1.基本原理
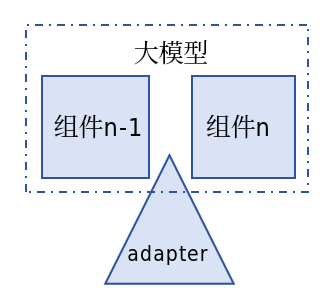
在预训练模型的特定位置(通常是注意层和全连接层之后)添加少量可训练参数,这些参数构成一个小型神经网络模块,如下图所示:
2.代码案例
2.1 定义adapter
python
# -*- coding:utf-8 -*-
import torch
import torch.nn as nn
from transformers import BertModel, BertTokenizer
from torch.utils.data import DataLoader, Dataset
class Adapter(nn.Module):
def __init__(self, input_dim, bottleneck_dim=64):
super(Adapter, self).__init__()
self.adapter_layer = nn.Sequential(
nn.Linear(input_dim, bottleneck_dim),
nn.ReLU(),
nn.Linear(bottleneck_dim, input_dim)
)
nn.init.normal_(self.adapter_layer[0].weight, std=1e-3)
nn.init.normal_(self.adapter_layer[2].weight, std=1e-3)
def forward(self, x):
return x + self.adapter_layer(x)2.2 在Bert特殊位置插入Adapter
python
class BertWithAdapter(nn.Module):
def __init__(self, model_name, num_classes=2):
super(BertWithAdapter, self).__init__()
self.bert = BertModel.from_pretrained(model_name)
for param in self.bert.parameters():
param.requires_grad = False
for i in range(len(self.bert.encoder.layer)):
# 注入 Adapter
self.bert.encoder.layer[i].attention.output.add_module("adapter", Adapter(768))
self.bert.encoder.layer[i].output.add_module("adapter", Adapter(768))
self._inject_forward_logic(self.bert.encoder.layer[i])
self.classifier = nn.Linear(768, num_classes)
def _inject_forward_logic(self, layer):
attn_out = layer.attention.output
ffn_out = layer.output
original_attn_forward = attn_out.forward
def new_attn_forward(hidden_states, input_tensor):
x = original_attn_forward(hidden_states, input_tensor)
return attn_out.adapter(x)
attn_out.forward = new_attn_forward
original_ffn_forward = ffn_out.forward
def new_ffn_forward(hidden_states, input_tensor):
x = original_ffn_forward(hidden_states, input_tensor)
return ffn_out.adapter(x)
ffn_out.forward = new_ffn_forward
def forward(self, input_ids, attention_mask, token_type_ids=None):
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids
)
pooled_output = outputs[1]
return self.classifier(pooled_output)2.3 准备数据
python
class SimpleDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_len=32):
self.encodings = tokenizer(texts, truncation=True, padding='max_length', max_length=max_len, return_tensors="pt")
self.labels = torch.tensor(labels)
def __getitem__(self, idx):
item = {key: val[idx] for key, val in self.encodings.items()}
item['labels'] = self.labels[idx]
return item
def __len__(self):
return len(self.labels)2.4 Bert模型微调
python
def train(model_name):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"正在运行设备: {device}")
texts = ["这个电影真好看", "太难看了,浪费时间", "导演很有才华", "剧情一塌糊涂"]
labels = [1, 0, 1, 0]
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertWithAdapter(model_name).to(device)
dataset = SimpleDataset(texts, labels, tokenizer)
loader = DataLoader(dataset, batch_size=2, shuffle=True)
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss()
model.train()
print("开始训练...")
for epoch in range(5):
total_loss = 0
for batch in loader:
optimizer.zero_grad()
input_ids = batch['input_ids'].to(device)
mask = batch['attention_mask'].to(device)
t_ids = batch['token_type_ids'].to(device) # 增加对 token_type_ids 的显式处理
targets = batch['labels'].to(device)
logits = model(input_ids, mask, t_ids)
loss = criterion(logits, targets)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {total_loss/len(loader):.4f}")
model.eval()
test_text = ["非常喜欢"]
test_enc = tokenizer(test_text, return_tensors="pt").to(device)
with torch.no_grad():
out = model(test_enc['input_ids'], test_enc['attention_mask'], test_enc.get('token_type_ids'))
pred = torch.argmax(out, dim=1)
print(f"测试结果: {'正面' if pred.item()==1 else '负面'}")
model_name = 'your_bert-base-chinese'
train(model_name)