论文:Knowledge Bridging for Empathetic Dialogue Generation
会议:AAAI 2022
作者:Qintong Li et al.(山东大学、腾讯、香港大学)
一、 动机 & 问题背景 (Motivation & Background)
本文聚焦于在对话中生成共情性对话。
共情 是一个好的倾听者在社会交际中的基本特征,它通过提供共情反馈来表现出倾听者对说话者的想法和感受的理解。
共情的话语可以增强倾听者的积极印象,促进说话者表达自己的意愿,已有的研究表明,具有共情特征的对话生成模式可以产生更多的反应,用户对对话系统的满意度。
核心问题 :现有的对话系统在生成共情回复时,往往难以感知隐式情感。仅凭有限的对话历史,机器很难像人类一样通过经验和外部知识来捕捉说话者的真实情绪 。
背景痛点:
-
回复与历史词汇重合度极低:研究发现,在共情对话数据集中,回复内容与对话历史的非停用词重合率仅为 0.5%,这说明共情回复往往依赖于对话文本之外的知识推理 。
-
外部知识的缺失:缺乏外部知识(如常识、情感词典)使系统难以理解对话背后的深层含义 。
-
情感依赖性被忽视 :人类在交流中存在情感依赖和情感惯性(如倾向于镜像对方的情绪来建立和谐关系),而现有模型对这种动态情感转换建模不足 。

图1
- 图一中是利用取自EMPATHETICDIALOGUES的外部知识进行共情对话的例子 ,对话中与情感相关的词语以红色突出显示,而与情感相关的概念以蓝色标记,括号中的数字表示情感强度值。
- 如图1中的回复与对话历史几乎没有关键词语的重叠(0.5%的对话样本),这种现象意味着人类进行共情对话时,需要推断更多的外部知识。
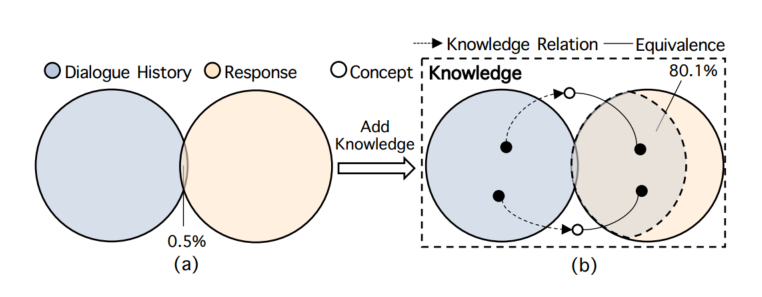 图2
图2 - 相比之下,如果将外部知识注入系统中,我们观察到,对于大多数对话样本(80.1%)聊天机器人可以直接从对话历史获取有效提示。如图二所示。
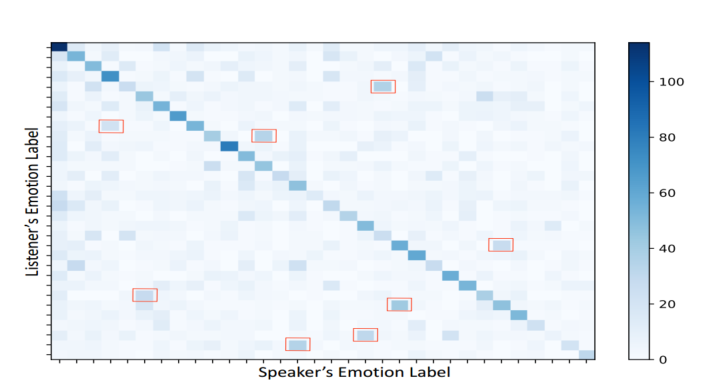
图3
- 图三表示从说话者到听众的情感转换。在图3中,较暗的对角线网格显示听众倾向于反映对话者的情感以建立融洽关系。除了对角线方向之外,(红色框中)还存在一些复杂的情感转换模式,因此,对对话者之间的情感依赖进行建模至关重要。
为此,我们提出了一种知识感知的情感对话生成方法(KEMP),它由三部分组成:情感上下文图、情感上下文编码器和情感依赖解码器。
二、 方法概览
作者提出了一个名为 KEMP (Knowledge-aware EMPathetic dialogue generation) 的方法,旨在通过外部知识"架起桥梁"来增强情感感知和表达。给定对话历史 D D D,目标是生成一个具有共情性的文本序列回复 Y = { y 1 , y 2 , ... , y m } Y = \{y_1, y_2, \dots, y_m\} Y={y1,y2,...,ym}。
核心思路:将外部知识(常识知识库 ConceptNet 和情感词典 NRC VAD)引入模型,构建知识增强的情感上下文图,并从中提取情感信号来引导回复生成 。
模型结构:主要由三个核心组件组成:
-
情感上下文图 (Emotional Context Graph):整合对话历史与外部知识 。
-
