目录
[1 概念解释](#1 概念解释)
[2 Unet VS DCSAUnet 的【参数量 计算量】](#2 Unet VS DCSAUnet 的【参数量 计算量】)
[3 深入分析DCSAUnet](#3 深入分析DCSAUnet)
引:部署模型时兼顾速度和精度,这需要根据使用场景中数据对象的特点设计(选择)模型。体现模型特点的两个主要参数就是Params(参数量) 和 **FLOPs(计算量)。**本博客借以 Unet和DCSAUnet为例,回答两个问题:
为什么unet.pth ≈100MB,DCSAUnet.pth≈10MB?
为什么修改模型输入的input_size后DCSAUnet.pth大小没有改变,但是速度却成倍提高?
1 概念解释
| 指标 | 代表什么 | 影响什么 |
|---|---|---|
| 参数量 (Params) | 模型里有多少可学习权重 | 模型大小、显存占用 |
| 计算量 (FLOPs) | 前向传播要做多少次运算 | 运行速度 |
python
nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1,bias=False)# 3*3 卷积核参数量:
对于一个卷积核结构【in_channels, out_channels, kernel_size】的
以【3, 64, 3】的卷积核举例
参数量= 3 * 64 * 3 * 3。参数量的多少和输入图像尺寸无关,以此推到整个模型亦如此。
计算量:
由上面计算公式可知,计算量和输入尺寸强相关。
一句话总结:参数量决定"模型有多大",计算量决定"模型跑多慢"。
2 Unet VS DCSAUnet 的【参数量 计算量】
我们统一输入条件为:【input_size=512×512, in_channel=3, kernei_size=3*3 】
UNet Encoder Params & FLOPs:
| Stage | Output size | Conv结构 | Params | FLOPs |
|---|---|---|---|---|
| inc | 512×512 | 3→64→64 | 38K | 10.1G |
| down1 | 256×256 | 64→128→128 | 221K | 14.5G |
| down2 | 128×128 | 128→256→256 | 885K | 14.5G |
| down3 | 64×64 | 256→512→512 | 3.54M | 14.5G |
| down4 | 32×32 | 512→1024→1024 | 14.15M | 14.5G |
| total | ≈ 18.8M | 67.9 GFLOPs |
DCSAUnet Encoder Params & FLOPs
| Stage | Output size | Conv结构 | Params | FLOPs |
|---|---|---|---|---|
| enc1 | 512×512 | 3→32→32 | 9.2K | 2.5G |
| enc2 | 256×256 | 32→64→64 | 55K | 3.6G |
| enc3 | 128×128 | 64→128→128 | 221K | 3.6G |
| enc4 | 64×64 | 128→256→256 | 885K | 3.6G |
| enc5 | 32×32 | 256→512→512 | 3.54M | 3.6G |
| total | ≈ 4.7M | 16.9 GFLOPs |
以上两个表格对比了两模型不同block的参数量和计算量,核心的差异在于Unet存在大量的"对大channels数作卷积操作",比如下面这一个【1024×1024×3×3】卷积核就直接导致Unet多出10M+的参数量和 10G+ 的计算量。
| 模型 | 是否存在 1024×1024×3×3 |
|---|---|
| UNet | ✅ 有 |
| DCSAUnet | ❌ 没有 |
3 深入分析DCSAUnet
上面章节我们对比了两个模型的参数量和计算量,清楚的看到DCSAUnet模型在卷积核设计上的优势思路:不对长channels向量作卷积计算。这个操作能回答:为什么unet.pth ≈100MB,DCSAUnet.pth≈10MB? 其实也已经回答了:为什么修改模型输入的input_size后DCSAUnet.pth大小没有改变,但是速度却成倍提高?
