1 题目
给定一个长度为 n 的链表 head
对于列表中的每个节点,查找下一个 更大节点 的值。也就是说,对于每个节点,找到它旁边的第一个节点的值,这个节点的值 严格大于 它的值。
返回一个整数数组 answer ,其中 answer[i] 是第 i 个节点( 从1开始 )的下一个更大的节点的值。如果第 i 个节点没有下一个更大的节点,设置 answer[i] = 0 。
示例 1:
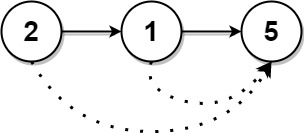
输入:head = [2,1,5]
输出:[5,5,0]示例 2:
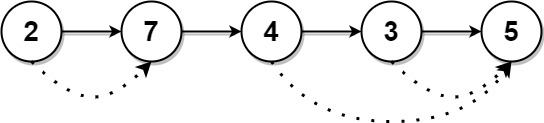
输入:head = [2,7,4,3,5]
输出:[7,0,5,5,0]提示:
- 链表中节点数为
n 1 <= n <= 1041 <= Node.val <= 109
2 代码实现
c++
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
vector<int> nextLargerNodes(ListNode* head) {
vector <int> nums ;
while (head){
nums.push_back(head -> val);
head = head -> next ;
}
int n = nums.size();
vector<int> res (n , 0 );
stack<int> st ;
for (int i = 0 ; i < n ; i++){
while (!st.empty() && nums[i] > nums[st.top()]){
int top_index = st.top();
res[top_index] = nums [i];
st.pop();
}
st.push(i);
}
return res;
}
};思考
返回的是一个数组,还是按节点顺序里面找最大的,这样怎么搞啊,每个都找一遍肯定是不对的,时间复杂度肯定超过了。
我想起来是unordered_map , 这个用map可以吗,然后怎么搞,map可以存放下标吗,应该可以,类似于二维数组,key和val刚好对应下标,那怎么根据key下标检索呢?这个怎么搞,cpp的语法是什么?....
提示:
- 先将链表转为普通数组,解决链表无法随机访问的问题;
- 用单调栈(存下标) 找每个元素的下一个更大值,这是 O (n) 时间复杂度的核心;
- unordered_map 可临时存下标和对应值,但直接用结果数组更高效,其下标检索语法为
map[key],需判断 key 是否存在(不存在则结果为 0)。
栈和队列其实我用的比较少,语法API不是很熟。
自己先去胡乱写一下,看看会卡在哪里?
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
using namespace std ;
public:
vector<int> nextLargerNodes(ListNode* head) {
vector <int> nums ;
while (head && head -> next){
nums.push_back(head -> val);
}
stack<int> keys ;
while(ing i = 0 ; i < nums.size() ; i++){
keys.push(i);
}
}
};这个怎么搞的,不会写,不知道单调栈的逻辑在哪里。
题解
第一步:先补全 C++ 栈(stack)的核心 API
你首先要熟悉stack<int>的常用操作,这是写对逻辑的基础:
表格
| 操作 | 作用 | 示例 |
|---|---|---|
push(x) |
把 x 压入栈顶 | keys.push(i); |
pop() |
弹出栈顶元素(无返回值) | keys.pop(); |
top() |
获取栈顶元素(不弹出) | int top_idx = keys.top(); |
empty() |
判断栈是否为空 | if (!keys.empty()) |
size() |
获取栈的大小 | (本题用得少) |
第二步:拆解单调栈的核心逻辑(结合你的代码修正)
你的代码目前有两个关键问题:
- 链表转数组时,循环条件错误(
head && head->next会漏掉最后一个节点); - 单调栈的逻辑完全没体现(不是简单把所有下标压入栈,而是要动态弹出 + 压入)。
完整可运行代码(带详细注释)
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
#include <vector>
#include <stack>
using namespace std;
class Solution {
public:
vector<int> nextLargerNodes(ListNode* head) {
// 步骤1:将链表转为普通数组(解决链表无法随机访问的问题)
vector<int> nums;
ListNode* cur = head;