情感上下文编码器 (Emotional Context Encoder):学习图表示并感知情感信号 。
-
情感依赖解码器 (Emotion-dependency Decoder) :基于情感依赖性生成回复 。
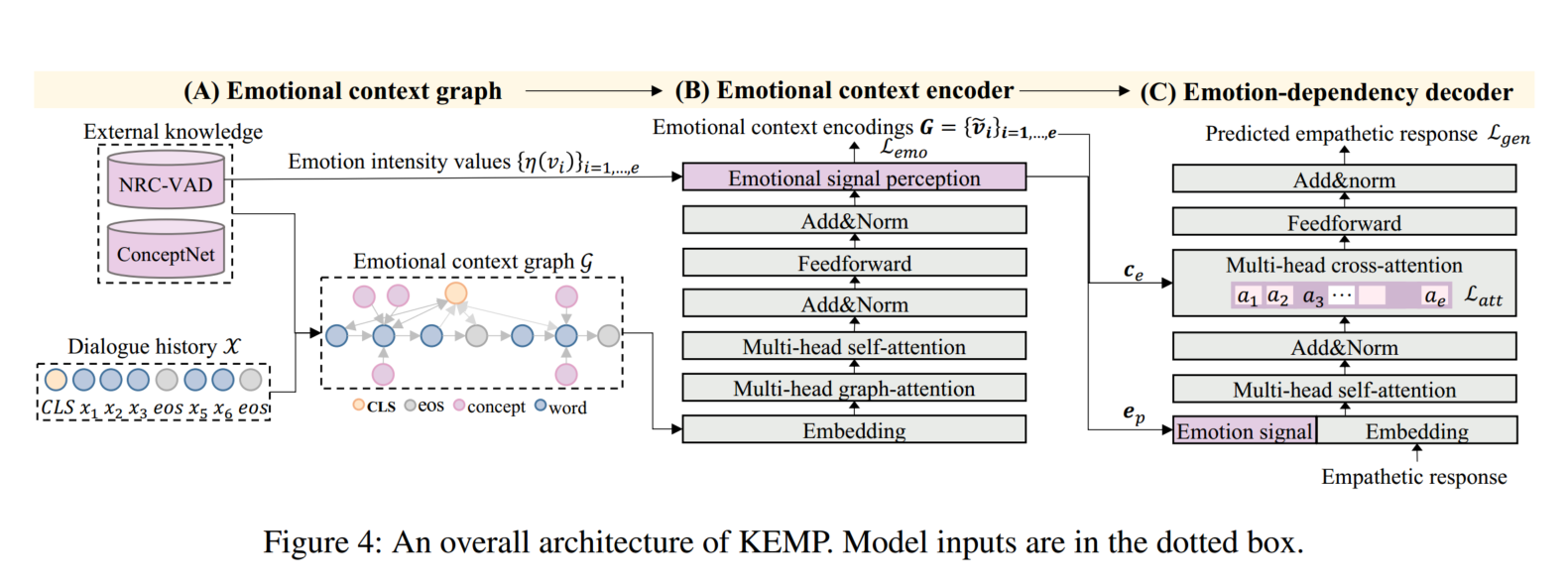
KEMP的总体架构如上图所示,情感上下文图 (Emotional Context Graph)、情感上下文编码器 (Emotional Context Encoder)、情感依赖解码器 (Emotion-dependency Decoder)分别对应图中的(A)、(B)、(C)阶段。
给出具有M句话的对话历史,即 D = X 1 , . . . , X M D = X_1, ... , X_M D=X1,...,XM作为输入,其中第i句话 X i = x 0 i , . . . , x m i i Xi = {x}\^i_0 , ... , {x}\^i_{m_i} Xi=x0i,...,xmii是一个 m i m_i mi字的序列。
在阶段(A)中,我们利用外部知识将对话历史D丰富到情感上下文图G中。
在阶段(B)中,基于来自G的嵌入和情感强度值来提取D的情感信号 e p e_p ep。
阶段(C)包含一个情感交叉注意机制,给定 e p e_p ep和G,利用该机制选择性地学习情感依赖。
最后,生成具有适当情感和信息内容的共情回应 Y = y 1 , . . . , y n Y = y_1, ... , y_n Y=y1,...,yn。
三、 方案详情
3.1 情感上下文图构建 (Emotional Context Graph)
该模块旨在通过常识知识和情感词典,将碎片化的对话历史转变为结构化的语义知识图。
-
输入 (Input):
- 对话历史 D = X 1 , X 2 , . . . , X M D = X_1, X_2, ..., X_M D=X1,X2,...,XM( M M M 轮对话内容)。
- 外部知识库:ConceptNet (常识) 和 NRC_VAD (情感词典)。
-
输出 (Output):
- 情感上下文图 G G G(包含节点特征和邻接矩阵 A A A)。
-
实现流程:
该模块将对话历史扁平化为长单词序列,在标记句的开头插入一个CLS标记,即 X = C L S ; x 1 , x 2 , . . . , x m X = CLS; x_1, x_2, ..., x_m X=CLS;x1,x2,...,xm。
- 知识获取 (Knowledge Acquisition): 提取对话中的非停用词作为关键词,在 ConceptNet 中检索一阶关联概念。
- 知识精炼 (Knowledge Refinement): * 过滤低置信度元组。
- 使用 NRC_VAD 计算候选概念的情感强度值 η \eta η。
- 选取情感强度最高的 K ′ K' K′ 个概念作为扩展节点。
- 异构图构建: 定义三种关系边:
- 时间边 (Temporal Edges): 连接对话中相邻的词。
- 情感边 (Emotional Edges): 连接词汇与其检索到的常识概念、情感概念节点。
- 全局边 (Global Edges): 引入
[CLS]节点连接所有其他节点,获取全局语义。
