LLMs之Benchmark:《CL-bench: A Benchmark for Context Learn》翻译与解读
导读 :CL-bench 提出并量化了"上下文学习"(Context Learning)这一关键但被忽视的能力:通过精心构造的 500 个真实/无污染上下文与严谨的多维 rubric 评估,证明当前 LLM 在从复杂上下文中即时学习并应用新知识方面仍远未成熟,并给出了训练数据、课程化训练、自动 rubrics 与架构改进等明确的发展路线以指导下一步研究与产品化改进。
>> 背景痛点:
● 任务复杂性:现实世界任务高度依赖上下文,很多问题需要模型从"任务专属的复杂上下文"中学到新知识来推理,而非仅靠预训练知识。此类任务超出常规长文本检索或简单的 in-context learning。
● 语料污染风险:若基准数据与模型预训练语料重合,就无法检验"从上下文学到新知识"的能力,需避免数据泄露与污染。
● 评估难度:复杂任务常有多维正确性(事实、计算、程序、格式等),难以用单一规则自动判定,需要精细且可验证的判分机制。
● 长上下文瓶颈:随着输入长度增长,模型对关键信息的追踪与综合能力显著下降,成为上下文学习的主要瓶颈。
● 指令与格式遵从差:即便能读到相关信息,模型也经常违反明确的格式或执行约束,影响最终可用性。
>> 具体的解决方案(CL-bench 提供的设计与方法):
● 基准总体设计:构建CL-bench------500 个复杂上下文、1,899 个任务、31,607 条验证 rubric,任务所需新知识都包含在对应上下文内,避免外部检索。
● 上下文分类(治理范围化):将上下文分为 4 大类 18 个子类(领域知识推理、规则体系应用、程序性执行、经验发现与仿真),覆盖广泛真实场景。
● 污染防护策略:通过(1)虚构创建、(2)修改现有内容、(3)纳入小众/新兴内容三种方式生成"contamination-free"上下文,确保所需知识不在预训练中普遍存在。
● 严谨的自动化评估:为每个任务设计多维二元判别 rubric(平均 16.6 条/任务、平均 63.2 条 rubric/上下文),并用强 LM(GPT-5.1)作为判别器,严格"全部通过才算解出"。 验证显示评估器间一致性 >90%。
>> 核心思路步骤(从构建到评估的流水线):
● 上下文设计:由资深领域专家设计完整上下文(真实或虚构/修改/小众),确保信息充足且可解题。每个上下文平均耗时 ~20 小时专家工时。
● 任务设计:针对每个上下文设计多道相关任务(平均 3.8 题/上下文),含顺序依赖(约 51.1% 为多回合依赖)以模拟真实使用情境。
● Rubric 编写:为每题写多条二元判定 rubrics,覆盖事实/计算/判断/流程/格式等维度,支持自动化严格评估。
● 评估执行:在"thinking/high reasoning"设置下,用十款前沿 LLM(含 GPT-5.1/5.2、Claude、Gemini 等)通过 API 批量生成答案并由 GPT-5.1 验证器逐条核验。
>> 优势(CL-bench 相较于以往基准的价值点):
● 真实且多样:覆盖 4 大类、18 子类,包含产品手册、实验数据、虚构法律系统等多种上下文类型,接近实际应用场景。
● 无污染设计:通过三种策略确保上下文知识超出模型预训练语料,从而真正测评"从上下文学新知识"的能力。
● 评估严格且可扩展:细粒度二元 rubric + LM 判分器实现可复现、高一致性的自动评估,便于规模化实验和 leaderboard。
● 多回合与组合难度:支持顺序依赖任务,测试模型的持续学习、记忆与累积推理能力,而非单次检索或简答。
>> 论文中的结论与经验性观点(侧重建议与可操作经验):
● 现状结论:当前前沿 LLM 在 CL-bench 上平均只解出 17.2% 的任务,最佳模型 GPT-5.1 也仅 23.7%,表明"上下文学习"仍是显著短板。
● 失败类型洞见:失败主要来自两类------"忽视上下文"与"错误应用上下文",二者占多数;另有大量格式/指令跟从错误。建议重点提升模型对上下文事实的忠实遵从与格式约束执行。
● 长上下文与推理强度:随着输入长度增加,解题率显著下降;提高 reasoning effort 有小幅提升(例如 GPT-5.1 从 21.2% 提升到 23.7%),但并非万能解。建议在模型能力与工程上同时发力(长上下文处理 + 更好的学习机制)。 fileciteturn1file19
● 发展路线建议(论文提出的路径):
●● 训练上:构造"context-aware"训练数据(在训练时强制模型依赖上下文中的新知识),以减少模型偏向预训练记忆。
●● 教学式进阶(Curriculum):采用由浅入深的训练课程,先练习短且结构化的上下文再逐步过渡到复杂长上下文任务。
●● 评估与训练信号:发展自动合成高质量 rubric 的方法(或用强 LM 生成并人工修正),将细粒度反馈整合进训练(如 RL 或对抗式训练)。
●● 架构创新:探索对上下文建立显式记忆/索引、多次迭代理解(multi-pass)或为不同信息类型设计专门通路的模型结构。
● 限制与未来方向:当前基准为文本单模态;未来应扩展至多模态,上下文学习的长期交互性也应纳入(更长多轮学习、人与模型协同学习等)。同时补充人类基线会更有助于量化差距。
目录
[《CL-bench: A Benchmark for Context Learn》翻译与解读](#《CL-bench: A Benchmark for Context Learn》翻译与解读)
