16_RNN为什么记不住长文本?循环神经网络的缺陷
本章目标 :理解序列数据的本质 ------ 顺序就是信息。掌握 RNN 的核心机制:权重共享 与时间展开 (Unrolling) 。深入剖析其致命缺陷:梯度消失 与长距离依赖问题,为下一章 LSTM 的出场做铺垫。
目录
- [序列数据:Context Matters](#序列数据:Context Matters)
- RNN:自带记忆的神经网络
- 核心机制:权重共享 (Weight Sharing)
- BPTT:随时间反向传播
- [痛点:为什么 RNN 记不住长句子?](#痛点:为什么 RNN 记不住长句子?)
- [实战:PyTorch 实现 RNN Cell](#实战:PyTorch 实现 RNN Cell)
1. 序列数据:Context Matters
假如我想预测这句话的下一个词:
- "The clouds are in the ____." (Answer: sky)
- "I grew up in France... I speak fluent ____." (Answer: French)
在 CNN 或 MLP 中,输入是独立的。但在序列数据中,当前的输出依赖于之前的输入 。这就需要网络拥有记忆力 (Memory)。
2. RNN:自带记忆的神经网络
循环神经网络 (RNN) 的结构其实非常简单,就比 MLP 多了一个环(Loop):
h t = tanh ( W x h ⋅ x t + W h h ⋅ h t − 1 + b ) h_t = \tanh(W_{xh} \cdot x_t + W_{hh} \cdot h_{t-1} + b) ht=tanh(Wxh⋅xt+Whh⋅ht−1+b)
- x t x_t xt: 当前时刻的输入 (Input)。
- h t − 1 h_{t-1} ht−1: 上一时刻的隐藏状态 (Hidden State),也就是"记忆"。
- h t h_t ht: 当前时刻更新后的"记忆"。
- tanh \tanh tanh: 激活函数,把值压缩到 ( − 1 , 1 ) (-1, 1) (−1,1)。
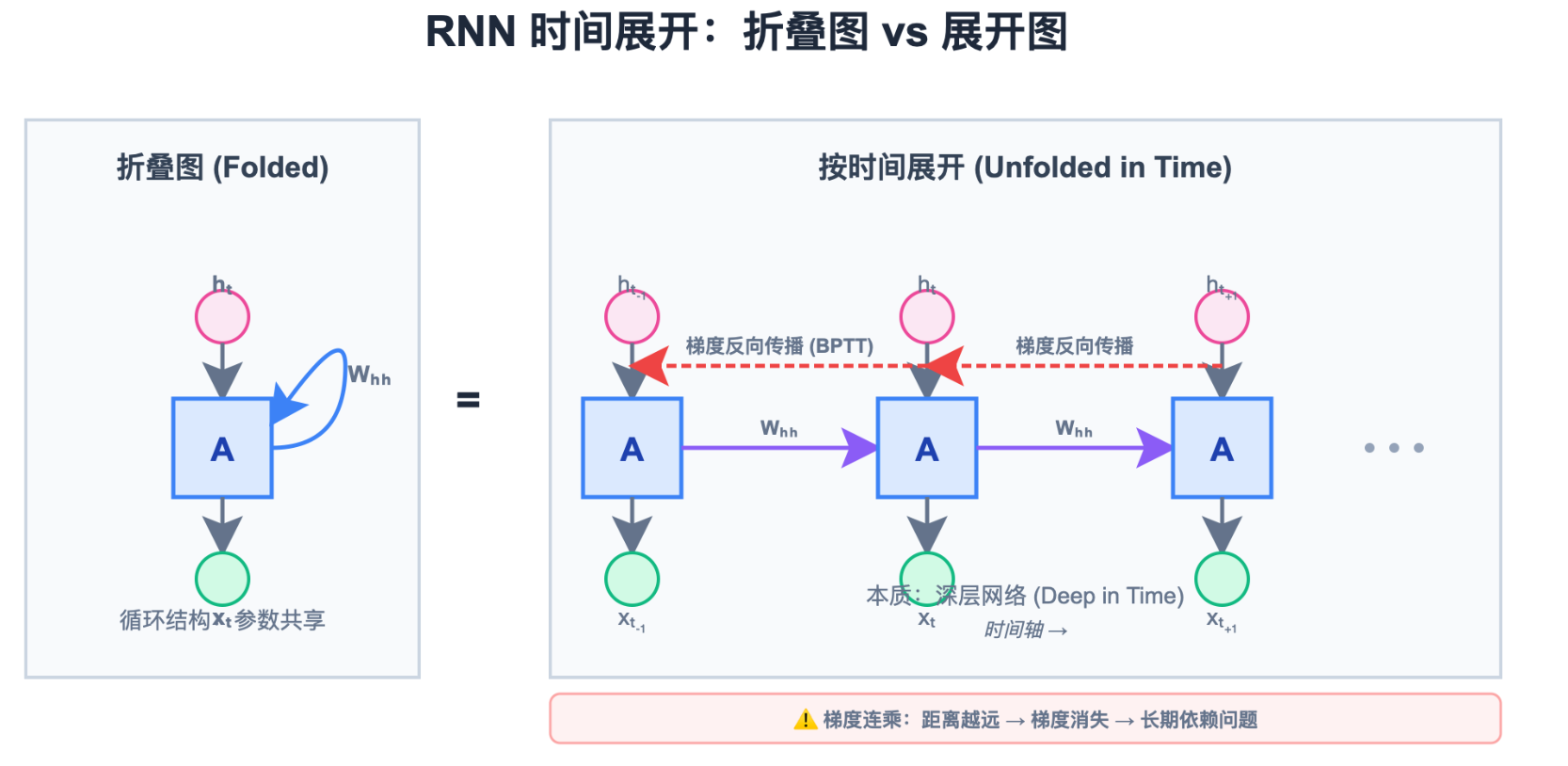
看上图:左边是折叠图 (Folded),右边是时间展开图 (Unfolded)。
关键点 :虽然右图看起来很深,但每一层用的 W h h W_{hh} Whh 和 W x h W_{xh} Wxh 都是同一个!
