说起来,我第一次接触数据分析的时候,还挺懵的。
那时候我只会写一些基础的Python脚本,处理文件、爬取数据什么的。但看到别人用Python做数据分析、画各种漂亮的图表时,心里挺羡慕的。
于是我决定学学。结果一查资料,什么NumPy、Pandas、Matplotlib......光这些库就够让人头大的。
后来我发现,其实学数据分析没那么难,关键是要搞清楚每个库是做什么的 。
今天我想分享一下从入门到实践的学习路径,希望对你有帮助。
为什么选择Python做数据分析?
这个问题,我一开始也挺困惑的。Excel不是也能做数据分析吗?R语言不是更专业吗?
后来用了一段时间,我发现Python的优势挺明显的:
生态丰富 : 你想做的任何事情,几乎都有现成的库可以用。数组操作、数据处理、可视化、机器学习......一站式搞定。
上手简单 : 如果你已经会一些Python基础,那基本就零门槛了。语法统一,不用像学R语言那样从零开始。
社区强大 : 遇到问题,一搜就有答案。CSDN、Stack Overflow上全是现成的解决方案。
应用广泛 : 不只是数据分析,机器学习、Web开发、自动化脚本都能用。学了之后,用处比我想象的大得多。
当然,Python也有它的局限性。比如处理特别大的数据集时,性能不如专门的工具。但对于初学者来说,这个影响不大。
小贴士:如果你是完全零基础,建议先花2-3周时间掌握Python基础语法(变量、循环、函数、类),再开始学数据分析。会省很多事。
环境搭建:别被安装劝退
说真的,环境搭建这块,我一开始也被劝退过。
官方的Python装好了,然后pip安装各种包,结果一会儿报这个错,一会儿报那个错。装了一天都没弄好。
后来发现了Anaconda,才发现原来环境搭建可以这么简单 。
安装Anaconda
Anaconda是一个Python发行版,里面预装了数据分析常用的所有库。你只需要下载安装包,一路点"下一步"就行了。
具体步骤:
-
打开Anaconda官网:https://www.anaconda.com/download
-
选择你的操作系统(Windows/Mac/Linux)
-
下载Python 3.x版本(推荐Python 3.9或3.10)
-
双击安装包,一路"Next"
-
安装完成后,在开始菜单找到"Anaconda Navigator",打开看看
就这么简单。不用手动装Python,不用pip安装包,不用配置环境变量。这些Anaconda都帮你搞定了。
小贴士:安装过程中记得勾选"Add Anaconda to my PATH environment variable"选项,这样在命令行就能直接用conda命令了。
Jupyter Notebook基础操作
Anaconda装好后,Jupyter Notebook就跟着装好了。
Jupyter Notebook是什么?简单说,就是一个交互式编程环境。你可以写一行代码,立即运行看结果。特别适合学习数据分析。
启动方式:
在开始菜单找到"Jupyter Notebook",点击启动。会自动打开浏览器,显示你的文件目录。
新建笔记本:
-
点击"New"按钮
-
选择"Python 3"
-
就会打开一个新的笔记本
基本操作:
• Shift + Enter:运行当前单元格,并跳到下一个单元格
• Ctrl + Enter:运行当前单元格,但不跳到下一个
• A:在当前单元格上方插入新单元格(按Esc进入命令模式)
• D + D:删除当前单元格(按Esc进入命令模式,按两次D)
小贴士:Jupyter Notebook很适合做实验和记录笔记,但写大型项目时,建议用PyCharm或VS Code。Jupyter文件(.ipynb)可以导出为Python脚本。
核心库:NumPy、Pandas、Matplotlib
数据分析的核心,就是这三个库。我先一个一个说。
NumPy:数组操作的基础
NumPy是Python科学计算的基础库。它提供了一个强大的数组对象,支持大量的数学运算。
为什么需要NumPy?因为Python原生的列表在处理数值计算时效率太低。NumPy的数组底层用C实现,速度快得多。
创建数组:
python
import numpy as np
# 创建一维数组
arr1 = np.array([1, 2, 3, 4, 5])
print(arr1)
# 输出: [1 2 3 4 5]
# 创建二维数组
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(arr2)
# 输出:
# [[1 2 3]
# [4 5 6]]
# 创建全0数组
zeros = np.zeros((2, 3))
print(zeros)
# 输出:
# [[0. 0. 0.]
# [0. 0. 0.]]
# 创建全1数组
ones = np.ones((3, 3))
print(ones)
