很多安全问题,并不是"没做对齐",而是"后来被冲淡了"
在很多团队内部讨论中,这个问题经常被问出来:
"我们只是做了业务微调,
不会把 base model 的安全对齐搞坏吧?"
这个问题听起来很合理,
但它隐藏了一个更深层、也更危险的误解:
把安全对齐,当成一种"独立存在、不会被影响的能力"。
现实情况是:
安全对齐不是一层外壳,
而是和模型整体行为分布纠缠在一起的。
所以问题从来不是:
- 会不会削弱
而是:
- **在什么阶段
- 以什么方式
- 削弱到什么程度
- 削弱的是哪一类安全行为**
这篇文章,就是要把这件事一层层拆清楚。
先给一个非常关键的结论(一定要先看)
在展开之前,我先把全文最重要的一句话写出来:
微调不会"删除" base model 的安全对齐,
但它几乎一定会"重新加权"安全行为的触发条件。
如果你理解成"删 vs 不删",
那你后面所有判断都会偏。
第一层误解:把安全对齐理解成"不可变属性"
很多人潜意识里把 base model 的安全对齐想成:
- 一套写死的规则
- 一个安全模块
- 一种"已经完成的状态"
于是自然会问:
"我在上面微调点东西,
还能把它弄坏吗?"
但从模型结构上看,这种理解是错误的。
安全对齐在模型里是怎么存在的?
在大模型中,安全对齐本质上是:
- 一组行为偏好分布
- 在特定输入模式下
- 输出更保守、更拒绝、更模糊的概率更高
它不是:
- 独立参数
- 独立层
- 可以被"锁住"的开关
而是:
和所有其他行为,
共用同一套参数空间。
第二层:base model 的安全,是"相对优势",不是"绝对禁止"
这是理解后续一切的基础。
在 base model 中:
-
对危险请求
- 安全输出概率高
- 危险输出概率低
但请注意:
"低概率" ≠ "不存在"。
base model 的安全性,更多是通过:
- 概率压制
- 行为偏好
- 输出分布塑形
来实现的。
这意味着:
只要你在微调中,
持续奖励另一种行为,
原本被压制的路径,
就可能重新被抬高。
第三层:SFT 阶段,安全对齐是如何被"稀释"的
很多团队第一步微调,都是 SFT。
而 SFT 是最容易被低估风险的阶段。
SFT 在做什么?
SFT 的核心目标是:
让模型更频繁地产生
你提供的目标输出。
如果你的 SFT 数据中:
- 回答非常具体
- 很少拒答
