功能,其作用是为神经网络模型提供高效的运算支持,确保不同层次、不同规模的模型都能在硬件加速下得到快速的推理和训练。
二、CANN算子库的设计原则与优化策略
CANN算子库的设计目标是尽可能减少计算资源的浪费,提升算法的执行效率。主要通过以下几种策略来实现:
1. 硬件适配性
CANN的算子库不仅支持GPU加速,还优化了针对昇腾AI芯片的性能,能够在不同硬件环境下进行高效执行。通过深度硬件适配,CANN最大化地利用了底层硬件的计算能力。
2. 算子复用
CANN通过模块化设计将常用的计算操作封装为通用算子,这样可以避免重复设计,提高开发效率。每个算子都能根据不同场景动态调度,确保在多种任务中都能达到最佳的性能。
3. 自动化调优
CANN支持对算子的自动化优化,包括并行化、内存管理以及运算精度的优化。它能够根据输入数据的特征、硬件环境的情况,自动选择最佳的算子路径。
三、深入解析:ops-nn中的关键算子与实现
ops-nn库包含了许多基础算子,如卷积、池化、矩阵乘法等。这里我们重点解析两个典型算子:卷积算子 和矩阵乘法算子。
3.1 卷积算子的优化
卷积是深度神经网络中最常见的操作之一,在图像处理、目标检测等任务中应用广泛。CANN中的卷积算子采用了分组卷积、深度可分离卷积等技术,显著降低了计算量。
卷积算子公式:
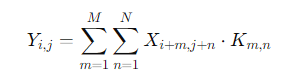
其中,XXX是输入图像,KKK是卷积核,YYY是输出特征图。为了加速卷积计算,CANN对卷积过程进行了并行化处理,支持多个卷积核的同时计算。
在ops-nn中,卷积算子被高度优化,通过调整卷积核的大小、步长和填充方式,显著提升了推理速度。
3.2 矩阵乘法算子的优化
矩阵乘法是深度学习中常见的操作,尤其是在全连接层和Transformer模型中。CANN中的矩阵乘法算子通过优化矩阵分块、分配多线程计算,极大地提升了运算效率。
矩阵乘法公式:
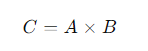
其中,AAA和BBB是输入矩阵,CCC是输出矩阵。ops-nn通过将矩阵划分为小块并行计算,减少了内存访问的瓶颈,从而加速了矩阵乘法的执行。
四、CANN与ops-nn中的实际操作:自定义算子的实现
为了更好地理解CANN的算子优化,下面我们将通过一个实际的例子,展示如何在ops-nn中自定义算子,并实现简单的卷积算子优化。
4.1 自定义卷积算子示例
首先,我们需要在ops-nn中创建一个新的卷积算子,该算子将在推理时调用:
import cann
from cann.ops import conv2d
# 自定义卷积算子
class CustomConv2D(cann.Op):
def __init__(self, kernel_size, stride, padding):
super().__init__()
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
def forward(self, x):
return conv2d(x, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding)
# 初始化卷积算子
conv_op = CustomConv2D(kernel_size=3, stride=1, padding=1)
# 输入数据
input_tensor = cann.Tensor(shape=(1, 28, 28, 3)) # 假设输入为28x28x3的图像
# 执行卷积操作
output_tensor = conv_op(input_tensor)在这个例子中,我们自定义了一个卷积算子,并将其与CANN框架中的基础算子conv2d结合。通过修改卷积核大小、步长和填充方式,可以优化该算子的执行效率。
4.2 性能测试与优化
通过运行上述代码,我们可以使用CANN提供的性能分析工具,对算子的执行效率进行评估,并进一步进行优化。例如,我们可以通过调整卷积核的大小、并行化策略或通过异步执行来减少运算时间。
# 性能测试代码
import time
start_time = time.time()
output_tensor = conv_op(input_tensor)
end_time = time.time()
print(f"Convolution operation took {end_time - start_time} seconds")通过这种方式,我们能够在CANN框架中实现并优化自定义算子,以满足特定的性能需求。
五、总结与展望
CANN框架和ops-nn算子库为深度学习的高效推理与训练提供了强大的支持。通过对算子库的优化与自定义,我们能够在不同硬件平台上实现更高效的AI计算。未来,随着AI技术的发展,我们可以期待更多创新的算子优化方法与算法,在推动智能化应用的同时,也提升AI模型的整体性能。
通过本文的介绍,相信读者能够更好地理解CANN框架和ops-nn算子库的设计原理与应用实践,并能够根据需求对现有算子进行优化和扩展,以实现更加高效的AI计算。
希望这篇文章能够帮助你更好地理解和实践CANN与ops-nn的技术。欢迎前往CANN 官方 Git 仓库和ops-nn 官方 Git 仓库进一步探索和学习。