[Figure 1: Mismatch between how language models are commonly optimized in practice and the capabilities required by real-world tasks. While current LMs primarily elicit reasoning over prompts using pre-trained knowledge, real-world tasks are often context-dependent and require models to learn from context to solve them, a capability we term context learning.图 1:语言模型在实际中的常见优化方式与现实任务所需能力之间的不匹配。当前的语言模型主要通过预训练的知识来对提示进行推理,而现实任务往往依赖于上下文,并且需要模型从上下文中学习以解决问题,我们将这种能力称为上下文学习。](#Figure 1: Mismatch between how language models are commonly optimized in practice and the capabilities required by real-world tasks. While current LMs primarily elicit reasoning over prompts using pre-trained knowledge, real-world tasks are often context-dependent and require models to learn from context to solve them, a capability we term context learning.图 1:语言模型在实际中的常见优化方式与现实任务所需能力之间的不匹配。当前的语言模型主要通过预训练的知识来对提示进行推理,而现实任务往往依赖于上下文,并且需要模型从上下文中学习以解决问题,我们将这种能力称为上下文学习。)
[Figure 2: Solving tasks in CL-bench requires LMs to learn new knowledge from the provided context, rather than relying solely on static pre-trained knowledge. The knowledge is curated by domain experts, either newly created or sourced from niche and emerging long-tail content. New knowledge required for solving each task is provided within corresponding context, with no need for external retrieval. LM solutions are then verified against carefully annotated task-level rubrics. The example task illustrates a charged particle dynamics analysis within the framework of classical electrodynamics (see Table 5 in the Appendix for more details).图 2:在 CL-bench 中解决任务要求语言模型从提供的上下文中学习新知识,而不能仅仅依赖于静态的预训练知识。这些知识由领域专家整理,要么是新创建的,要么是从小众和新兴的长尾内容中获取的。解决每个任务所需的新知识都在相应的上下文中提供,无需外部检索。然后,根据精心标注的任务级评分标准来验证语言模型的解决方案。示例任务展示了在经典电动力学框架内对带电粒子动力学的分析(更多细节见附录中的表 5)。](#Figure 2: Solving tasks in CL-bench requires LMs to learn new knowledge from the provided context, rather than relying solely on static pre-trained knowledge. The knowledge is curated by domain experts, either newly created or sourced from niche and emerging long-tail content. New knowledge required for solving each task is provided within corresponding context, with no need for external retrieval. LM solutions are then verified against carefully annotated task-level rubrics. The example task illustrates a charged particle dynamics analysis within the framework of classical electrodynamics (see Table 5 in the Appendix for more details).图 2:在 CL-bench 中解决任务要求语言模型从提供的上下文中学习新知识,而不能仅仅依赖于静态的预训练知识。这些知识由领域专家整理,要么是新创建的,要么是从小众和新兴的长尾内容中获取的。解决每个任务所需的新知识都在相应的上下文中提供,无需外部检索。然后,根据精心标注的任务级评分标准来验证语言模型的解决方案。示例任务展示了在经典电动力学框架内对带电粒子动力学的分析(更多细节见附录中的表 5)。)
