这里写自定义目录标题
-
- [1. VLN Paradigm](#1. VLN Paradigm)
- [2. VLN Paradigm Alg](#2. VLN Paradigm Alg)
- [3. 模仿学习](#3. 模仿学习)
- [3.1 Teacher-forcing 与 Student-forcing 的异同点与搭配使用](#3.1 Teacher-forcing 与 Student-forcing 的异同点与搭配使用)
-
- [3.1.1 核心定义(一句话区分)](#3.1.1 核心定义(一句话区分))
- [3.1.2 Teacher-forcing(教师强制 · 离线演示)](#3.1.2 Teacher-forcing(教师强制 · 离线演示))
- [3.1.3 使用方式(训练流程)](#3.1.3 使用方式(训练流程))
- [3.1.4 本质](#3.1.4 本质)
- [3.1.5 优点](#3.1.5 优点)
- [3.1.6 致命缺陷:暴露偏差(Exposure Bias)](#3.1.6 致命缺陷:暴露偏差(Exposure Bias))
- [3.2 Student-forcing(学生强制 · 交互式演示)](#3.2 Student-forcing(学生强制 · 交互式演示))
-
- [3.2.1 使用方式(训练流程)](#3.2.1 使用方式(训练流程))
- [3.2.2 本质](#3.2.2 本质)
- [3.2.3 优点](#3.2.3 优点)
- [3.2.4 缺陷](#3.2.4 缺陷)
- [3.3 能否搭配使用?](#3.3 能否搭配使用?)
-
- [3.3.1 搭配的核心逻辑(互补)](#3.3.1 搭配的核心逻辑(互补))
- [3.4 主流搭配使用方案(工程&学术标准)](#3.4 主流搭配使用方案(工程&学术标准))
-
- 方案1:分阶段训练(最常用、最简单)
-
- [阶段1:纯 Teacher-forcing(预热/预训练)](#阶段1:纯 Teacher-forcing(预热/预训练))
- [阶段2:纯 Student-forcing(精调/闭环优化)](#阶段2:纯 Student-forcing(精调/闭环优化))
- 方案2:动态混合式强制(每步随机选择)
- [方案3:DAgger(Dataset Aggregation)------ 模仿学习经典标杆](#方案3:DAgger(Dataset Aggregation)—— 模仿学习经典标杆)
- 方案4:部分序列混合(长视距任务)