# 输出:
# [[1. 1. 1.]
# [1. 1. 1.]
# [1. 1. 1.]]数组运算:
python
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
# 加法
print(a + b) # 输出: [5 7 9]
# 乘法(对应元素相乘)
print(a * b) # 输出: [ 4 10 18]
# 标量运算
print(a * 2) # 输出: [2 4 6]
# 统计运算
print(a.mean()) # 平均值,输出: 2.0
print(a.sum()) # 求和,输出: 6
print(a.max()) # 最大值,输出: 3小贴士:NumPy的数组运算都是元素级的,和Python原生列表不一样。比如 1, 2, 3 * 2 在Python里会复制列表,但在NumPy里会把每个元素都乘2。
Pandas:数据分析的核心
Pandas是数据分析的核心库。它提供了DataFrame和Series两种数据结构,让数据处理变得超级简单。
我一开始觉得Pandas有点复杂,但用了一段时间发现,它把数据处理中最常用的操作都封装好了 。
创建DataFrame:
python
import pandas as pd
# 从字典创建DataFrame
data = {
'姓名': ['张三', '李四', '王五'],
'年龄': [25, 30, 35],
'城市': ['北京', '上海', '广州']
}
df = pd.DataFrame(data)
print(df)
# 输出:
# 姓名 年龄 城市
# 0 张三 25 北京
# 1 李四 30 上海
# 2 王五 35 广州读取数据:
python
import pandas as pd
# 读取CSV文件
df = pd.read_csv('data.csv') # 假设有一个data.csv文件
# 查看前5行
print(df.head())
# 查看数据信息
print(df.info())
# 查看基本统计信息
print(df.describe())
# 选择某一列
print(df['列名'])
# 选择多列
print(df[['列名1', '列名2']])数据筛选:
python
import pandas as pd
# 假设df是上面的DataFrame
# 筛选年龄大于28的人
result = df[df['年龄'] > 28]
print(result)
# 筛选城市是北京或上海的人
result = df[df['城市'].isin(['北京', '上海'])]
print(result)
# 多条件筛选(年龄>28 且 城市=上海)
result = df[(df['年龄'] > 28) & (df['城市'] == '上海')]
print(result)数据排序:
python
import pandas as pd
# 按年龄升序排序
df_sorted = df.sort_values('年龄')
print(df_sorted)
# 按年龄降序排序
df_sorted = df.sort_values('年龄', ascending=False)
print(df_sorted)小贴士:Pandas的索引操作很容易出错。比如 df0:5 和 df.iloc0:5 结果一样,但 df\['列名'] 和 df.loc:, \['列名'] 就不一样。刚开始学的时候,建议用 .loc 和 .iloc 明确表达你的意图,这样不容易出错。
Matplotlib:数据可视化
数据可视化的目的,是让数据"说话"。Matplotlib是Python最基础的可视化库,功能强大但需要写的代码也比较多。
我一开始觉得Matplotlib的代码太复杂了。后来发现,掌握几个核心函数,就能应付90%的场景 。
绘制折线图:
python
import matplotlib.pyplot as plt
# 准备数据
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
# 创建图形和坐标轴
fig, ax = plt.subplots(figsize=(8, 6))
# 绘制折线图
ax.plot(x, y, marker='o', linewidth=2)
# 设置标题和标签
ax.set_title('简单的折线图', fontsize=14)
ax.set_xlabel('X轴', fontsize=12)
ax.set_ylabel('Y轴', fontsize=12)
# 显示网格
ax.grid(True, linestyle='--', alpha=0.7)
# 显示图形
plt.show()
绘制柱状图:
python
import matplotlib.pyplot as plt
# 准备数据
categories = ['A', 'B', 'C', 'D', 'E']
values = [23, 45, 56, 78, 32]
# 创建图形和坐标轴
fig, ax = plt.subplots(figsize=(10, 6))
# 绘制柱状图
bars = ax.bar(categories, values, color='skyblue', edgecolor='black')
# 在柱子上添加数值标签
for bar in bars:
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width()/2., height,
f'{height}',
ha='center', va='bottom', fontsize=12)
# 设置标题和标签
ax.set_title('各类别数据对比', fontsize=14)
ax.set_xlabel('类别', fontsize=12)
ax.set_ylabel('数值', fontsize=12)