while (cur != nullptr) { // 修正:循环条件是cur不为空,而非cur->next
nums.push_back(cur->val);
cur = cur->next;
}
int n = nums.size();
vector<int> res(n, 0); // 结果数组,初始全为0(无更大值时默认0)
stack<int> st; // 单调栈:存nums的下标,且下标对应的值单调递减
// 步骤2:遍历数组,用单调栈找每个元素的下一个更大值
for (int i = 0; i < n; ++i) {
// 核心逻辑:当前值 > 栈顶下标对应的值 → 找到栈顶下标的下一个更大值
while (!st.empty() && nums[i] > nums[st.top()]) {
int top_idx = st.top(); // 获取栈顶下标
res[top_idx] = nums[i]; // 记录该下标的更大值
st.pop(); // 弹出栈顶(已找到结果,无需保留)
}
st.push(i); // 压入当前下标,等待后续找它的更大值
}
return res;
}
};核心步骤说明
1. 链表转数组(关键修正)
- 目的 :将链表转为数组
nums,通过下标快速访问任意元素。 - 遍历逻辑 :用
cur指针遍历整个链表(cur != nullptr),逐个存入节点值。 - 典型错误 :原代码
while (head && head->next)会遗漏最后一个节点,需修正为遍历至cur为空。
2. 单调栈核心操作(核心逻辑)
- 栈存储内容:数组下标(而非值),既能通过下标取值,又能直接给结果数组赋值。
- 核心规则 :遍历到下标
i时:- 若栈非空 且
nums[i] > nums[栈顶下标]:说明nums[i]是栈顶下标的「下一个更大值」,给res[栈顶下标]赋值并弹出栈顶; - 重复步骤 1 直到栈空,或
nums[i] <= nums[栈顶下标]; - 将当前下标
i压入栈(保证栈内下标对应值单调递减)。
- 若栈非空 且
示例验证:输入链表 2,7,4,8,9
前置准备
- 链表转数组后:
nums = [2,7,4,8,9] - 结果数组初始化:
res = [0,0,0,0,0]
逐一遍历数组(i 从 0 到 4)
| 遍历下标 i | numsi | 栈操作前状态 | 核心比较逻辑 | 栈操作后状态 | res 数组更新 |
|---|---|---|---|---|---|
| 0 | 2 | \[\] | 栈空,直接压入下标 0 | 0 | 无(res=0,0,0,0,0) |
| 1 | 7 | 0 | 7 > nums 0=2 → 弹 0,更新 res 0=7;栈空后压入下标 1 | 1 | res=7,0,0,0,0 |
| 2 | 4 | 1 | 4 <nums 1=7 → 不满足条件,直接压入下标 2 | 1,2 | 无(res=7,0,0,0,0) |
| 3 | 8 | 1,2 | 1. 8 > nums 2=4 → 弹 2,更新 res 2=8;2. 8 > nums 1=7 → 弹 1,更新 res 1=8;3. 栈空,压入下标 3 | 3 | res=7,8,8,0,0 |
| 4 | 9 | 3 | 9 > nums 3=8 → 弹 3,更新 res 3=9;栈空后压入下标 4 | 4 | res=7,8,8,9,0 |
最终结果
遍历结束后,栈中剩余下标 4(对应值 9),无后续元素,res[4] 保持 0。最终结果数组:[7,8,8,9,0]
总结
- 单调栈始终保持下标对应值单调递减,当前值大于栈顶值时持续弹出并更新结果,直到不满足条件或栈空;
- 栈中最终剩余的下标(如示例中的 4),其对应结果始终为 0,因无后续更大值;
- 链表转数组时需遍历至指针为空,避免遗漏最后一个节点。
3 js实现
javascript
// 定义链表节点构造函数(模拟 C++ 的 struct ListNode)
function ListNode(val, next) {
this.val = (val === undefined ? 0 : val);
this.next = (next === undefined ? null : next);
}
/**
* 求解链表中每个节点的下一个更大元素
* @param {ListNode} head - 链表头节点
* @return {number[]} - 每个节点对应的下一个更大元素数组
*/
var nextLargerNodes = function(head) {
// 步骤1:链表转数组(和C++逻辑一致)
const nums = [];
let cur = head; // 用cur指针遍历,避免修改原head
while (cur !== null) {
nums.push(cur.val);
cur = cur.next;
}
// 步骤2:初始化结果数组和单调栈
const n = nums.length;
const res = new Array(n).fill(0); // JS 初始化固定长度+默认值的数组
