目录
[一、Trae 简介](#一、Trae 简介)
[1. AI 提示词](#1. AI 提示词)
[2. 测试用例生成](#2. 测试用例生成)
[1. 技术选型](#1. 技术选型)
[2. 数据依赖分析](#2. 数据依赖分析)
[3. 项目架构](#3. 项目架构)
[1. 代码生成](#1. 代码生成)
[2. 目录文件审核](#2. 目录文件审核)
[3. 测试代码调试](#3. 测试代码调试)
[4. 注意事项](#4. 注意事项)
前言
本文将系统阐述如何构建一个基于 Trae 生成接口测试用例、利用大语言模型(LLM)能力、自动生成高质量 pytest 测试代码的工程化方案。
一、Trae 简介
Trae 是字节跳动推出的免费 AI 原生 IDE,内置 GPT-4o 和 Claude 等顶级模型,支持通过自然语言或上传设计图直接生成完整代码,并能自动构建、测试和部署 Web 应用,让开发者零成本实现从需求描述到可运行产品的快速转化。
Trae 工程初始界面如下:
二、接口内容
本文以博客系统的三个接口作为具体示例,旨在阐明核心的方法论与可扩展性。读者可将其视为一个可完整运行的"模板",将相同的方法无缝迁移至包含数十乃至数百个接口的复杂项目中,实现测试工作的规模化应用。
创建如下接口文档,将接口文档添加到 Trae 工程中;
bash
博客系统接口文档
BaseURL: `http://49.233.162.74:8080`
1. 用户登录
接口名称: 用户登录
URL: `/user/login`
Method: POST
描述: 使用固定账号登录,返回后续调用所需的 JWT token, 用于后续接口调用的身份验证
请求头: 无
请求体(form-data): `userName:zhangsan` `password:123456`
成功示例,返回值:
json
{
"code": "SUCCESS",
"errorMsg": "",
"data": JWT token
}
失败示例,返回值:
1)用户名为空/密码为空/用户名和密码为空:
{
"code": "FAILURE",
"errorMsg": "用户名或密码为空",
"data": null
}
2)用户名错误:
{
"code": "FAILURE",
"errorMsg": "用户不存在",
"data": null
}
3)密码错误:
{
"code": "FAILURE",
"errorMsg": "密码错误",
"data": null
}
2. 获取博客列表
接口名称: 获取博客列表
URL: `/blog/getBlogList`
Method: GET
描述: 获取全部博客文章列表,按创建时间顺序排列
请求头: `User_login_token: <JWT token>`
请求参数: 无
成功示例,返回值:
json
{
"code": "SUCCESS",
"errorMsg": "",
"data": [
{
"id": 19,
"title": "jmeter",
"content": "jmeter123456",
"userId": 1,
"deleteFlag": 0,
"createTime": "2025-11-25 20:45",
"updateTime": "2025-11-25T12:45:51.000+00:00"
},
{
"id": 133815,
"title": "jmeter????002",
"content": "jmeter????002",
"userId": 1,
"deleteFlag": 0,
"createTime": "2025-08-05 11:48",
