一、排序的概念及引用
1.1 排序的概念
排序 :所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
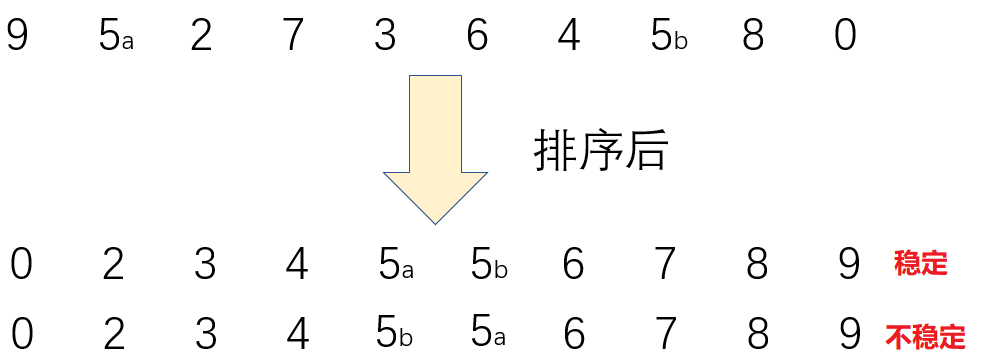
稳定性 :假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,ri=rj,且ri在rj之前,而在排序后的序列中,ri仍在rj之前,则称这种排序算法是稳定的;否则称为不稳定的 。
内部排序 :数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
1.2 排序运用
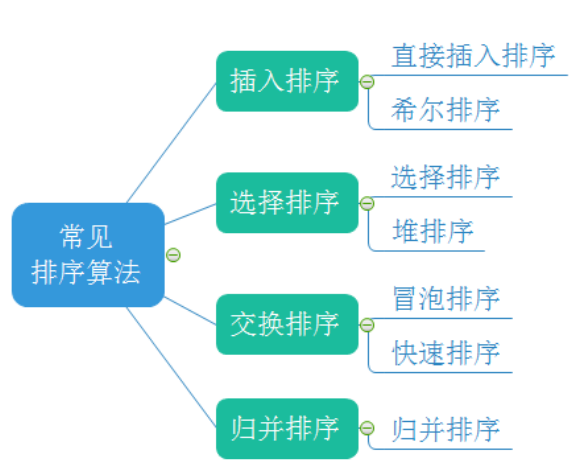
1.3 常见的排序算法
二、常见排序算法的实现
2.1 插入排序
2.1.1基本思想:
直接插入排序是一种简单的插入排序法,其基本思想是:
把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列 。实际中我们玩扑克牌时,就用了插入排序的思想。

2.1.2 直接插入排序
直接插入排序的核心是"逐步构建有序序列 ",类比打扑克牌时整理手牌的过程:
1.将数组分为有序区 (初始只有第一个元素)和无序区 (剩余所有元素);
2.依次从无序区取出第一个元素 作为待插入元素 ,将其与有序区的元素从后往前逐一比较
3.若有序区的元素大于待插入元素,就将该元素向后移动一位 ,为待插入元素腾出位置;
4.找到待插入元素的正确位置(有序区元素≤待插入元素的后一位),将其插入;
5.重复上述步骤,直到无序区元素全部插入有序区,排序完成。
代码实现:
java
public class InsertionSort {
// 直接插入排序核心方法:传入整型数组,原地排序
public static void insertionSort(int[] arr) {
// 边界判断:数组为空或长度为1,无需排序
if (arr == null || arr.length <= 1) {
return;
}
// 外层循环:遍历无序区,i从1开始(0号元素是初始有序区)
for (int i = 1; i < arr.length; i++) {
int insertVal = arr[i]; // 取出无序区第一个元素作为待插入值
int j = i - 1; // j指向有序区的最后一个元素(初始为i-1)
// 内层循环:从后往前扫描有序区,找插入位置
// 条件:j>=0(不越界) && 有序区元素>待插入值(需要后移)
while (j >= 0 && arr[j] > insertVal) {
arr[j + 1] = arr[j]; // 有序区元素向后移动一位,腾出位置
j--; // j向前移动,继续比较前一个元素
}
// 找到插入位置(j+1),将待插入值放入
arr[j + 1] = insertVal;
}
}
// 工具方法:打印数组,方便查看排序结果
public static void printArray(int[] arr) {
if (arr == null) {
System.out.println("数组为空");
return;
}
for (int num : arr) {
