文章目录
摘要
自回归模型应用到视觉领域有所拓展,但是没有达到自回归模型在语言处理领域的GPT时刻,本周看到一篇探索自回归模型如何达到GPT时刻的论文。
Abstract
Autoregressive models have been applied in the visual field, but they have not yet reached the 'GPT moment' that autoregressive models achieved in language processing. This week, I came across a paper exploring how autoregressive models could reach the GPT moment.
1 RandAR

Auto-Regressive (AR) 范式,提供了把所有文本任务、文本应用统一在一起的Formulation。
结合Decoder-only结构,Next-token Prediction使得大规模训练对Infra友好、可以非常高效。
正因为第一点"统一的Formulation",可以收集海量数据,最终得到一个能够Zero-shot泛化的大模型。
是什么限制了这些模型复刻GPT范式的成功:按照一维的顺序做Next-token Prediction,势必要把二维的Image Tokens转化成一维的序列,而之前的方法在这里采用了一个提前规定好的顺序------Raster-Order,也就是从图片的左上角开始一行一行地生成Image Tokens,
无法按照任意顺序处理Image Tokens,所以很显然,他们面对editing任务或者针对图片特定区域Perception的任务会很挣扎。因此,这样的Next-token Prediction很难成为"把所有任务统一在一起的Formulation"------也就是违背了上面GPT成功的第一个条件。
无法Zero-shot泛化,也正是因为生成顺序的限制,这样的模型很难未经训练直接泛化到新的场景上,比如说新的图片分辨率(resolution)、提取图片的Representation。也就违背了上面的第三个条件。
RandAR的起点:
让一个和GPT相同的Decoder-only Transformer可以按照Random-order生成图像
RandAR可以Zero-shot泛化到新的场景上,包括但不限于一些全新的角度------Parallel Decoding (next set-of-token)、生成更高分辨率图片,而且它还可以直接做Generative Model的另一面------Representation Learning。
