和之后的bert有很强烈的关系
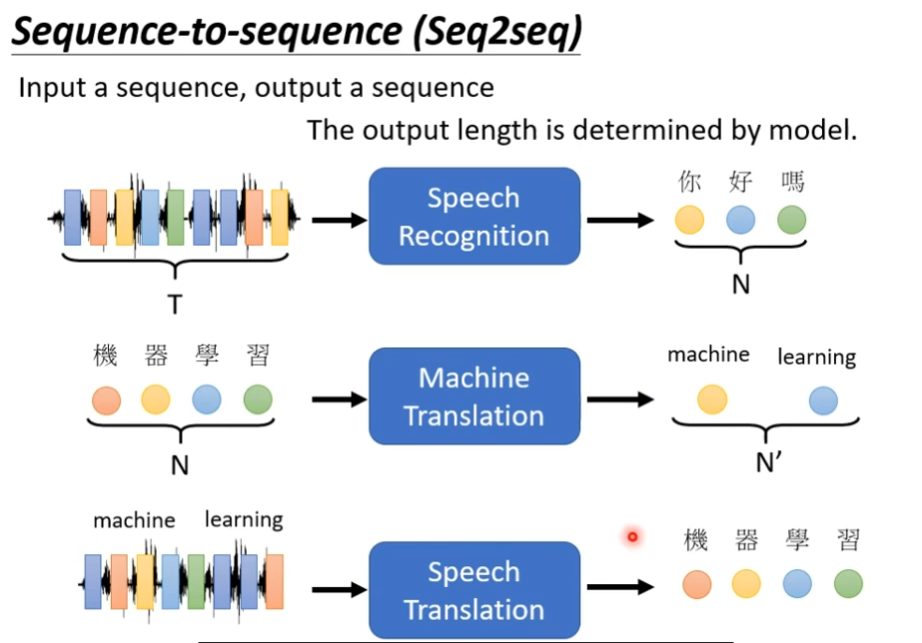
transformer就是一个sequence to sequence的model,input和output都是一个sequence,但是output我们不知道多长,由机器自己决定
其中一个很好的应用就是语音辨识,输入是一段语音讯号,但是输出就是一个句子,输入和输出有关系,但是没有绝对的关系
还有一个应用就是机器翻译,读一个句子然后翻译成另一种语言
甚至有更复杂的应用就是语音翻译,如下图
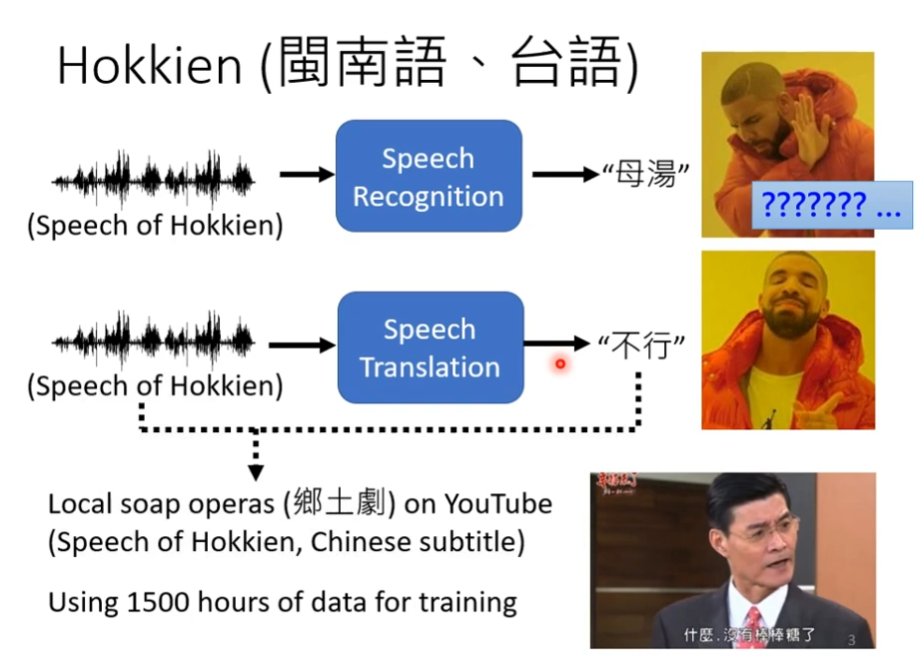
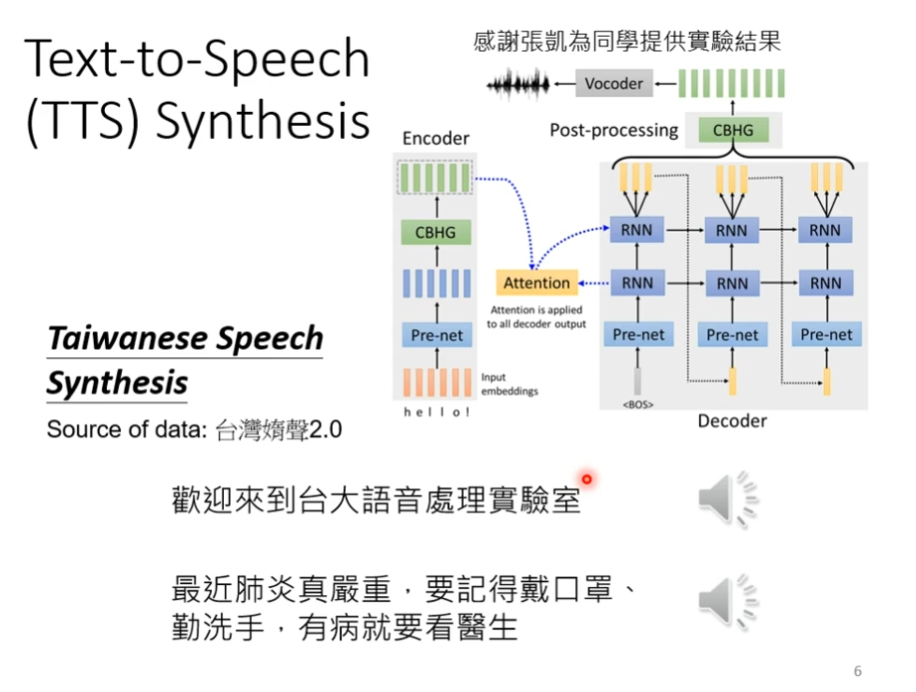
比如说,台语的语音辨识,台语的文字并不是很普及,所以大部分人不知道,我们可以做一个语言辨识,让他翻译成我们看得懂的文字,我们需要的资料就是台语语音以及其对应的中文,需要知道他们之间的对应,如下图