System.out.print(num + " ");
}
System.out.println();
}
// 主方法:测试直接插入排序
public static void main(String[] args) {
// 测试用例1:普通无序数组
int[] arr1 = {3, 1, 4, 1, 5, 9, 2, 6};
System.out.println("排序前:");
printArray(arr1);
insertionSort(arr1);
System.out.println("排序后:");
printArray(arr1);
// 测试用例2:基本有序数组(最优情况)
int[] arr2 = {1, 2, 3, 5, 4, 6, 7};
System.out.println("\n基本有序数组排序前:");
printArray(arr2);
insertionSort(arr2);
System.out.println("排序后:");
printArray(arr2);
// 测试用例3:逆序数组(最坏情况)
int[] arr3 = {7, 6, 5, 4, 3, 2, 1};
System.out.println("\n逆序数组排序前:");
printArray(arr3);
insertionSort(arr3);
System.out.println("排序后:");
printArray(arr3);
}
}直接插入排序的特性总结:
- 元素集合越接近有序,直接插入排序算法的时间效率越高
- 时间复杂度:O(N^2)
- 空间复杂度:O(1),它是一种稳定的排序算法
- 稳定性:稳定\
2.1.3 希尔排序( 缩小增量排序 )
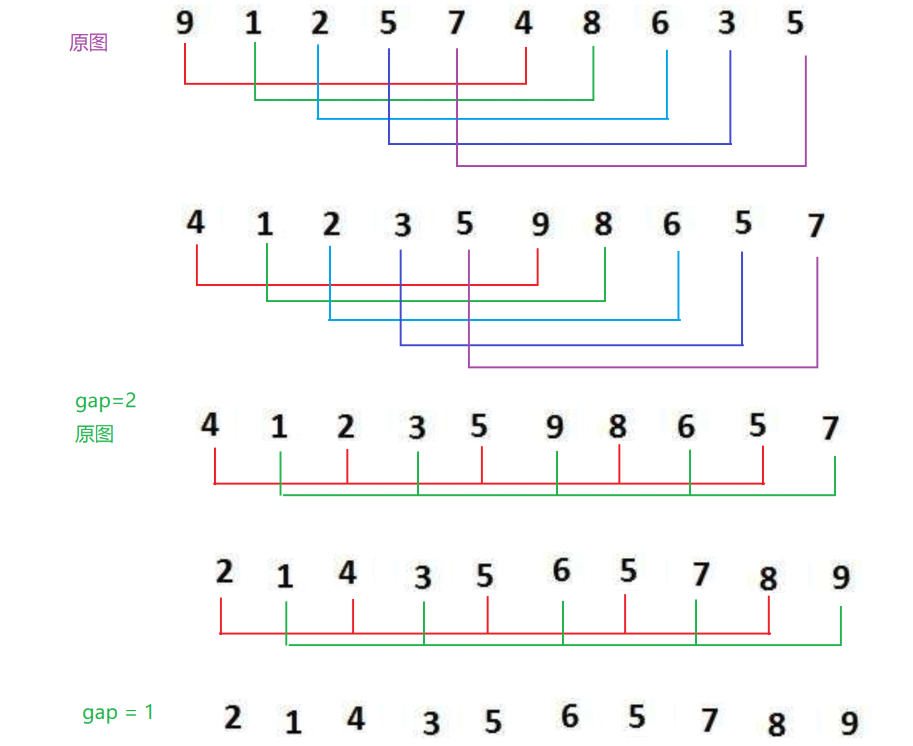
希尔排序是插入排序的优化版 ,核心是缩小增量 :
1.把待排序数组按增量gap 分成多个子数组(下标差为gap的元素为一个子数组);
2.对每个子数组分别进行直接插入排序 ;
3.逐步缩小增量gap(通常取 gap = gap / 2,直到 gap=1);
4.当gap=1时,数组整体进行一次直接插入排序,此时数组已基本有序,插入排序的效率会大幅提升。
关键 :gap 的选择会影响希尔排序效率,最常用的是希尔增量 (gap = 初始长度/2 → gap/2 → ... → 1),实现简单且效果较好。
java
public class ShellSort {
// 希尔排序核心方法:对int数组进行升序排序
public static void shellSort(int[] arr) {
// 空数组或单元素数组,无需排序,直接返回
if (arr == null || arr.length <= 1) {
return;
}
int n = arr.length;
// 1. 初始化增量gap,初始值为数组长度的一半(希尔增量)
int gap = n / 2;
// 2. 循环缩小增量,直到gap=0时结束(gap=1时会执行最后一次插入排序)
while (gap > 0) {
// 3. 对每个增量对应的子数组,执行直接插入排序
// 从gap开始遍历,因为前gap个元素分别是每个子数组的第一个元素,默认有序
for (int i = gap; i < n; i++) {
int temp = arr[i]; // 保存当前要插入的元素(待插入值)
