一、前言
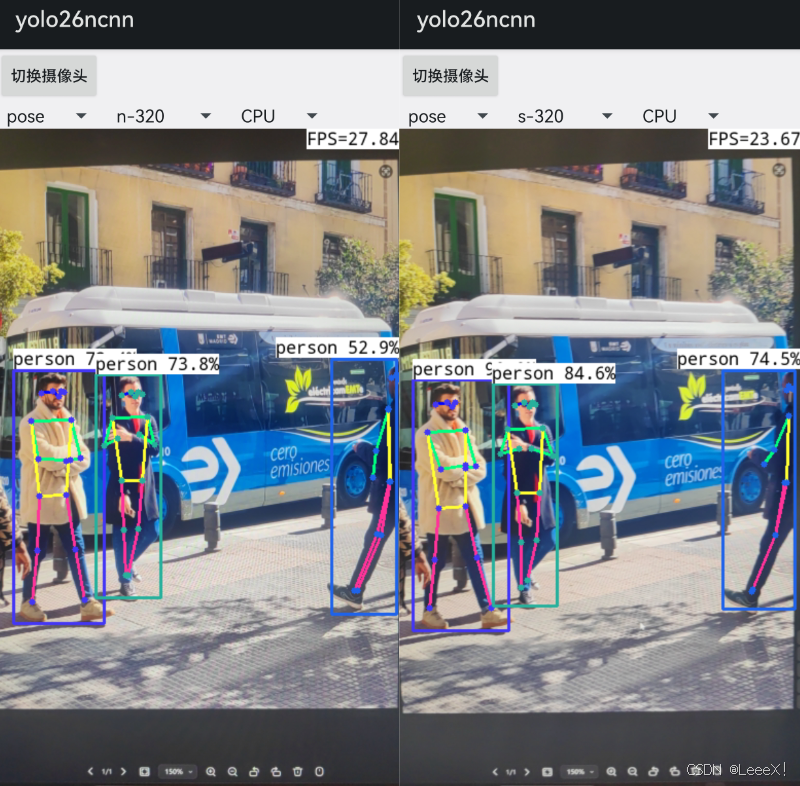
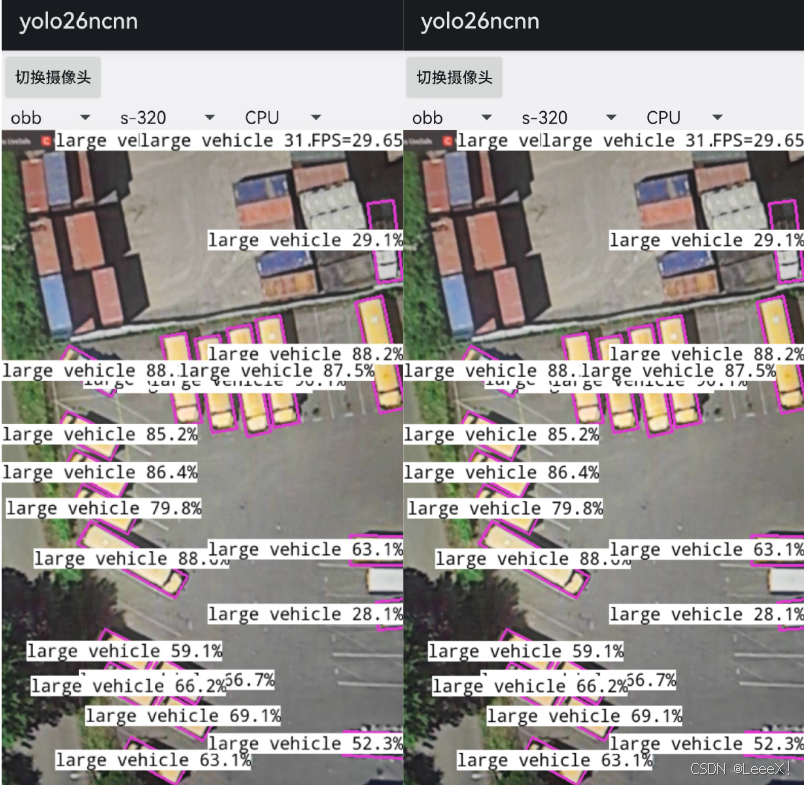
在伦敦YOLO Vision 2025大会上,Ultralytics创始人Glenn Jocher演示YOLO26在树莓派上实时检测的效果,我才彻底被打脸。那个只有512MB内存的小设备,竟能以28FPS的速度准确识别出视频中快速移动的小鸟,而功耗仅仅0.8W!
