llamafactory采用vllm推理时有一个do_sample参数,do_sample参数(是否采样)等于True(默认),为False为采用贪婪解码,即为不随机采样,生成将会更加稳定,自己测试了,结果是采用do_sample参数为False时效果有所提升。
参考链接:
https://github.com/vllm-project/vllm/blob/main/vllm/sampling_params.py#L117

temperature为0意味着采用贪婪策略
所以在LLaMA-Factory\src\llamafactory\api\protocol.py中:
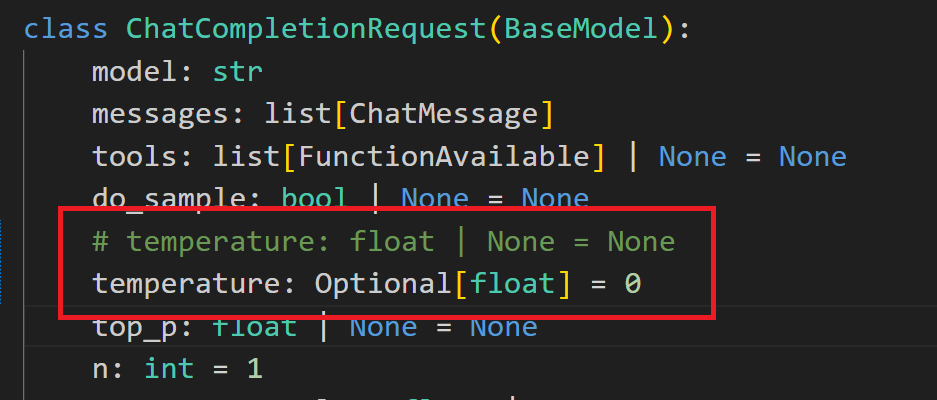
将temperature: float | None = None改为temperature: Optionalfloat = 0,即为采用贪婪策略,生成的更加稳定