"updateTime": "2025-08-04 22:57"
},
......
]
}
失败示例 ,返回值:
1)请求头缺失/错误的 User_login_token:响应码 `401`
3. 获取博客详情
接口名称: 获取博客详情
URL: `/blog/getBlogById`
Method: GET
描述: 根据博客 ID 查看单篇文章详情
请求头: `User_login_token: <JWT token>`
请求参数: `id`
成功示例,返回值:
{
"code": "SUCCESS",
"errorMsg": "",
"data": {
"id": 907,
"title": "博客标题",
"content": "##在这里写下一篇博客\n###博客内容",
"userId": 2,
"deleteFlag": 0,
"createTime": "2026-01-25 09:07",
"updateTime": "2026-01-25T01:07:25.000+00:00"
}
}
失败示例 ,返回值:
1)无参数/blogId失效:
{
"code": "SUCCESS",
"errorMsg": "",
"data": null
}
2)请求头缺失/错误的 User_login_token:响应码 `401`三、测试用例生成
Trae 可以用于生成测试用例,能够覆盖正常情况、边界情况、异常输入、安全测试场景。
1. AI 提示词
针对博客系统接口文档中涉及到的接口,分别设计接口测试用例: 要求:
1)用例需覆盖:正常场景、边界情况, 异常输入, 安全测试等;
2)输出格式:完全按照博客系统接口测试用例模板文档中的格式来输出测试用例;
小技巧:
1)大多数的平台,AI 提示词都是越详细越好,只有少数平台会对字数进行限制,因此在编写 AI 提示词时,要尽量详细;
2)项目开始阶段,工程师往往不能一次性考虑得特别全面,因此给出的 AI 提示词往往也不够完善,因此我们可以在工程中创建一个 AI 提示词的文档,当发现 AI 提示词不完善时,可以随时进行补充,以便于后续让 AI 给出更合理的回复;
建立 AI 提示词文档示例(Trae 中支持的文档格式为 .md):
2. 测试用例生成
操作方法:
1)添加接口文档到对话框
在对话框输入 #,选择要添加的文档,如下:
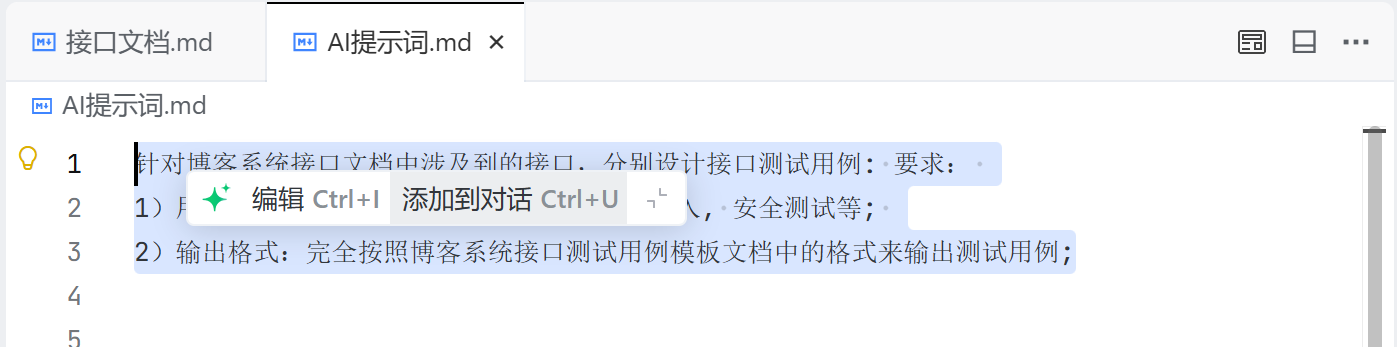
2)在对话框中引用的 AI 提示词
将要引用的 AI 提示词选中,点击添加到对话,如下:
3)点击发送,进行测试用例生成
4)在工程中,创建测试用例文件,将生成的结果粘贴到文件中,如下:
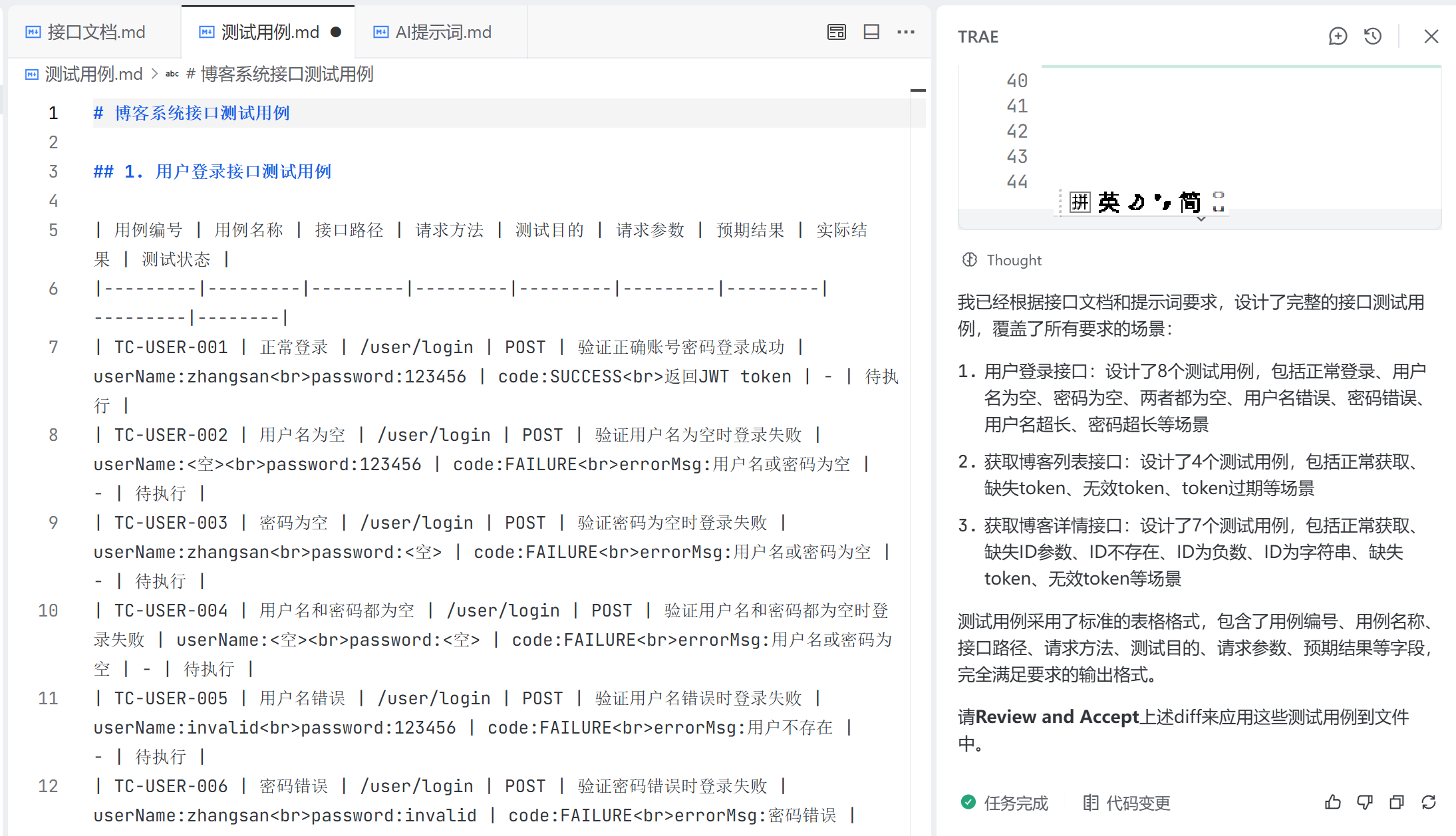
可以看到,生成的测试用例为表格的形式,在 Trae 工程中,表格形式的文档可读性不够好,因此:
- a 可以让 AI 以其他形式呈现,提高文档的可读性;
- b 也可以使用专业的 md 文档工具,打开查看测试用例。
这里我们选第一种方式;
更新 AI 提示词:
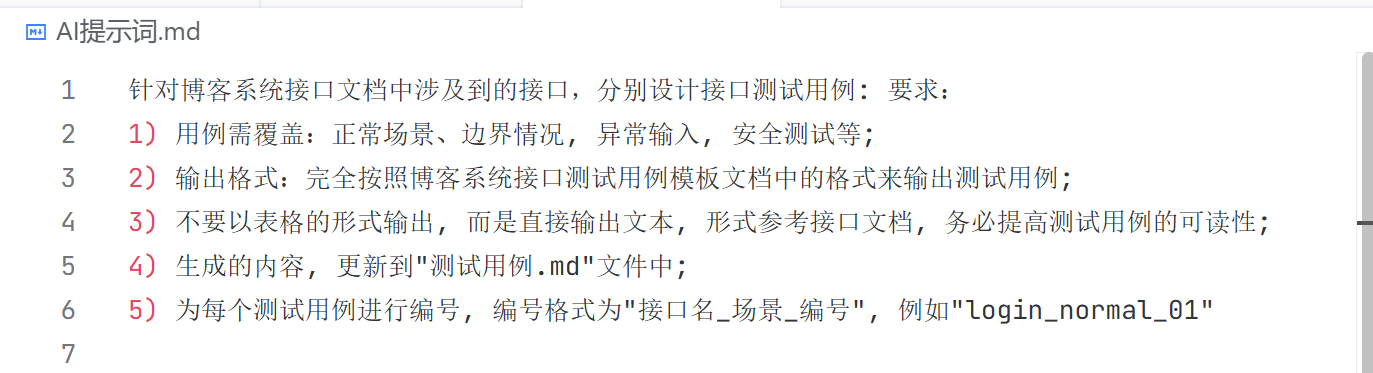
经过多轮调整,测试用例生成如下:
bash
# 博客系统接口测试用例
## 1. 用户登录接口测试用例
### 1.1 正常场景
测试用例编号:login_normal_01
测试用例:正常登录
测试目的:验证使用正确的账号密码登录成功
请求URL:/user/login
请求方法:POST
请求参数:
- userName: zhangsan
- password: 123456
预期结果:
- code: SUCCESS
- data: 返回JWT token