int j = i; // 从当前位置向前找插入位置
// 4. 向前遍历子数组,找temp的正确插入位置(降序则改为arr[j-gap] < temp)
// 条件:j >= gap 保证不越界;arr[j-gap] > temp 说明前一个元素更大,需要后移
while (j >= gap && arr[j - gap] > temp) {
arr[j] = arr[j - gap]; // 元素后移,腾出插入位置
j -= gap; // 继续向前找
}
// 5. 将temp插入到正确位置
arr[j] = temp;
}
// 缩小增量,直到gap=1
gap /= 2;
}
}
// 工具方法:打印数组元素,方便测试
public static void printArray(int[] arr) {
for (int num : arr) {
System.out.print(num + " ");
}
System.out.println();
}
// 主方法:测试希尔排序
public static void main(String[] args) {
// 测试用例1:普通乱序数组
int[] arr1 = {8, 9, 1, 7, 2, 3, 5, 4, 6, 0};
System.out.println("排序前:");
printArray(arr1);
shellSort(arr1);
System.out.println("排序后:");
printArray(arr1);
// 测试用例2:已有序数组
int[] arr2 = {1, 2, 3, 4, 5};
System.out.println("\n已有序数组排序后:");
shellSort(arr2);
printArray(arr2);
// 测试用例3:逆序数组
int[] arr3 = {5, 4, 3, 2, 1};
System.out.println("\n逆序数组排序后:");
shellSort(arr3);
printArray(arr3);
}
}希尔排序的性能分析
1.时间复杂度 :希尔排序的时间复杂度和增量选择相关,希尔增量的时间复杂度为O(n^1.3)(远优于插入排序的O(n²)) ;若用更优的增量(如Hibbard 增量),时间复杂度可接近O(nlog2n)。
2.空间复杂度:O(1),仅使用了临时变量temp,属于原地排序。
3.稳定性 :不稳定排序 (因为子数组的插入排序会打破相同元素的相对位置)。
4.适用场景:适合中等规模的数组排序,比直接插入排序、冒泡排序、选择排序效率高很多。
总结
1.希尔排序是插入排序的优化 ,通过缩小增量将数组分成子数组分别排序 ,最终gap=1时完成整体排序;
2.上述代码采用希尔增量(gap/2),实现简单、易理解,是最常用的希尔排序实现方式;
3.希尔排序原地、不稳定 ,时间复杂度优于基础插入/冒泡/选择排序,适合中等规模数据。
2.1选择排序
2.2.1基本思想:
每一次从待排序的数据元素中选出最小(或最大)的一个元素 ,存放在序列的起始位置,直到全部待排序的数据元素排完 。
2.2.2 直接选择排序:
直接选择排序核心思想
直接选择排序是简单的选择类排序,核心是每轮选最值,放到指定位置(升序选最小值,降序选最大值),步骤如下:
1.将数组分为已排序区 (初始为空)和未排序区 (初始为整个数组);
