文章:Spatial Mental Modeling from Limited Views
团队:李飞飞,谢赛宁
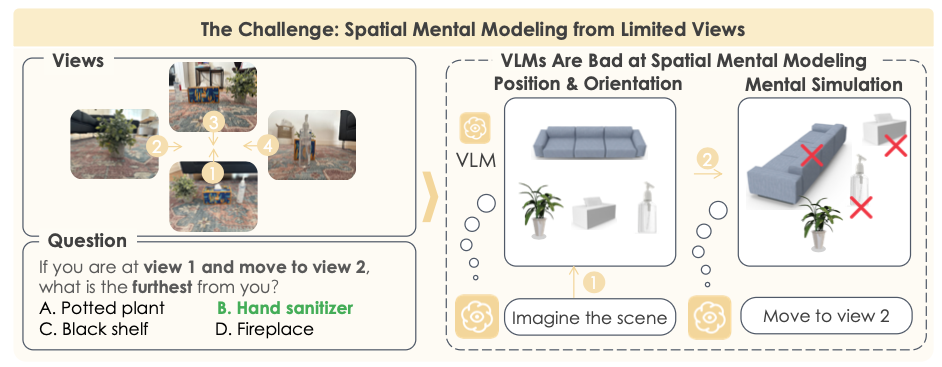
任务设计
MindCube问题类型就是三种:rotation / around / among。
问题的形式是数张multiview的图片
回答方式就是做选择题
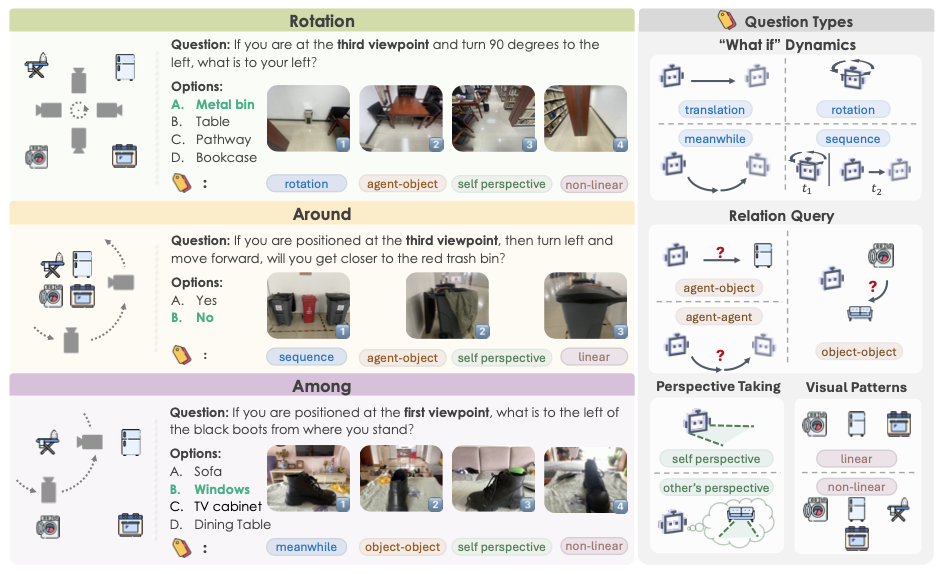
数据集信息
数据集规模:
21, 154 questions across 3, 268 images,organized into 976 multi-view groups
这一整个benchmark的数据集算下来有:21, 154 questions across 3, 268 images,是要比VSI bench大得多的
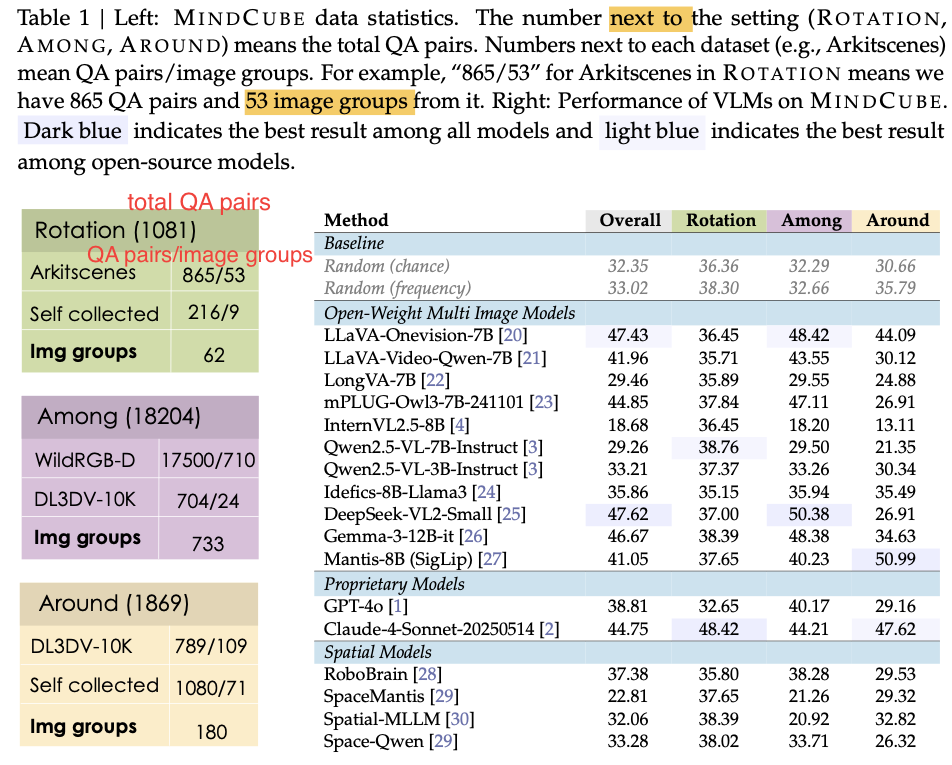
作者在测试时,其实使用的是一个更小的子集(MindCube-Tiny)