[7 Conclusion](#7 Conclusion)
《CL-bench: A Benchmark for Context Learn》翻译与解读
|------------|--------------------------------------------------------------------------------------------------------------|
| 地址 | 论文地址:https://arxiv.org/abs/2602.03587 |
| 时间 | 2026年02月03日 |
| 作者 | 腾讯混元团队 复旦大学 |
Abstract
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Current language models (LMs) excel at reasoning over prompts using pre-trained knowledge. However, real-world tasks are far more complex and context-dependent: models must learn from task-specific context and leverage new knowledge beyond what is learned during pre-training to reason and resolve tasks. We term this capability context learning, a crucial ability that humans naturally possess but has been largely overlooked. To this end, we introduce CL-bench, a real-world benchmark consisting of 500 complex contexts, 1,899 tasks, and 31,607 verification rubrics, all crafted by experienced domain experts. Each task is designed such that the new content required to resolve it is contained within the corresponding context. Resolving tasks in CL-bench requires models to learn from the context, ranging from new domain-specific knowledge, rule systems, and complex procedures to laws derived from empirical data, all of which are absent from pre-training. This goes far beyond long-context tasks that primarily test retrieval or reading comprehension, and in-context learning tasks, where models learn simple task patterns via instructions and demonstrations. Our evaluations of ten frontier LMs find that models solve only 17.2% of tasks on average. Even the best-performing model, GPT-5.1, solves only 23.7%, revealing that LMs have yet to achieve effective context learning, which poses a critical bottleneck for tackling real-world, complex context-dependent tasks. CL-bench represents a step towards building LMs with this fundamental capability, making them more intelligent and advancing their deployment in real-world scenarios. | 当前的语言模型(LMs)擅长利用预训练的知识对提示进行推理。然而,现实世界中的任务要复杂得多,且具有很强的上下文依赖性:模型必须从特定任务的上下文中学习,并利用预训练期间未学到的新知识来推理和解决问题。我们将这种能力称为上下文学习,这是人类天生具备但长期以来被忽视的一项关键能力。为此,我们推出了 CL-bench ,这是一个由经验丰富的领域专家精心打造的包含 500 个复杂上下文、1899 个任务和 31607 个验证标准的真实世界基准。每个任务的设计都使得解决它所需的新内容包含在相应的上下文中。在 CL-bench 中解决任务需要模型从上下文中学习,包括新的领域特定知识、规则系统、复杂流程以及从经验数据中得出的规律,而这些在预训练期间都是不存在的。这远远超出了主要测试检索或阅读理解的长上下文任务,以及通过指令和演示学习简单任务模式的在上下文学习任务。我们对十种前沿语言模型 的评估发现,这些模型平均仅能解决 17.2% 的任务。即使表现最佳的模型 GPT-5.1 也仅能解决 23.7% 的任务,这表明语言模型尚未实现有效的上下文学习,这是解决现实世界中复杂且依赖上下文的任务的关键瓶颈。CL-bench 代表了朝着构建具备这一基本能力的语言模型迈出的一步,这将使它们更加智能,并推动其在现实场景中的应用。 |