词汇 x ∈ X x \in X x∈X和它的情感概念构成了图谱 G \mathcal{G} G中的顶点V。
3.2 情感上下文编码器 (Emotional Context Encoder)
该模块负责在图上进行特征流动,并预测当前对话的情感标签。
- 输入 (Input):
- 构建好的图 G G G 及对应的节点初始嵌入(Embedding)。
- 输出 (Output):
- 图节点的高维表示 v ~ i \tilde{v}_i v~i。
- 预测的情感类别分布 P e P_e Pe 和情感信号特征 c e c_e ce。
- 实现流程:
- 节点初始化: 融合词向量、位置向量和状态向量(State Embedding,用于标识该节点是原始对话词还是外部知识)。
- 图注意力编码 (GAT): 使用多头图注意力机制,让节点根据邻居节点的关联度更新自身特征。
- Transformer 层: 进一步通过全连接层和自注意力层捕捉长距离依赖。
- 情感感知 (Emotional Signal Perception): * 根据节点的情感强度 η \eta η 进行加权池化,提取出情感信号 c e c_e ce。
通过线性分类器预测回复应具备的情感(如:欣慰、悲伤等)。
3.2.1 节点初始化环节
h i ( 0 ) = E w o r d ( v i ) + E p o s ( i ) + E s t a t e ( s i ) h_i^{(0)} = E_{word}(v_i) + E_{pos}(i) + E_{state}(s_i) hi(0)=Eword(vi)+Epos(i)+Estate(si)
其中:
E w o r d E_{word} Eword : 预训练或随机初始化的词嵌入。
E p o s E_{pos} Epos : 捕捉词序信息,对于外部知识节点,通常使用其连接的对话词的位置。
E s t a t e E_{state} Estate (状态向量): 关键创新点。模型学习两个可学习的向量:一个代表"对话上下文节点",一个代表"外部常识节点"。这让模型能区分哪些信息是用户亲口说的,哪些是系统检索出来的补充知识。
3.2.2 图注意力编码(GAT)
利用邻接矩阵 A A A 在图上进行信息传递。
计算关联度 ( α i j \alpha_{ij} αij): 节点 i i i 与其邻居 j j j 计算注意力分数,衡量邻居对当前节点的重要性。
多头聚合: 论文中给出的形式化表达如下:
v ^ i = v i + ∥ n = 1 H ∑ j ∈ A i α i j n W v n v j \hat{v}{i}=v_i + \left\Vert{n=1}^{H}\sum_{j\in\mathcal{A}{i}}\alpha{ij}^{n}W_{v}^{n}v_{j}\right. v^i=vi+ n=1Hj∈Ai∑αijnWvnvj
α i j n = a n ( v i , v j ) \alpha_{ij}^{n} = a^{n}(v_{i},v_{j}) αijn=an(vi,vj)
关键符号及其在论文中的定义:
-
残差连接 (Residual Connection):公式开头的 v i + ... v_i + \dots vi+... 表明这是一个残差结构 。模型将聚合后的邻居信息叠加在原始节点特征上,这有助于保留原始对话的语义,防止被外部知识过度冲淡。