下面我们详细分析一下DCSAUnet模型的设计,尝试额外回答:为什么DCSAUnet对小尺寸(64*64)的输入有效。
模型论文链接:https://arxiv.org/pdf/2202.00972v2
模型结构及其关键组件如下:
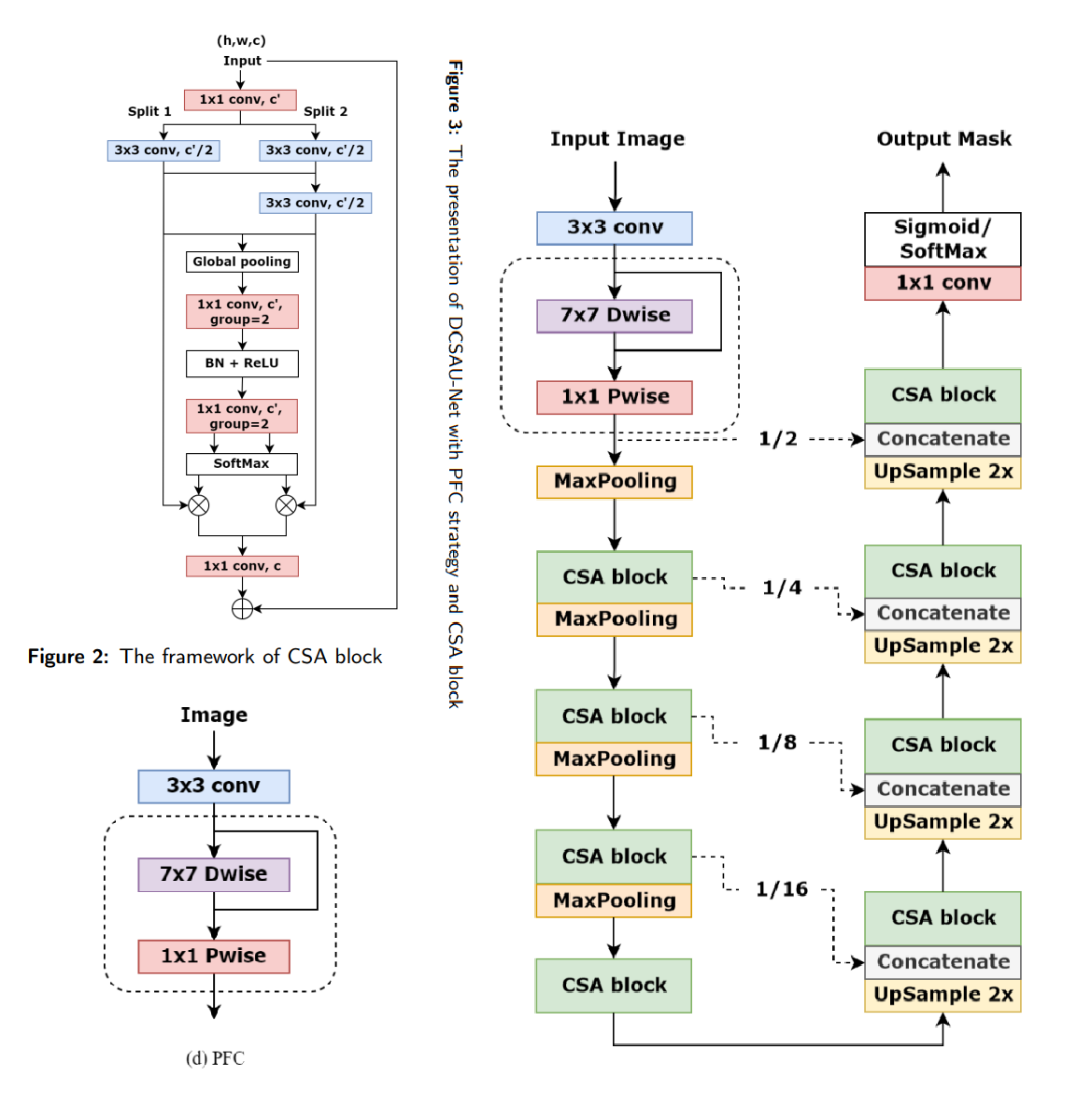 Fig 1. DCSAUnet模型
Fig 1. DCSAUnet模型
我们重点分析Encoder部分,该部分对输入图像的第一次卷积in_conv使用PFC模块:用多个卷积分支提取不同感受野的特征,然后融合。
python
输入 C_in
│
┌──────┼────────┐
│ │ │
1×1 3×3 5×5
│ │ │
└──────concat────┘
│
1×1
│
输出 64在主卷积block中,使用**轻量的多分支注意力卷积块 --**CAS 模块
python
input_tensor
| 特征分组(Split)(参考sufflenet)
| 卷积操作:先用 1×1 卷积做通道融合,再用 3×3 卷积提取局部特征
⬇ 通道注意力(Channel Attention)
残差连接(Residual Connection)Encoder部分最后的tensor_size = 1/16 * input_size,后续Decoder部分有unsample,所以对64*64input_size分割有效,但是基本无法继续缩小input_size。
end...