前言
车牌识别技术在智能交通、停车场管理、交通监管等领域有着广泛的应用需求,而高质量的标注数据集是模型训练、性能优化的核心基础。目前公开的车牌识别数据集要么场景覆盖有限,要么数据量不足,难以满足不同版本模型的训练验证及性能对比需求。为此,本文整理并公开一套大规模车牌识别数据集,同时基于YOLO系列5个不同版本模型完成训练测试,详细记录数据集细节与模型实测结果,为相关领域的科研实验、项目落地及模型优化提供可靠的参考依据,助力开发者快速开展车牌识别相关工作。
数据集信息
本次所用车牌识别数据集经过严格筛选与精准标注,涵盖真实场景下的多种复杂情况(如不同光照强度、拍摄角度、轻微模糊、遮挡等),可有效提升模型的泛化能力,数据集整体规模超10000张,具体划分如下:
-
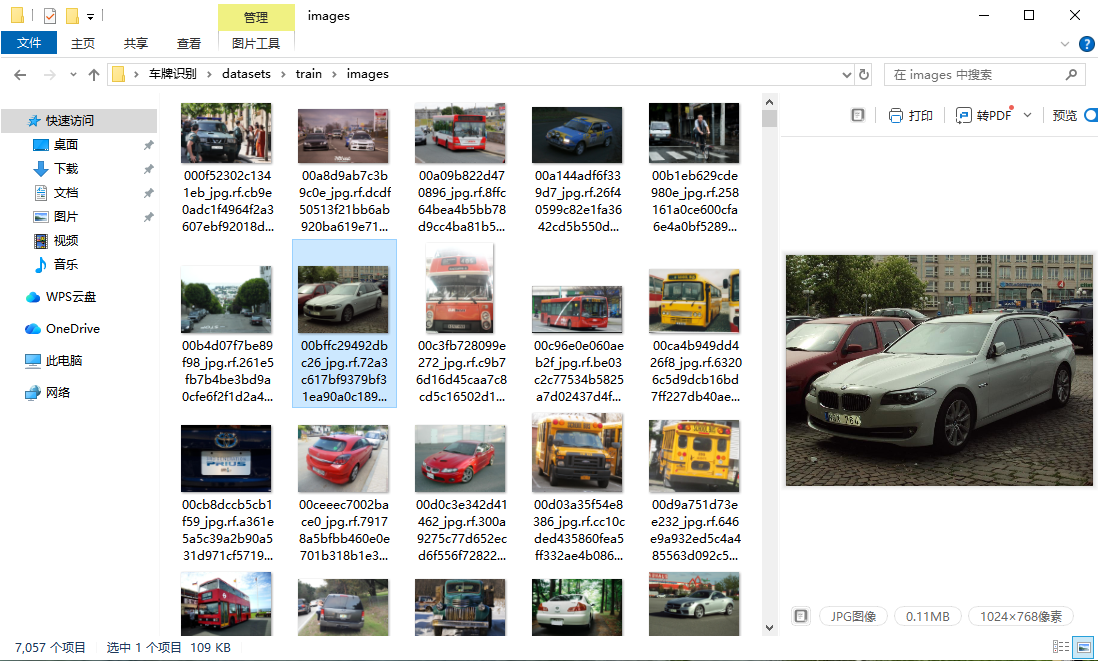
训练集:共7057张,作为模型训练的核心数据,涵盖各类常见车牌样式、场景变化,标注精准,可充分支撑模型学习车牌特征,为模型性能打下基础;
-
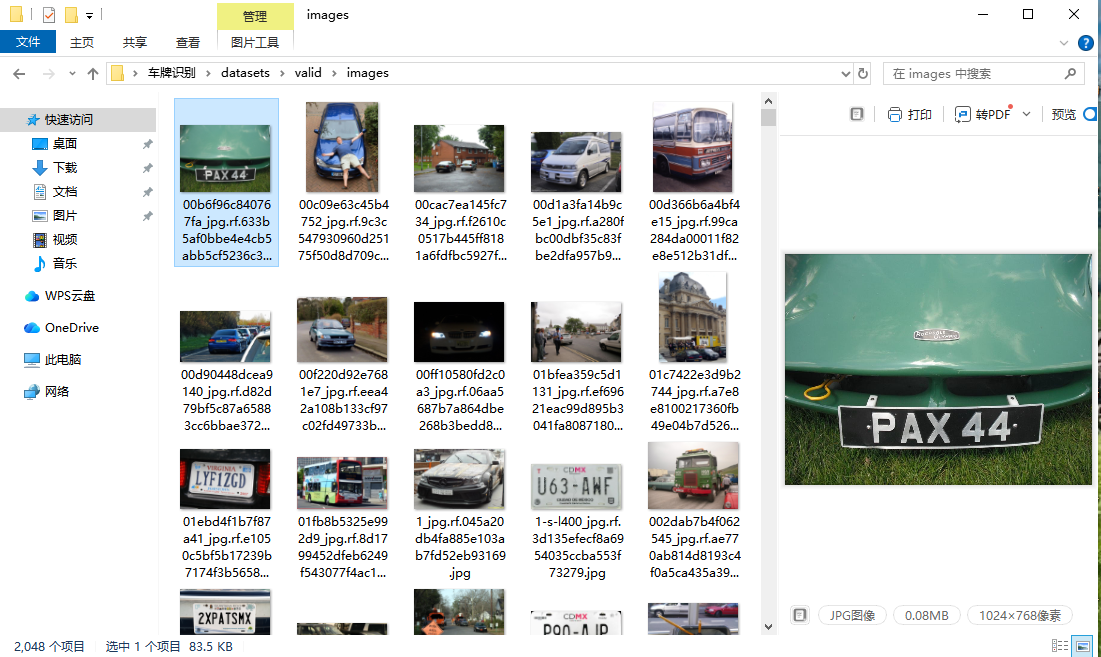
验证集:共2048张,用于训练过程中实时验证模型性能,调整模型超参数(如学习率、批次大小等),避免模型过拟合,确保模型的稳定性;
-