既然我们想要让模型可以生成任意顺序的图像Token,那么我们需要把顺序用某种方式"告诉"模型。我们用一种特殊的Token,叫做"Position Instruction Tokens",代表下一个需要生成的Image Token在哪个位置,来指导模型生成Image Tokens。
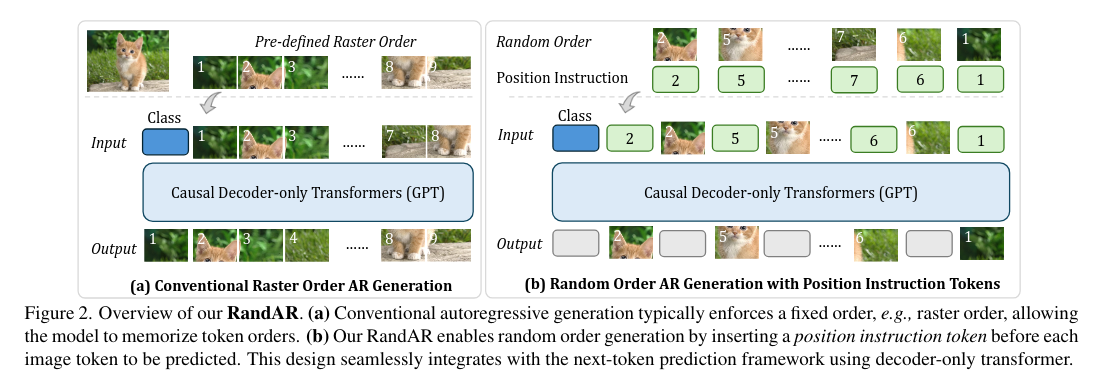
Parallel Decoding:每一步同时生成多个来自随机位置的Token即可。这样的方式可以直接提速2.5倍,而不会带来任何的FID降低。这是由训练的随机性天然得到的,不需要任何的微调和改变。
图像编辑、Inpainting、Outpainting:可以处理任意顺序,我们的RandAR可以解决这两种应用。方法很简单:把所有已知的上下文(Context Tokens)放在一开始,然后让模型去生成新的Tokens。
Zero-shot放大分辨率:模型是在256x256的图片上训练的,那么它的参数是否可以直接生成更大分辨率,例如512x512的图片?在这里,我们特殊强调要求图片必须展示一个unified object,而不是通过Outpainting可以实现。我们因为可以控制生成顺序,所以提出了两步走的方法:
第一步先找对应低分辨率的Token生成,得到全局结构
第二步再去填充高分辨率的Token,得到高频细节
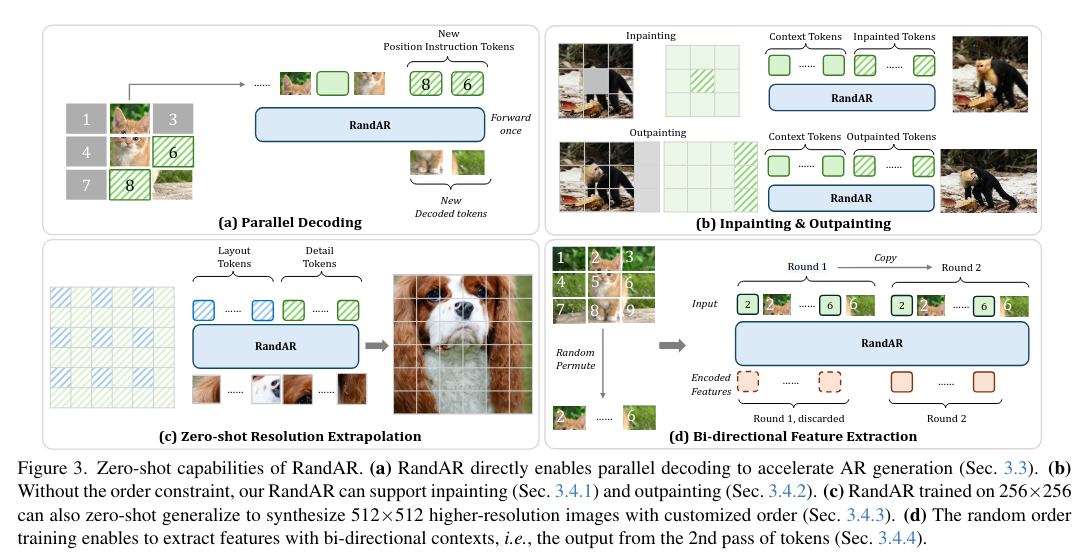
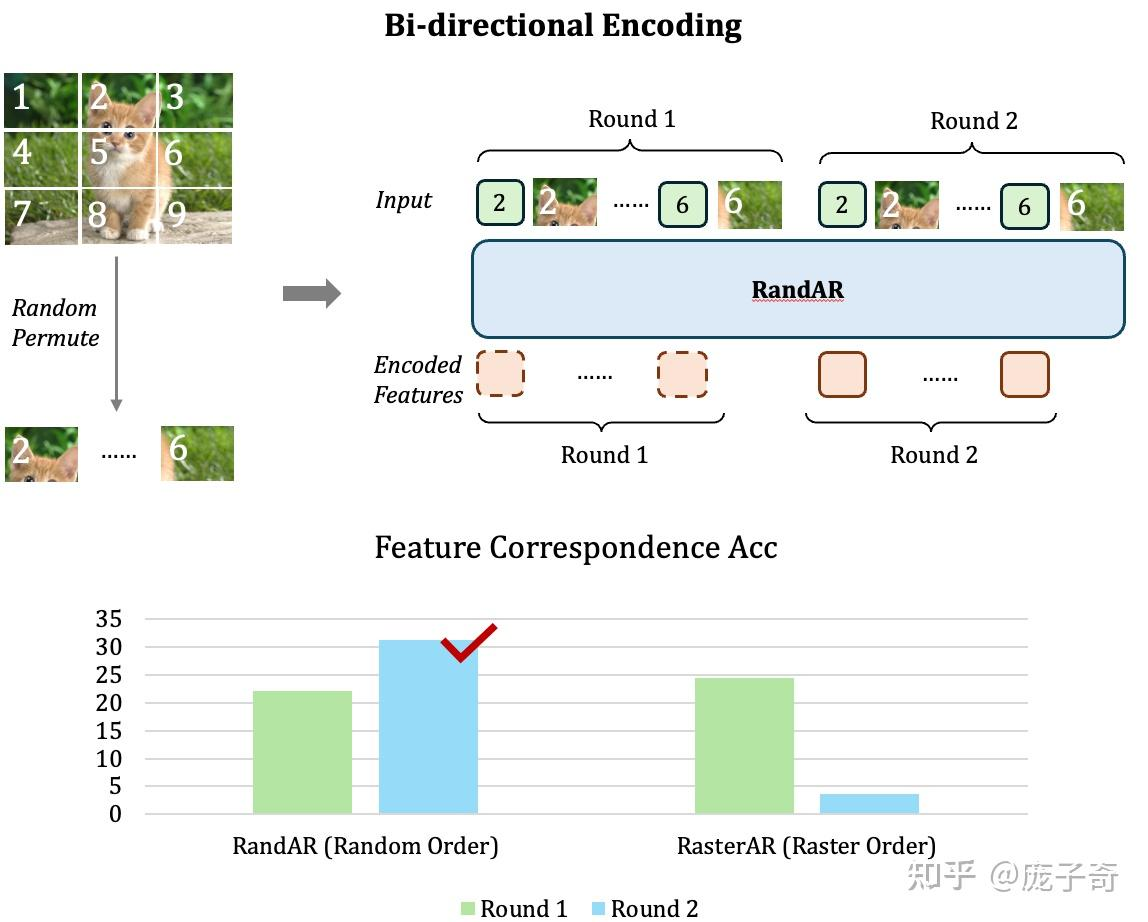
Representation Learning:Decoder-only模型采用的是Causal Attention,也就意味着在序列中靠前的Token没有办法"看见"在后面的Token,那它的Representation就只能代表很少的一部分信息。最极端的例子就是------第一个图片Token只有它自己Patch的信息,根本无法知道图片的其它位置。
一个直接的解决办法就是------把图像Token序列再输入一遍,然后只取第二轮序列的Representation,这样每个图片Token都可以得到完整的图片信息了。从对比中可以看到,使用了Random-order的模型可以直接泛化到这种提取Representation的方式,但是按照Raster-order训练的模型却会直接崩掉。
总结
RandAR与RAR的思路很类似,也提出了很好的思路,后续会将这个工程复现。