2.遍历未排序区 ,找到最小值 (升序),将其与未排序区的第一个元素交换位置;
3.此时未排序区第一个元素归入已排序区,未排序区长度减1;
4.重复上述步骤,直到未排序区只剩1个元素(数组完全有序)。
关键:每轮仅1次交换(找到最值后才交换),相比冒泡排序的多次交换,减少了数据移动次数,效率略高。
java
public class SelectSort {
// 直接选择排序核心方法:对int数组进行升序排序
public static void selectSort(int[] arr) {
// 边界处理:空数组或单元素数组,无需排序直接返回
if (arr == null || arr.length <= 1) {
return;
}
int n = arr.length;
// 外层循环:控制未排序区的起始位置i(已排序区为[0, i-1],未排序区为[i, n-1])
// 只需循环n-1次:最后1个元素会自动归位,无需处理
for (int i = 0; i < n - 1; i++) {
int minIndex = i; // 初始化最小值下标为未排序区第一个元素
// 内层循环:遍历未排序区,找到最小值的下标
for (int j = i + 1; j < n; j++) {
// 若当前元素比最小值小,更新最小值下标(降序则改为arr[j] >arr[minIndex])
if (arr[j] < arr[minIndex]) {
minIndex = j;
}
}
// 找到最小值后,若最小值下标不是未排序区第一个,才交换(避免无意义的自我交换)
if (minIndex != i) {
int temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
}
}
// 工具方法:打印数组,方便测试结果查看
public static void printArray(int[] arr) {
for (int num : arr) {
System.out.print(num + " ");
}
System.out.println();
}
// 主方法:测试直接选择排序的多场景效果
public static void main(String[] args) {
// 测试用例1:普通乱序数组(经典测试用例)
int[] arr1 = {8, 9, 1, 7, 2, 3, 5, 4, 6, 0};
System.out.println("排序前:");
printArray(arr1);
selectSort(arr1);
System.out.println("升序排序后:");
printArray(arr1);
// 测试用例2:已有序数组(验证无意义交换的优化)
int[] arr2 = {1, 2, 3, 4, 5};
System.out.println("\n已有序数组排序后:");
selectSort(arr2);
printArray(arr2);
// 测试用例3:逆序数组(最坏情况)
int[] arr3 = {5, 4, 3, 2, 1};
System.out.println("\n逆序数组排序后:");
selectSort(arr3);
printArray(arr3);
// 测试用例4:含重复元素的数组