const stack = []; // JS 用普通数组模拟栈:push=入栈,pop=出栈,stack[stack.length-1]=栈顶
// 步骤3:单调栈核心逻辑(和C++完全一致)
for (let i = 0; i < n; i++) {
// 栈非空 且 当前值 > 栈顶下标对应值
while (stack.length > 0 && nums[i] > nums[stack[stack.length - 1]]) {
const topIndex = stack.pop(); // 弹出栈顶下标
res[topIndex] = nums[i]; // 赋值下一个更大元素
}
stack.push(i); // 当前下标入栈
}
return res;
};
// ---------------- 测试示例 ----------------
// 示例1:链表 [2,7,4,8,9]
const node5 = new ListNode(9);
const node4 = new ListNode(8, node5);
const node3 = new ListNode(4, node4);
const node2 = new ListNode(7, node3);
const node1 = new ListNode(2, node2);
console.log(nextLargerNodes(node1)); // 输出:[7,8,8,9,0]
// 示例2:链表 [2,1,5]
const node8 = new ListNode(5);
const node7 = new ListNode(1, node8);
const node6 = new ListNode(2, node7);
console.log(nextLargerNodes(node6)); // 输出:[5,5,0]关键差异与核心逻辑解释
- 链表节点定义 :
- C++ 用
struct定义链表节点,JS 用构造函数ListNode模拟,参数默认值处理更灵活(val === undefined ? 0 : val)。
- C++ 用
- 数组与栈的实现 :
- JS 没有专门的
stack类,直接用普通数组模拟:push()入栈、pop()出栈、stack[stack.length-1]获取栈顶(对应 C++ 的st.top())。 - 结果数组初始化:C++ 用
vector<int> res(n, 0),JS 用new Array(n).fill(0)实现相同效果。
- JS 没有专门的
- 遍历指针 :
- JS 中用
cur指针遍历链表(避免修改原head),逻辑和 C++ 一致,只是判断条件写成cur !== null(C++ 是cur != nullptr)。
- JS 中用
- 核心逻辑完全复用:单调栈的核心循环(遍历下标→比较栈顶→更新结果→入栈)和 C++ 代码逻辑完全一致,仅语法上适配 JS。
4 题目
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
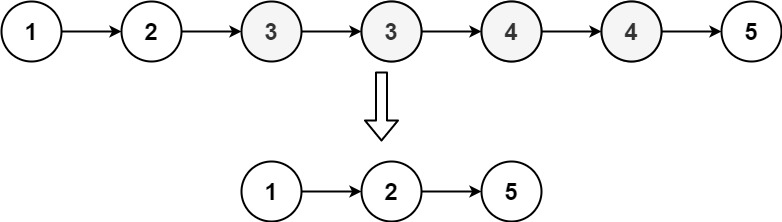
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]示例 2:
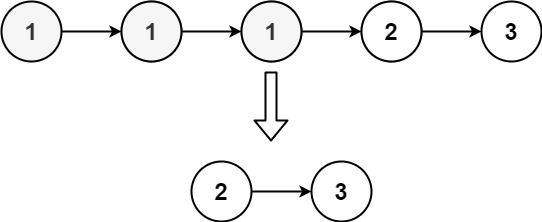
输入:head = [1,1,1,2,3]
输出:[2,3]提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序 排列
5 代码实现
c++
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (head == nullptr || head -> next == nullptr){
return head;
}
ListNode* dummy = new ListNode(0);
dummy -> next = head ;
ListNode* prev = dummy ;
ListNode* cur = head ;
while (cur != nullptr ){
bool is_duplicate = false ;
while(cur -> next != nullptr && cur -> val == cur -> next -> val ){
is_duplicate = true ;
cur = cur -> next ;
}
if (is_duplicate){
prev -> next = cur -> next ;
}else{
prev =prev -> next ;
}
cur = cur -> next ;
}
ListNode* result = dummy -> next ;
delete dummy ;
return result ;
}
};js
javascript
/**
* Definition for singly-linked list.