最简单的就是一些方言的有特殊含义的句子,一些乱一些的发音全部都不管,直接去训练,如下图

以下是结果,会有对的,但是也会有犯错的时候,特别是倒装的部分,感觉机器学的比较差,如下图

台语语音辨识反过来就是台语的合成,如下图
接下来就是文字上对于seq2seq的model,可以训练一个聊天机器人,这就需要大量人的对话,这样就可以直接训练model,当看到hi,他的回答就和hello,how are you today越接近越好,如下图

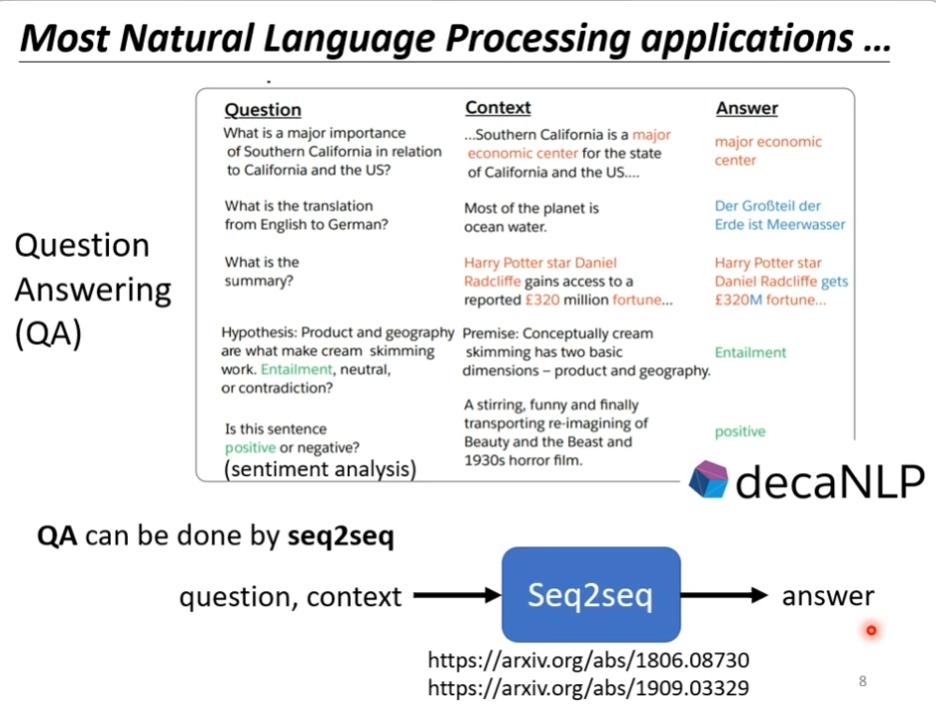
事实上,在nlp领域中seq2seq应用是很广泛的,所谓的question answering就是给机器读一段文字,然后你问机器,机器再回答,比如说翻译,摘要,自动判断句子是积极还是消极的等方向,这种qa的问题就可以用seq2seq的model来解决,如下图