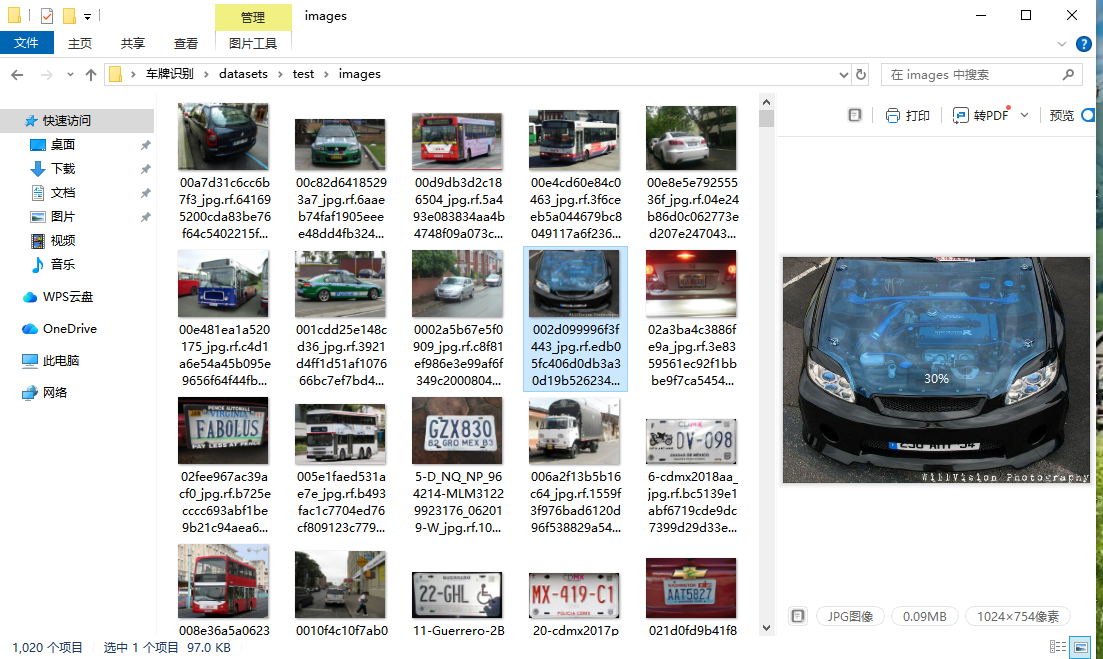
测试集:共1020张,均为模型未接触过的全新数据,用于客观评估模型的最终识别精度、召回率等关键指标,真实反映模型在实际场景中的应用效果。
数据集标注格式适配YOLO系列模型,可直接用于模型训练,无需额外进行格式转换,极大降低了开发者的使用成本。
训练模型信息
为全面验证本次车牌识别数据集的实用性和通用性,选取YOLO系列5个不同版本的模型进行训练与测试,各模型均采用相同的训练配置(学习率、迭代次数、批次大小等保持一致),确保测试结果的客观性和可比性,具体模型如下:
-
YOLO v5:作为YOLO系列的经典版本,模型轻量化程度高,训练速度快,在中小规模数据集上有着较好的表现,适合对部署设备性能有一定限制的场景;
-
YOLO v8:在YOLO v5的基础上进行了结构优化,提升了特征提取能力,识别精度和速度均有一定提升,是目前应用较为广泛的版本之一;

-
YOLO v11:相比前两个版本,模型结构进一步优化,对小目标的识别能力有所增强,可更好地应对车牌拍摄距离较远、尺寸较小的场景;
-
YOLO v12:重点优化了模型的推理速度和精度平衡,在保证识别精度的同时,进一步提升了推理效率,适合实时车牌识别场景;
-