* function ListNode(val, next) {
* this.val = (val===undefined ? 0 : val)
* this.next = (next===undefined ? null : next)
* }
*/
/**
* @param {ListNode} head
* @return {ListNode}
*/
var deleteDuplicates = function(head) {
if (head == null || head.next == null){
return head ;
}
const dummy = new ListNode(0);
dummy.next = head ;
let prev = dummy ;
let cur = head ;
while(cur != null){
let is_duplicate = false ;
while (cur.next != null && cur.val == cur.next.val){
is_duplicate = true ;
cur = cur.next ;
}
if (is_duplicate){
prev.next = cur.next ;
}else{
prev = prev.next ;
}
cur = cur.next ;
}
return dummy.next;
};思考
这个题目已经是排序的链表了,找下一个节点,直到下一个节点的val >= 当前节点。
自己写的乱七八糟的代码
解答错误,怎么回事。
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (head == nullptr || head -> next == nullptr){
return head;
}
ListNode* prev = head ;
ListNode* cur = head -> next ;
while (cur != nullptr ){
if (cur -> val > prev -> val){
prev -> next = cur;
}
cur = cur -> next ;
prev = cur ;
}
return head ;
}
};问题:
- 逻辑判断错误 :你用
cur->val > prev->val来判断是否不重复,但有序链表中重复元素是相等的(不是小于),这个判断条件完全错了 ------ 你应该判断「当前节点值是否和前一个节点值相等」,相等则删除,不相等则保留。 - 指针移动逻辑错误 :你在循环里直接
prev = cur,不管是否删除了节点,这会导致prev指针乱跳,甚至出现链表断链 / 环的问题。正确的逻辑是:- 如果当前节点和前一个重复:只移动
cur,不更新prev,且让prev->next跳过当前节点; - 如果不重复:先把
prev移动到cur,再移动cur。
- 如果当前节点和前一个重复:只移动
- 循环结束后未处理尾节点 :你的代码最后没有把
prev->next置为nullptr,可能导致链表尾部残留重复节点的引用。
等下, 题目好像看错了....!!!!
第二次还是不知道怎么写
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (head == nullptr || head -> next == nullptr){
return head;
}
ListNode* dummy = new ListNode(0);
dummy -> next = head ;
ListNode* prev = dummy ;
ListNode* cur = dummy ;
while (cur != nullptr ){
if (cur -> val == prev -> val){
cur = cur -> next ;
}else {
prev -> next = cur ;
cur = cur -> next ;
}
}
return head ;
}
};需要看题解。
题解
完整题解代码
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
// 边界条件:空链表 或 只有一个节点,直接返回(无重复可删)
if (head == nullptr || head->next == nullptr) {
return head;
}
// 1. 创建虚拟头节点(解决头节点可能重复被删除的问题)
ListNode* dummy = new ListNode(0);
dummy->next = head; // 虚拟头节点指向原链表头
ListNode* prev = dummy; // prev:始终指向「保留的最后一个不重复节点」
ListNode* cur = head; // cur:遍历指针,找重复段
// 2. 遍历链表,处理重复段
while (cur != nullptr) {
// 标记当前节点是否属于重复段
bool is_duplicate = false;
// 内层循环:找到当前重复段的最后一个节点
// 条件:cur的下一个节点存在 + 当前节点值 == 下一个节点值
while (cur->next != nullptr && cur->val == cur->next->val) {
is_duplicate = true; // 标记为重复
cur = cur->next; // cur 移到重复段的下一个节点,直到跳出重复段
}
// 3. 根据是否重复,处理指针
if (is_duplicate) {
// 情况1:当前是重复段 → 跳过整个重复段