- [3.5 搭配后为什么更"合理"?](#3.5 搭配后为什么更“合理”?)
- [3.6 总结(极简版)](#3.6 总结(极简版))
1. VLN Paradigm
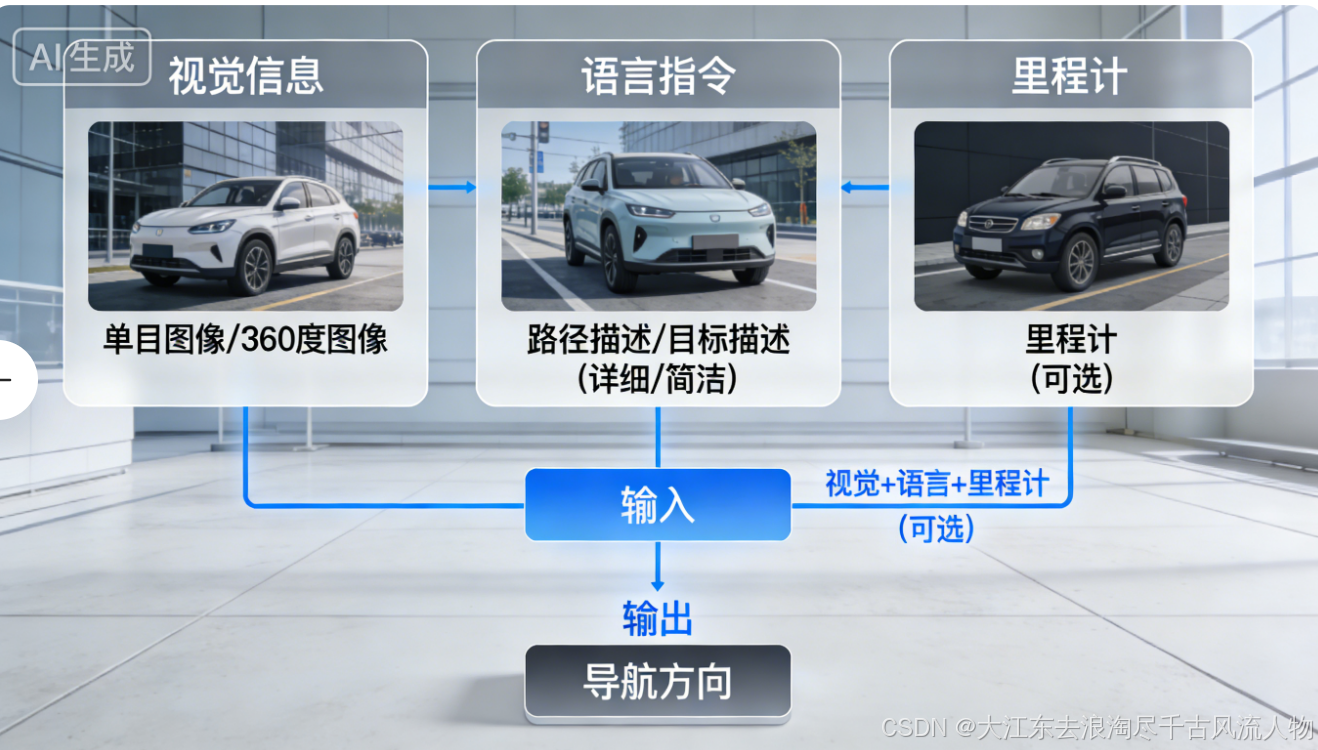
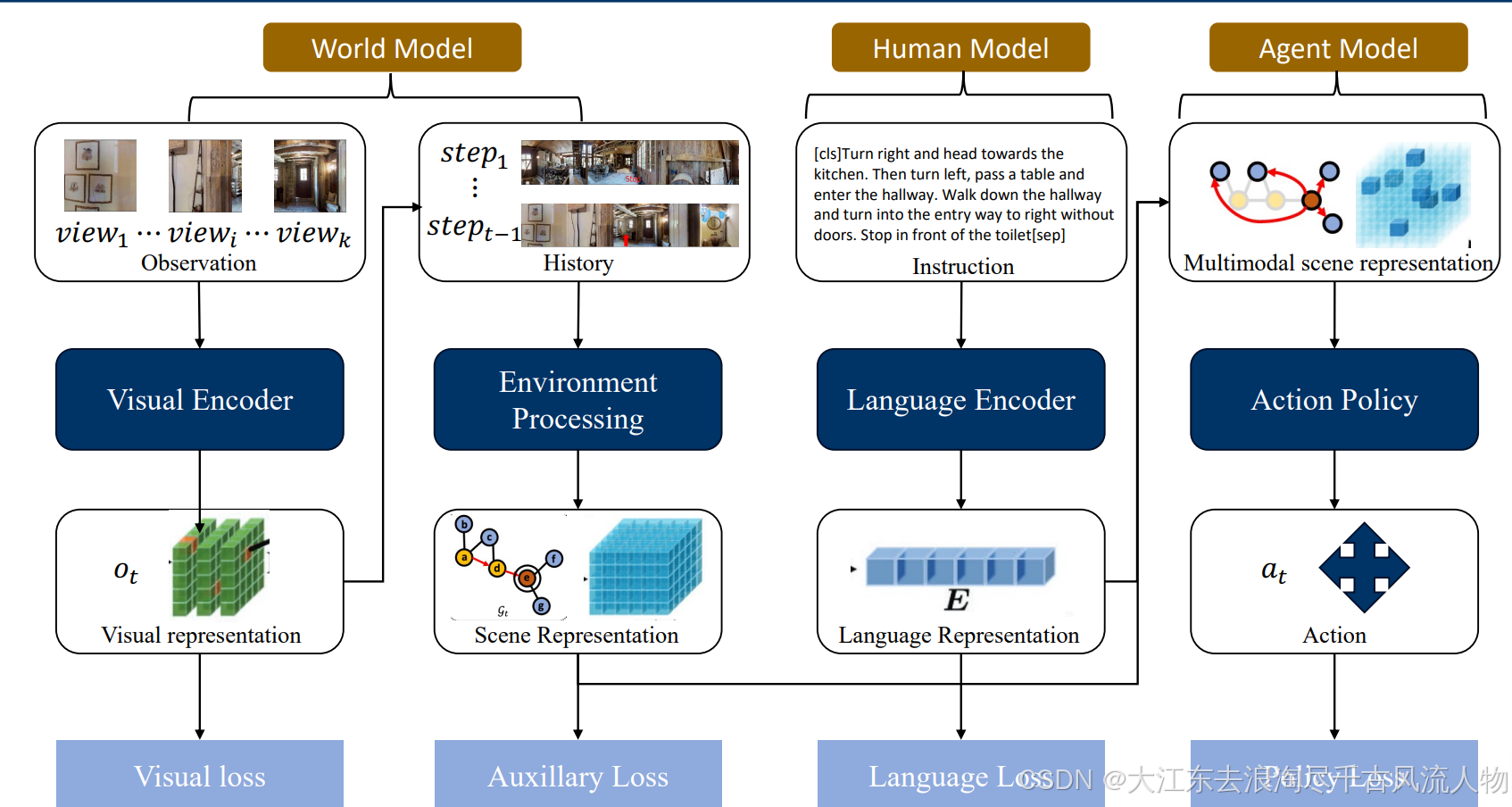
极简一句话总结
Auxiliary Loss = 训练时的 "额外小老师",用额外监督信号帮模型学得更好、更稳,推理时直接下课,不影响最终模型。

2. VLN Paradigm Alg
| 英文 | 中文 |
|---|---|
| Behavior cloning (imitation learning) | 行为克隆(模仿学习) |
| - Teacher-forcing: Offline demonstrator | 教师强制:离线演示者 |
| - Student-forcing: Interactive demonstrator | 学生强制:交互式演示者 |
| Reinforcement Learning | 强化学习 |
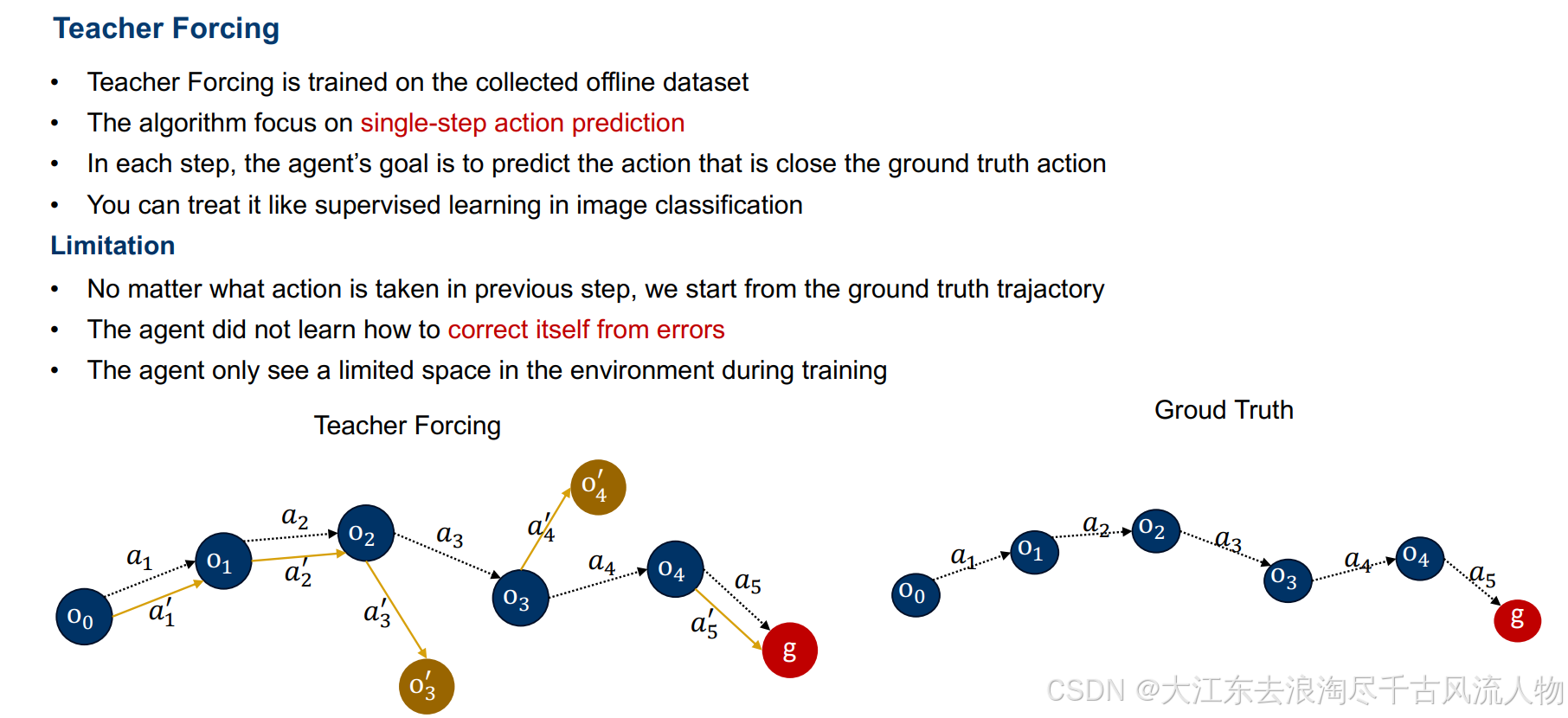
