手把手搭建 Zookeeper3.4.10三节点高可用集群(含 myid 配置与选举机制详解)
文章目录
- [手把手搭建 Zookeeper3.4.10三节点高可用集群(含 myid 配置与选举机制详解)](#手把手搭建 Zookeeper3.4.10三节点高可用集群(含 myid 配置与选举机制详解))
-
- [📘 Zookeeper 简介前言](#📘 Zookeeper 简介前言)
-
- [🐘 什么是 Apache Zookeeper?](#🐘 什么是 Apache Zookeeper?)
- [2.1 Zookeeper 安装部署](#2.1 Zookeeper 安装部署)
-
- [2.1.1 准备工作](#2.1.1 准备工作)
-
- [(1)上传 Zookeeper 安装包](#(1)上传 Zookeeper 安装包)
- [(2)解压 Zookeeper 安装包](#(2)解压 Zookeeper 安装包)
- (3)配置环境变量
- [2.1.2 相关配置修改](#2.1.2 相关配置修改)
-
- [(1)修改 `zoo.cfg` 配置文件](#(1)修改
zoo.cfg配置文件) - [(2)创建 `myid` 文件](#(2)创建
myid文件) - (3)分发配置到其他节点
- [(4)修改其他节点的 `myid` 文件](#(4)修改其他节点的
myid文件)
- [(1)修改 `zoo.cfg` 配置文件](#(1)修改
- [2.1.3 Zookeeper 服务的启动与关闭](#2.1.3 Zookeeper 服务的启动与关闭)
- [2.1.4 Zookeeper 选举机制](#2.1.4 Zookeeper 选举机制)
- [手把手搭建 Zookeeper三节点高可用集群教程](#手把手搭建 Zookeeper三节点高可用集群教程)
📘 Zookeeper 简介前言
🐘 什么是 Apache Zookeeper?
Apache Zookeeper 是一个开源的分布式协调服务,由 Apache Hadoop 生态衍生而来,最初由 Yahoo! 开发,现已成为构建高可用、强一致性分布式系统的核心组件之一。
在分布式环境中,多个服务实例需要协同工作------例如:谁是主节点?配置如何统一?任务如何分配?节点宕机如何感知?这些问题统称为"分布式协调"。而 Zookeeper 正是为解决这些难题而生。
它提供了一套简单但强大的原语(如临时节点、监听机制、原子操作等),通过类似文件系统的树形数据模型(ZNode)和 ZAB(ZooKeeper Atomic Broadcast)一致性协议,确保集群中所有客户端看到一致的数据视图。
📌 典型应用场景:
- Hadoop HDFS 的 NameNode 高可用(HA)
- HBase 的 Master 选举与 RegionServer 注册
- Kafka 的 Broker 注册、Topic 元数据管理
- 分布式锁、配置中心、服务发现等通用协调需求
Zookeeper 本身不存储业务数据 ,而是作为"分布式系统的神经中枢",帮助上层应用实现可靠协作。
在本实验中,我们将基于三台服务器(master、slave1、slave2)部署 Zookeeper 3.4.10 集群,并验证其 Leader-Follower 架构与故障容错能力,为后续搭建 HBase、Kafka 等服务奠定基础。
2.1 Zookeeper 安装部署
Zookeeper 的安装配置分为两种模式:
- 本地模式:仅包含一台服务器,适用于开发测试。
- 集群模式 :包含多台服务器(推荐使用奇数台,如 3、5、7 台),具备高可用性和容错能力。
本文选择集群模式 进行部署,在
master、slave1和slave2三台服务器上均部署 Zookeeper。配置策略:先在
master节点完成全部配置,再将配置文件分发至其他节点。
2.1.1 准备工作
(1)上传 Zookeeper 安装包
使用 Xftp 连接 master 服务器,将 zookeeper-3.4.10.tar.gz 安装包上传至 /opt/software 目录下。
(2)解压 Zookeeper 安装包
通过 Xshell 登录 master,执行以下命令:
bash
[root@master ~]# cd /opt/software/
[root@master software]# tar -zvxf zookeeper-3.4.10.tar.gz -C /opt/module/
[root@master software]# cd ../module/
[root@master module]# ls
hadoop java zookeeper-3.4.10
[root@master module]# mv zookeeper-3.4.10/ zookeeper
[root@master module]# ls
hadoop java zookeeper(3)配置环境变量
编辑 /etc/profile 文件:
bash
[root@master module]# vi /etc/profile
在文件末尾添加以下内容:
bash
# ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/opt/module/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin保存后执行以下命令使环境变量生效:
bash
[root@master module]# source /etc/profile
2.1.2 相关配置修改
(1)修改 zoo.cfg 配置文件
进入 Zookeeper 安装目录的 conf 子目录,复制模板文件:
bash
[root@master module]# cd zookeeper/
[root@master zookeeper]# cd conf
[root@master conf]# cp zoo_sample.cfg zoo.cfg
[root@master conf]# vi zoo.cfg
修改以下内容:
-
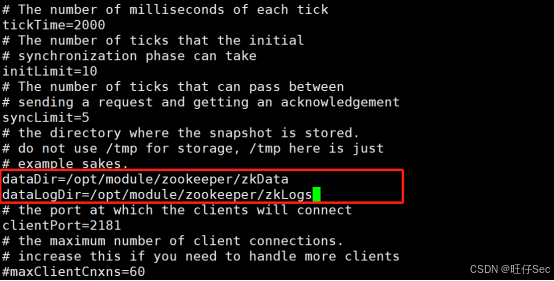
设置数据目录(避免使用系统临时目录):
inidataDir=/opt/module/zookeeper/zkData -
新增日志目录(可选但推荐):
inidataLogDir=/opt/module/zookeeper/zkLog
在文件末尾 添加集群服务器列表(注意:主机名需提前配置好 DNS 或 /etc/hosts):
ini
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
配置项说明:
tickTime=2000:Zookeeper 服务器与客户端之间的心跳间隔(单位:毫秒)。initLimit=10:Follower 与 Leader 初始连接时允许的最大心跳数(即 10 × 2000 = 20 秒)。syncLimit=5:Follower 与 Leader 同步通信超时阈值(5 × 2000 = 10 秒)。clientPort=2181:客户端连接端口,默认不变。dataDir:存储内存数据库快照的位置,切勿使用/tmp(Linux 可能自动清理)。
(2)创建 myid 文件
根据 zoo.cfg 中的 dataDir 路径,创建对应目录:
bash
[root@master conf]# cd ..
[root@master zookeeper]# mkdir zkData
[root@master zookeeper]# mkdir zkLog进入 zkData 目录,创建 myid 文件:
bash
[root@master zookeeper]# cd zkData
[root@master zkData]# vi myid在文件中写入当前节点对应的服务器编号(无空格、无空行):
1✅
master对应server.1,因此myid内容为1。
(3)分发配置到其他节点
由于已配置 SSH 免密登录,可使用 scp 命令将整个 zookeeper 目录和环境变量文件分发到 slave1 和 slave2:
bash
# 分发 Zookeeper 安装目录
[root@master ~]# scp -r /opt/module/zookeeper root@slave1:/opt/module/
[root@master ~]# scp -r /opt/module/zookeeper root@slave2:/opt/module/
# 分发环境变量(可选,或手动在各节点添加)
[root@master ~]# scp /etc/profile root@slave1:/etc/
[root@master ~]# scp /etc/profile root@slave2:/etc/