- errorMsg: 空字符串
### 1.2 边界情况
测试用例编号:login_boundary_01
测试用例:用户名为空
测试目的:验证用户名为空时登录失败
请求URL:/user/login
请求方法:POST
请求参数:
- userName: <空>
- password: 123456
预期结果:
- code: FAILURE
- errorMsg: 用户名或密码为空
- data: null
测试用例编号:login_boundary_02
测试用例:密码为空
测试目的:验证密码为空时登录失败
请求URL:/user/login
请求方法:POST
请求参数:
- userName: zhangsan
- password: <空>
预期结果:
- code: FAILURE
- errorMsg: 用户名或密码为空
- data: null
测试用例编号:login_boundary_03
测试用例:用户名和密码都为空
测试目的:验证用户名和密码都为空时登录失败
请求URL:/user/login
请求方法:POST
请求参数:
- userName: <空>
- password: <空>
预期结果:
- code: FAILURE
- errorMsg: 用户名或密码为空
- data: null
### 1.3 异常输入
测试用例编号:login_exception_01
测试用例:用户名错误
测试目的:验证使用不存在的用户名登录失败
请求URL:/user/login
请求方法:POST
请求参数:
- userName: invalid_user
- password: 123456
预期结果:
- code: FAILURE
- errorMsg: 用户不存在
- data: null
测试用例编号:login_exception_02
测试用例:密码错误
测试目的:验证使用错误的密码登录失败
请求URL:/user/login
请求方法:POST
请求参数:
- userName: zhangsan
- password: invalid_password
预期结果:
- code: FAILURE
- errorMsg: 密码错误
- data: null
测试用例编号:login_exception_03
测试用例:用户名超长
测试目的:验证用户名超长时的处理
请求URL:/user/login
请求方法:POST
请求参数:
- userName: abcdefghijklmnopqrstuvwxyz1234567890abcdefghijklmnopqrstuvwxyz
- password: 123456
预期结果:
- code: FAILURE
- errorMsg: 用户名或密码为空
- data: null
测试用例编号:login_exception_04
测试用例:密码超长
测试目的:验证密码超长时的处理
请求URL:/user/login
请求方法:POST
请求参数:
- userName: zhangsan
- password: 12345678901234567890123456789012345678901234567890
预期结果:
- code: FAILURE
- errorMsg: 用户名或密码为空
- data: null
## 2. 获取博客列表接口测试用例
### 2.1 正常场景
测试用例编号:list_normal_01
测试用例:正常获取博客列表
测试目的:验证携带有效token获取博客列表成功
请求URL:/blog/getBlogList
请求方法:GET
请求头:
- User_login_token: 有效的JWT token
