一张图看懂私有模型训练闭环:数据→训练→评测→上线→监控→迭代(你缺的不是训练,是交付)
-
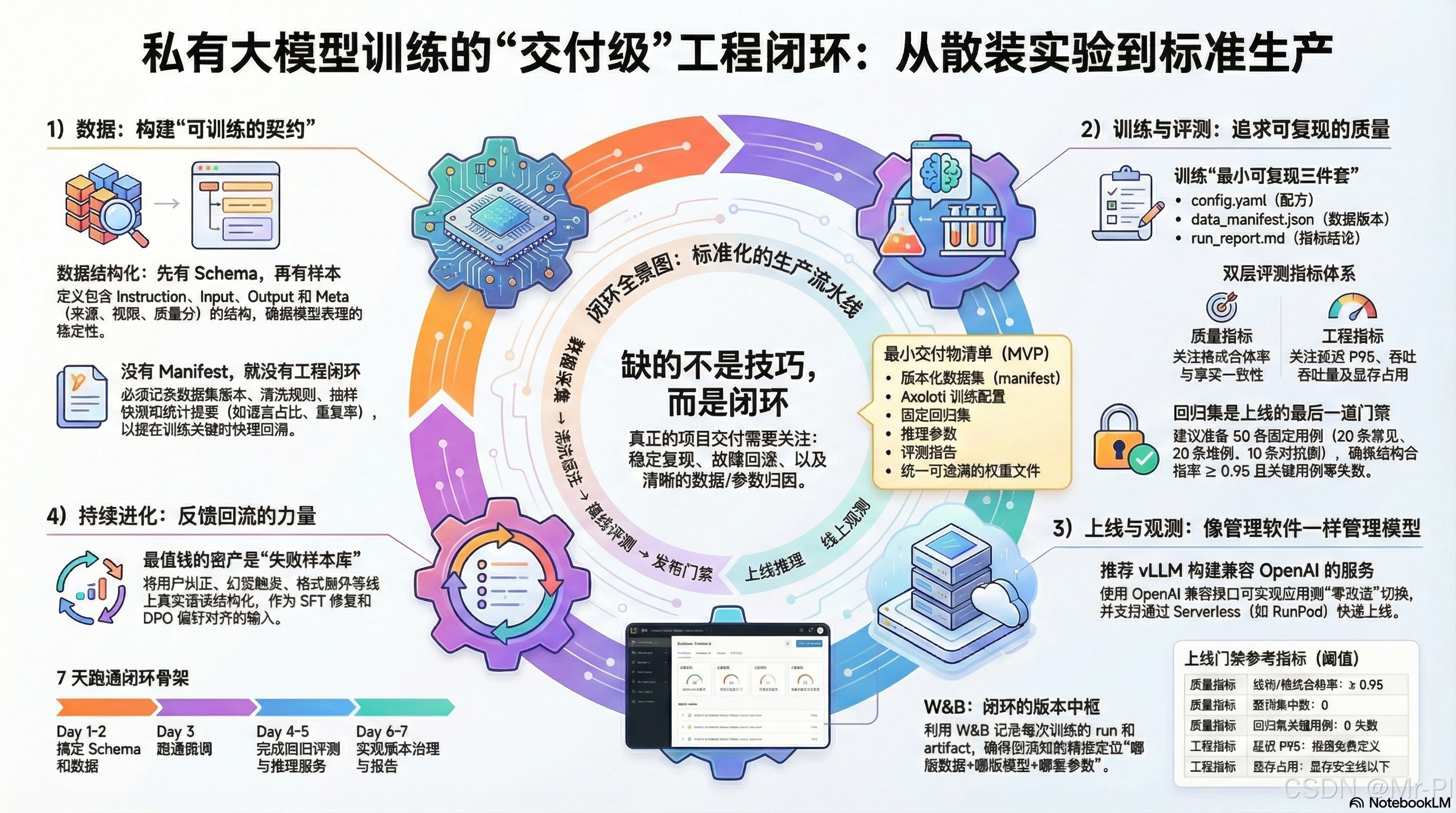
- 01|为什么"会训练"不等于"能交付"?(闭环缺口清单)
- [02|你只缺这一张图(闭环全景 Mermaid)](#02|你只缺这一张图(闭环全景 Mermaid))
- [03|训练范式怎么选?(SFT / LoRA / QLoRA / DPO / 全参边界)](#03|训练范式怎么选?(SFT / LoRA / QLoRA / DPO / 全参边界))
-
- [✅ SFT(Supervised Fine-Tuning)](#✅ SFT(Supervised Fine-Tuning))
- [✅ LoRA(低成本增量)](#✅ LoRA(低成本增量))
- [✅ QLoRA(更低显存门槛)](#✅ QLoRA(更低显存门槛))
- [✅ DPO(偏好对齐)](#✅ DPO(偏好对齐))
- [✅ 全参(Full Fine-tune)](#✅ 全参(Full Fine-tune))
- 04|你将得到什么?(这套专栏的"工程化三件套")
-
- [① 模板仓库结构(Repo Skeleton)](#① 模板仓库结构(Repo Skeleton))
- [② 可复现脚本(Repro Scripts)](#② 可复现脚本(Repro Scripts))
- [③ W&B 报告规范(Run / Config / Artifact / Report)](#③ W&B 报告规范(Run / Config / Artifact / Report))
- [05|交付物 1:Repo 目录树(直接复制当你的项目骨架)](#05|交付物 1:Repo 目录树(直接复制当你的项目骨架))
01|为什么"会训练"不等于"能交付"?(闭环缺口清单)
很多人卡在这几个坑:
- ❌ 数据不版本化:今天训得好,明天复现不了;上线后效果掉了也不知道是哪版数据的问题
- ❌ 训练只看 loss:看起来收敛了,但实际任务格式崩、幻觉、越权照样有
- ❌ 没有回归评测集:上线就是赌博;更新一次模型就"惊喜/惊吓"
- ❌ 推理服务不可替换:接口不兼容、参数散落,应用侧接入痛苦
- ❌ 无监控/无追踪:线上到底慢在哪、贵在哪、坏在哪,全靠猜
- ❌ 不能回滚:出了事故只能硬扛,越修越乱
一句话:你缺的是"工程闭环",不是"更多调参秘籍"。
02|你只缺这一张图(闭环全景 Mermaid)
建议:把它放在专栏置顶、仓库 README 第一屏、视频开篇第一张。
数据采集
Docs/QA/日志/反馈
清洗&标注
schema/去重/合规
数据版本化
manifest+snapshot
训练
SFT/LoRA/QLoRA/DPO
离线评测
指标+回归集
发布门禁
阈值不过不准上线
上线推理 vLLM OpenAI兼容
线上可观测
日志/采样/成本
反馈回流
失败样本库/偏好对
为什么我强调 vLLM 的 OpenAI 兼容?