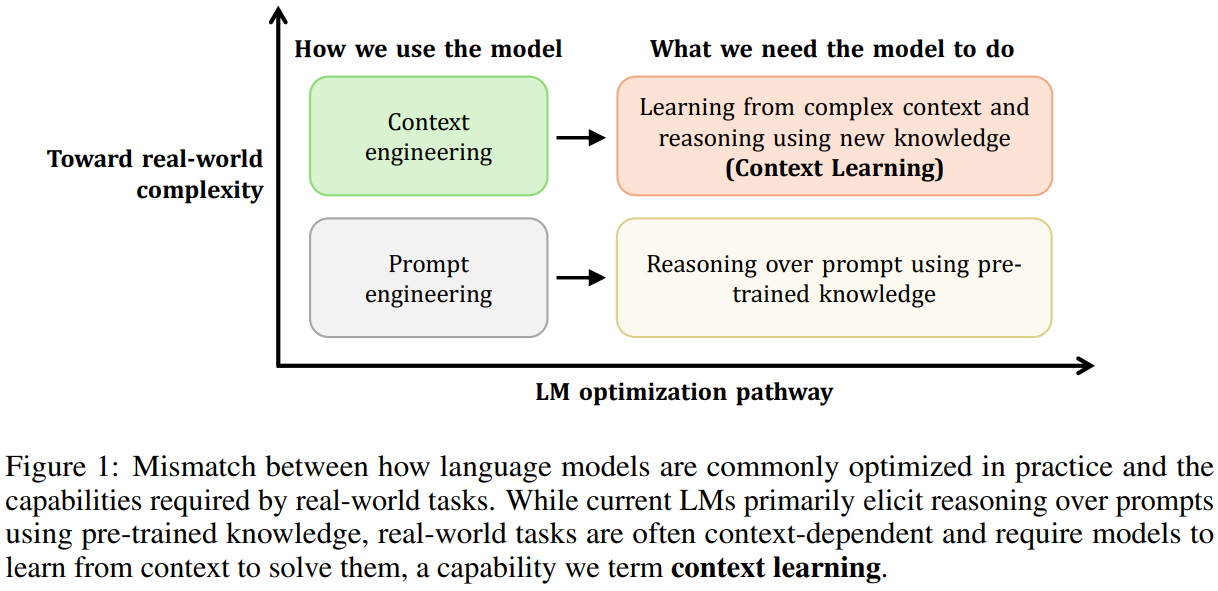
Figure 1: Mismatch between how language models are commonly optimized in practice and the capabilities required by real-world tasks. While current LMs primarily elicit reasoning over prompts using pre-trained knowledge, real-world tasks are often context-dependent and require models to learn from context to solve them, a capability we term context learning.图 1:语言模型在实际中的常见优化方式与现实任务所需能力之间的不匹配。当前的语言模型主要通过预训练的知识来对提示进行推理,而现实任务往往依赖于上下文,并且需要模型从上下文中学习以解决问题,我们将这种能力称为上下文学习。
1、Introduction
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Current language models (LMs) excel at using pre-trained knowledge to solve problems specified by prompts, achieving impressive performance on a wide range of tasks such as competition-level mathematical problems 62; 68; 39; 57, competitive programming challenges 76; 78; 5, and expert-level exams 56; 69; 1. However, real-world tasks often extend far beyond the scope of problems commonly considered in current evaluations. Specifically, many real-world tasks are highly context-dependent 43; 67 and require models to learn from complex contexts, leveraging new knowledge not previously available to reason and solve tasks effectively. Figure 1 shows this mismatch between current model capabilities and real-world requirements. We term this capability context learning. Effective context learning enables models to handle complex, domain-specific tasks by learning directly from rich contextual information, much as humans do in everyday settings. For example, it allows models to rapidly make use of previously unseen product documentation, participate in ongoing group conversations with years of prior context in real time, or discover laws from large collections of experimental data. Such learning from complex contexts is critical for practical, real-world scenarios and forms the foundation for broader context-driven applications. Despite its central role in human task-solving, context learning has been largely overlooked in current research. | 当前的语言模型(LMs)擅长利用预训练的知识来解决提示所指定的问题,在诸如竞赛级别的数学问题62; 68; 39; 57、竞赛编程挑战76; 78; 5以及专家级考试56; 69; 1等广泛的任务中取得了令人瞩目的成绩。然而,现实世界中的任务往往远远超出了当前评估中通常考虑的问题范围。具体而言,许多现实世界中的任务高度依赖于上下文43; 67,需要模型从复杂的上下文中学习,利用之前未曾接触过的知识来进行推理和有效解决问题。图 1 展示了当前模型的能力与现实世界需求之间的这种不匹配。我们将这种能力称为上下文学习。 有效的上下文学习使模型能够像人类在日常环境中那样,直接从丰富的上下文信息中学习,从而处理复杂的、特定领域的任务。例如,它能让模型迅速利用之前未曾见过的产品文档,实时参与包含多年背景信息的持续群组对话,或者从大量实验数据中发现规律。这种从复杂情境中学习的能力对于实际的现实场景至关重要,并构成了更广泛的情境驱动型应用的基础。尽管在人类解决问题的过程中起着核心作用,但情境学习在当前的研究中却很大程度上被忽视了。 |