一共1,050 questions:其中
600 from the among,
250 from around,
200 from rotation
实验结果
作者首先在MindCube-Tiny上测试了不做SFT的模型效果:
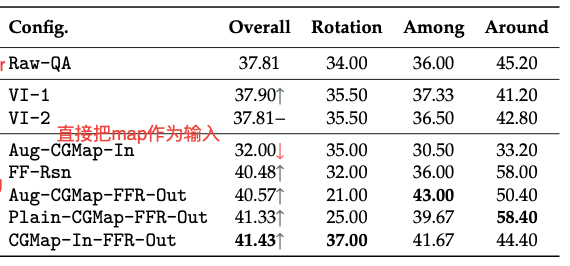
作者试了不同的setting:
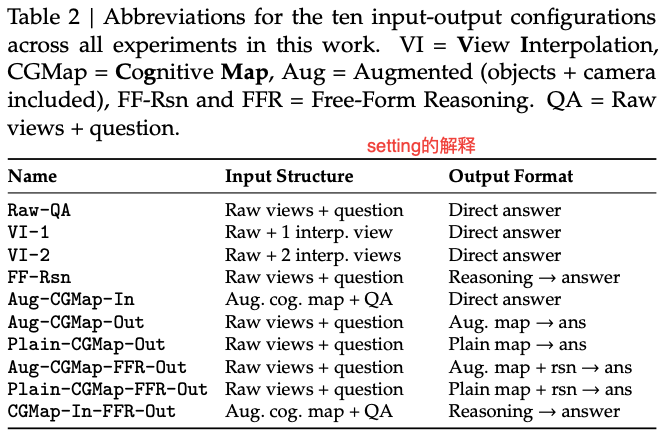
对于模型生成的cognitive map,做了正确性的分析:
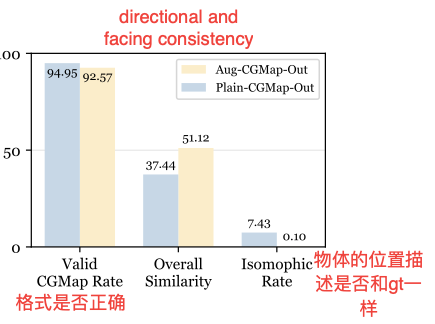
MindCube是有用于微调的数据集的:下面是在Qwen2.5-VL-3B-Instruct上微调后得到的结果:
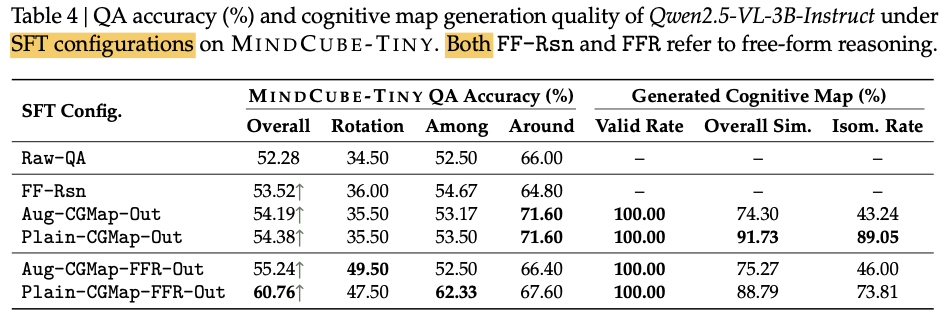
微调模型后,再进行强化学习可以进一步提升模型的效果:
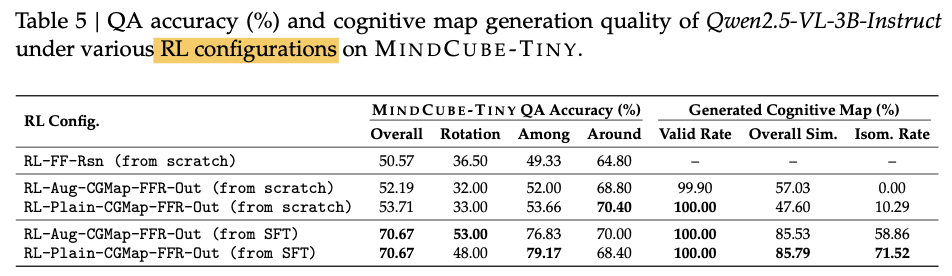
SFT数据构造:
数据分为:cognitive maps and free-form reasoning chains
cognitive maps是通过模板和尽心设计的函数来自动生成的
微调数据集:10k QA pairs
微调时的参数:
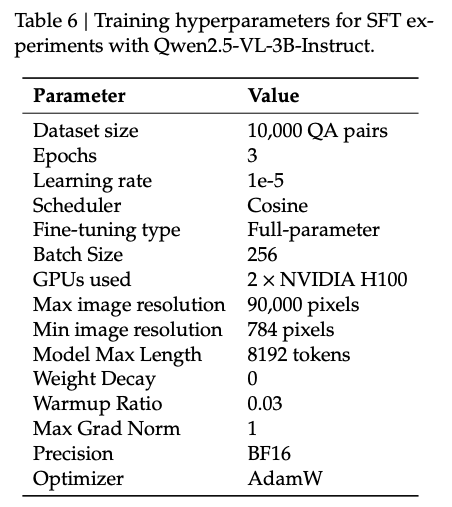
微调时用的是权量微调:DeepSpeed with a ZeRO Stage 3 optimization strategy for efficient full-parameter fine-tuning
作者还测试了只训练模型的不同部分:vision encoder和LLM,发现只训练vision encoder基本没有提升,
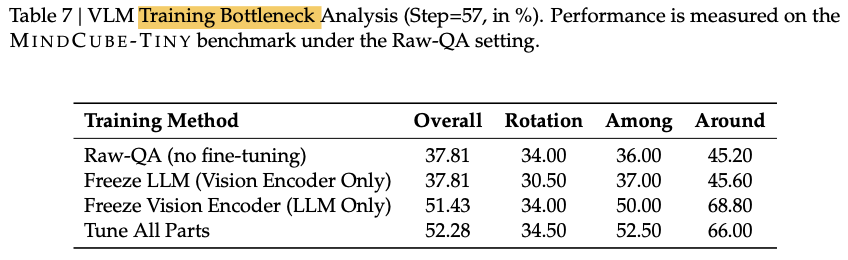
上面的实验得出结论:vision encoder 实际上只编码了物体的语意特征,而忽略了物体和场景的空间特征,这大概率是因为在vision encoder预训练时,vision encoder只学会了将视觉特征和text描述对齐的能力。而没有学习到物体空间位置的能力。