# 显示图形
plt.show()小贴士:Matplotlib的参数特别多,不需要全部记住。用的时候查文档就行。记住几个核心的就够了:plot(折线图)、bar(柱状图)、scatter(散点图)、hist(直方图)。
Seaborn:更高级的可视化
Seaborn是基于Matplotlib的高级可视化库,语法更简洁,默认样式更好看。
我一开始学Matplotlib时,画出来的图总觉得不够漂亮。后来用了Seaborn才发现,原来数据可视化也可以这么简单这么好看 。
绘制箱线图:
python
import seaborn as sns
import matplotlib.pyplot as plt
# Seaborn自带一些示例数据集
tips = sns.load_dataset('tips')
# 创建图形
fig, ax = plt.subplots(figsize=(10, 6))
# 绘制箱线图
sns.boxplot(x='day', y='total_bill', data=tips, ax=ax)
# 设置标题
ax.set_title('不同日期的账单金额分布', fontsize=14)
ax.set_xlabel('星期', fontsize=12)
ax.set_ylabel('账单金额', fontsize=12)
# 显示图形
plt.show()
绘制热力图:
python
import seaborn as sns
import matplotlib.pyplot as plt
# 创建相关系数矩阵数据
data = [[1.0, 0.8, 0.3],
[0.8, 1.0, 0.5],
[0.3, 0.5, 1.0]]
# 创建图形
fig, ax = plt.subplots(figsize=(8, 6))
# 绘制热力图
sns.heatmap(data, annot=True, cmap='coolwarm',
xticklabels=['A', 'B', 'C'],
yticklabels=['A', 'B', 'C'],
ax=ax)
# 设置标题
ax.set_title('相关性热力图', fontsize=14)
# 显示图形
plt.show()小贴士:Seaborn的API设计得很好,很多常用图只需要一行代码就能画出来。比如 sns.countplot() 画计数图,sns.pairplot() 画变量关系图,这些都特别实用。
实战案例:泰坦尼克号数据探索
光说理论没什么用,来个实战案例吧。
我用泰坦尼克号数据集做一个完整的数据分析:数据加载 → 清洗 → 分析 → 可视化。
这个数据集包含泰坦尼克号乘客的信息,包括是否幸存、年龄、性别、船舱等级等。是个很好的入门练习数据集。
步骤1:加载数据
python
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据集
# 如果没有这个文件,可以从Kaggle下载
url = 'https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv'
df = pd.read_csv(url)
# 查看数据前5行
print("数据前5行:")
print(df.head())
# 查看数据信息
print("\n数据信息:")
print(df.info())
# 查看基本统计信息
print("\n基本统计信息:")
print(df.describe())步骤2:数据清洗
python
# 检查缺失值
print("\n缺失值统计:")
print(df.isnull().sum())
# 处理缺失值
# 年龄缺失的,用平均值填充
df['Age'] = df['Age'].fillna(df['Age'].mean())
# 删除缺失值过多的行(这里假设Survived列没有缺失值)
# 如果某列缺失值超过30%,可以考虑删除该列
print("\n清洗后的缺失值统计:")
print(df.isnull().sum())步骤3:数据分析
python
# 分析1:总体幸存率
survival_rate = df['Survived'].mean()
print(f"\n总体幸存率: {survival_rate:.2%}")
# 分析2:不同性别的幸存率
gender_survival = df.groupby('Sex')['Survived'].mean()
print("\n不同性别的幸存率:")
print(gender_survival)
# 分析3:不同船舱等级的幸存率
class_survival = df.groupby('Pclass')['Survived'].mean()
print("\n不同船舱等级的幸存率:")
print(class_survival)
# 分析4:不同年龄段的幸存率
# 将年龄分段
df['AgeGroup'] = pd.cut(df['Age'],
bins=[0, 18, 30, 50, 100],
labels=['0-18', '18-30', '30-50', '50+'])
age_survival = df.groupby('AgeGroup')['Survived'].mean()
print("\n不同年龄段的幸存率:")
print(age_survival)步骤4:数据可视化
python
# 创建一个2x2的子图布局
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
# 图1:幸存与未幸存人数对比
ax1 = axes[0, 0]
sns.countplot(x='Survived', data=df, ax=ax1)
ax1.set_title('幸存与未幸存人数对比', fontsize=14)
ax1.set_xlabel('是否幸存', fontsize=12)