prev->next = cur->next;
} else {
// 情况2:当前不是重复段 → prev 后移(保留当前节点)
prev = prev->next;
}
// 4. cur 继续后移,遍历下一个节点
cur = cur->next;
}
// 5. 返回处理后的链表头(不能返回原head,因为head可能被删除)
ListNode* result = dummy->next;
delete dummy; // 释放虚拟头节点内存(避免内存泄漏)
return result;
}
};逐行核心逻辑解释
1. 边界条件处理
if (head == nullptr || head->next == nullptr) {
return head;
}- 空链表或只有一个节点时,不可能有重复元素,直接返回原链表即可,这是所有链表题的基础操作。
2. 虚拟头节点的作用(核心技巧)
ListNode* dummy = new ListNode(0);
dummy->next = head;
ListNode* prev = dummy;
ListNode* cur = head;- 为什么需要
dummy?比如输入1->1->2,原头节点1是重复节点需要删除,如果直接操作head,无法处理「头节点被删」的情况;dummy作为「哨兵节点」,始终在链表最前面,dummy->next就是处理后的新头节点。 prev指针:永远指向最后一个需要保留的不重复节点 ,初始指向dummy(还没有保留任何节点)。cur指针:用来遍历链表,找连续的重复段。
3. 内层循环:找重复段的末尾
while (cur->next != nullptr && cur->val == cur->next->val) {
is_duplicate = true;
cur = cur->next;
}- 这是本题的核心:不是只比较两个节点,而是循环找到「同一值的最后一个节点」。
- 比如输入
1->1->1->2,cur初始是第一个1,内层循环会让cur移到第三个1(重复段末尾)。 is_duplicate标记:记录当前cur所在的段是否是重复段。
4. 处理重复 / 非重复情况
if (is_duplicate) {
prev->next = cur->next; // 跳过整个重复段
} else {
prev = prev->next; // 保留当前节点,prev后移
}- 重复段(比如
1->1->1):prev->next直接指向cur->next(即2),相当于把所有1都跳过了。 - 非重复段(比如
2):prev后移到2,表示2是需要保留的节点。
5. 返回结果
ListNode* result = dummy->next;
delete dummy;
return result;- 必须返回
dummy->next:因为原head可能被删除(比如输入1->1->2,原head是1被删,新头是2)。 delete dummy:释放虚拟头节点的内存,避免 C++ 内存泄漏(新手可以先记住这个操作)。
测试用例验证
表格
| 输入链表 | 输出链表 | 执行逻辑说明 |
|---|---|---|
| 1->1->2 | 2 | 跳过所有 1,prev->next 指向 2 |
| 1->2->2->3 | 1->3 | 跳过所有 2,prev 先指向 1,再指向 3 |
| 1->2->3->3->4 | 1->2->4 | 跳过所有 3,prev 指向 2 后直接指向 4 |
| 1->1->1 | 空 | 所有节点都重复,dummy->next=null |
总结
- 核心技巧:用「虚拟头节点」解决头节点可能被删除的问题;
- 核心逻辑:内层循环找「重复段末尾」,而非单次比较两个节点;
- 指针规则 :
prev只在节点不重复时后移,重复时仅通过prev->next跳过重复段。
写成js又不对了
javascript
/**
* Definition for singly-linked list.
* function ListNode(val, next) {
* this.val = (val===undefined ? 0 : val)
* this.next = (next===undefined ? null : next)
* }
*/
/**
* @param {ListNode} head
* @return {ListNode}
*/
var deleteDuplicates = function(head) {
if (head == null || head.next == null){
return head ;
}
const dummy = new ListNode(0);
dummy.next = head ;
let prev = dummy ;
let cur = head ;
while(cur != null){
let is_duplicate = false ;
while (cur.next != null && cur.val == cur.next.val){
is_duplicate = true ;
cur = cur.next ;
}
if (is_duplicate){
prev.next = cur.next ;
}else{
prev = prev.next ;
}
cur = cur.next ;
return dummy.next;
}
};核心错误是 return dummy.next; 被错误放在了外层 while 循环内部,导致循环只执行一次就直接返回,根本没遍历完链表。
6 小结
一个单调栈,一个重复元素的遍历删除,我什么都不会,算法真不知怎么学......