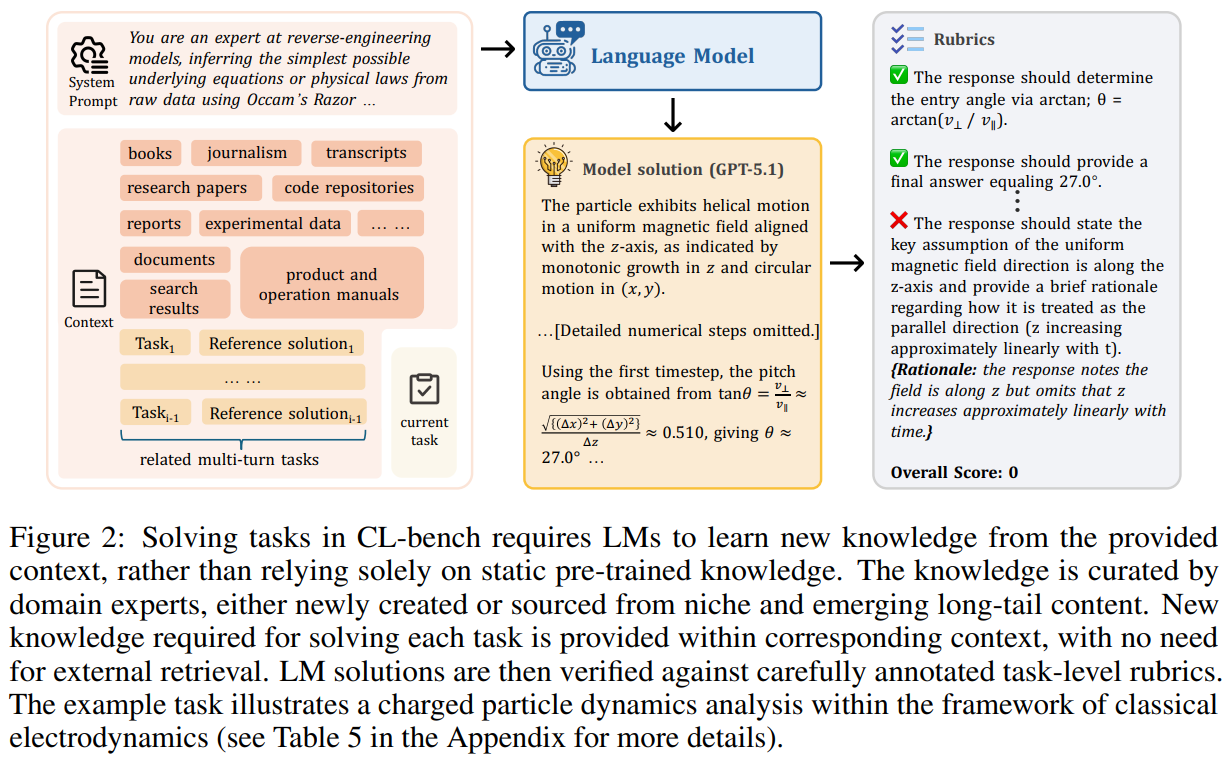
| To systematically evaluate context learning, we introduce CL-bench, a real-world benchmark con-sisting of 500 complex contexts, 1,899 tasks, and 31,607 verification rubrics. Each context and task is grounded in the real world, requiring models to truly learn from the provided context and correctly apply what they learn to solve tasks, as shown in Figure 2. The knowledge in contexts, including newly created and niche long-tail content, largely extends beyond what existing models have acquired during pre-training, and is carefully organized so that models do not need to retrieve from external sources. For example, tasks require LMs to understand the complete legal system of a fictional country, including case precedents and legal principles, and apply it to adjudicate cases; or to comprehend a complex new product manual to generate step-by-step operational procedures or troubleshoot issues. CL-bench categorizes contexts into four categories based on the contexts humans encounter in the real world and how they typically learn from and apply them: domain knowledge reasoning, rule system application, procedural task execution, and empirical discovery & simulation. These categories are further divided into 18 subcategories to validate context learning in diverse real-world scenarios. | 为了系统地评估情境学习,我们引入了 CL-bench,这是一个由 500 个复杂情境、1899 个任务和 31607 个验证标准组成的现实世界基准。每个情境和任务都基于现实世界,要求模型真正从所提供的情境中学习,并正确应用所学来解决问题,如图 2 所示。情境中的知识,包括新创建的和小众的长尾内容,很大程度上超出了现有模型在预训练期间所获取的知识,并且经过精心组织,使得模型无需从外部来源检索。例如,任务要求语言模型理解一个虚构国家的完整法律体系,包括案例先例和法律原则,并将其应用于裁决案件;或者理解一份复杂的新产品手册,以生成分步操作程序或解决故障。CL-bench 根据人类在现实世界中遇到的情境以及他们通常如何从中学习和应用,将情境分为四类:领域知识推理、规则系统应用、程序性任务执行以及经验发现与模拟。这些类别进一步细分为 18 个子类别,以验证在各种现实世界场景中的情境学习情况。 |
| CL-bench offers several key features to ensure effective evaluation. (1) Realistic and high-quality. Each context and corresponding tasks and rubrics are crafted by experienced domain experts and refined through multiple rounds of rigorous quality review. (2) Contamination-free. Contexts contain new knowledge absent from pre-training, constructed by domain experts through three approaches: fictional creation, modification of existing knowledge, or incorporation of niche and emerging specialized knowledge. As some new knowledge may conflict with pre-training knowledge, models must truly learn from context and adhere to it, rather than be misled by what they learned during