ax1.set_ylabel('人数', fontsize=12)
# 添加数值标签
for p in ax1.patches:
ax1.annotate(f'{int(p.get_height())}',
(p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center', fontsize=12)
# 图2:不同性别的幸存率对比
ax2 = axes[0, 1]
sns.barplot(x='Sex', y='Survived', data=df, ax=ax2)
ax2.set_title('不同性别的幸存率对比', fontsize=14)
ax2.set_xlabel('性别', fontsize=12)
ax2.set_ylabel('幸存率', fontsize=12)
# 图3:不同船舱等级的幸存率对比
ax3 = axes[1, 0]
sns.barplot(x='Pclass', y='Survived', data=df, ax=ax3)
ax3.set_title('不同船舱等级的幸存率对比', fontsize=14)
ax3.set_xlabel('船舱等级', fontsize=12)
ax3.set_ylabel('幸存率', fontsize=12)
# 图4:年龄分布对比
ax4 = axes[1, 1]
sns.histplot(data=df, x='Age', hue='Survived',
kde=True, element='step', ax=ax4)
ax4.set_title('不同年龄段的分布对比', fontsize=14)
ax4.set_xlabel('年龄', fontsize=12)
ax4.set_ylabel('人数', fontsize=12)
plt.tight_layout()
plt.show()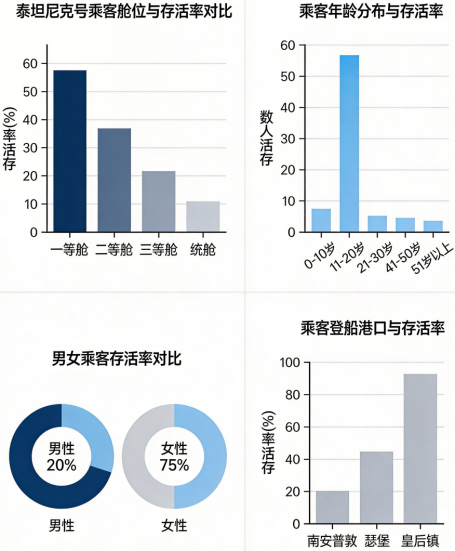
步骤5:结论总结
python
# 输出分析结论
print("\n=== 分析结论 ===")
print(f"1. 总体幸存率为 {survival_rate:.2%}")
print("2. 女性的幸存率显著高于男性")
print("3. 高等舱的乘客幸存率更高")
print("4. 儿童和老人的幸存率相对较高")
print("\n这些发现与历史上的真实情况基本一致:")
print("- 妇女和儿童优先获救")
print("- 高等舱乘客更靠近甲板,更容易获救")小贴士:做数据分析时,不仅要看数据,还要结合业务背景去理解。比如泰坦尼克号数据分析,如果你不了解"妇女儿童优先"这个历史背景,可能会错过重要的洞察。
进阶方向:学完这些还能做什么?
掌握了NumPy、Pandas、Matplotlib这些基础后,你就可以开始做更复杂的事情了。
机器学习入门
有了数据分析的基础,学习机器学习会容易很多。你可以用scikit-learn库尝试:
• 分类问题(预测某事会不会发生)
• 回归问题(预测具体数值)
• 聚类分析(把相似的数据分到一起)
推荐先从简单的算法开始,比如逻辑回归、决策树、K近邻。这些算法的原理不难,但实际应用效果不错。
大数据处理
当数据量超过内存容量时,Pandas就不够用了。这时候可以考虑:
• PySpark:基于Spark的Python库,适合处理大规模数据
• Dask:类似Pandas的API,但支持分布式计算
• Vaex:类似Pandas,但针对大数据做了优化
自动化报表
学会了数据分析,你还可以把它自动化。比如:
• 每天自动从数据库读取数据
• 自动生成分析报告
• 自动发送邮件给相关人员
这块我推荐学习Apache Airflow,它可以帮你编排这些任务。
小贴士:不要什么都想学。数据分析这个领域太大了,不可能全部掌握。建议先专注于一个方向,深入下去,再考虑拓展。比如先学机器学习分类,再学回归,最后学深度学习。
学习资源推荐
官方文档:
• NumPy官方文档:https://numpy.org/doc/
• Pandas官方文档:https://pandas.pydata.org/docs/
• Matplotlib官方文档:https://matplotlib.org/stable/contents.html
• Seaborn官方文档:https://seaborn.pydata.org/tutorial.html
优质课程:
• Coursera上的"Python for Data Science"课程(免费)
• Kaggle上的Python微课程(免费)
• DataCamp上的互动课程(部分免费)
实战平台:
• Kaggle:全球最大的数据科学竞赛平台,有很多公开数据集和Notebook案例
• 天池:阿里云的数据科学平台,有很多国内的竞赛和数据集
推荐书籍:
• 《Python数据分析》 by Wes McKinney(Pandas创始人)
• 《利用Python进行数据分析》第2版
• 《Python数据科学手册》
小贴士:官方文档虽然枯燥,但最权威。遇到问题时,先查官方文档,再查Google。很多问题的答案就在文档里,只是你没仔细看。
最后想说的话
说真的,我学数据分析的时候,一开始也挺挫败的。
看别人的代码,觉得简单;自己一写,各种报错。查文档,看不懂;看教程,跟不上。
但坚持下来后,我发现数据分析这个技能,真的很值 。
不只是工作上能用,生活中也能用。比如分析一下自己的消费数据,看看钱都花哪儿了;或者分析一下运动数据,看看如何提高效率。
最重要的是,它培养了一种数据思维 。
做决策时,不再凭感觉,而是看数据。分析问题时,不再靠猜测,而是找证据。
这种思维方式的改变,我觉得比学技术本身更有价值。
所以,如果你现在觉得有点难,不要放弃。
慢慢来,比较快。
你在学习数据分析时遇到过哪些问题?欢迎在评论区交流!