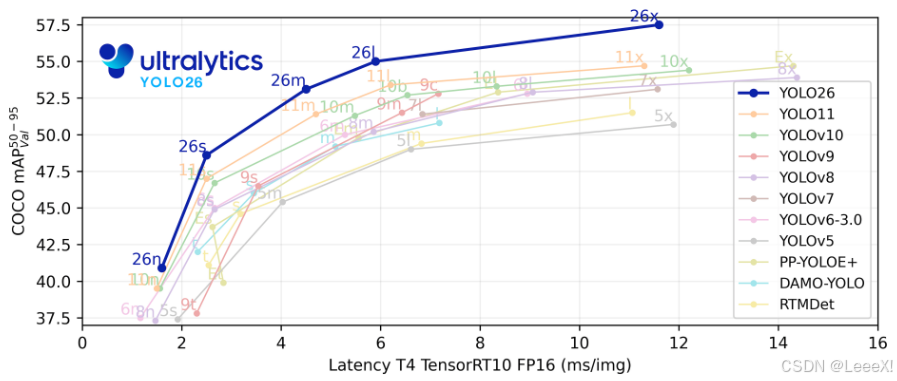
今年1月14日,Ultralytics正式发布了YOLO26,基于官方发布的测试数据与实际验证,YOLO26在边缘计算场景的表现确实实现了显著突破。YOLO26的设计理念发生了根本转变:其设计重心从追求基准测试性能,转向优化真实场景下的部署效率与稳定性。它不再单纯追求在标准数据集上的那一两个百分点提升,而是把重心放在了如何让AI模型在真实世界中更好地工作。
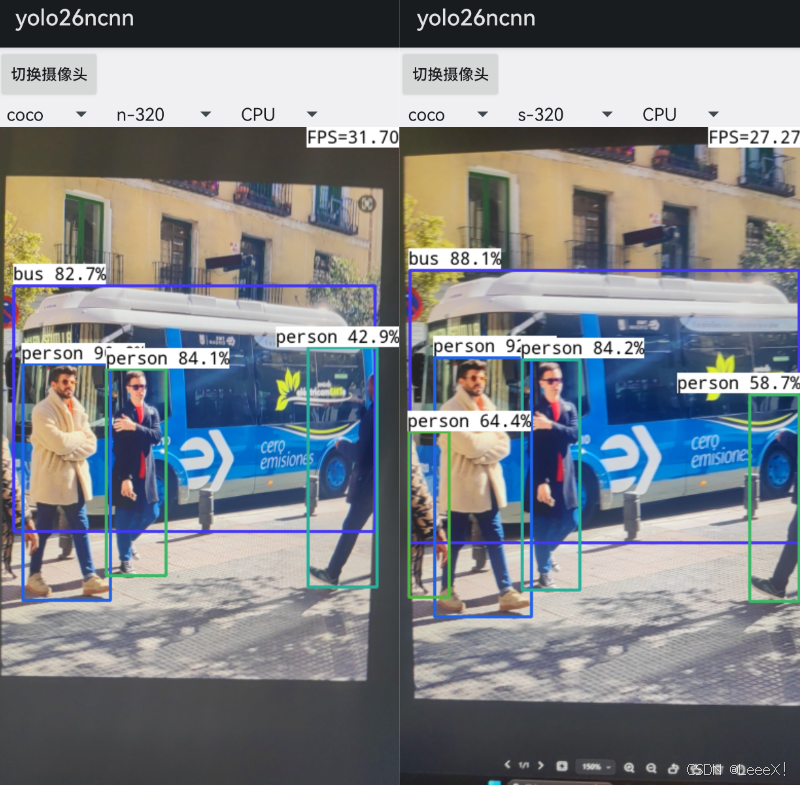
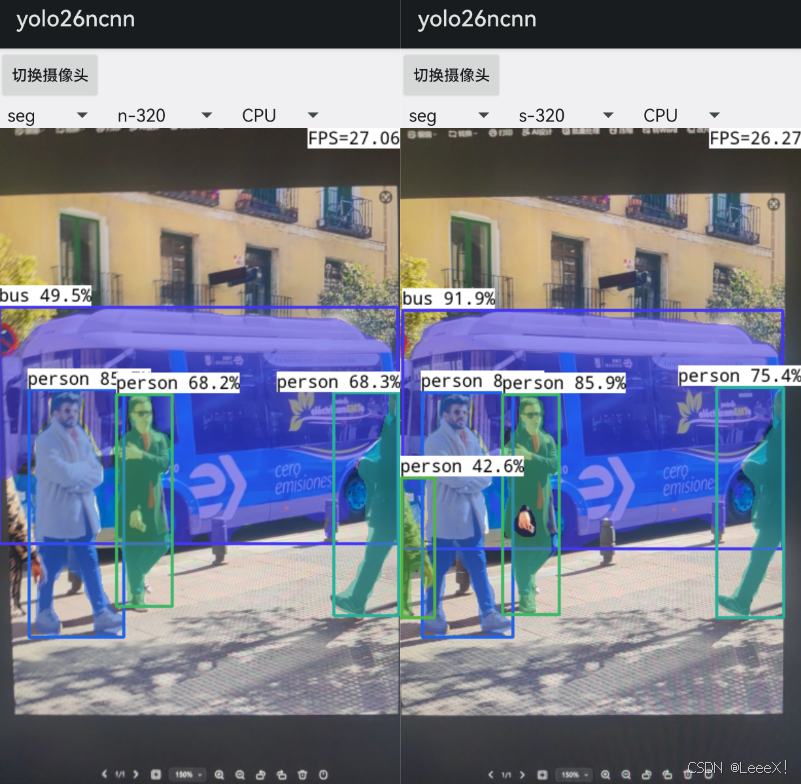
二、环境搭建(Windows版)
bash
#1. 创建conda环境
conda create -n yolo26 python=3.11.9 -y
#2. 激活环境
conda activate yolo26
#3. 安装torch和torchvision
pip install torch==2.2.2 torchvision==0.17.2 --index-url https://download.pytorch.org/whl/cu121
#4.安装ultralytics
pip install -U ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
#4. 预训练权重下载
wget https://github.com/ultralytics/assets/releases/download/v8.4.0/yolo26n.pt
wget https://github.com/ultralytics/assets/releases/download/v8.4.0/yolo26n-seg.pt
wget https://github.com/ultralytics/assets/releases/download/v8.4.0/yolo26n-pose.pt
wget https://github.com/ultralytics/assets/releases/download/v8.4.0/yolo26n-obb.pt
#5. 量化依赖库
pip install -U pnnx ncnn使用指令或者创建infer.py进行推理
bash
yolo predict model=yolo26n.pt source="https://ultralytics.com/images/bus.jpg"