pre-training. (3) Challenging. Each context contains up to 12 tasks with an average of 3.8. Annotating each context and corresponding tasks requires an average of 20 hours of expert effort. Moreover, tasks within each context may be presented sequentially across multiple interaction turns and depend on the solutions of earlier tasks, which further increases task difficulty. (4) Rigorously verifiable. Each context contains an average of 63.2 rubrics. These rubrics are carefully annotated and verified, and are designed to assess task correctness and completeness from multiple dimensions. We evaluate ten state-of-the-art LMs on CL-bench, find that models solve only 17.2% of tasks on average, and even the best-performing model, GPT-5.1, solves only 23.7%. Frontier models struggle with context learning, revealing that this fundamental capability has been largely overlooked. Moreover, results show that while different LMs exhibit varying performance across categories, all models perform substantially worse on more challenging categories, such as inducing and applying laws from extensive experimental data or simulating complex sandbox environments, with an average solve rate of only 11.8%. Error analysis shows that a higher proportion of failures stems from models ignoring what is presented in the context. Moreover, deeper case studies find that insufficient long-context reasoning and instruction-following abilities also contribute to context learning failures. More insightful findings are presented in Section 4 and 5. Overall, context learning in current frontier LMs remains remarkably poor. This crucial learning capability warrants greater attention from AI community. Advancing context learning is the key to building next-generation LMs that, like humans, possess the ability to learn from context, adapt to evolving contexts, and excel in the real world. CL-bench provides a critical testbed for this endeavor. | CL-bench 提供了几个关键特性以确保评估的有效性。 (1)真实且高质量。每个情境以及相应的任务和评分标准均由经验丰富的领域专家精心设计,并经过多轮严格的质量审查。 (2)无污染。情境包含预训练中不存在的新知识,由领域专家通过三种方式构建:虚构创作、对现有知识进行修改或融入小众和新兴的专业知识。由于一些新知识可能与预训练知识相冲突,模型必须真正从情境中学习并遵循它,而不是被预训练期间所学的内容误导。 (3)具有挑战性。每个情境包含多达 12 个任务,平均为 3.8 个。标注每个情境及其相应任务平均需要 20 小时的专家工作量。此外,每个情境中的任务可能在多个交互回合中依次呈现,并依赖于早期任务的解决方案,这进一步增加了任务的难度。 (4)严格可验证。每个情境平均包含 63.2 个评分标准。这些评分标准经过了仔细的注释和验证,旨在从多个维度评估任务的正确性和完整性。 我们在 CL-bench 上对十个最先进的语言模型进行了评估,发现模型平均仅能解决 17.2%的任务,即使表现最佳的模型 GPT-5.1 也仅能解决 23.7%。前沿模型在上下文学习方面存在困难,这表明这一基本能力在很大程度上被忽视了。此外,结果表明,尽管不同语言模型在各类任务中的表现各不相同,但所有模型在更具挑战性的类别(如从大量实验数据中归纳和应用规律或模拟复杂的沙盒环境)上的表现都明显更差,平均解决率仅为 11.8%。错误分析表明,模型忽略上下文中所呈现内容的情况占了较大比例。此外,更深入的案例研究发现,上下文推理能力不足和遵循指令的能力欠缺也是导致上下文学习失败的原因。 更多有见地的发现将在第 4 节和第 5 节中呈现。总体而言,当前前沿语言模型的上下文学习能力仍然非常薄弱。这种关键的学习能力值得人工智能领域给予更多关注。推进上下文学习是构建下一代语言模型的关键,这些模型能够像人类一样从上下文中学习、适应不断变化的上下文,并在现实世界中表现出色。CL-bench 为此提供了重要的测试平台。 |