- 很少模糊表达
- 强调"给出完整解决方案"
你就在做一件事:
系统性地奖励"确定性输出"。
问题在于:
-
base model 的安全对齐
-
很多时候正是通过
- 模糊
- 犹豫
- 回避
来实现的
于是你会看到:
安全行为不是被删除,
而是被"挤"到更少出现的区域。
第四层:LoRA / Adapter,让安全削弱更"集中"
当你使用 LoRA 或 Adapter 时,
很多人会下意识觉得:
"我没有动 base model,
那安全总该还在吧?"
这是一个非常危险的误解。
LoRA 不动 base model,意味着什么?
意味着:
- base 参数被冻结
- 新行为被写入低秩子空间
但关键问题是:
推理时,
base 行为 + LoRA 行为
是一起叠加的。
如果 LoRA 强烈推动某些输出模式:
- 更具体
- 更主动
- 更少拒绝
那么在最终输出分布中:
安全行为虽然还在,
但被覆盖在"更强的信号"下面。
这是一种非常典型的:
"表面保留,实际被掩盖"。
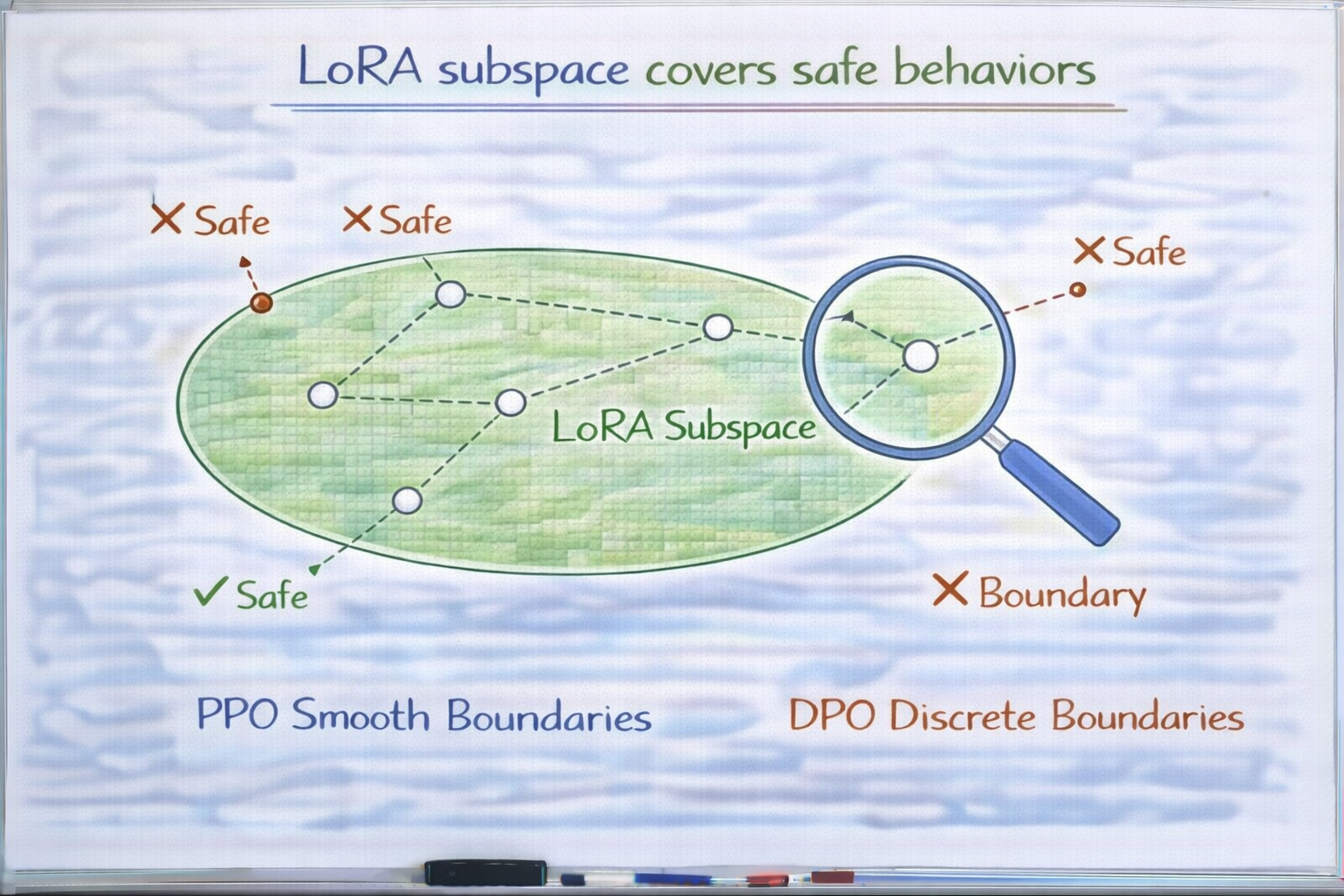
LoRA 子空间覆盖安全行为
第五层:PPO / DPO,会"修复"还是"进一步迁移"安全?
很多团队会说:
"没关系,后面还有 PPO / DPO,
可以再对齐回来。"
这句话只对了一半。
PPO / DPO 确实可以:
- 压制显性违规
- 强化拒答表达
- 恢复一部分安全表象
但问题在于:
它们对安全的修复,是"有方向性的"。
PPO / DPO 真正做了什么?
它们做的是:
- 根据偏好信号
- 调整输出概率
如果你的偏好数据:
- 只标注了"明显违规"
- 没覆盖灰区
- 没标注"过度具体但危险"的情况
那么 PPO / DPO 的效果往往是:
把风险推到
你没标注、没评估的区域。
于是你会看到一种现象:
- 表面更安全
- 实际更隐蔽
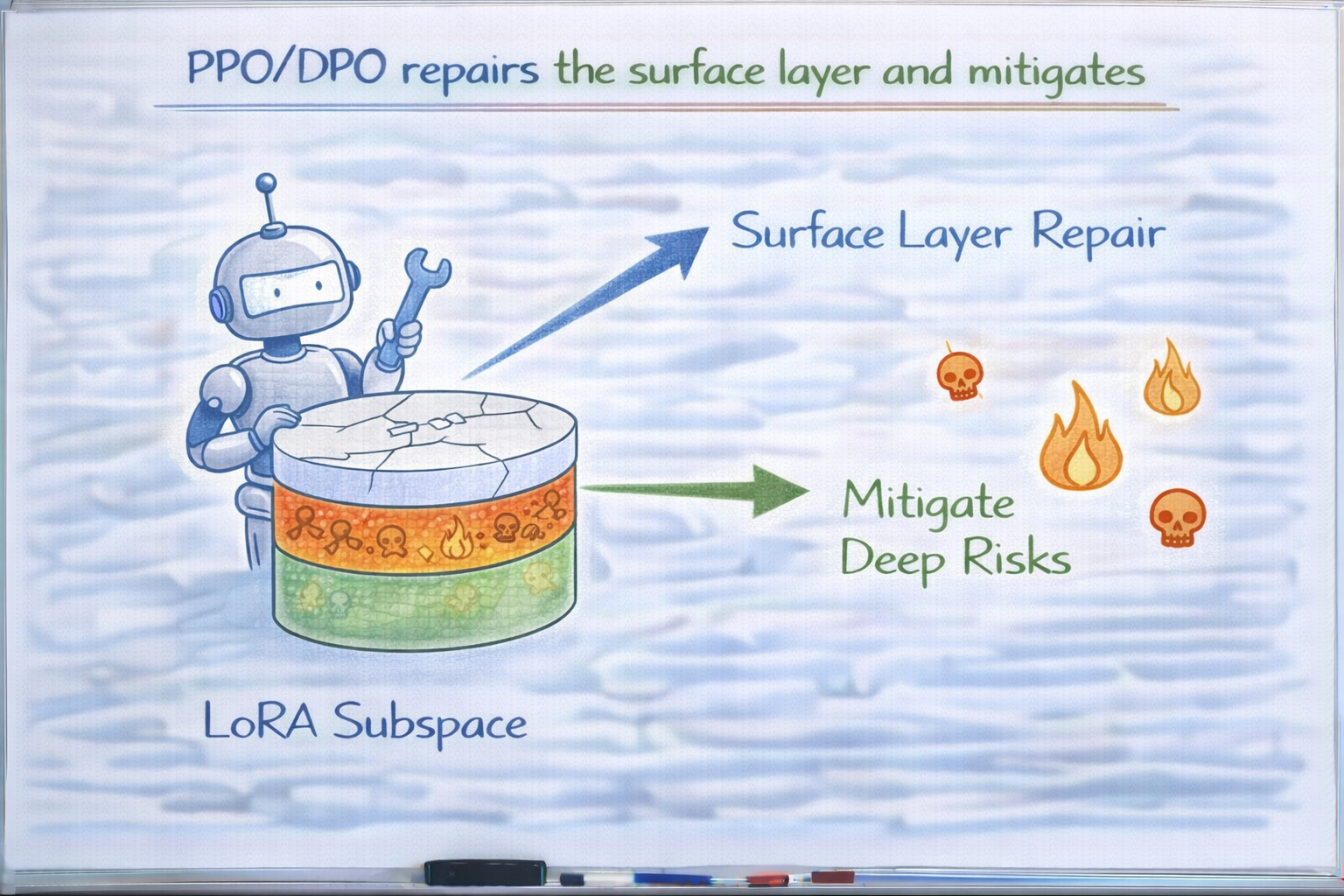
PPO/DPO 修复表层,迁移深层风险
第六层:为什么安全削弱,往往在"组合场景"中才显现
很多团队会说:
"我们单测过,没问题。"
但安全削弱,往往不在单一输入中出现。
而是在:
- 多轮对话
- 连续追问
- 条件逐步细化
时才显现。
原因很简单:
base model 的安全对齐,
