核心结论:Gemini 3 在多模态处理上实现了全方位领先
从技术架构、基准测试和实际应用三个维度来看,Gemini 3 在多模态处理能力上明显优于 GPT-5.1,这主要得益于其原生多模态设计理念和突破性的技术实现。
一、架构差异:原生融合 vs 工程集成
表格对比维度Gemini 3GPT-5.1设计理念原生多模态架构,从训练之初就将文本、图像、视频、音频等所有信息统一转化为向量 Token 处理,彻底抛弃外挂式编码器采用"模态拼接"的折中方案,将图像编码器外挂到语言模型上,通过工程集成实现多模态功能核心优势实现了多模态数据的无缝协同,如同"手机原生搭载全能摄像头",避免了传统模型"各模态独立处理后拼凑"导致的逻辑断裂文本处理能力依然强大,但跨模态推理时容易出现信息断层和逻辑不一致技术实现采用"分层注意力机制+稀疏混合专家(Sparse MoE)"设计,视觉、音频、文本等数据先进入各自专属"专业工作室"进行特征提取,推理阶段通过全局注意力机制实现多模态信息的集中"协同决策"基于文本模型的基础上扩展多模态能力,在处理复杂跨模态任务时效率较低
二、基准测试:断层式领先
在多项权威多模态基准测试中,Gemini 3 取得了碾压性的优势:
MMMU-Pro(多模态理解与推理) :Gemini 3 得分 81.0%,领先 GPT-5.1(76.0%)多达 5 个百分点,表明其在处理复杂的跨模态输入时,能更有效地进行深度推理。
Video-MMMU(视频理解) :Gemini 3 得分 87.6%,远超 GPT-5.1 的未公开数据与 Claude 4.5 不足 70% 的成绩,证明其在理解视频内容的时间序列和上下文关系方面具有显著优势。
ScreenSpot-Pro(屏幕界面理解) :Gemini 3 取得 72.7% 的高分,而 GPT-5.1 在该测试中仅为个位数百分比的水平。这意味着 Gemini 3 可以"看懂"软件界面,为计算机使用智能体(Computer Use Agents)的性能提升奠定了基础。
CharXiv Reasoning(复杂图表信息合成) :Gemini 3 取得了 81.4% 的高分,表明其能够从复杂的、专业化的视觉数据(如金融图表、SAAS 界面截图)中准确提取并合成信息。
三、实际应用能力对比
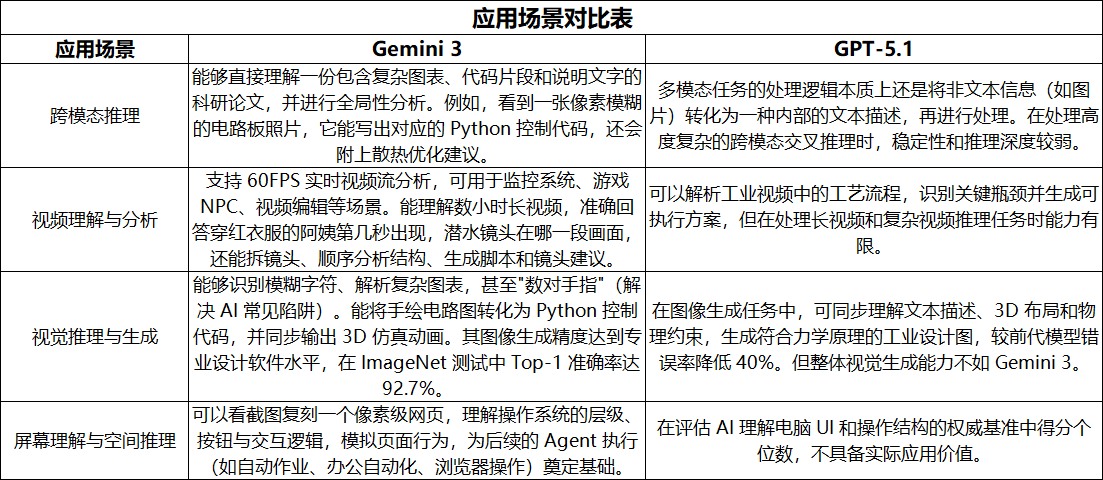
四、总结
Gemini 3 在多模态处理上的优势主要体现在以下几个方面:
原生多模态架构:从训练之初就将所有模态信息统一处理,实现了真正的跨模态深度融合。
强大的视觉推理能力:能够理解复杂图表、UI 界面、视频内容等,并进行深度推理和生成。
超长上下文窗口:支持 100 万 Token 上下文,能够处理完整的代码库、长文档或数小时的视频。
智能体能力:能够自主调用工具,执行多步骤任务,从"对话"升级到"行动"。