Teacher-forcing: Offline demonstrator
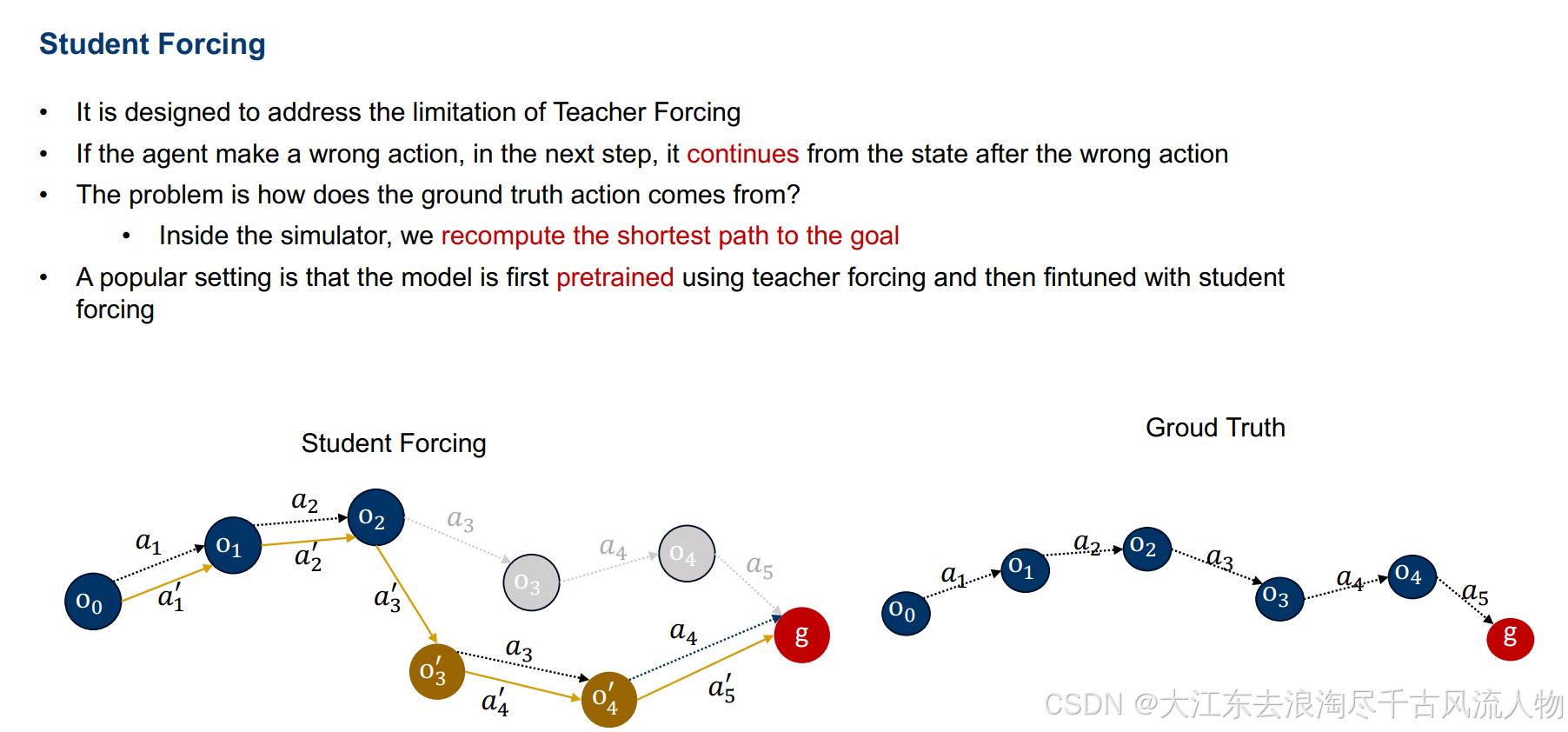
Student-forcing: Interactive demonstrator
compare
VLN Paradigm -- Behavior Cloning
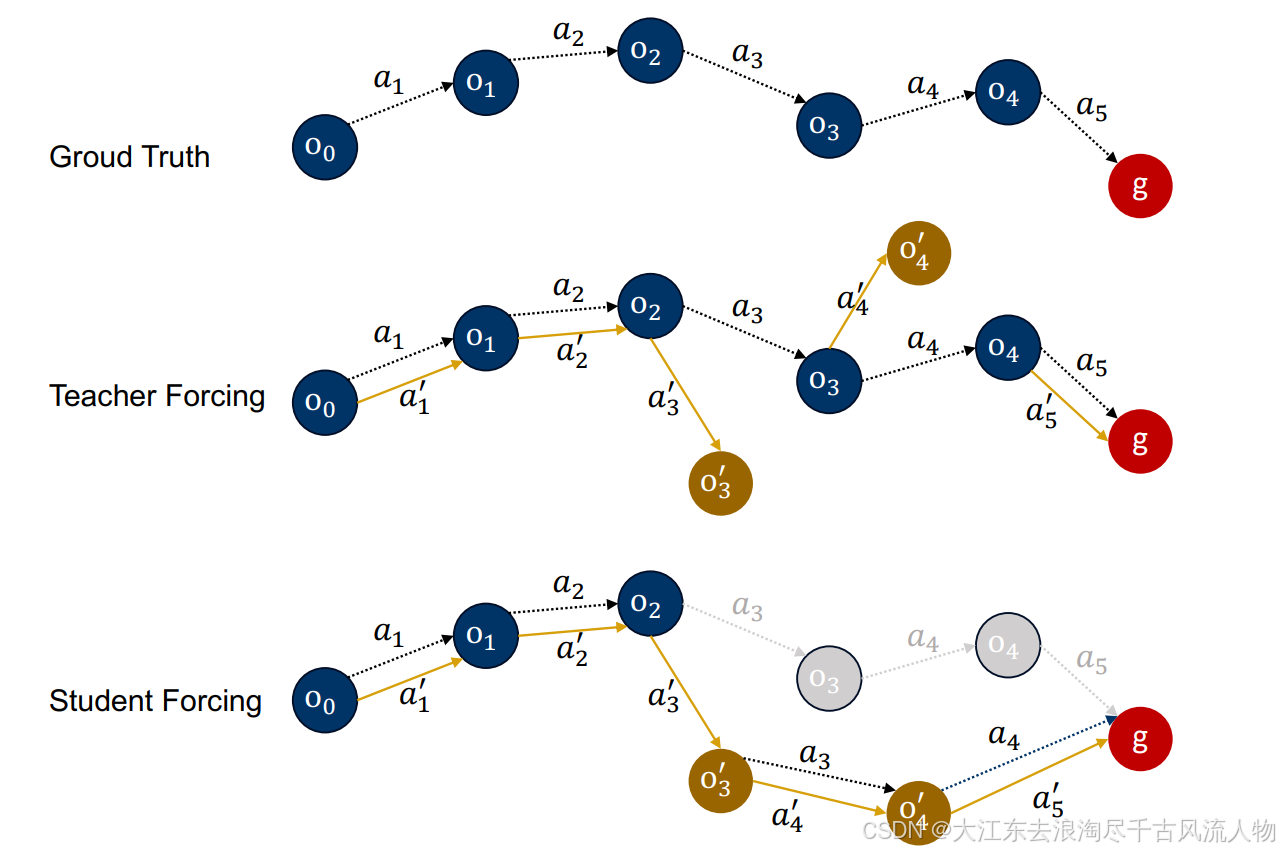
在模仿学习(尤其是行为克隆 BC)中,Teacher-forcing、Student-forcing 是两种轨迹状态输入来源 的核心训练策略,二者完全可以搭配使用,也是解决单一策略缺陷、构建更稳定、泛化更强训练流程的主流方案。
下面分三部分详细说明:
1)两者的定义、训练流程与优缺点
2)能否搭配 + 为什么搭配更合理
3)具体搭配范式(含经典算法 DAgger)
3. 模仿学习
3.1 Teacher-forcing 与 Student-forcing 的异同点与搭配使用
3.1.1 核心定义(一句话区分)
- Teacher-forcing(教师强制) :每一步输入 = 专家演示的真实历史状态(离线、监督式)
- Student-forcing(学生强制) :每一步输入 = 模型自己上一步动作产生的新状态(在线、闭环交互)