但是我们要强调一下,对于多数语音相关的任务而言,特质化的模型会有更好的效果,如下图
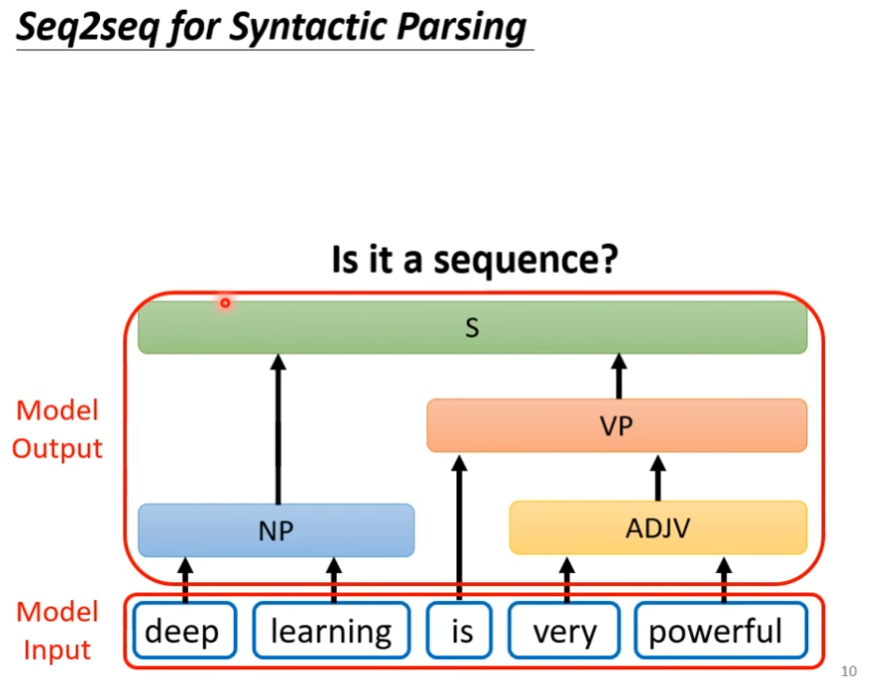
其实有很多应用我们不觉得是seq2seq的问题,但是我们都可以看做是seq2seq,比如说文法剖析,我们输入句子,然后机器要告诉我们,这个句子里面都有什么语等,输入是一段文字,输出是一个树状的结构,这个也可以硬是看作sequence,如下图
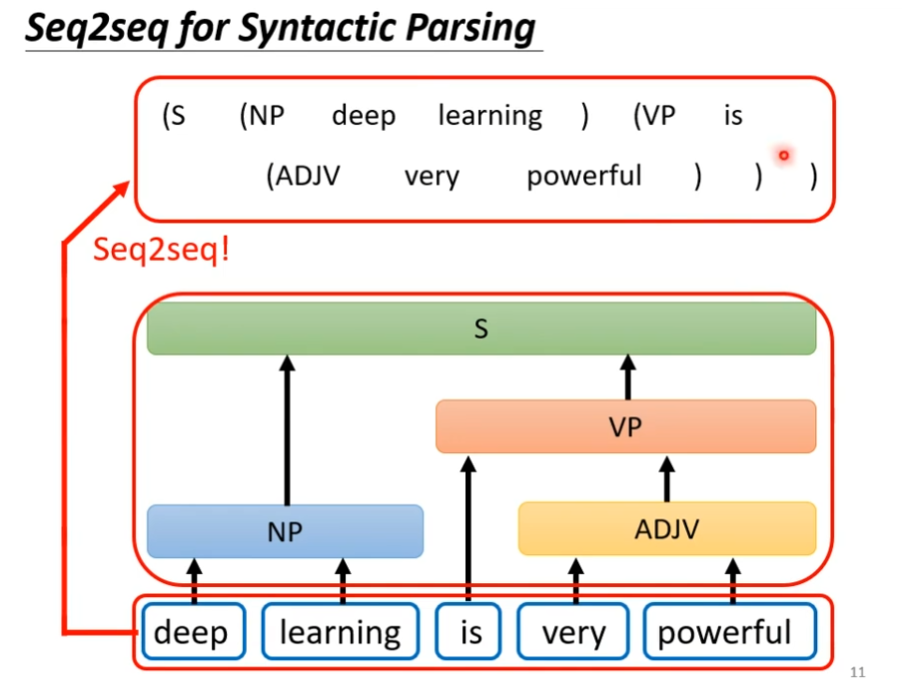
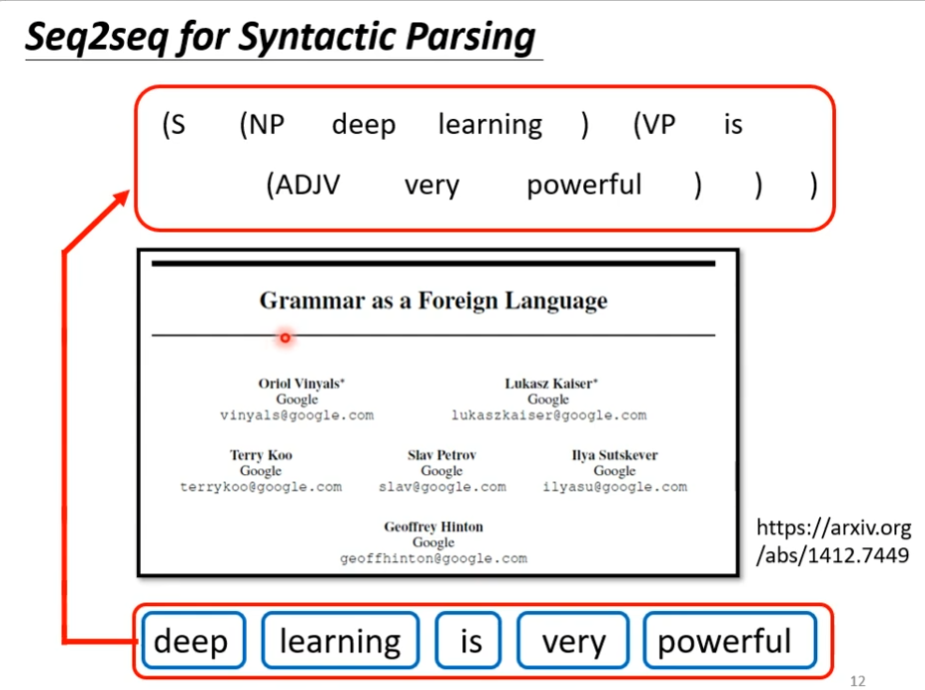
这个事情是可以做到的,如下图,里面有一篇文章,这个文章把文法当作另外一个语言