python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo26n.pt") # load an official model
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
# Access the results
for result in results:
xywh = result.boxes.xywh # center-x, center-y, width, height
xywhn = result.boxes.xywhn # normalized
xyxy = result.boxes.xyxy # top-left-x, top-left-y, bottom-right-x, bottom-right-y
xyxyn = result.boxes.xyxyn # normalized
names = [result.names[cls.item()] for cls in result.boxes.cls.int()] # class name of each box
confs = result.boxes.conf # confidence score of each box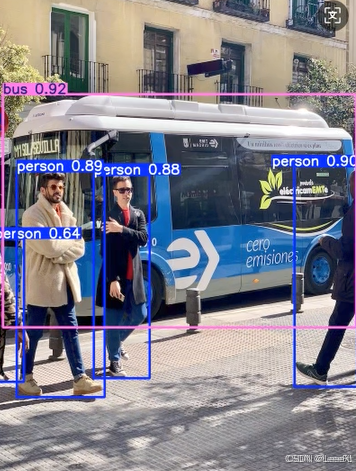
三、pnnx转检测模型
1. 导出yolo26{n/s/m}.torchscript
bash
#看个人需求,选择模型
yolo export model=yolo26n.pt format=torchscript
yolo export model=yolo26s.pt format=torchscript
yolo export model=yolo26m.pt format=torchscript一定要将生成的.torchscript后缀的模型单独放置文件夹,后面步骤会生成比较多的文件
2. 转换静态尺寸输入的 torchscript
bash
#看个人需求,选择模型
pnnx yolo26n.torchscript
pnnx yolo26s.torchscript
pnnx yolo26m.torchscript在进行转换时,会出现一些警告,BinaryOp floor_divide not supported yet,BinaryOp remainder not supported yet,目前暂不支持这两个操作,经过排查,这两个操作基本上都是在后处理中,对于后面结果暂时还没有影响...