共同目标:让模型输出动作逼近专家动作;
核心差异:状态从哪来,决定训练分布与测试分布是否一致。
3.1.2 Teacher-forcing(教师强制 · 离线演示)
3.1.3 使用方式(训练流程)
适用于:纯离线行为克隆 ,预先收集好专家轨迹数据集:
τ ∗ = { ( s 0 ∗ , a 0 ∗ ) , ( s 1 ∗ , a 1 ∗ ) , ... , ( s T ∗ , a T ∗ ) } \tau^* = \{(s_0^*,a_0^*),\ (s_1^*,a_1^*),\dots,(s_T^*,a_T^*)\} τ∗={(s0∗,a0∗), (s1∗,a1∗),...,(sT∗,aT∗)}
训练步骤:
- 逐时间步取 专家真实状态 s t ∗ s_t^* st∗作为模型输入
- 模型输出动作 a ^ t \hat{a}_t a^t
- 损失: L = Loss ( a ^ t , a t ∗ ) \mathcal{L} = \text{Loss}(\hat{a}_t,\ a_t^*) L=Loss(a^t, at∗)(MSE/交叉熵)
- 全程不与环境交互,只在离线数据集上做监督学习
3.1.4 本质
用专家轨迹"强行纠正"每一步输入,让模型始终看到标准分布的状态。
3.1.5 优点