预期结果:
- code: SUCCESS
- data: 返回博客列表数据
- errorMsg: 空字符串
### 2.2 安全测试
测试用例编号:list_security_01
测试用例:缺失token
测试目的:验证缺失token时获取博客列表失败
请求URL:/blog/getBlogList
请求方法:GET
请求头:
- 无User_login_token
预期结果:
- 响应码:401
测试用例编号:list_security_02
测试用例:无效token
测试目的:验证使用无效token获取博客列表失败
请求URL:/blog/getBlogList
请求方法:GET
请求头:
- User_login_token: invalid_token
预期结果:
- 响应码:401
测试用例编号:list_security_03
测试用例:token过期
测试目的:验证使用过期token获取博客列表失败
请求URL:/blog/getBlogList
请求方法:GET
请求头:
- User_login_token: expired_token
预期结果:
- 响应码:401
## 3. 获取博客详情接口测试用例
### 3.1 正常场景
测试用例编号:detail_normal_01
测试用例:正常获取博客详情
测试目的:验证携带有效token和有效ID获取博客详情成功
请求URL:/blog/getBlogById
请求方法:GET
请求头:
- User_login_token: 有效的JWT token
请求参数:
- id: 有效的博客ID
预期结果:
- code: SUCCESS
- data: 返回博客详情数据
- errorMsg: 空字符串
### 3.2 边界情况
测试用例编号:detail_boundary_01
测试用例:缺失ID参数
测试目的:验证缺失ID参数时的处理
请求URL:/blog/getBlogById
请求方法:GET
请求头:
- User_login_token: 有效的JWT token
请求参数:
- 无id参数
预期结果:
- code: SUCCESS
- data: null
- errorMsg: 空字符串
测试用例编号:detail_boundary_02
测试用例:ID不存在
测试目的:验证ID不存在时的处理
请求URL:/blog/getBlogById
请求方法:GET
请求头:
- User_login_token: 有效的JWT token
请求参数:
- id: 999999
预期结果:
- code: SUCCESS
- data: null
- errorMsg: 空字符串
### 3.3 异常输入
测试用例编号:detail_exception_01
测试用例:ID为负数
测试目的:验证ID为负数时的处理
请求URL:/blog/getBlogById
请求方法:GET
请求头:
- User_login_token: 有效的JWT token
请求参数:
- id: -1
预期结果:
- code: SUCCESS
- data: null
- errorMsg: 空字符串
测试用例编号:detail_exception_02
测试用例:ID为字符串
测试目的:验证ID为字符串时的处理
请求URL:/blog/getBlogById
请求方法:GET
请求头:
- User_login_token: 有效的JWT token
请求参数:
- id: abc
预期结果:
- code: SUCCESS
- data: null
- errorMsg: 空字符串