很大一部分依赖"上下文不完整"。
而微调后的模型:
- 更愿意补全
- 更少拒绝
- 更主动推理
于是原本安全的"犹豫空间",被一步步吃掉。
第七层:一个极简示意,看安全是如何被"盖过去"的
python
# base model
if request in risky_space:
return vague_or_refuse()
# 微调后
if request in risky_space:
if has_similar_seen_pattern:
return concrete_answer()
else:
return vague_or_refuse()注意这里:
vague_or_refuse没被删- 但触发条件变窄了
这就是:
安全没有消失,
但不再是默认路径。
第八层:什么时候你可以认为"安全对齐被明显削弱了"
在工程实践中,有几个非常清晰的信号:
- 模型几乎不再使用模糊表达
- 对灰区问题给出完整分析
- 拒答更"讲道理",但仍然给信息
- 多轮追问下,边界越来越松
如果你看到这些现象,
那就不要再纠结"是不是削弱了"。
答案已经很明显。
第九层:真正危险的不是"削弱",而是"你不知道削弱发生了"
这里是最现实的一点。
安全削弱之所以危险,不是因为它发生了,
而是因为:
- 指标不反映
- 测试不覆盖
- 团队默认"没问题"
于是安全从:
显式风险
变成:
系统性盲区。
一个非常实用的判断问题(强烈建议)
在你准备上线一个微调模型前,问自己一句话:
如果 base model 在这里会犹豫,
而微调模型不会,
这是我"明确想要的结果"吗?
如果你答不上来,
那就说明:
安全对齐已经被动到了,
只是你还没正视它。
很多团队是在模型上线后才意识到安全行为发生了变化,其实这些变化在微调阶段就已经出现。用LLaMA-Factory online对比 base model 与不同微调阶段模型的输出分布,更容易判断:安全对齐是被保留、被稀释,还是被新的行为模式覆盖了。
总结:安全对齐不是"不会变",而是"需要被守住"
我用一句话,把这篇文章彻底收住:
微调不是在删除安全,
而是在重新决定:
什么时候,安全还值得被坚持。
当你开始:
- 不再把安全当成"初始属性"
- 而是当成"需要持续维护的行为偏好"
- 在效果提升时同步问"代价是什么"
你才真正开始对微调模型负责。