因为它直接把你的推理层做成"像 OpenAI 一样能被调用"的 HTTP 服务,现有应用迁移成本极低。(vLLM)
为什么我强调 RunPod Serverless?
因为它让你不必管理服务器,按调用付费,把"上线"从大工程变成"可复制步骤"。(docs.runpod.io)
03|训练范式怎么选?(SFT / LoRA / QLoRA / DPO / 全参边界)
别把"训练方法"当信仰。按交付目标选:
✅ SFT(Supervised Fine-Tuning)
- 适合:格式稳定 、任务学会 、先跑通闭环
- 典型交付:结构化输出、领域 QA、摘要/抽取/改写
✅ LoRA(低成本增量)
- 适合:在不动底座的前提下快速注入能力/风格
- 典型交付:一套 LoRA 对应一个产品线/一个写作口径/一个风格锁
✅ QLoRA(更低显存门槛)
-
适合:单卡/低 VRAM 也能训 7B/13B 甚至更大
-
你要的不是"能训",而是"训得稳"------工程化要有固定配置与回归门禁
(Axolotl 支持 LoRA/QLoRA/DPO 等完整训练谱系,并强调"用一份 YAML 复用整个管线"。(GitHub))
✅ DPO(偏好对齐)
- 适合:去 AI 味 、更克制 、更符合你的口径/合规约束
- 关键输入:chosen/rejected 的偏好对(来自线上反馈回流更值钱)
✅ 全参(Full Fine-tune)
- 适合:数据充足、预算充足、需要大幅改造底座能力
- 风险:成本高、回归风险大、上线门禁要求更严格
04|你将得到什么?(这套专栏的"工程化三件套")
只要你按这三件套做,训练项目就从"玄学作坊"变成"可交付工程"。
① 模板仓库结构(Repo Skeleton)
- 把"数据/训练/评测/部署/报告/版本"全部放到可追溯的位置
- 每次迭代只要改一处,其他都能复现
② 可复现脚本(Repro Scripts)
- 同一份数据、同一份配置、同一份环境 → 结果可复跑
- 任何人拉仓库都能复现(包括未来的你)
③ W&B 报告规范(Run / Config / Artifact / Report)
W&B 的 Track + Artifacts 能把"实验过程、配置、模型产物、数据版本"串成一条可追溯链路:能对比、能回滚、能复盘。(Weights & Biases 文档)
05|交付物 1:Repo 目录树(直接复制当你的项目骨架)
private-model-loop/
├── data/
│ ├── raw/ # 原始数据(不可改,只追加)
│ ├── processed/ # 清洗后的训练数据(可复现)
│ ├── manifests/ # data_manifest.json(版本号/统计/快照)
│ └── regression/ # 回归评测集(固定用例)
├── train/
│ ├── axolotl/ # Axolotl configs(SFT/QLoRA/DPO)
│ ├── scripts/ # 一键训练/导出/合并
│ └── outputs/ # checkpoints / lora / merged
├── eval/
│ ├── metrics/ # 质量指标(格式/禁词/引用/一致性)
│ ├── reports/ # 对比报告(markdown/html)
│ └── judge/ # 可选:LLM-as-judge 配置
├── deploy/
│ ├── vllm/ # vLLM serve / OpenAI compatible
│ ├── runpod/ # Serverless handler / endpoint config
│ └── gateways/ # 鉴权/限流/日志字段规范
├── observability/
│ ├── wandb/ # run 命名规范 / artifact 规范 / report 模板
│ └── tracing/ # request_id / prompt_id / model_version
└── docs/
├── architecture.md # "一张图" + 关键决策记录
└── roadmap_48.md # 48 篇路线表补一句关键点:Axolotl 的强项就是一份 YAML 复用预处理、训练、评测、量化、推理等阶段 (它在项目介绍里明确这么定位)。(GitHub)