### 3.4 安全测试
测试用例编号:detail_security_01
测试用例:缺失token
测试目的:验证缺失token时获取博客详情失败
请求URL:/blog/getBlogById
请求方法:GET
请求头:
- 无User_login_token
请求参数:
- id: 有效的博客ID
预期结果:
- 响应码:401
测试用例编号:detail_security_02
测试用例:无效token
测试目的:验证使用无效token获取博客详情失败
请求URL:/blog/getBlogById
请求方法:GET
请求头:
- User_login_token: invalid_token
请求参数:
- id: 有效的博客ID
预期结果:
- 响应码:401如果认为测试用例覆盖不全,或者测试用例质量不高,可以对生成的测试用例进行调整。本文当前采用上述测试用例。
四、技术选型与项目架构
1. 技术选型
|---------|------------------|
| 语言 | python |
| 框架 | pytest |
| HTTP库 | requests |
| 数据驱动 | YAML |
| 报告 | Allure |
| 接口返回值断言 | jsonschema |
| 日志 | logging模块,按天分割日志 |
2. 数据依赖分析
登录接口:登录成功时,返回一个 JWT 令牌作为登录凭证,后续其余接口访问博客系统时,都需要携带这个凭证;
博客列表接口:博客是动态变化的,访问博客详情时,需要携带有效的 blogId,因此获取博客列表后,需要将一个有效的博客 id 保存起来,后续访问博问博客详情时带上这个有效数据;
3. 项目架构
AI 提示词:
##项目架构生成
根据以下内容,直接输出接口自动化目录结构即可,不需要创建项目代码或文件 技术栈要求:
编程语言:Python
测试框架:pytest
HTTP 库:requests
数据驱动:YAML
报告:Allure
接口返回值断言:jsonschema
logging日志记录:日志分级输出,按天分割
其他设计要求:
其他接口需要在请求头 (User_login_token) 添加有效 token,token 值来自于登录接口的返回值data, 因此登录成功后, 需要把有效的 token 保存起来;
访问博客详情中有效的 blogId 取自列表页接口 getBlogList 的有效返回值 id, 例如: 列表页返回 {"id": 19, "title": "jmeter"} 则详情页中 blogId 为 19, 因此获取列表后, 要把一个有效的 id 保存起来;
增加一个文档目录,用于保存项目文档, 只增加目录即可, 不需要把文件列出来;
创建一个项目架构文件,用于保存项目架构,AI 生成的项目架构如下:
api_auto_test/
├── tests/ # 测试用例目录
│ ├── test_login.py # 登录接口测试
│ ├── test_list.py # 博客列表接口测试
│ └── test_detail.py # 博客详情接口测试
├── data/ # 数据驱动目录
│ ├── login_data.yaml # 登录接口测试数据
│ ├── list_data.yaml # 列表接口测试数据
│ └── detail_data.yaml # 详情接口测试数据
├── config/ # 配置文件目录
│ ├── config.yaml # 全局配置
│ └── env.yaml # 环境配置
├── utils/ # 工具类目录
│ ├── init.py # 包初始化文件
│ ├── request.py # 请求封装