⚠️ 分发后需在
slave1和slave2上分别执行source /etc/profile使环境变量生效。
(4)修改其他节点的 myid 文件
-
登录
slave1,将myid内容改为2:bash[root@slave1 ~]# echo 2 > /opt/module/zookeeper/zkData/myid



-
登录
slave2,将myid内容改为3:bash[root@slave2 ~]# echo 3 > /opt/module/zookeeper/zkData/myid



🔍 确保每个节点的
myid与zoo.cfg中server.x的x严格对应。
2.1.3 Zookeeper 服务的启动与关闭
(1)启动服务
在每台服务器上分别执行:
bash
[root@master ~]# zkServer.sh start
[root@slave1 ~]# zkServer.sh start
[root@slave2 ~]# zkServer.sh start


(2)查看服务状态
bash
[root@master ~]# zkServer.sh status正常情况下,三台节点中会有一台显示
Mode: leader,其余两台显示Mode: follower。



(3)关闭服务
bash
[root@master ~]# zkServer.sh stop(其他节点同理)
2.1.4 Zookeeper 选举机制
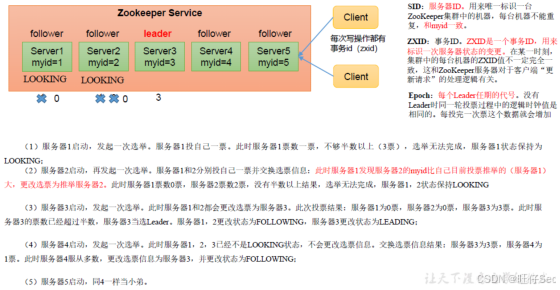
Zookeeper 集群通过 ZAB(Zookeeper Atomic Broadcast)协议 实现一致性与高可用,其选举机制分为两种场景:
(1)第一次启动(全新集群)
- 所有节点初始状态为
LOOKING。 - 通过投票选出
myid最大的节点作为 Leader(若网络分区,则需多数派达成一致)。 - 选举完成后,Leader 进入
LEADING状态,Follower 进入FOLLOWING状态。
(2)非第一次启动(已有数据)
- 若 Leader 宕机,剩余 Follower 重新发起选举。
- 优先选择 ZXID(事务 ID)最大 的节点作为新 Leader(保证数据最新)。
- 若 ZXID 相同,则比较
myid,选较大者。
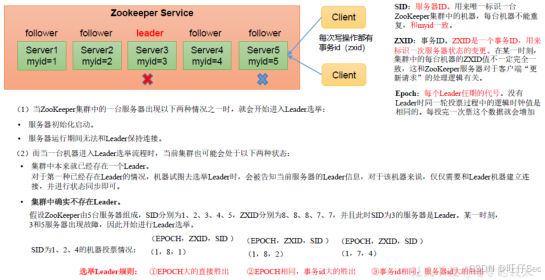
💡 Zookeeper 要求集群中超过半数节点存活才能提供服务(例如 3 节点最多容忍 1 台宕机)。
✅ 至此,Zookeeper 集群部署完成,可为 Hadoop、HBase、Kafka 等分布式系统提供协调服务。
手把手搭建 Zookeeper三节点高可用集群教程
大数据应用开发竞赛-03-手把手搭建 Zookeeper三节点高可用集群
希望大家也三连一下视频,你的支持是我创作的最大动力!