- 训练极稳定、收敛快、不易崩
- 完全利用离线专家数据,无需环境交互
- 初期策略学习效率极高
3.1.6 致命缺陷:暴露偏差(Exposure Bias)
- 训练分布 = 专家状态分布
- 测试/部署分布 = 模型自己走出来的状态分布
→ 模型从未见过自己犯错后的状态,一步错 → 步步错 → 轨迹快速偏离崩溃(复合误差累积)。
3.2 Student-forcing(学生强制 · 交互式演示)
3.2.1 使用方式(训练流程)
适用于:在线/闭环模仿学习,必须与环境实时交互:
训练步骤:
- 从初始状态 (s_0) 开始
- 模型输入当前状态 (s_t)(由模型上一步动作与环境交互得到)
- 输出 (\hat{a}t),进入环境得到 (s{t+1})
- 损失依旧对齐专家动作(或专家示范)
- 全程轨迹由模型自主生成,而非来自数据集
3.2.2 本质
让模型在"自己会遇到的真实分布"上训练,与部署环境一致。
3.2.3 优点
- 完美解决 暴露偏差 / 复合误差累积
- 测试性能与训练性能一致
- 闭环泛化极强
3.2.4 缺陷
- 冷启动极不稳定:初始模型很差 → 轨迹极差 → 训练崩溃
- 收敛慢、需要大量在线交互
- 容易陷入局部最优、噪声敏感
3.3 能否搭配使用?