│ ├── extractor.py # 响应数据提取器
│ ├── validator.py # 响应数据验证器
│ └── logger.py # 日志工具
├── common/ # 公共目录
│ ├── init.py # 包初始化文件
│ ├── constants.py # 常量定义
│ └── global_var.py # 全局变量(存储token和blogId)
├── schemas/ # JSON Schema目录
│ ├── login_schema.json # 登录响应schema
│ ├── list_schema.json # 列表响应schema
│ └── detail_schema.json # 详情响应schema
├── docs/ # 项目文档目录
├── reports/ # 测试报告目录
│ └── allure/ # Allure报告
├── logs/ # 日志目录
├── pytest.ini # pytest配置文件
├── requirements.txt # 依赖包文件
└── README.md # 项目说明文件
按照项目架构文件,生成项目架构:
AI 提示词:
生成目录架构: 按照目录结构文件生成相应的目录架构, 不需要生成项目代码, 只需要创建目录和文件即可;
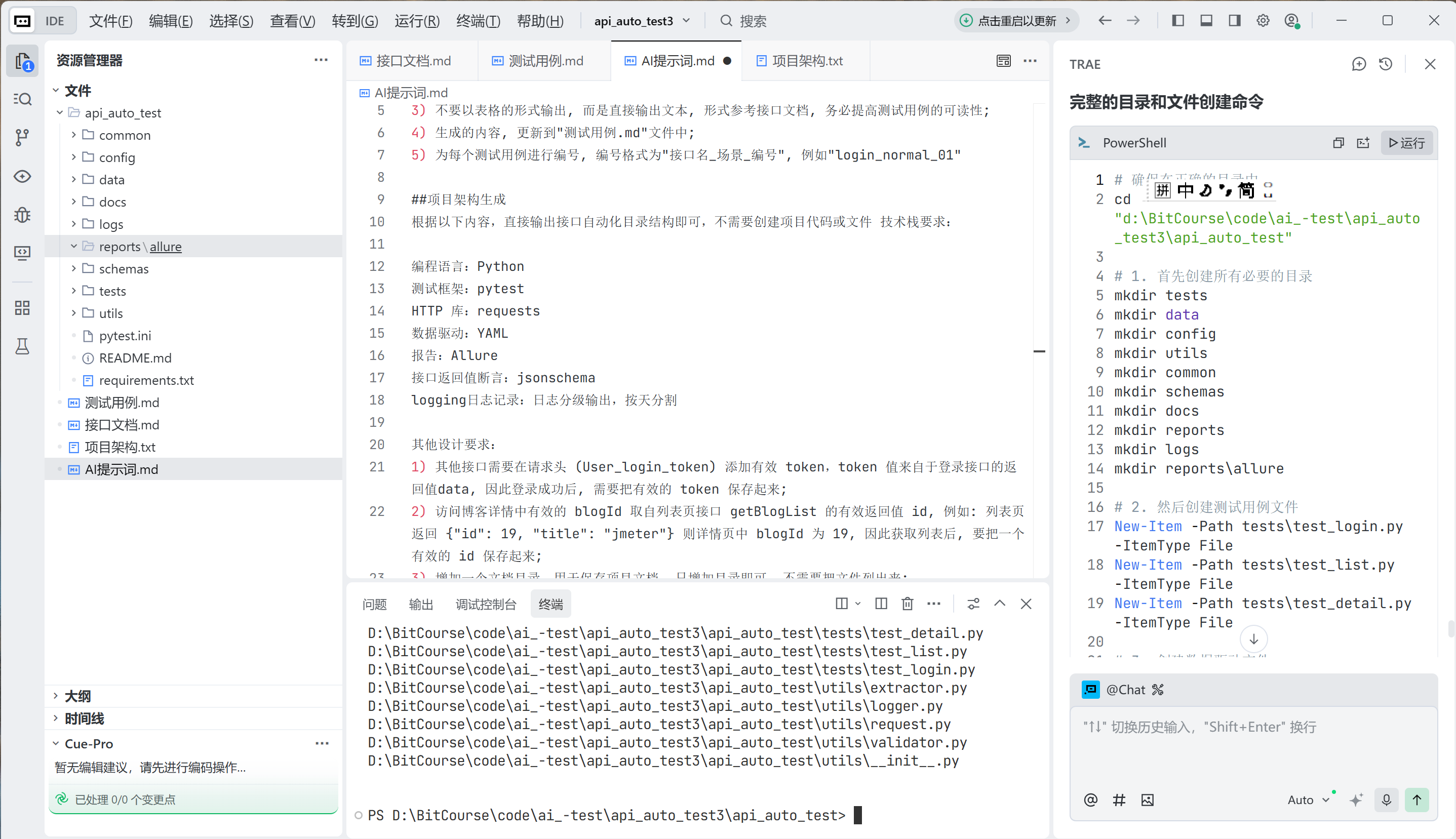
运行 AI 提供的创建命令,目录与文件创建成功,如下:
注意事项:
不要让AI删除文件或者文件夹,因为 AI 没法复原(只能还原文件, 不能还原文件内容),因此建议手动删除文件,删错了还能去回收站找;
五、测试代码
1. 代码生成
AI 提示词
生成测试代码
根据"测试用例.md"生成测试代码, 注意:
其他接口需要在请求头 (User_login_token) 添加有效 token,token 值来自于登录接口的返回值data, 因此登录成功后, 需要把有效的 token 保存起来;
访问博客详情中有效的 blogId 取自列表页接口 getBlogList 的有效返回值 id, 例如: 列表页返回 {"id": 19, "title": "jmeter"} 则详情页中 blogId 为 19, 因此获取列表后, 要把一个有效的 id 保存起来;
基于 pytest 框架生成测试代码;
能使用参数化合并的测试用例, 要使用参数化的方式进行合并, 不能合并的保持原样, 不要强行合并, 导致遗漏测试内容;
使用 jsonschema 校验接口返回值;
使用 YAML 文件来保存数据依赖, 例如 blogID, 登录成功后的 token 等;
使用 python 自带的 logging 模块打印日志, 日志要分级输出, Error 级别单独输出到一个文件, info 级别单独输出到一个文件, 所有的的日志也要单独输出到一个文件, 方便用户查看全部日志; 日志要按天分割, 日志格式要包含时间, 日志级别, 文件名, 行号, 日志内容等;
注意, 检查以下技术栈是否都在项目中使用: Python, pytest, requests, YAML, Allure, jsonschema, logging;
使用上述提示词,AI 能够为我们生成测试代码;
2. 目录文件审核
接下来要人工核对生成的测试代码是否正确,以及是否需要进行调整。可以人工来调整,也可以使用 AI 帮助我们进行调整。
common 目录:
common 目录是公共目录,用来保存项目中用到的常量以及全局变量;
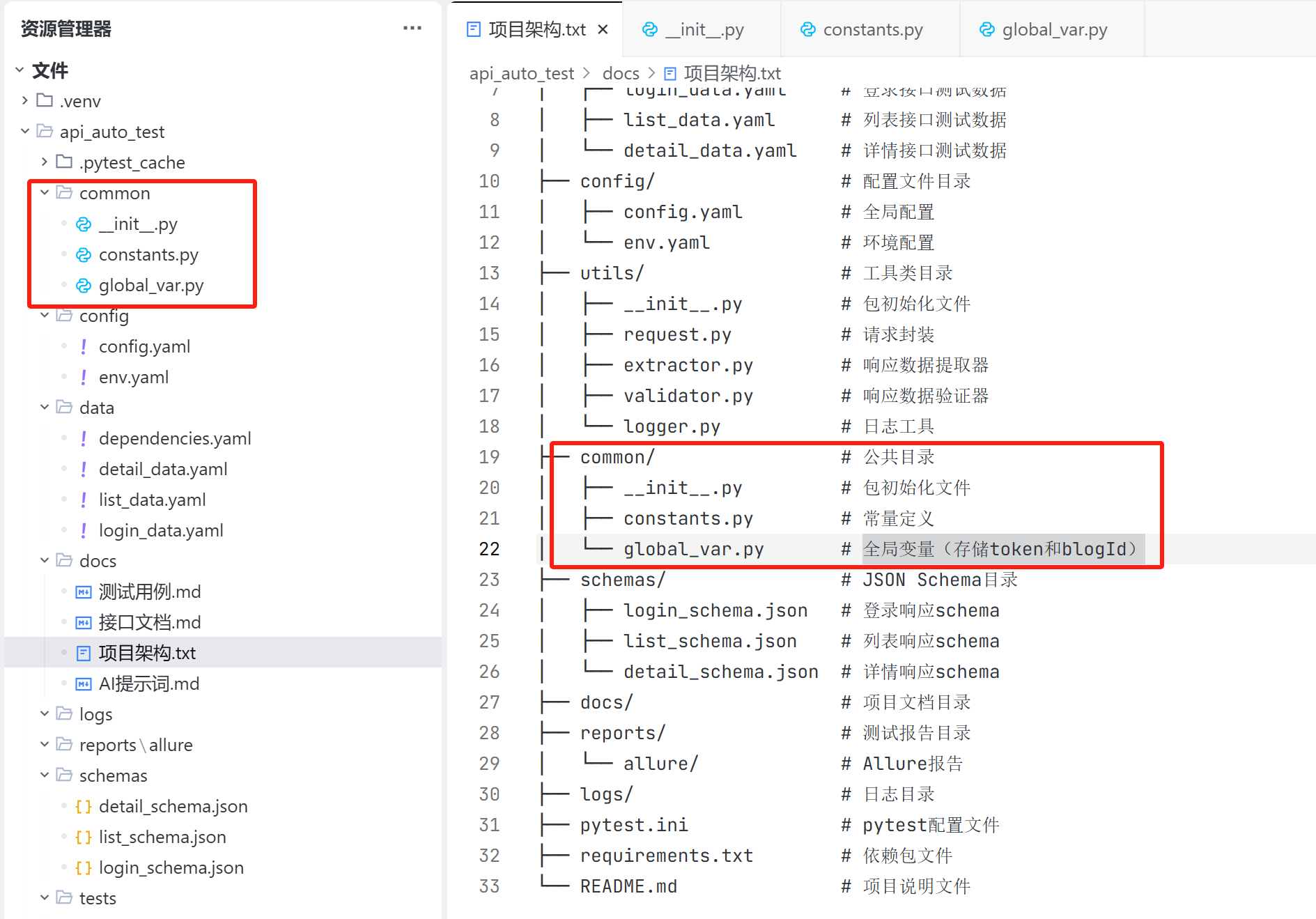
实际上:
- 项目中使用的 token 和 blogId 是使用 yaml 文件保存的,不作为全局变量保存到内存当中;