-
多头拼接 ( ∥ n = 1 H \Vert_{n=1}^{H} ∥n=1H):符号 ∥ \Vert ∥ 代表将 H H H 个注意力头的结果进行拼接 (Concatenation) 。
-
注意力权重 α i j n \alpha_{ij}^n αijn :权重是通过节点 i i i (Query) 和节点 j j j (Key) 的线性变换计算得到的 :
a n ( q i , k j ) = exp ( ( W q n q i ) ⊤ W k n k j ) ∑ z ∈ A i exp ( ( W q n q i ) ⊤ W k n k z ) a^{n}(q_{i},k_{j})=\frac{\exp((W_{q}^{n}q_{i})^{\top}W_{k}^{n}k_{j})}{\sum_{z\in\mathcal{A}{i}}\exp((W{q}^{n}q_{i})^{\top}W_{k}^{n}k_{z})} an(qi,kj)=∑z∈Aiexp((Wqnqi)⊤Wknkz)exp((Wqnqi)⊤Wknkj)
- 线性变换 W v n W_v^n Wvn:这是针对 Value (数值) 的线性映射矩阵 。
3.2.3 Transformer 层
虽然 GAT 捕捉了局部邻域信息,但需要 Transformer 来进行全局建模。
输入: GAT 处理后的节点序列。
操作:
- Self-Attention: 节点不再受图边限制,而是全连接地观察图中所有节点。
- Feed-Forward: 逐位置的前馈网络进行非线性变换。
- LayerNorm & Residual: 保证深层网络训练的稳定性。
输出: 最终节点表示 V ~ = { v ~ 1 , v ~ 2 , . . . , v ~ N } \tilde{V} = \{\tilde{v}_1, \tilde{v}_2, ..., \tilde{v}_N\} V~={v~1,v~2,...,v~N}。
3.2.4 情感感知
这是 KEMP 模型预测"该用什么情绪回话"的关键步骤。
c e c_e ce 被称为 情感信号表示 (Emotional Signal Representation) ,它是模型提炼出的核心情感特征,直接决定了后续生成回复时的情感基调 。
c e = ∑ i = 1 e exp ( η i ) ∑ j = 1 e exp ( η j ) v ~ i c_{e}=\sum_{i=1}^{e}\frac{\exp(\eta_{i})}{\sum_{j=1}^{e}\exp(\eta_{j})}\tilde{v}_{i} ce=i=1∑e∑j=1eexp(ηj)exp(ηi)v~i
- 利用 NRC_VAD 提供的先验情感强度 η i \eta_i ηi 作为权重。
- 强度值越大的节点(如"痛苦"、"狂喜"),在特征向量 c e c_e ce 中占的比重越大。
e p e_p ep 是 情感概率向量 (Emotion Probability Vector) 。它是模型对当前对话历史所隐含情感的初步判断,并作为生成回复时的核心指导信号。 e p e_p ep 是 c e c_e ce 通过一个线性层映射得到:
e p = W e c e e_{p} = W_{e}c_{e} ep=Wece