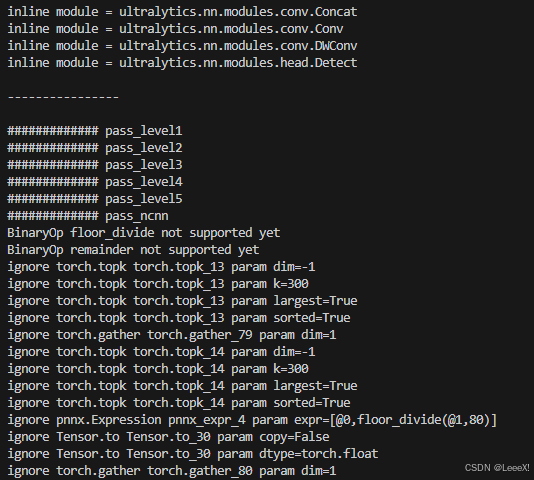
之后会生成以下多个文件
3. 修改 yolo26{n/s/m}_pnnx.py 模型脚本
以yolo26n为例,不同量级模型可能在宽度和深度上有微小区别。
1. 第一处注意力模块(高层特征)
python
# 原始(固定 20×20 → 400):
# v_96 = v_95.reshape(1, 2, 128, 400)
# 改造后(动态 H×W):
B, C, H, W = v_95.shape
v_96 = v_95.reshape(B, 2, 128, -1)
# 后续恢复空间维度时也使用 H, W:
# v_106 = v_105.reshape(1, 128, 20, 20)
# v_107 = v_99.reshape(1, 128, 20, 20)
v_106 = v_105.reshape(B, 128, H, W)
v_107 = v_99.reshape(B, 128, H, W)2. 第二处注意力模块(更深/更大感受野)
python
# 原始(同样假设 20×20):
# v_211 = v_210.reshape(1, 2, 128, 400)
# 改造后:
B, C, H, W = v_210.shape
v_211 = v_210.reshape(B, 2, 128, -1)
# v_221 = v_220.reshape(1, 128, 20, 20)
# v_222 = v_214.reshape(1, 128, 20, 20)
v_221 = v_220.reshape(B, 128, H, W)
v_222 = v_214.reshape(B, 128, H, W)3. 检测头输出(三个尺度)------ 动态展平 + 维度调整
python
# Box 分支(原硬编码 6400/1600/400 = 80²/40²/20²)
v_240 = v_239.reshape(1, 4, -1).transpose(1, 2) # 替代 .reshape(1, 4, 6400)
v_246 = v_245.reshape(1, 4, -1).transpose(1, 2) # 替代 .reshape(1, 4, 1600)
v_252 = v_251.reshape(1, 4, -1).transpose(1, 2) # 替代 .reshape(1, 4, 400)
# Cls 分支(同理)
v_263 = v_262.reshape(1, 80, -1).transpose(1, 2) # 替代 .reshape(1, 80, 6400)
v_273 = v_272.reshape(1, 80, -1).transpose(1, 2) # 替代 .reshape(1, 80, 1600)
v_283 = v_282.reshape(1, 80, -1).transpose(1, 2) # 替代 .reshape(1, 80, 400)
# 拼接方式修正(按 anchor 数量拼接,非通道)
v_253 = torch.cat((v_240, v_246, v_252), dim=1) # 所有 box 预测
v_284 = torch.cat((v_263, v_273, v_283), dim=1) # 所有 cls 预测4. 裁剪后处理,提前返回原始 logits
python
# 删除从 v_285 开始的所有 anchor 解码、sigmoid、topk、NMS 等逻辑
# 直接输出检测头原始结果:
v_det = torch.cat((v_253, v_284), dim=2) # [1, N_total, 4 + num_classes]
return v_det4. 重新导出 yolo26{n/s/m} torchscript
python
python -c 'import yolo26n_pnnx; yolo26n_pnnx.export_torchscript()'
python -c 'import yolo26s_pnnx; yolo26s_pnnx.export_torchscript()'
python -c 'import yolo26m_pnnx; yolo26m_pnnx.export_torchscript()'5. 动态尺寸转换新 torchscript
python
pnnx yolo26n_pnnx.py.pt inputshape=[1,3,640,640] inputshape2=[1,3,320,320]
pnnx yolo26s_pnnx.py.pt inputshape=[1,3,640,640] inputshape2=[1,3,320,320]
pnnx yolo26m_pnnx.py.pt inputshape=[1,3,640,640] inputshape2=[1,3,320,320]四、pnnx转分割模型
1. 动态注意力计算(两处)
python
# 第一处(v_95 → v_107)
B, C, H, W = v_95.shape
v_96 = v_95.reshape(B, 2, 128, -1)
v_106 = v_105.reshape(B, 128, H, W)
v_107 = v_99.reshape(B, 128, H, W)
# 第二处(v_210 → v_222)
B, C, H, W = v_210.shape
v_211 = v_210.reshape(B, 2, 128, -1)
v_221 = v_220.reshape(B, 128, H, W)
v_222 = v_214.reshape(B, 128, H, W)2. 检测与 mask 系数输出重构
python
v_240 = v_239.reshape(1, 4, -1).transpose(1, 2) # box
v_263 = v_262.reshape(1, 80, -1).transpose(1, 2) # cls