- 而生成的初始化文件和常量定义文件都是空的,项目中不需要初始化,也不需要定义常量;
因此不需要这个目录,进行人工删除。
Config 目录:
Config 目录是配置文件目录,本次生成的两个文件 config.yaml 和 env.yaml 分别用来保存全局配置和环境配置,实际上两个文件也都是空的。本次项目不需要全局配置和环境配置,因此人工删除这个目录;
Data 目录:
Data 目录是数据驱动目录,用来保存接口需要用到的测试数据;
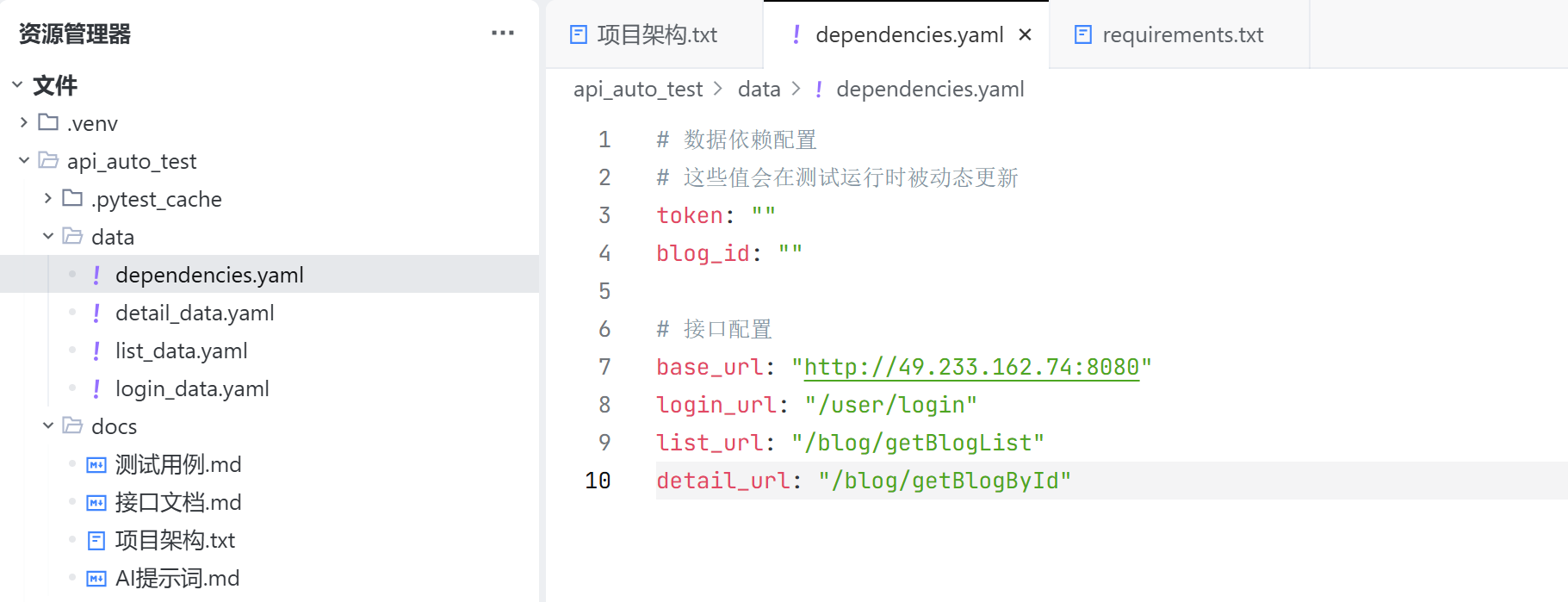
dependencies.yaml 用于保存各个接口的配置,以及登录成功后的登录凭证,访问接口列表后获取的有效的 blogId;
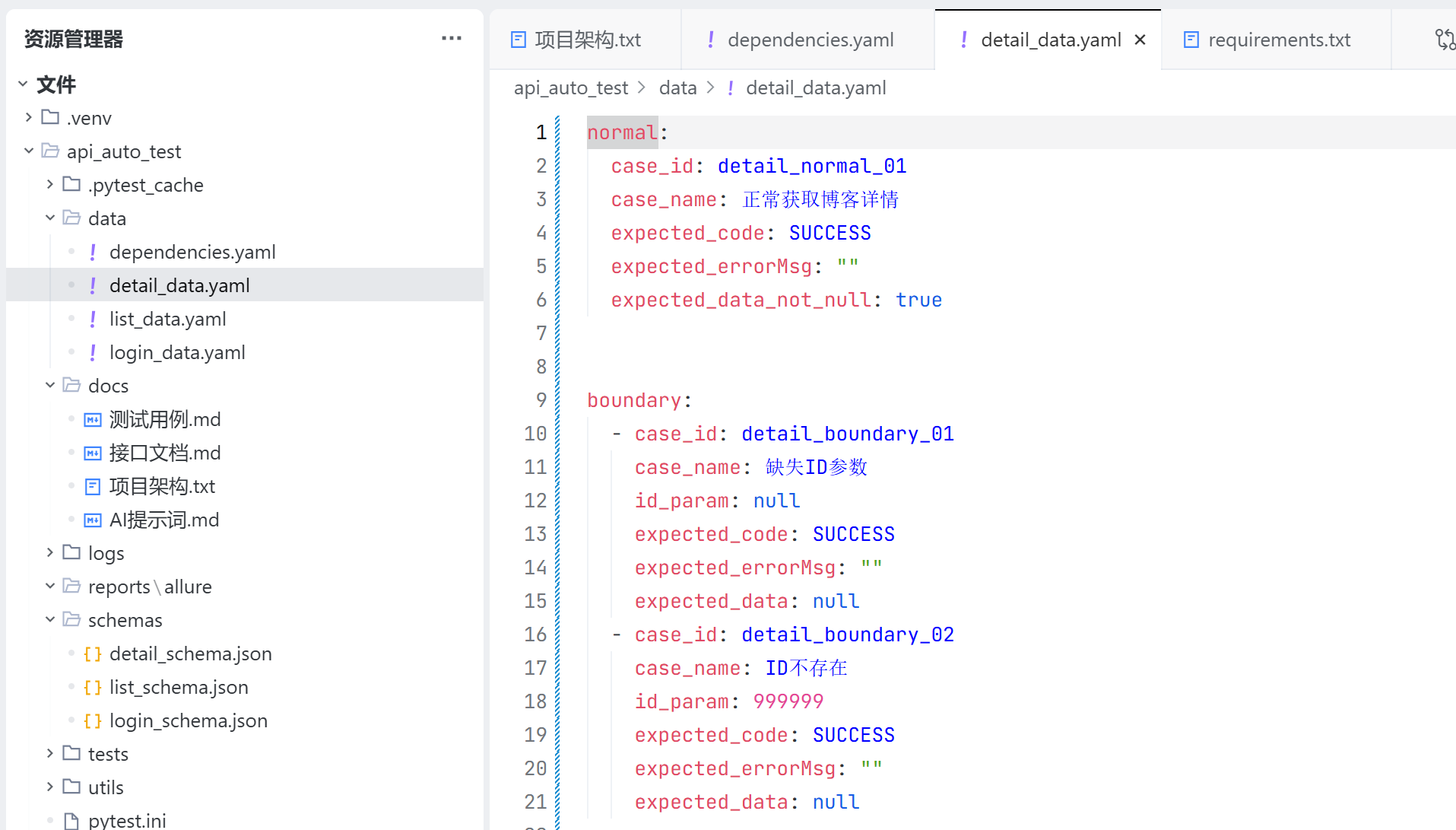
detail_data.yaml 用于保存获取博客详情接口每一个测试用例预期返回的结果,用于校验接口的返回值是否正确;
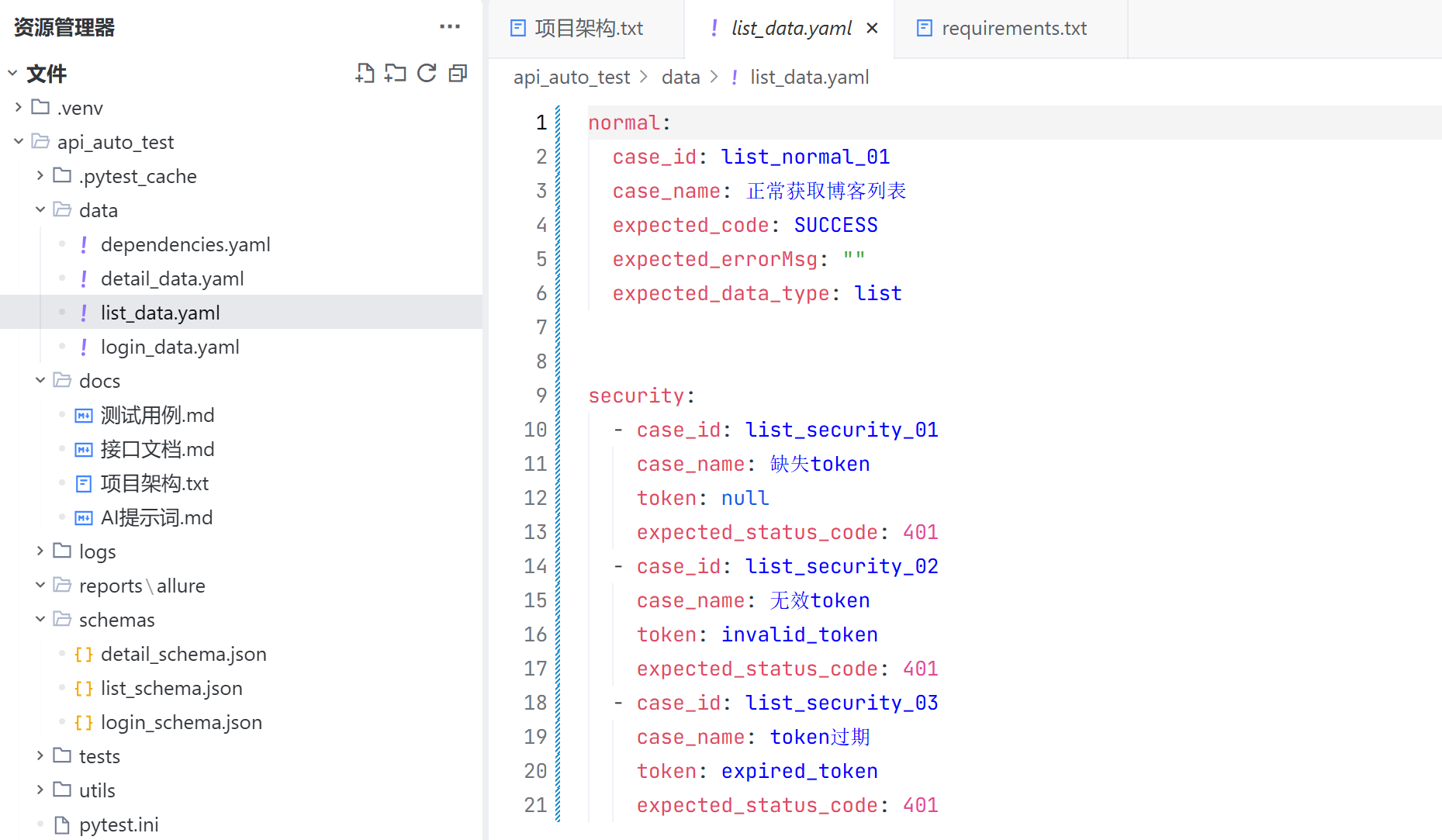
list_data.yaml 用于保存博客列表接口所有测试用例预期返回的结果,用于校验接口的返回值是否正确;
login_data.yaml 用于保存登录接口所有测试用例预期返回的结果,用于校验接口的返回值是否正确;
docs 目录:
docs 目录用于保存项目文档,包括接口文档,测试用例, 项目架构,以及项目用到的 AI 提示词;
因为前面手动删除了一些目录,因此项目架构后续还需要调整;
logs 目录:
logs 目录用于保存项目日志;目前项目还未运行,还没有生成日志,所以目录为空;
reports 目录:
reports 目录用于存放 allure 生成的原始数据以及 html 格式的测试报告,因此还需要建两个子目录分别存放原始数据与测试报告;
手工调整:
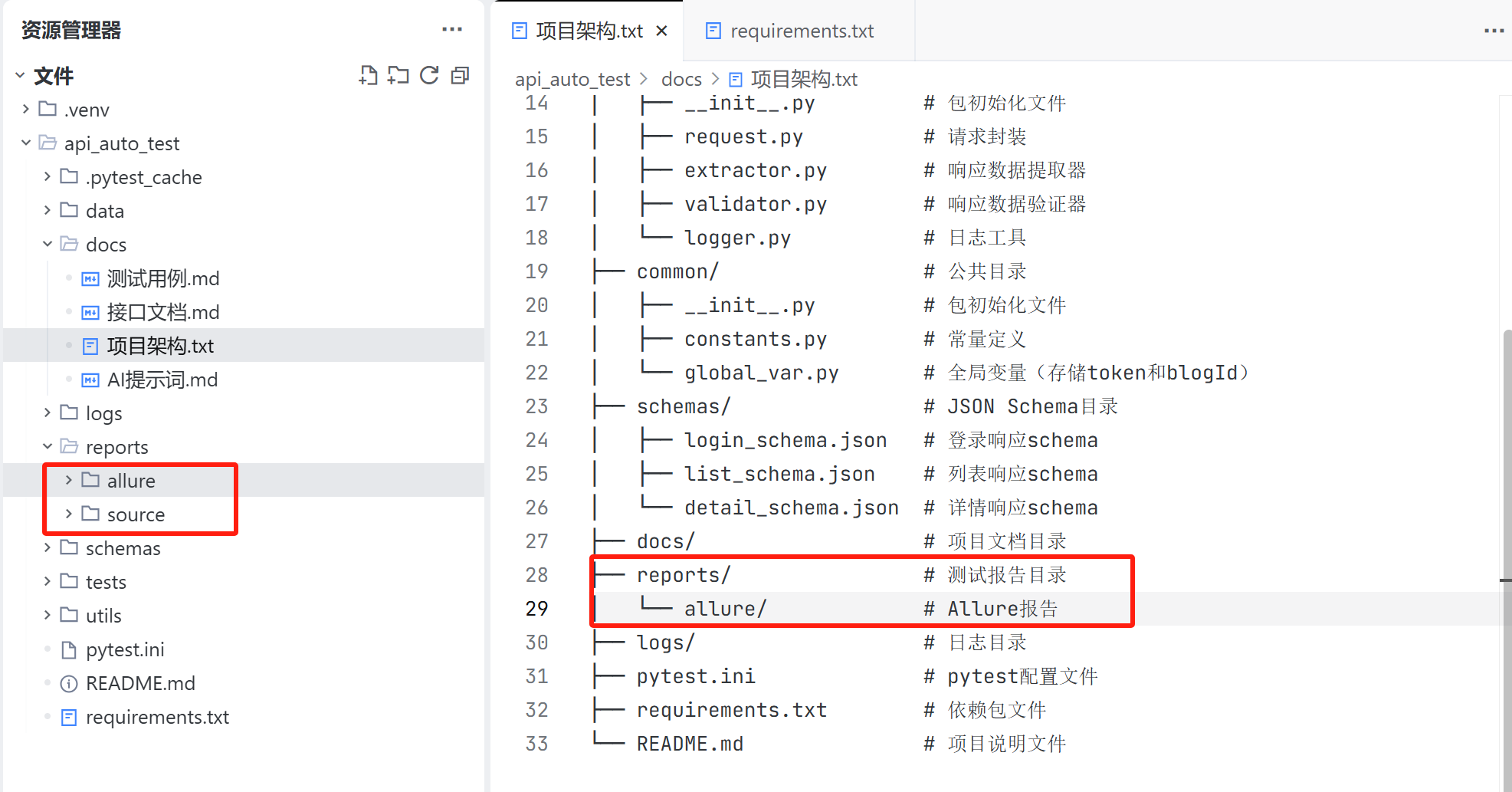
后续统一更新项目架构文档;
shcemas 目录:
schemas 目录用于存放 jsonschema 文件,用于校验各个接口返回值的字段及其类型;
detail_schema.json 用于校验获取博客详情接口返回字段是否齐全,以及每一个字段的类型是否正确;
list_schema.json 用于校验获取博客列表返回的字段是否齐全,以及每一个字段的类型是否正确;
login_schema.json 用于校验登录接口返回的字段是否齐全,以及每一个字段的额类型是否正确;
tests 目录:
tests 目录是存放接口测试用例代码的目录;
test_detail.py 用于存放获取博客详情接口测试用例的代码实现;
test_list.py 用于存放获取博客列表接口的测试用例的代码实现;
test_login.py 用于存放登录接口的测试用例的代码实现;
utils 目录
utils 目录用于存放项目需要用到的工具类;
dependency_manager.py 用于存放项目所依赖的数据的工具类,这个工具类用于获取接口的 url,保存/获取登录凭证,保存/获取有效的 blogId 等;
logger.py 用于存放打印日志的工具类;
extractor 用于提取相应数据的,request 用于请求封装,validator 用于验证相应数据,但这三个模块实际在项目中没有用到,生成的文件是空文件,因此手动删除;
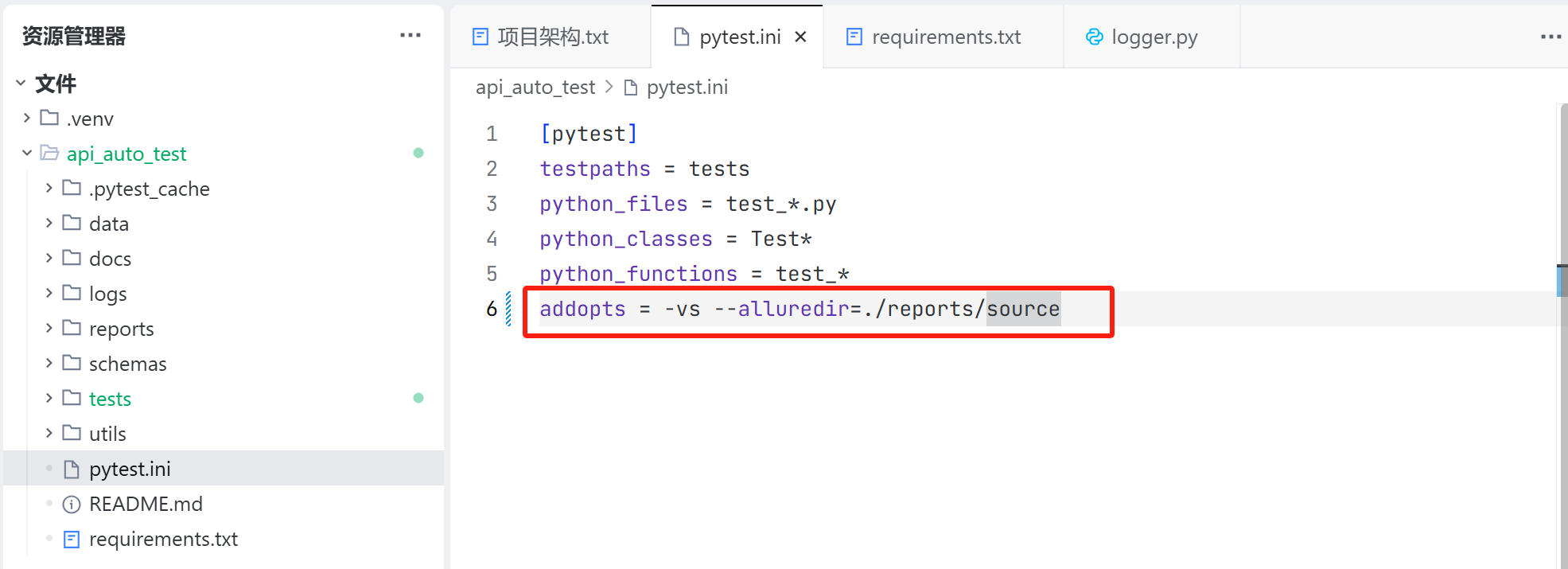
pytest.ini 文件:
pytest.ini 文件用于配置 pytest 框架测试用例的收集规则,以及默认测试命令的执行内容;