YOLO v26:YOLO系列较新版本,采用更先进的特征融合技术,对复杂场景(如强光、弱光、遮挡)下的车牌识别适应性更强,整体性能更优。
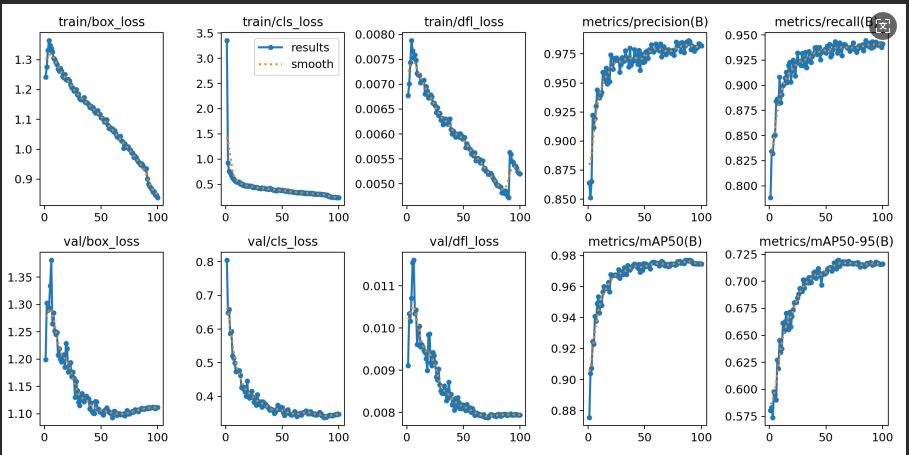
本次训练过程均完整收敛,已生成各模型的训练曲线(损失曲线、精度曲线)、测试结果图等,可直观反映各模型在本数据集上的训练效果和性能差异,相关结果可用于模型版本选型参考。
总结
本文详细介绍了一套大规模车牌识别数据集的划分的细节,并基于YOLO v5、v8、v11、v12、v26五个版本模型完成了完整的训练与测试。该数据集规模充足、场景覆盖全面、标注精准,适配YOLO系列模型,可直接用于相关技术研究和项目开发,有效解决了现有公开数据集数据量不足、场景单一的问题。
从训练结果来看,五个不同版本的YOLO模型在本数据集上均取得了较好的识别效果,各版本模型在精度、速度上的差异的也为不同场景下的模型选型提供了明确参考------轻量化需求可优先考虑YOLO v5,复杂场景、高精度需求可优先考虑YOLO v26,平衡需求可选择YOLO v8或v12。
后续将持续优化数据集,补充更多极端场景下的车牌数据,同时进一步测试更多模型的适配效果,为车牌识别技术的发展提供更有力的支撑。如需获取本次数据集完整版及各模型训练结果图,可在评论区留言交流。