v_290 = v_289.reshape(1, 32, -1).transpose(1, 2) # mask coeff
v_253 = torch.cat((v_240, v_246, v_252), dim=1) # [1, N_total, 4]
v_284 = torch.cat((v_263, v_273, v_283), dim=1) # [1, N_total, 80]
v_303 = torch.cat((v_290, v_296, v_302), dim=1) # [1, N_total, 32]
#显式构建检测头输出
v_det = torch.cat((v_253, v_284), dim=2) # [1, N, 84]3. Mask Prototype 上采样动态化 + 提前返回
python
# 动态上采样到 P3 特征图尺寸(v_170 的 H/W)
v_341 = F.upsample_nearest(v_340, size=(v_170.shape[2], v_170.shape[3]))
v_345 = F.upsample_nearest(v_344, size=(v_342.shape[2], v_342.shape[3]))4. 关键代码修改
python
# --- 分类分支 ---
v_284 = torch.cat((v_263, v_273, v_283), dim=1)
# --- 构建 detection head output: [box, cls] ---
v_det = torch.cat((v_253, v_284), dim=2)
v_285 = self.model_23_one2one_cv4_0_0_conv(v_170)
v_286 = self.model_23_one2one_cv4_2_1_act(v_285)
v_287 = self.model_23_one2one_cv4_0_1_conv(v_286)
v_288 = self.pnnx_unique_86(v_287)
v_289 = self.model_23_one2one_cv4_0_2(v_288)
# v_290 = v_289.reshape(1, 32, 6400)
v_290 = v_289.reshape(1, 32, -1).transpose(1,2)
v_291 = self.model_23_one2one_cv4_1_0_conv(v_197)
v_292 = self.pnnx_unique_87(v_291)
v_293 = self.model_23_one2one_cv4_1_1_conv(v_292)
v_294 = self.pnnx_unique_88(v_293)
v_295 = self.model_23_one2one_cv4_1_2(v_294)
# v_296 = v_295.reshape(1, 32, 1600)
v_296 = v_295.reshape(1, 32, -1).transpose(1,2)
v_297 = self.model_23_one2one_cv4_2_0_conv(v_233)
v_298 = self.pnnx_unique_89(v_297)
v_299 = self.model_23_one2one_cv4_2_1_conv(v_298)
v_300 = self.pnnx_unique_90(v_299)
v_301 = self.model_23_one2one_cv4_2_2(v_300)
# v_302 = v_301.reshape(1, 32, 400)
v_302 = v_301.reshape(1, 32, -1).transpose(1,2)
# v_303 = torch.cat((v_290, v_296, v_302), dim=2)
# --- mask coefficient 分支 ---
v_303 = torch.cat((v_290, v_296, v_302), dim=1)
# --- 构建 mask prototype ---
v_339 = self.model_23_proto_feat_refine_0_conv(v_197)
v_340 = self.pnnx_unique_91(v_339)
# v_341 = F.upsample_nearest(v_340, size=(80,80))
v_341 = F.upsample_nearest(v_340, size=(v_170.shape[2], v_170.shape[3]))
v_342 = (v_170 + v_341)
v_343 = self.model_23_proto_feat_refine_1_conv(v_233)
v_344 = self.pnnx_unique_92(v_343)
# v_345 = F.upsample_nearest(v_344, size=(80,80))
v_345 = F.upsample_nearest(v_344, size=(v_342.shape[2], v_342.shape[3]))
v_346 = (v_342 + v_345)
v_347 = self.model_23_proto_feat_fuse_conv(v_346)
v_348 = self.pnnx_unique_93(v_347)
v_349 = self.model_23_proto_cv1_conv(v_348)
v_350 = self.pnnx_unique_94(v_349)
v_351 = self.model_23_proto_upsample(v_350)
v_352 = self.model_23_proto_cv2_conv(v_351)
v_353 = self.pnnx_unique_95(v_352)
v_354 = self.model_23_proto_cv3_conv(v_353)