Figure 2: Solving tasks in CL-bench requires LMs to learn new knowledge from the provided context, rather than relying solely on static pre-trained knowledge. The knowledge is curated by domain experts, either newly created or sourced from niche and emerging long-tail content. New knowledge required for solving each task is provided within corresponding context, with no need for external retrieval. LM solutions are then verified against carefully annotated task-level rubrics. The example task illustrates a charged particle dynamics analysis within the framework of classical electrodynamics (see Table 5 in the Appendix for more details).图 2:在 CL-bench 中解决任务要求语言模型从提供的上下文中学习新知识,而不能仅仅依赖于静态的预训练知识。这些知识由领域专家整理,要么是新创建的,要么是从小众和新兴的长尾内容中获取的。解决每个任务所需的新知识都在相应的上下文中提供,无需外部检索。然后,根据精心标注的任务级评分标准来验证语言模型的解决方案。示例任务展示了在经典电动力学框架内对带电粒子动力学的分析(更多细节见附录中的表 5)。
7 Conclusion
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| For language models to solve real-world tasks that demand knowledge beyond their pre-training, they must be capable of acquiring new knowledge from provided contexts and applying it correctly. We term this fundamental capability context learning. To rigorously evaluate it, we present CL-bench, a benchmark comprising 500 contexts, 1,899 tasks, and 31,607 verification rubrics. Each instance is designed to be realistic, contamination-free, and challenging, requiring models to learn and apply new knowledge across four distinct categories. Our evaluations reveal that even the best-performing model, GPT-5.1, solves only 23.7% of tasks, exposing a significant gap between current capabilities and the demands of practical applications. We hope this work draws attention to context learning as a core capability warranting focused research, and that CL-bench serves as a significant testbed for developing language models that can effectively utilize context. | 要使语言模型能够解决那些需要超出其预训练知识的真实世界任务,它们必须能够从提供的上下文中获取新知识并正确应用。我们将这种基本能力称为上下文学习 。为了严格评估这一能力,我们提出了CL-bench ,这是一个包含 500 个上下文、1899 个任务和 31607 个验证准则的基准测试。每个实例都经过精心设计,以确保其现实性、无污染且具有挑战性,要求模型在四个不同的类别中学习并应用新知识。我们的评估表明,即使表现最佳的模型 GPT-5.1 也仅能解决 23.7%的任务,这揭示了当前能力与实际应用需求之间存在显著差距。我们希望这项工作能引起人们对上下文学习这一核心能力的关注,从而促使对其进行集中研究,并且希望 CL-bench 能成为开发能够有效利用上下文的语言模型的重要测试平台。 |