可以,且是模仿学习最经典、最合理的训练范式。
3.3.1 搭配的核心逻辑(互补)
- Teacher-forcing 负责:稳定初始化、快速收敛、提供高质量监督
- Student-forcing 负责:修正分布偏移、适应闭环部署、消除暴露偏差
单独用任何一个都有明显短板,混合/交替/迭代使用 才能得到:
稳定训练 + 真实分布对齐 + 强泛化 的完整流程。
3.4 主流搭配使用方案(工程&学术标准)
方案1:分阶段训练(最常用、最简单)
阶段1:纯 Teacher-forcing(预热/预训练)
- 只用离线专家数据,快速学到基础策略
- 让模型达到中等以上性能,避免冷启动崩溃
阶段2:纯 Student-forcing(精调/闭环优化)
- 切换到模型自生成轨迹,在线交互微调
- 让模型适应自身误差与真实部署分布
效果:前期稳、后期准,完美解决双缺陷。
方案2:动态混合式强制(每步随机选择)
每一步训练中,以概率 (p) 用 Teacher,(1-p) 用 Student:
- 训练开始:(p \approx 1)(几乎全 Teacher)
- 训练后期:(p \rightarrow 0)(几乎全 Student)
也可自适应调整:模型准确率越高,越少用 Teacher。
方案3:DAgger(Dataset Aggregation)------ 模仿学习经典标杆
DAgger 就是 Teacher-forcing + Student-forcing 最标准的结合算法,专门解决暴露偏差。
流程:
- Teacher 阶段:用专家离线数据训练初始模型 (\pi_1)
- Student 阶段 :用 (\pi_1) 与环境交互,收集模型自生成状态 (S_{\text{model}})
- Teacher 再标注:让专家对 (S_{\text{model}}) 标注最优动作
- 混合训练:新标注数据 + 原始专家数据 → 继续 Teacher-forcing 训练 (\pi_2)
- 迭代多次,直到轨迹分布收敛
本质
- Student-forcing 提供 真实部署的状态分布
- Teacher-forcing 提供 高质量监督信号
→ 既稳定又无分布偏移。
方案4:部分序列混合(长视距任务)
- 前 k 步:用专家状态(Teacher)保证起点正确
- k 步之后:切换为模型自生成状态(Student)
逐步增加模型自主控制长度,实现平滑过渡。
3.5 搭配后为什么更"合理"?
单一策略的训练过程都存在本质矛盾:
- Teacher:训练简单,但训练-测试分布不一致(部署必崩)
- Student:分布一致,但训练难收敛、易崩溃
搭配后实现:
- 训练稳定性 ↑:前期靠 Teacher 避免发散
- 泛化能力 ↑:后期靠 Student 对齐真实闭环分布
- 数据效率 ↑:离线数据 + 少量在线交互,无需海量演示
- 部署一致性 ↑:模型在训练中就见过自己的错误,不会突然崩盘
3.6 总结(极简版)
| 策略 | 输入状态来源 | 优势 | 缺陷 |
|---|---|---|---|
| Teacher-forcing | 专家离线演示 | 稳定、快收敛 | 暴露偏差、测试崩 |
| Student-forcing | 模型自生成+环境 | 无偏差、泛化强 | 冷启动不稳、慢 |
| 搭配使用 | 混合/交替/迭代 | 稳定 + 泛化 + 一致 | 工程稍复杂 |
结论 :
Teacher-forcing 与 Student-forcing 不仅可以搭配,而且必须搭配 ,才能在模仿学习中得到稳定、高效、部署可靠 的训练过程。其中 DAgger 是最成熟、最常用的官方级组合方案。