v_355 = self.pnnx_unique_96(v_354)
return v_det, v_303, v_355五、pnnx转姿态估计模型
1. 动态注意力模块(两处)
python
# 第一处(v_95)
B, C, H, W = v_95.shape
v_96 = v_95.reshape(B, 2, 128, -1)
v_106 = v_105.reshape(B, 128, H, W)
v_107 = v_99.reshape(B, 128, H, W)
# 第二处(v_210)
B, C, H, W = v_210.shape
v_211 = v_210.reshape(B, 2, 128, -1)
v_221 = v_220.reshape(B, 128, H, W)
v_222 = v_214.reshape(B, 128, H, W)2. 检测与关键点输出结构化
python
# Box 分支 (4D)
v_240 = v_239.reshape(1, 4, -1).transpose(1, 2) # [1, N, 4]
# Class 分支 (1D,姿态任务通常单类)
v_263 = v_262.reshape(1, 1, -1).transpose(1, 2) # [1, N, 1]
# Keypoints 分支 (51D = 17 keypoints × (x, y, conf))
v_298 = v_297.reshape(1, 51, -1).transpose(1, 2) # [1, N, 51]
v_253 = torch.cat((v_240, v_246, v_252), dim=1) # [1, N_total, 4]
v_284 = torch.cat((v_263, v_273, v_283), dim=1) # [1, N_total, 1]
v_303 = torch.cat((v_298, v_300, v_302), dim=1) # [1, N_total, 51]
v_det = torch.cat((v_253, v_284), dim=2) # [1, N, 5]
return v_det, v_3033. 关键代码修改
python
v_251 = self.model_23_one2one_cv2_2_2(v_250)
# v_252 = v_251.reshape(1, 4, 400)
v_252 = v_251.reshape(1, 4, -1).transpose(1,2)
# --- box 分支---
v_253 = torch.cat((v_240, v_246, v_252), dim=1)
v_254 = self.model_23_one2one_cv3_0_0_0_conv(v_170)
v_255 = self.model_23_one2one_cv3_2_1_1_act(v_254)
v_256 = self.model_23_one2one_cv3_0_0_1_conv(v_255)
v_257 = self.pnnx_unique_75(v_256)
v_258 = self.model_23_one2one_cv3_0_1_0_conv(v_257)
v_259 = self.pnnx_unique_76(v_258)
v_260 = self.model_23_one2one_cv3_0_1_1_conv(v_259)
v_261 = self.pnnx_unique_77(v_260)
v_262 = self.model_23_one2one_cv3_0_2(v_261)
# v_263 = v_262.reshape(1, 1, 6400)
v_263 = v_262.reshape(1, 1, -1).transpose(1,2)
v_264 = self.model_23_one2one_cv3_1_0_0_conv(v_197)
v_265 = self.pnnx_unique_78(v_264)
v_266 = self.model_23_one2one_cv3_1_0_1_conv(v_265)
v_267 = self.pnnx_unique_79(v_266)
v_268 = self.model_23_one2one_cv3_1_1_0_conv(v_267)
v_269 = self.pnnx_unique_80(v_268)
v_270 = self.model_23_one2one_cv3_1_1_1_conv(v_269)
v_271 = self.pnnx_unique_81(v_270)
v_272 = self.model_23_one2one_cv3_1_2(v_271)
# v_273 = v_272.reshape(1, 1, 1600)
v_273 = v_272.reshape(1, 1, -1).transpose(1,2)
v_274 = self.model_23_one2one_cv3_2_0_0_conv(v_233)
v_275 = self.pnnx_unique_82(v_274)
v_276 = self.model_23_one2one_cv3_2_0_1_conv(v_275)
v_277 = self.pnnx_unique_83(v_276)
v_278 = self.model_23_one2one_cv3_2_1_0_conv(v_277)
v_279 = self.pnnx_unique_84(v_278)
v_280 = self.model_23_one2one_cv3_2_1_1_conv(v_279)
v_281 = self.pnnx_unique_85(v_280)
v_282 = self.model_23_one2one_cv3_2_2(v_281)
# v_283 = v_282.reshape(1, 1, 400)
v_283 = v_282.reshape(1, 1, -1).transpose(1,2)