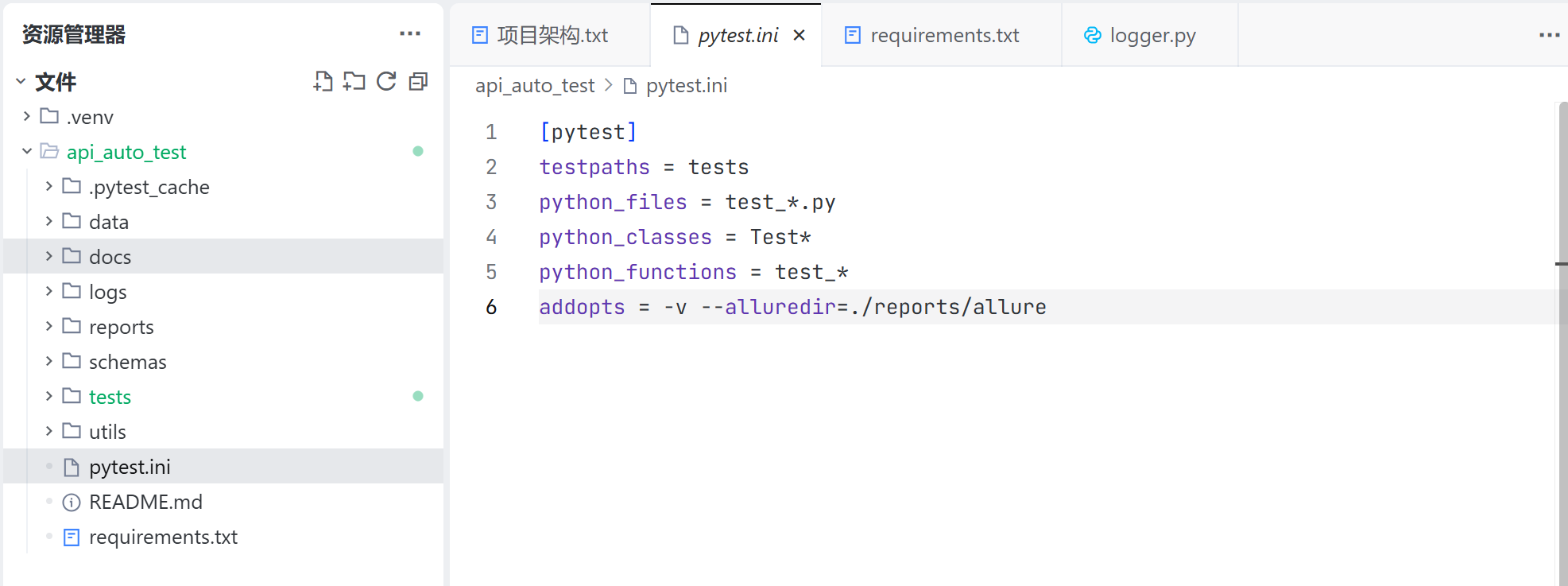
我们需要:
- 看到测试用例执行的详情以及控制台打印的内容;
- 调整测试源数据的保存位置为 ./reports/source;
因此手动更新测试配置文件:
README.md 文件:
README.md 文件用于介绍项目,后续可以用 AI 自动帮我们生成项目介绍;
requirements.txt 文件:
requirements.txt 文件用于列出项目依赖的软件包;
安装依赖:
pip install -r requirements.txt
检查是否安装成功:
pip list

3. 测试代码调试
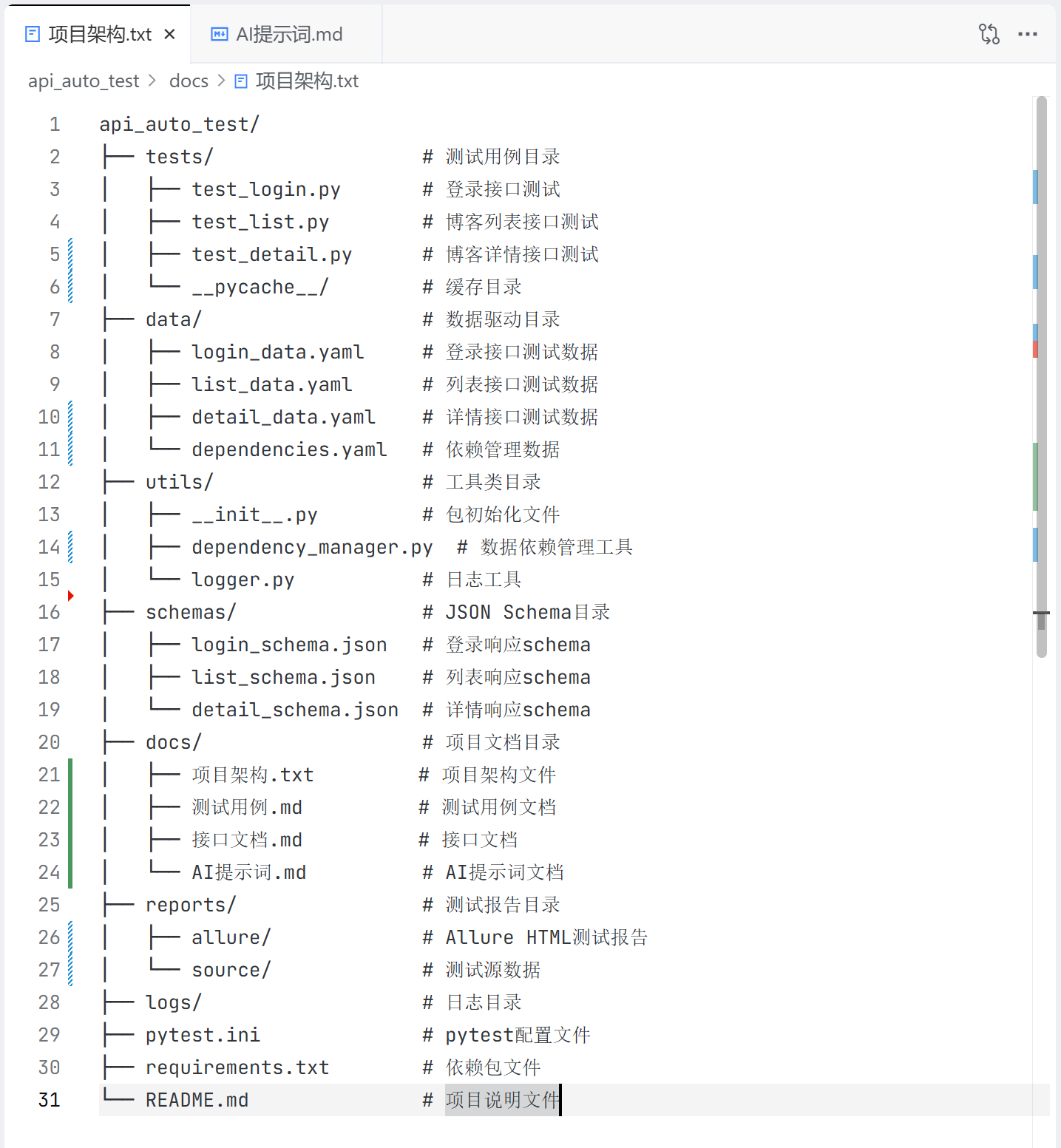
- 项目架构
使用 AI 更新项目架构文件,按照当前的项目架构进行调整:
- 测试代码审核
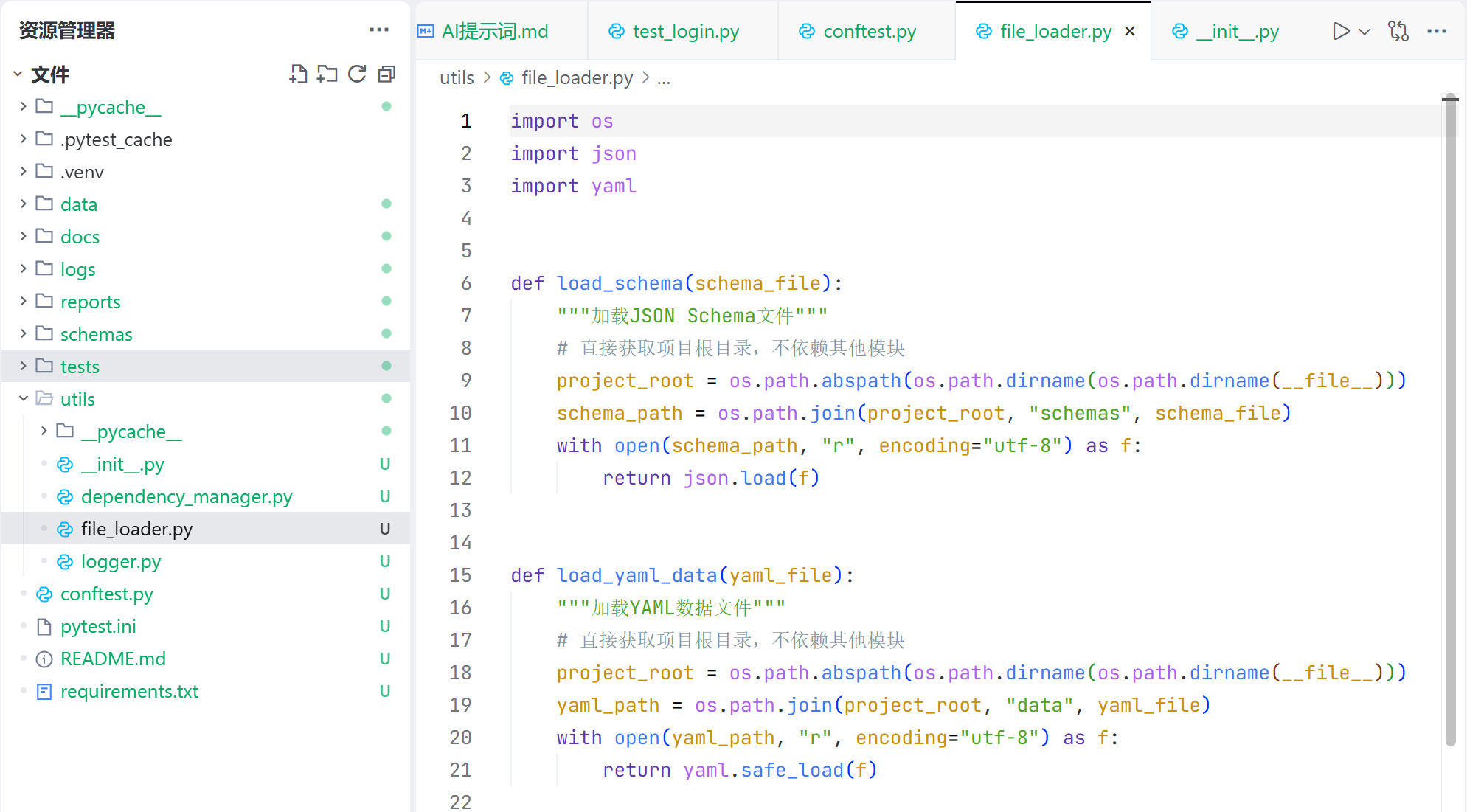
对于每一个测试用例,都需要从 yaml 文件中读取信息:
-
- 读取 schemas 目录,通过 jsonschema 校验返回值的字段及其类型;
-
- 读取 data 目录,通过断言校验返回值关键字段的内容;
因此这一块可以作为公共代码,提取出来,放到 util 工具包中。因此增加一个 file_loader.py 文件,如下:
每个测试用例运行之前,需要把项目目录添加到 python 文件中,因此统一新增 conftest.py 文件,在文件中先添加项目目录,如下:
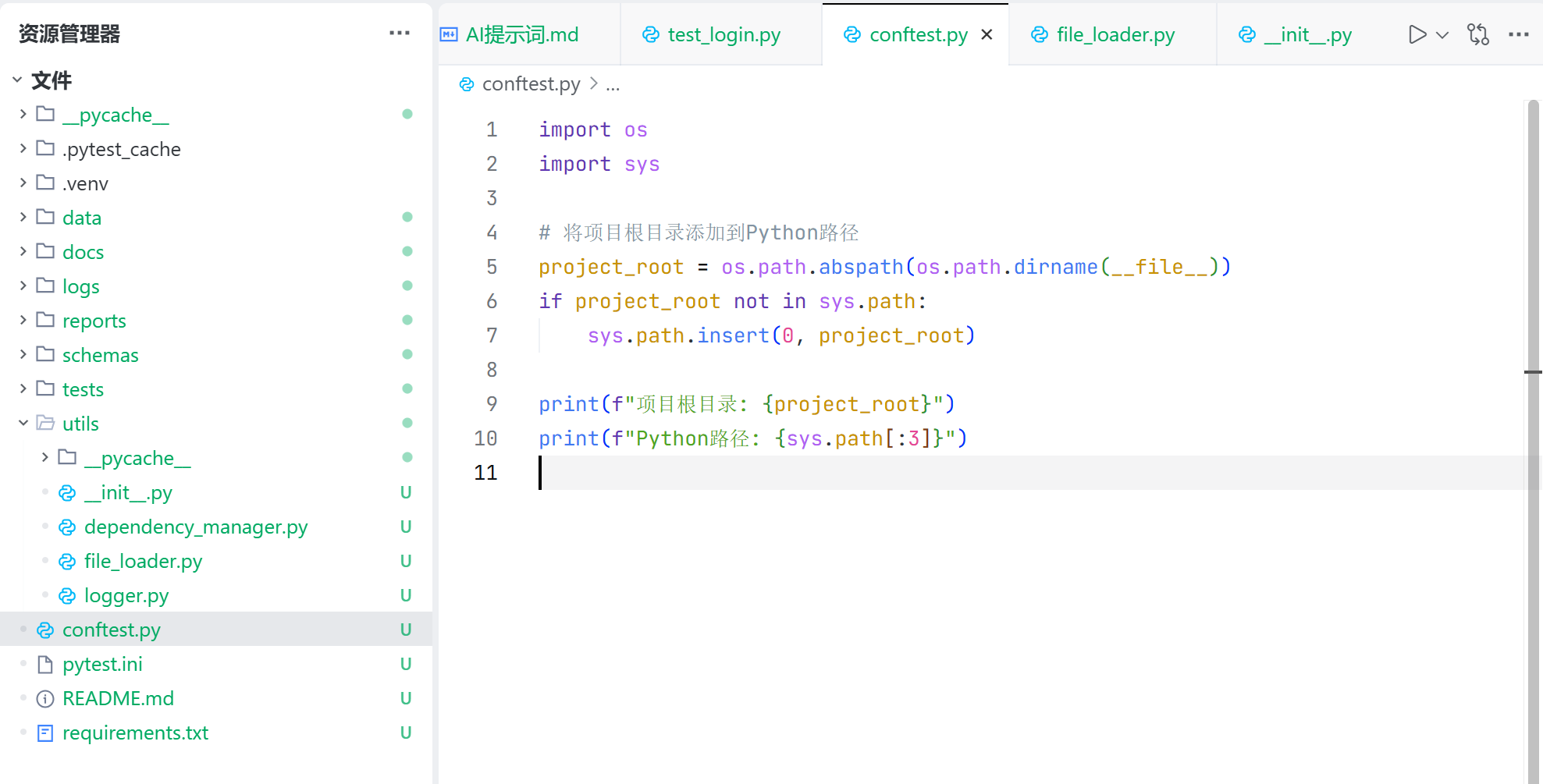
其余生成的测试代码,基本上都采用了,没有什么问题,详情见:api_auto_test3/tests/test_login.py · yzg-test/AI_Test - 码云 - 开源中国
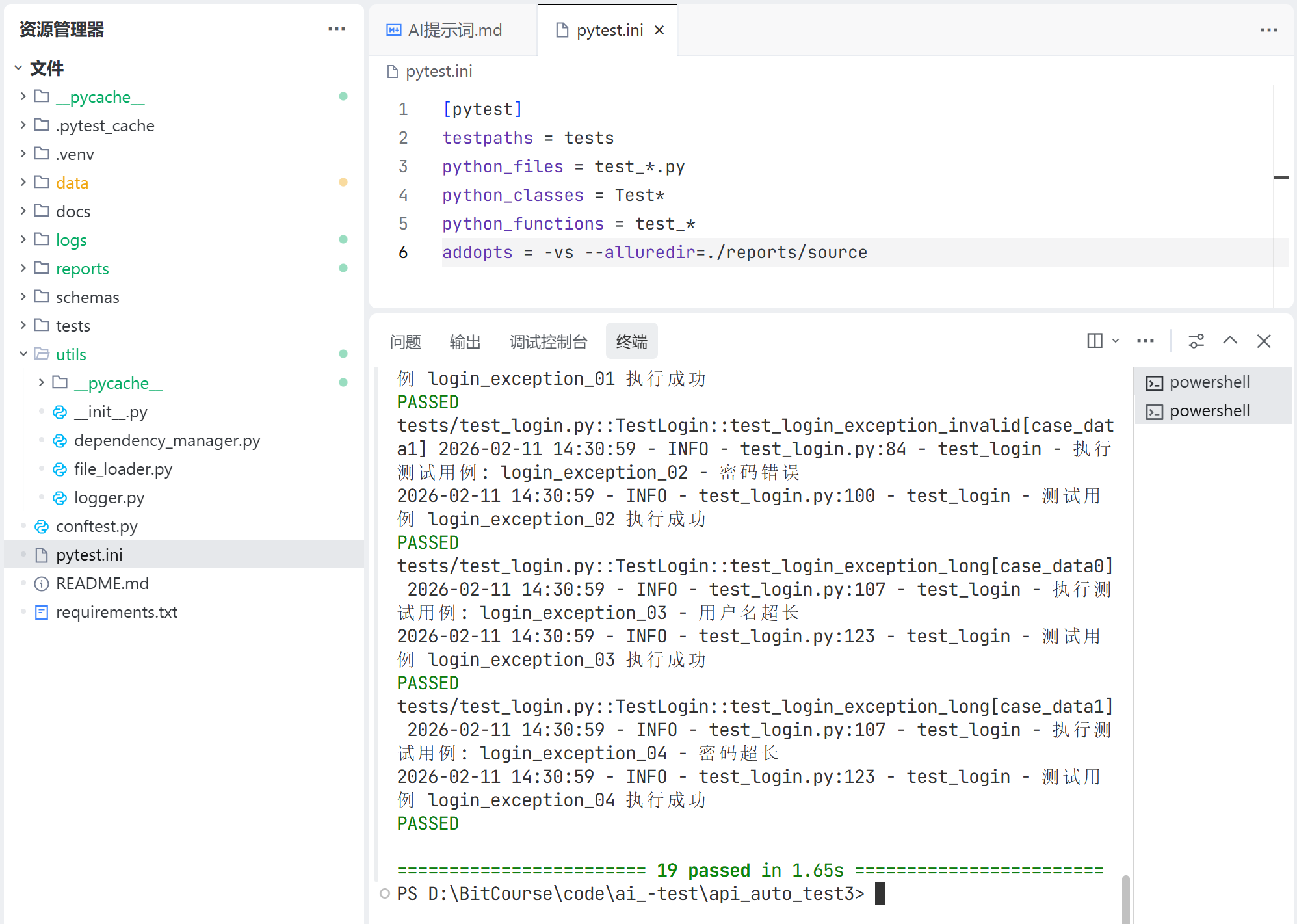
下图为本次调试的最终结果:
4. 注意事项
虽然测试用例都调试正常,但是接口测试是有顺序的,比如:
- 获取博客列表接口需要依赖登录返回的登录凭证;
- 获取博客详情需要列表接口返回有效的 blogId;
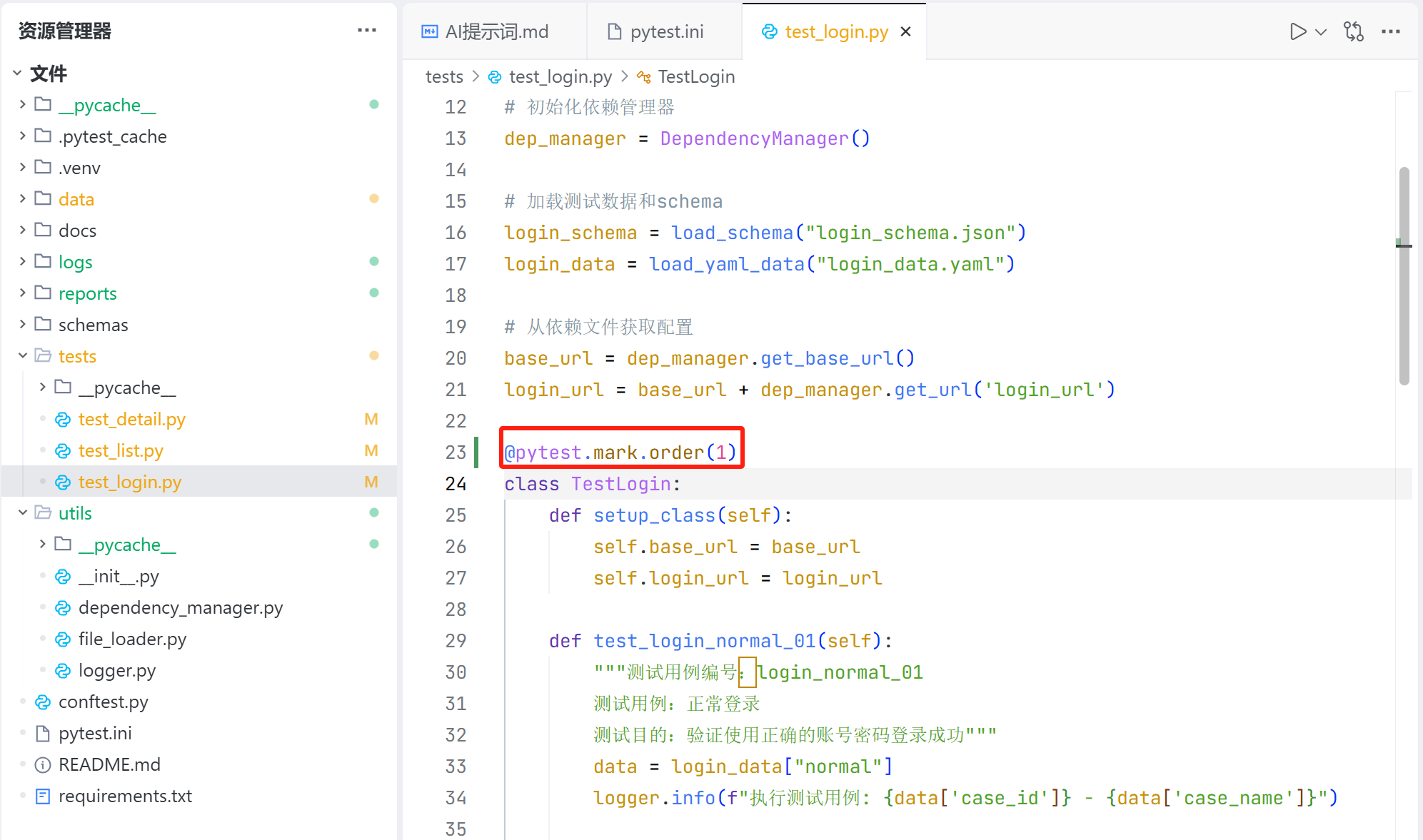
因此需要在代码中指定接口的运行顺序,这里选择 pytest-order 软件包,使用 @pytest.mark.order(num) 指定测试的运行顺序,num 越大,执行顺序越靠后,如下:
使用 pytest 运行,测试用例会按照指定的顺序运行。
六、运行测试
使用 allure 运行测试,生成测试报告;
pytest.ini 文件,更改 pytest 运行指令配置,生成测试源数据,并清除之前老数据:
addopts = -vs --alluredir=./reports/source --clean-alluredir
启动本地服务(这种方式可以跨主机查看),用于在线查看测试报告:
allure serve reports/source -o reports/allure --clean
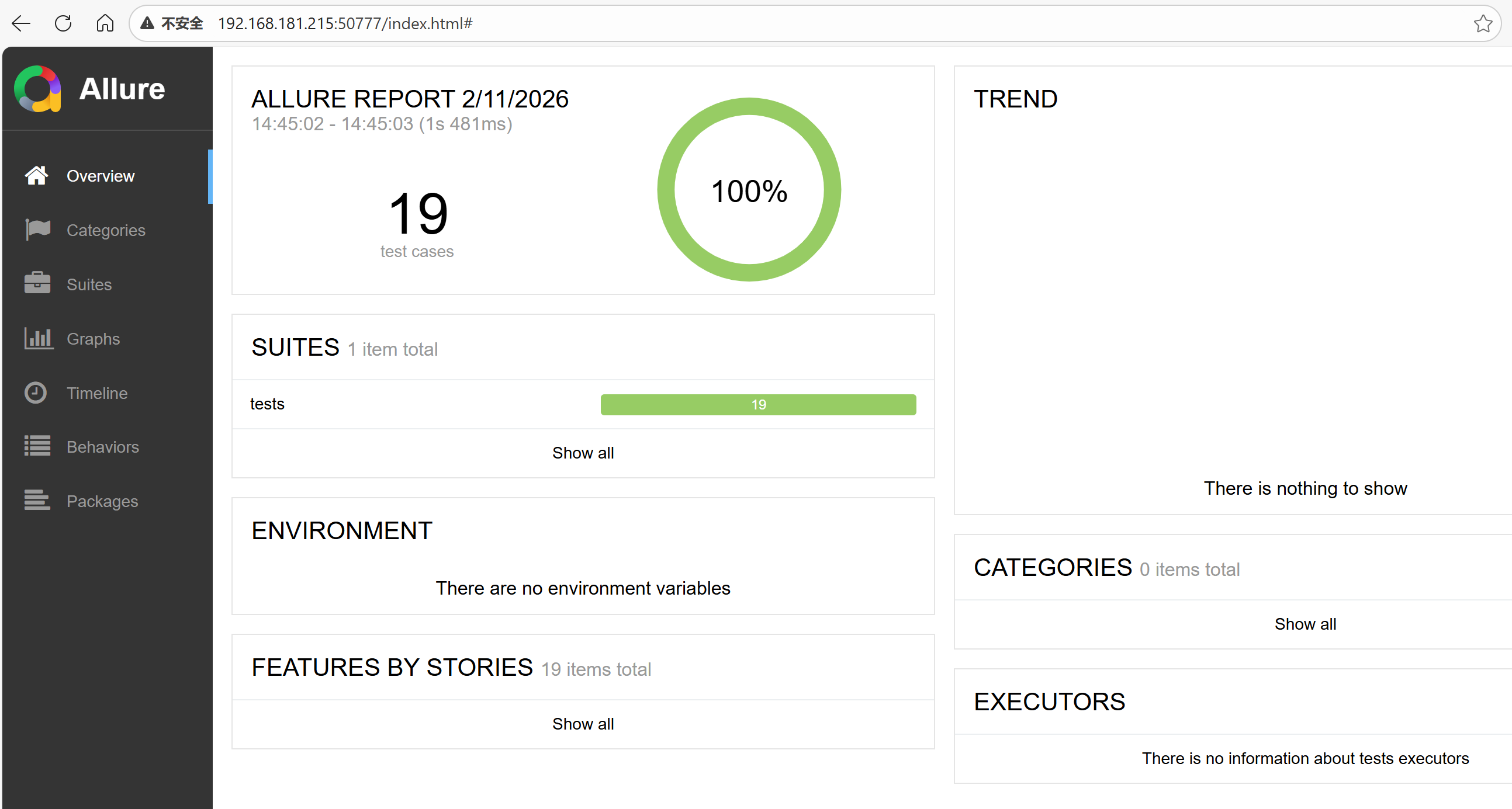
将测试报告保存在本地:
allure generate reports/source -o reports/allure --clean
可以访问本地的 index.html 文件,如下:
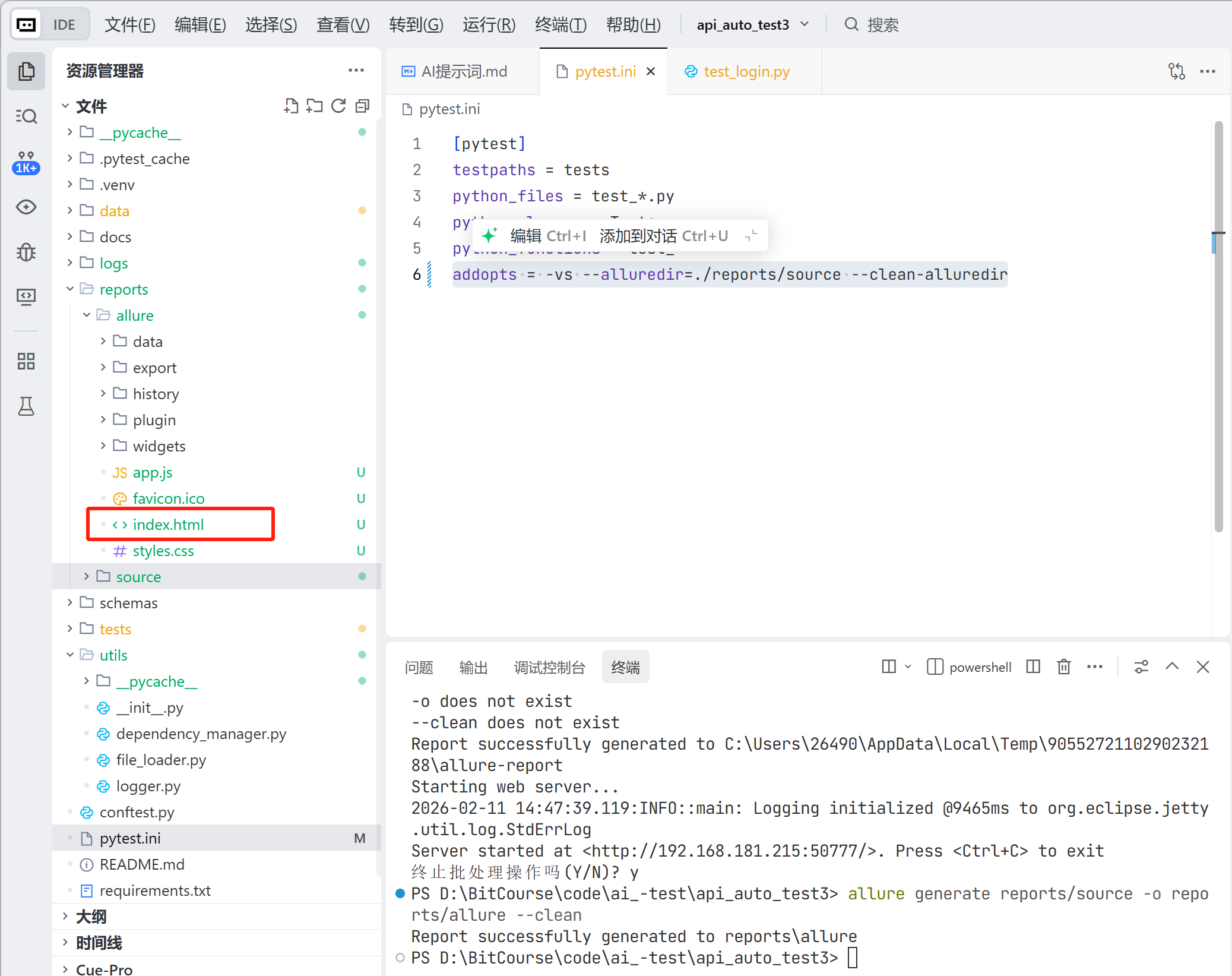
总结
本项目为博客系统的API测试提供了一套完整的自动化解决方案,通过规范化的测试流程和工具集成,提高了测试效率和质量,为系统的稳定性和可靠性提供了有力保障。