其中 W e W_e We 是可学习的权重矩阵, q q q 是情感类别的数量。
3.3 情感依赖解码器 (Emotion-dependency Decoder)
该模块利用编码阶段捕获的信息,生成具有共情力的文本回复。
- 输入 (Input):
- 编码器的节点表示 v ~ i \tilde{v}_i v~i。
- 情感信号 c e c_e ce 及预测的情感向量 e p e_p ep。
- 输出 (Output):
- 回复序列 Y = y 1 , y 2 , . . . , y T Y = y_1, y_2, ..., y_T Y=y1,y2,...,yT。
- 实现流程:
-
情感初始化: 将预测的情感概率向量 e p e_p ep 作为解码器的起始状态输入(即首个 Hidden State),确保回复基调符合预测情感。
-
情感交叉注意力 (Emotional Cross-attention): * 计算解码器当前状态与图节点之间的注意力分。将上下文向量 g s g_s gs 与情感信号 c e c_e ce 动态融合,增强共情词的生成概率。
-
情感注意力损失 (L_att): 这是一个辅助任务。强制模型在解码时,注意力分布应与节点的情感强度 η \eta η 保持一致(即关注那些情感强烈的词)。
-
生成与复制: 使用 Pointer Generator 机制,模型既可以从词表中选择词,也可以直接从情感图中复制常识词汇到回复中。
-
联合损失函数 模型通过以下加权损失进行端到端训练:
L = γ 1 L g e n + γ 2 L e m o + γ 3 L a t t L = \gamma_1 L_{gen} + \gamma_2 L_{emo} + \gamma_3 L_{att} L=γ1Lgen+γ2Lemo+γ3Latt其中,L g e n L_{gen} Lgen 是传统的生成负对数似然损失。L e m o L_{emo} Lemo 是情感分类的交叉熵损失。 L a t t L_{att} Latt 是情感注意力分布的约束损失。
-
四、 优缺点评价
(1)优点
突破性地引入外部知识:这是首个尝试利用外部常识和情感知识库来增强共情对话生成的工作,显著提升了模型对隐式情绪的理解能力 。
双重情感引导:通过显式的情感类别预测和隐式的情感强度注意力,双管齐下地引导回复生成,使得回复既相关又具共情性。
可解释性增强:通过可视化注意力权重,可以观察到模型确实在关注图中具有情感意义的关键词(如"fight", "health"),而非仅依赖停用词 。
性能提升:在 EMPATHETICDIALOGUES 数据集上,其情感预测准确度、多样性(Distinct-1/2)和人类评估指标均优于当时的 SOTA 基线(如 EmpDG, MIME) 。
(2) 局限性
知识引入量存在阈值 :实验表明,引入过多的外部概念反而会导致情感预测准确率下降(可能引入了噪声),这说明模型对大规模知识的筛选和过滤机制仍有改进空间 。
推理延迟 :由于引入了复杂的图构建和检索过程,相比于纯端到端的 Transformer 模型,其计算开销和推理延迟可能会增加。
对词典的依赖性:模型的性能高度依赖于 NRC VAD 词典的覆盖范围。如果对话词汇不在词典中,情感强度会被设为 0,这可能限制其在俚语或新词较多的场景下的表现。