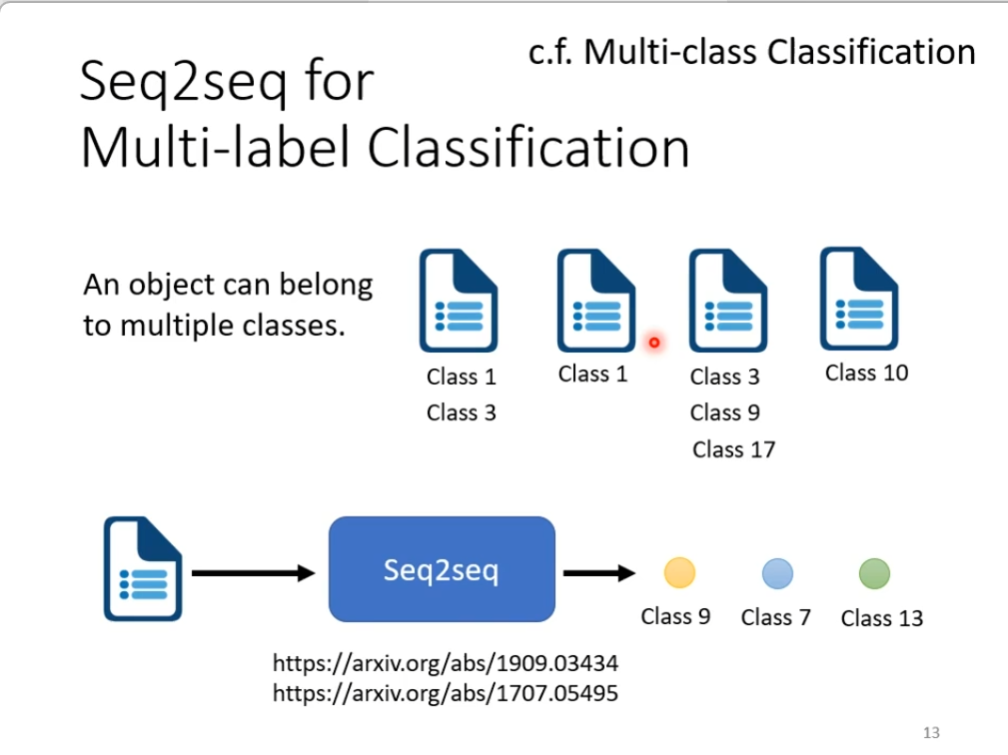
另外的应用举例就是,multi-class classification,这个是说有很多的class,而需要做的就是知道我们要的东西是属于哪个class,而multi-label classification是说同一个东西可以属于多个class,举例就是文章分类,图中有文章属于class1和3,也有文章属于class9,3,17,这里的问题该怎么解决呢?这里的文章分类不确定有几个,我们可以用seq2seq硬做,这样的话输入就是文章,输出就是class,而class的数目由机器自己决定,如下图
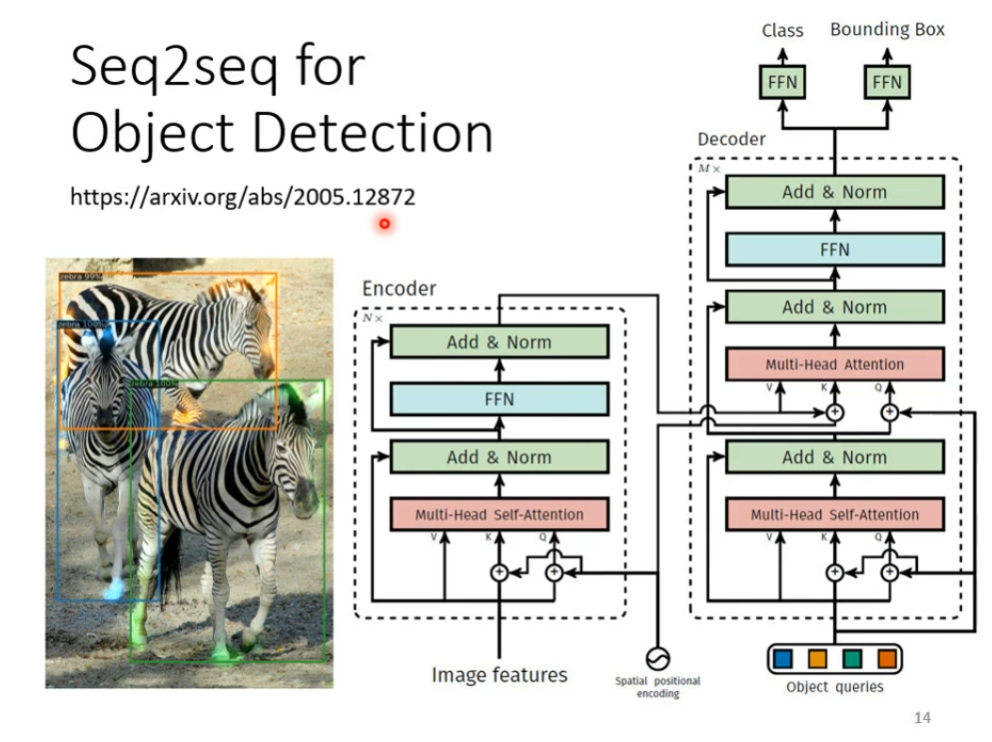
或者是object detection,也可以用seq2seq直接硬解,至于怎么做,我们这边不细讲,可以看图中的链接,如下图