3. 核心机制:权重共享 (Weight Sharing)
这一点和 CNN 很像:
- CNN : 卷积核在空间上滑动(不管猫在左上角还是右下角都用同一个核)。
- RNN : 细胞核在时间上滑动(不管是在第1秒还是第100秒都用同一个参数)。
如果你对每个时间步都用不同的权重,那就不是 RNN,而是全连接网络了,而且无法处理变长序列。
4. BPTT:随时间反向传播 (Backpropagation Through Time)
当我们要训练 RNN 时,我们把它按时间轴展开 (Unroll) 成一个深层网络。
- Forward : x 1 → h 1 → h 2 → ⋯ → h T x_1 \to h_1 \to h_2 \to \dots \to h_T x1→h1→h2→⋯→hT
- Loss : L = ∑ t = 1 T L t L = \sum_{t=1}^T L_t L=∑t=1TLt (每个时刻都有损失)。
- Backward : 梯度需要从最后一个时刻 T T T,一直反向传播回 t = 0 t=0 t=0。这条红色的梯度流就是 BPTT。
5. 痛点:为什么 RNN 记不住长句子?
这就是著名的 长距离依赖 (Long-term Dependency) 问题,本质上是 梯度消失。
在 BPTT 中,梯度的计算涉及连乘:
∂ h T ∂ h t = ∏ k = t T − 1 ∂ h k + 1 ∂ h k ≈ ∏ W h h ⋅ tanh ′ \frac{\partial h_T}{\partial h_t} = \prod_{k=t}^{T-1} \frac{\partial h_{k+1}}{\partial h_k} \approx \prod W_{hh} \cdot \tanh' ∂ht∂hT=k=t∏T−1∂hk∂hk+1≈∏Whh⋅tanh′
- tanh ′ \tanh' tanh′ 的导数最大值是 1(通常远小于 1)。
- 如果 ∣ W h h ∣ |W_{hh}| ∣Whh∣ 也小于 1(初始化或正则化导致)。
- 那么几百个小于 1 的数相乘,结果趋近于 0。
结果 :RNN 只能"看"到最近几步的信息。
对于 "I grew up in France... (隔了100个词) ... I speak fluent French "。
RNN 读到 "speak" 时,关于 "France" 的梯度早就消失了,它根本不知道前面提到了法国。
6. 实战:PyTorch 实现 RNN Cell
我们手动实现一个简单的 RNN Cell,感受一下这个循环过程。
python
import torch
import torch.nn as nn
class MyRNNCell(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 输入 -> 隐层
self.i2h = nn.Linear(input_size, hidden_size)
# 隐层 -> 隐层 (循环核)
self.h2h = nn.Linear(hidden_size, hidden_size)
def forward(self, input, hidden):
# h_t = tanh(W_ih * x_t + W_hh * h_{t-1})
combined = self.i2h(input) + self.h2h(hidden)
hidden = torch.tanh(combined)
return hidden
# 使用示例
input_size = 4
hidden_size = 8
cell = MyRNNCell(input_size, hidden_size)
# 模拟序列: SeqLen=5, Batch=1, Feature=4
inputs = torch.randn(5, 1, input_size)
hidden = torch.zeros(1, hidden_size) # 初始记忆为 0
print("Processing sequence:")
for idx, x in enumerate(inputs):
# x: [Batch, Input]
hidden = cell(x[0], hidden)
print(f"Step {idx+1}: Hidden state norm = {hidden.norm():.4f}")问题 :由于梯度消失,RNN 无法处理长序列。有什么办法能让记忆保持得更久一点?
这就需要给神经元装上"开关"(门控机制)。
下一章,我们将介绍 LSTM (Long Short-Term Memory)。