int[] arr4 = {3, 1, 4, 1, 5, 9, 2, 6, 5};
System.out.println("\n含重复元素数组排序后:");
selectSort(arr4);
printArray(arr4);
}
}运行结果:
java
排序前:
8 9 1 7 2 3 5 4 6 0
升序排序后:
0 1 2 3 4 5 6 7 8 9
已有序数组排序后:
1 2 3 4 5
逆序数组排序后:
1 2 3 4 5
含重复元素数组排序后:
1 1 2 3 4 5 5 6 9 1.循环次数:外层循环仅需执行n-1次,因为当未排序区只剩最后1个元素时,它一定是最大值,无需再比较;
2.最小值下标:用minIndex保存最小值的位置,而非直接保存值,避免多次修改数组,仅在找到最值后做1次交换;
3.避免无意义交换:增加if(minIndex!=i)判断,若未排序区第一个元素就是最小值,无需自我交换,提升效率;
4.边界控制:内层循环从i+1开始,因为0,i-1是已排序区,i是未排序区第一个元素,只需比较i之后的元素。
直接选择排序的性能分析
作为基础排序算法,它的性能特征很明确,适合入门理解:
1.时间复杂度 :最好/最坏/平均都是O(n²) ,因为无论数组是否有序,内层循环都要完整遍历未排序区,没有优化空间;
2.空间复杂度 :O(1),仅使用了临时变量temp和下标变量,属于原地排序;
3.稳定性:不稳定排序 (相同元素的相对位置可能被打破,例:数组{2,2,1},第一轮选1和第一个2交换,两个2的相对位置改变);
4.适用场景:适合小规模数据排序,或对交换操作效率要求高的场景(每轮仅1次交换,比冒泡排序少很多数据移动)
2.2.3 堆排序
堆排序(Heapsort)是指利用 堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是通过堆来进行选择数据 。需要注意的是排升序要建大堆,排降序建小堆 。
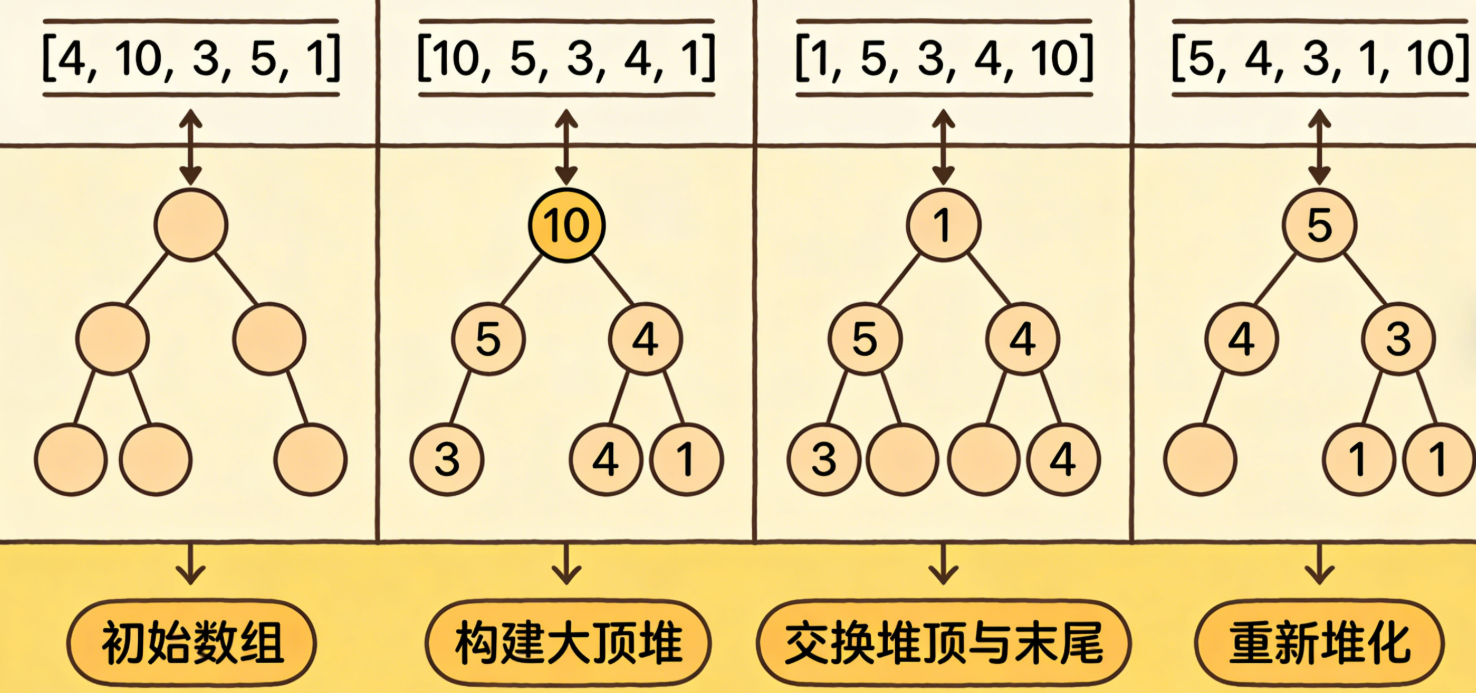
堆排序的性能分析
堆排序是高效的高级排序算法,性能远优于之前的希尔、直接选择、插入、冒泡排序,性能特征如下:
- 时间复杂度 :最好/ 最坏/ 平均都是O(nlogn) ,构建初始堆的时间是O(n),后续n-1次堆化每次是O(logn),整体复杂度为O(n+nlog2n)=O(nlogzn),且无最坏情况波动(比快速排序稳定);
2.空间复杂度 :O(1) ,仅使用了临时变量,属于原地排序;
3.稳定性 :不稳定排序 (交换堆顶和末尾元素时,会打破相同元素的相对位置);
4.适用场景:适合大规模数据排序(百万/千万级),是处理海量数据的常用排序算法;相比快速排序,堆排序无需递归(也可递归实现),无栈溢出风险,且最坏情况性能更稳定
总结
- 堆排序基于大顶堆/小顶堆 实现,升序用大顶堆(取堆顶最大值),降序用小顶堆(取堆顶最小值);
2.核心步骤是构建初始堆→交换堆顶与未排序区末尾→重新堆化 ,堆化方法(adjustHeap)是实现的关键;
3.数组与完全二叉树的映射规则(下标从0开始):左子2i+1、右子2i+2、父(i-1)/2,是堆化的基础; - 堆排序原地、不稳定 ,时间复杂度稳定O(nlog2n),适合大规模数据排序,是工业开发中常用的高效排序算法;
5.升/降序切换仅需修改堆化方法中的2个比较符号,逻辑灵活。