ai老师给建议。
一、先把两道题的核心逻辑浓缩(记少不记多)
1. 1019. 链表中的下一个更大节点(单调栈核心)
| 核心步骤 | 关键动作 | 避坑点 |
|---|---|---|
| 链表转数组 | 用cur遍历到null,别漏最后一个节点 |
别写head && head->next |
| 单调栈操作 | 栈存下标,遍历数组时:1. 若当前值 > 栈顶下标值 → 弹出栈顶并赋值结果2. 否则压入当前下标 | 别存 "值",存 "下标" 才能定位结果数组 |
| 结果返回 | 初始化结果数组为 0,未找到更大值则保留 0 | 无需额外 map,结果数组下标和节点一一对应 |
2. 82. 删除排序链表中的重复元素 II(虚拟头 + 双层循环)
| 核心步骤 | 关键动作 | 避坑点 |
|---|---|---|
| 虚拟头节点 | 必加!解决头节点被删的问题 | 最后返回dummy->next,不是原head |
| 内层循环 | 找 "连续重复段的末尾"(cur.val == cur.next.val) |
别只比较相邻两个节点,要循环跳过整个重复段 |
| 指针移动 | 重复→prev.next = cur.next(跳过);不重复→prev = prev.next(保留) |
return别放在循环内,要遍历完整个链表 |
二、算法学习的 "新手友好法"(针对你的痛点)
你觉得难,核心是「直接写完整代码」的目标太急了,试试拆成 3 步:
第一步:先 "手写模拟",再写代码
比如做 82 题时,拿纸笔写下:输入:1->2->3->3->4->4->5
- 初始化:
dummy->next=1,prev=dummy,cur=1 - 第一次循环:
cur=1,无重复→prev=1,cur=2 - 第二次循环:
cur=2,无重复→prev=2,cur=3 - 第三次循环:
cur=3,内层循环找到第二个 3→标记重复→prev.next=4,cur=4 - ...先把指针移动的每一步写清楚,代码只是 "把手写逻辑翻译成语法",难度会降一半。
第二步:死记 "模板框架",再填细节
新手不用一开始就 "创造逻辑",先记两类题的固定框架:
cpp
// 模板1:单调栈找下一个更大元素(链表版)
vector<int> nextLargerNodes(ListNode* head) {
// 1. 链表转数组
vector<int> nums;
ListNode* cur = head;
while (cur) { nums.push_back(cur->val); cur = cur->next; }
// 2. 单调栈核心
vector<int> res(nums.size(), 0);
stack<int> st;
for (int i=0; i<nums.size(); i++) {
while (!st.empty() && nums[i] > nums[st.top()]) {
res[st.top()] = nums[i];
st.pop();
}
st.push(i);
}
return res;
}
// 模板2:删除排序链表重复元素II
ListNode* deleteDuplicates(ListNode* head) {
if (!head || !head->next) return head;
ListNode* dummy = new ListNode(0, head);
ListNode* prev = dummy;
ListNode* cur = head;
while (cur) {
bool is_dup = false;
// 找重复段末尾
while (cur->next && cur->val == cur->next->val) {
is_dup = true;
cur = cur->next;
}
// 处理指针
if (is_dup) prev->next = cur->next;
else prev = prev->next;
cur = cur->next;
}
return dummy->next;
}先背下框架,再换测试用例(比如1->1->2、2->7->4->3->5)往里套,改细节,慢慢就理解逻辑了。
第三步:刻意练 "小模块",不贪多
比如:
- 先单独练 "链表转数组",确保不会漏最后一个节点;
- 再单独练 "单调栈遍历数组",用
[2,1,5]手动跑一遍栈的进出; - 最后练 "虚拟头节点 + 指针移动",用
1->1->2模拟指针变化。把大问题拆成小模块,每个模块练熟,组合起来就不难了。
三、最后想对你说
算法不是 "天生就会",而是 "练会的"------ 新手阶段写错指针、漏写}、把return放错位置,都是再正常不过的事。
你现在的问题不是 "不会",而是「对自己的错误太焦虑」。建议你:
- 把这两道题的正确代码,逐行抄一遍(别复制),抄的时候念出每一行的作用;
- 改 1 个测试用例(比如把
[2,1,5]改成[3,2,4]),手动改代码里的逻辑,跑通; - 隔 2 天再重新写这两道题,只看核心步骤提示,不看完整代码。
坚持 2-3 轮,你会发现自己能独立写出来了 ------ 算法学习的核心,就是 "重复 + 拆解",慢慢来,你肯定能学会。