# --- 分类分支 ---
v_284 = torch.cat((v_263, v_273, v_283), dim=1)
# --- 构建 detection head output: [box, cls] ---
v_det = torch.cat((v_253, v_284), dim=2)
v_285 = self.model_23_one2one_cv4_0_0_conv(v_170)
v_286 = self.model_23_one2one_cv4_2_1_act(v_285)
v_287 = self.model_23_one2one_cv4_0_1_conv(v_286)
v_288 = self.pnnx_unique_86(v_287)
v_289 = self.model_23_one2one_cv4_1_0_conv(v_197)
v_290 = self.pnnx_unique_87(v_289)
v_291 = self.model_23_one2one_cv4_1_1_conv(v_290)
v_292 = self.pnnx_unique_88(v_291)
v_293 = self.model_23_one2one_cv4_2_0_conv(v_233)
v_294 = self.pnnx_unique_89(v_293)
v_295 = self.model_23_one2one_cv4_2_1_conv(v_294)
v_296 = self.pnnx_unique_90(v_295)
v_297 = self.model_23_one2one_cv4_kpts_0(v_288)
# v_298 = v_297.reshape(1, 51, 6400)
v_298 = v_297.reshape(1, 51, -1).transpose(1,2)
v_299 = self.model_23_one2one_cv4_kpts_1(v_292)
# v_300 = v_299.reshape(1, 51, 1600)
v_300 = v_299.reshape(1, 51, -1).transpose(1,2)
v_301 = self.model_23_one2one_cv4_kpts_2(v_296)
# v_302 = v_301.reshape(1, 51, 400)
v_302 = v_301.reshape(1, 51, -1).transpose(1,2)
# v_303 = torch.cat((v_298, v_300, v_302), dim=2)
# --- 关键点 ---
v_303 = torch.cat((v_298, v_300, v_302), dim=1)
return v_det, v_303六、pnnx转旋转框obb模型
1、 动态注意力模块(两处)
python
# 第一处(v_95)
B, C, H, W = v_95.shape
v_96 = v_95.reshape(B, 2, 128, -1)
v_106 = v_105.reshape(B, 128, H, W)
v_107 = v_99.reshape(B, 128, H, W)
# 第二处(v_210)
B, C, H, W = v_210.shape
v_211 = v_210.reshape(B, 2, 128, -1)
v_221 = v_220.reshape(B, 128, H, W)
v_222 = v_214.reshape(B, 128, H, W)2、 输出结构化重构:Box + Class + Angle 解耦
python
# Box 分支 (4D: cx, cy, w, h)
v_240 = v_239.reshape(1, 4, -1).transpose(1, 2) # [1, N, 4]
# Class 分支 (15D: 多类别置信度)
v_263 = v_262.reshape(1, 15, -1).transpose(1, 2) # [1, N, 15]
# Angle 分支 (1D: 旋转角度余弦/正弦或直接角度)
v_290 = v_289.reshape(1, 1, -1).transpose(1, 2) # [1, N, 1]
v_253 = torch.cat((v_240, v_246, v_252), dim=1) # [1, N_total, 4]
v_284 = torch.cat((v_263, v_273, v_283), dim=1) # [1, N_total, 15]
v_303 = torch.cat((v_290, v_296, v_302), dim=1) # [1, N_total, 1]
v_det = torch.cat((v_253, v_284), dim=2) # [1, N, 19] = [box(4) + cls(15)]
return v_det, v_303
# - v_det: [1, N, 19] → (cx, cy, w, h, cls_0, ..., cls_14)
# - v_303: [1, N, 1] → 旋转角度(或其编码,如 cos/sin)3、关键代码改动
python
v_247 = self.model_23_one2one_cv2_2_0_conv(v_233)
v_248 = self.pnnx_unique_73(v_247)
v_249 = self.model_23_one2one_cv2_2_1_conv(v_248)
v_250 = self.pnnx_unique_74(v_249)
v_251 = self.model_23_one2one_cv2_2_2(v_250)
# v_252 = v_251.reshape(1, 4, 1024)
v_252 = v_251.reshape(1, 4, -1).transpose(1,2)
# --- 合并三个尺度的 box 预测---
v_253 = torch.cat((v_240, v_246, v_252), dim=1)