可以看出来seq2seq是一个很有用的model,这个model的应用还是比较广的,接下来我们学习如何做seq2seq这件事情
从seq2seq者个模型上面,他里面会分成两个部分,一个是encoder,一个是decoder,这里的encoder是负责处理这个sequence,把处理好的结果丢给decoder,由decoder决定它要输出什么样的结果,如下图
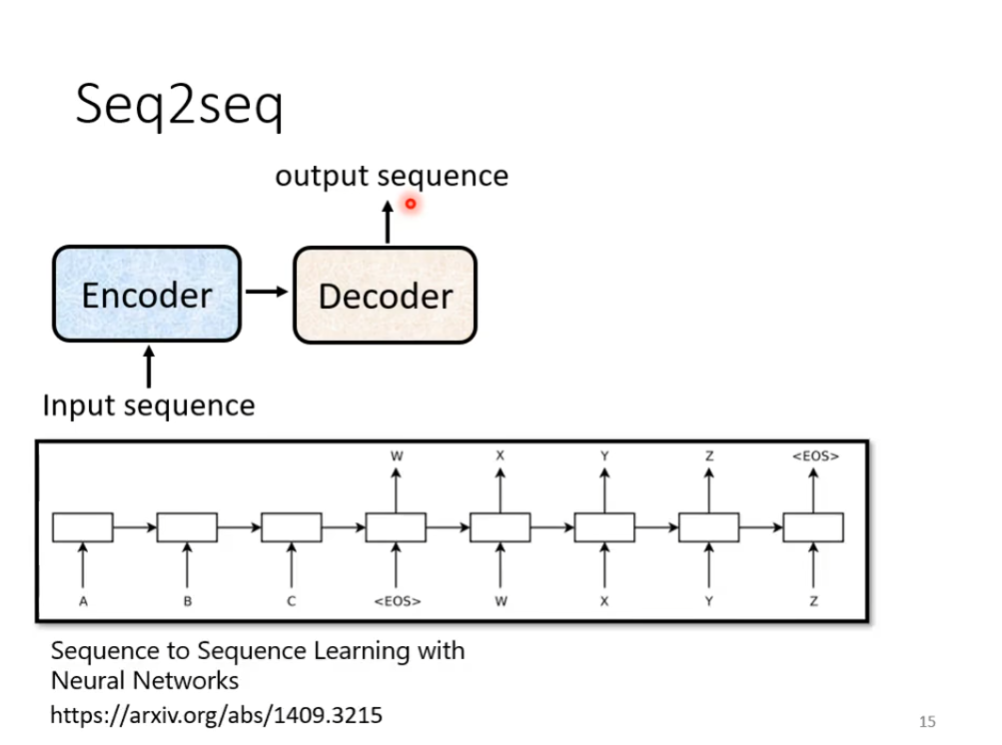
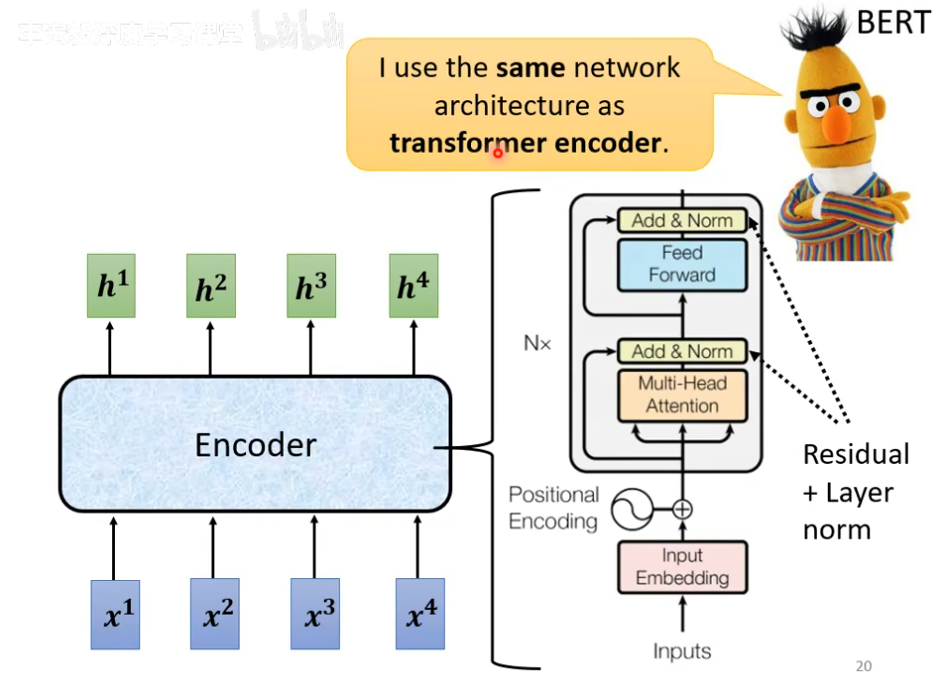
这里面最出名的就是我们的transformer,如下图
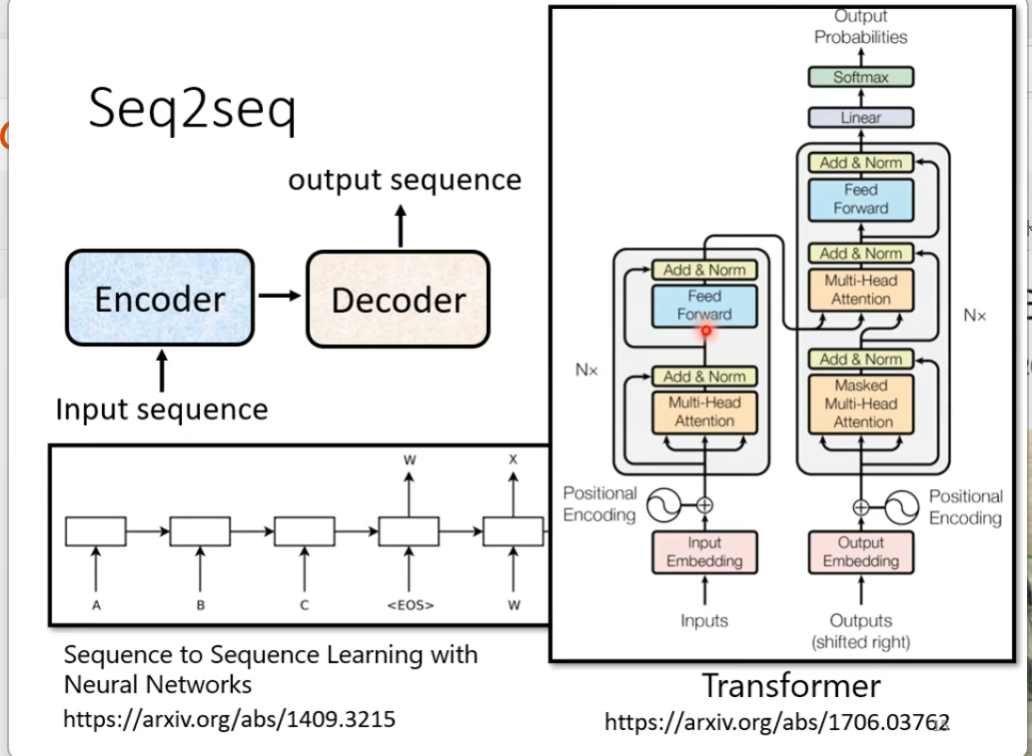
接下里是encoder部分,他就是给一排向量输出另外一排向量,我们之前学过的RNN以及CNN都是可以做到的,transformer的encoder就是用的self-attention,如下图
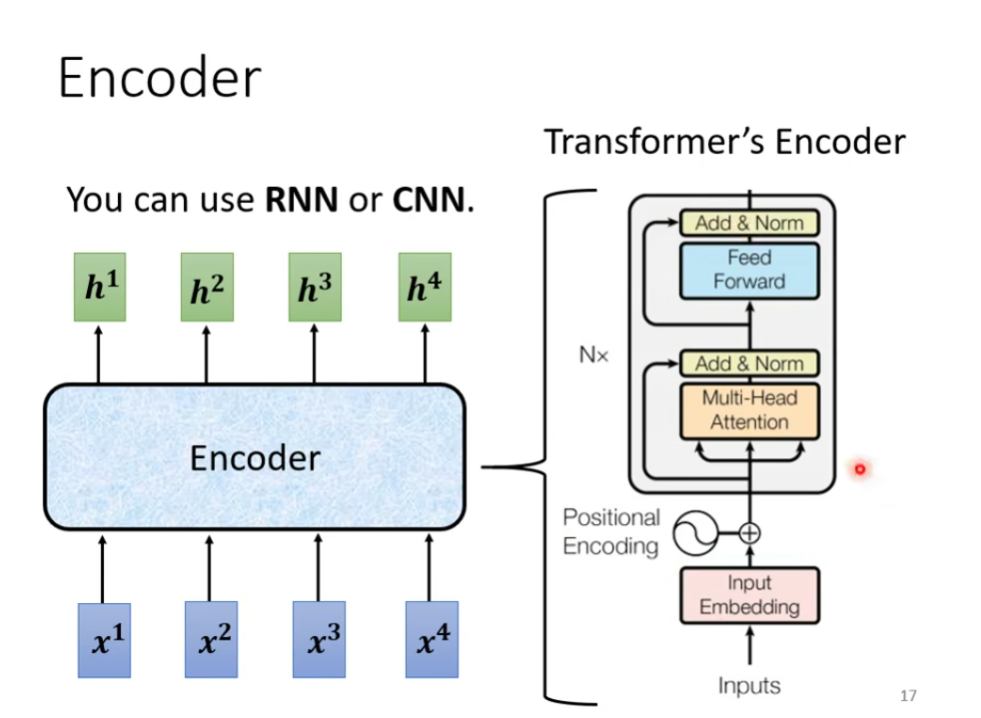
那现在encoder里面有很多很多的block,每一个block都是输入一排向量,输出另外一排向量给下一个block,最终的block输出我们需要的最终向量,但是这里的block不是nueral network的一层,这里之所以不称block为一个layer,是因为一个block做的事情是好几个layer做的事情,在transformer里面,一个Block大概做的事情就是,首先一排向量输入然后输出另外一排向量,输出的结果最后在进入到一层fully-connected network里面,在output另外一排向量,这就是block的输出,如下图
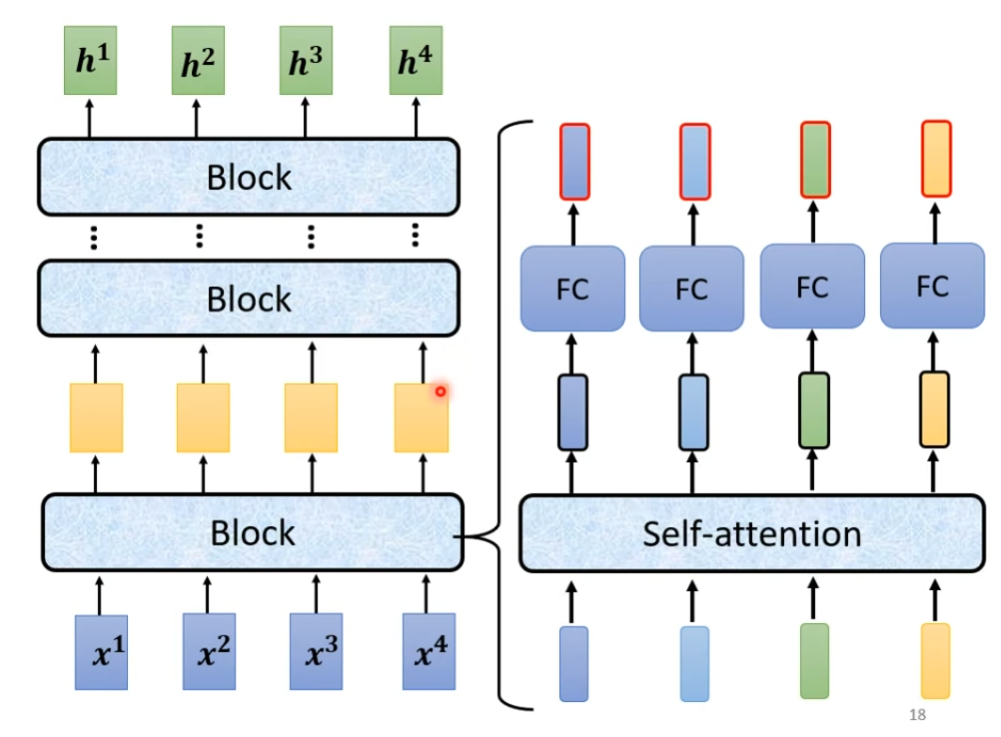