v_254 = self.model_23_one2one_cv3_0_0_0_conv(v_170)
v_255 = self.model_23_one2one_cv3_2_1_1_act(v_254)
v_256 = self.model_23_one2one_cv3_0_0_1_conv(v_255)
v_257 = self.pnnx_unique_75(v_256)
v_258 = self.model_23_one2one_cv3_0_1_0_conv(v_257)
v_259 = self.pnnx_unique_76(v_258)
v_260 = self.model_23_one2one_cv3_0_1_1_conv(v_259)
v_261 = self.pnnx_unique_77(v_260)
v_262 = self.model_23_one2one_cv3_0_2(v_261)
# v_263 = v_262.reshape(1, 15, 16384)
v_263 = v_262.reshape(1, 15, -1).transpose(1,2)
v_264 = self.model_23_one2one_cv3_1_0_0_conv(v_197)
v_265 = self.pnnx_unique_78(v_264)
v_266 = self.model_23_one2one_cv3_1_0_1_conv(v_265)
v_267 = self.pnnx_unique_79(v_266)
v_268 = self.model_23_one2one_cv3_1_1_0_conv(v_267)
v_269 = self.pnnx_unique_80(v_268)
v_270 = self.model_23_one2one_cv3_1_1_1_conv(v_269)
v_271 = self.pnnx_unique_81(v_270)
v_272 = self.model_23_one2one_cv3_1_2(v_271)
# v_273 = v_272.reshape(1, 15, 4096)
v_273 = v_272.reshape(1, 15, -1).transpose(1,2)
v_274 = self.model_23_one2one_cv3_2_0_0_conv(v_233)
v_275 = self.pnnx_unique_82(v_274)
v_276 = self.model_23_one2one_cv3_2_0_1_conv(v_275)
v_277 = self.pnnx_unique_83(v_276)
v_278 = self.model_23_one2one_cv3_2_1_0_conv(v_277)
v_279 = self.pnnx_unique_84(v_278)
v_280 = self.model_23_one2one_cv3_2_1_1_conv(v_279)
v_281 = self.pnnx_unique_85(v_280)
v_282 = self.model_23_one2one_cv3_2_2(v_281)
# v_283 = v_282.reshape(1, 15, 1024)
v_283 = v_282.reshape(1, 15, -1).transpose(1,2)
# --- 合并三个尺度的 cls 预测 ---
v_284 = torch.cat((v_263, v_273, v_283), dim=1)
v_285 = self.model_23_one2one_cv4_0_0_conv(v_170)
v_286 = self.model_23_one2one_cv4_2_1_act(v_285)
v_287 = self.model_23_one2one_cv4_0_1_conv(v_286)
v_288 = self.pnnx_unique_86(v_287)
v_289 = self.model_23_one2one_cv4_0_2(v_288)
# v_290 = v_289.reshape(1, 1, 16384)
v_290 = v_289.reshape(1, 1, -1).transpose(1,2)
v_291 = self.model_23_one2one_cv4_1_0_conv(v_197)
v_292 = self.pnnx_unique_87(v_291)
v_293 = self.model_23_one2one_cv4_1_1_conv(v_292)
v_294 = self.pnnx_unique_88(v_293)
v_295 = self.model_23_one2one_cv4_1_2(v_294)
# v_296 = v_295.reshape(1, 1, 4096)
v_296 = v_295.reshape(1, 1, -1).transpose(1,2)
v_297 = self.model_23_one2one_cv4_2_0_conv(v_233)
v_298 = self.pnnx_unique_89(v_297)
v_299 = self.model_23_one2one_cv4_2_1_conv(v_298)
v_300 = self.pnnx_unique_90(v_299)
v_301 = self.model_23_one2one_cv4_2_2(v_300)
# v_302 = v_301.reshape(1, 1, 1024)
v_302 = v_301.reshape(1, 1, -1).transpose(1,2)
# ---合并三个尺度的 angle 预测 ---
v_303 = torch.cat((v_290, v_296, v_302), dim=1)
v_det = torch.cat((v_253, v_284), dim=2)
return v_det, v_303