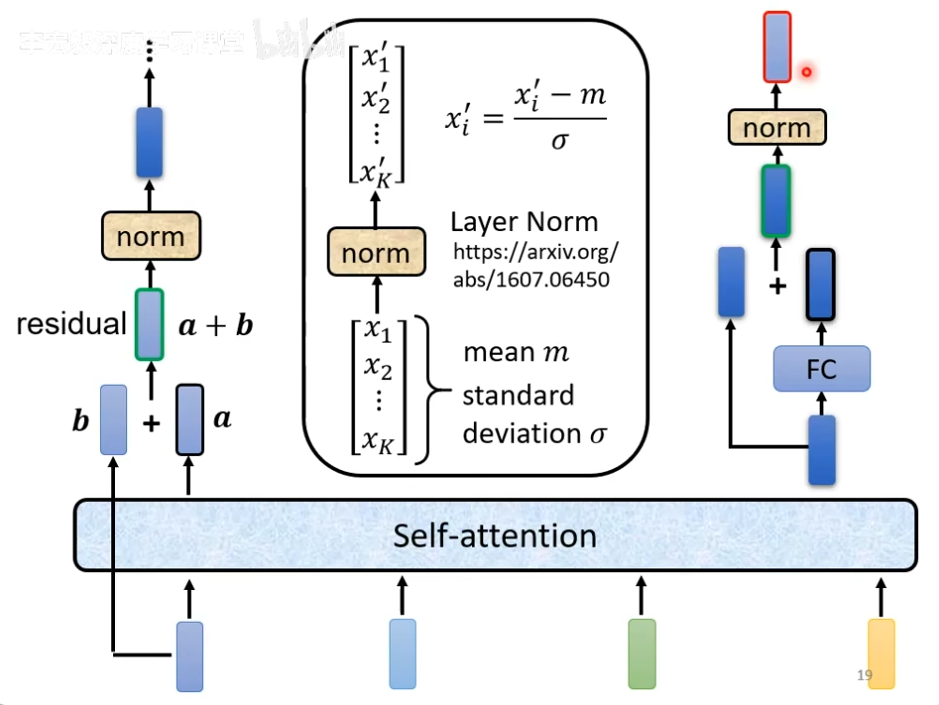
事实上,在原来的transformer里面做的事情更加复杂,这里输出的一排vector之中的每一个vector都考虑了所有的输入的vector之后得到的,这里是把原来的输入的vector加入到了对应的输出的vector当中,把输入输出的vector加起来获得一个新的vector,这种架构叫做residual,在deep learning的领域应用很广泛,得到结结果之后再做一个normalization,这里用的并不是batch normalization,这里用的是layer normalization,输入一个向量,输出另外一个向量,不考虑batch,计算输入向量的mean和standard deviation,注意一下,对于layer normalization是对于同一个feature,同一个example里面不同的dilemention去计算mean和standard deviation,就可以做一个normalize,然后output所需要的vector,图中的分子上xi没有" ' ",这个输出才是fully-connected network的输入,fc这里也有一个residual的架构,得到新的输出,把这个输出再做一次layer normalization之后的输出就是transformer里面一个的一个block的输出,如下图
这里的multi-head attention就是self-attention的block,add and norm就是residual+layer norm,feed forward就是fully-connected feed forward network,这个复杂的block再bert也会用,如下图