OneLive:面向直播推荐的动态统一生成式框架深度解析
目录
- OneLive:面向直播推荐的动态统一生成式框架深度解析
-
- [一. 直播推荐的独特挑战:为何传统方法失效?](#一. 直播推荐的独特挑战:为何传统方法失效?)
- [二. 传统架构瓶颈:为何需要生成式范式革命?](#二. 传统架构瓶颈:为何需要生成式范式革命?)
-
- [2.1 级联架构的固有缺陷](#2.1 级联架构的固有缺陷)
- [2.2 计算图碎片化](#2.2 计算图碎片化)
- [2.3 生成式推荐的机遇](#2.3 生成式推荐的机遇)
- [三. OneLive核心技术创新](#三. OneLive核心技术创新)
-
- [3.1 动态Tokenizer:实时内容-行为联合编码](#3.1 动态Tokenizer:实时内容-行为联合编码)
- [3.2 时序感知门控注意力:建模生命周期约束](#3.2 时序感知门控注意力:建模生命周期约束)
- [3.3 序列多Token预测(Sequential MTP)+ QK Norm](#3.3 序列多Token预测(Sequential MTP)+ QK Norm)
-
- [3.3.1 推理加速:Sequential MTP](#3.3.1 推理加速:Sequential MTP)
- [3.3.2 训练稳定性:QK Norm](#3.3.2 训练稳定性:QK Norm)
- [3.4 多目标对齐强化学习框架](#3.4 多目标对齐强化学习框架)
- [四. 实验验证:离线与在线双重验证](#四. 实验验证:离线与在线双重验证)
-
- [4.1 离线指标全面领先](#4.1 离线指标全面领先)
- [4.2 在线A/B测试:真实业务增益](#4.2 在线A/B测试:真实业务增益)
- [4.3 模型缩放定律验证](#4.3 模型缩放定律验证)
- [五. 行业价值与技术启示](#五. 行业价值与技术启示)
-
- [5.1 范式转变意义](#5.1 范式转变意义)
- [5.2 工业落地关键经验](#5.2 工业落地关键经验)
- [六. 未来展望](#六. 未来展望)
摘要:本文深度解析快手科技提出的OneLive------业界首个成功部署于大规模直播场景的动态统一生成式推荐框架。针对直播内容动态演化、生命周期短暂、实时性要求严苛等独特挑战,OneLive通过动态Tokenizer、时序感知门控注意力、序列多Token预测等四大创新组件,实现了端到端的高效推荐,在快手全量上线后带来核心业务指标显著提升。
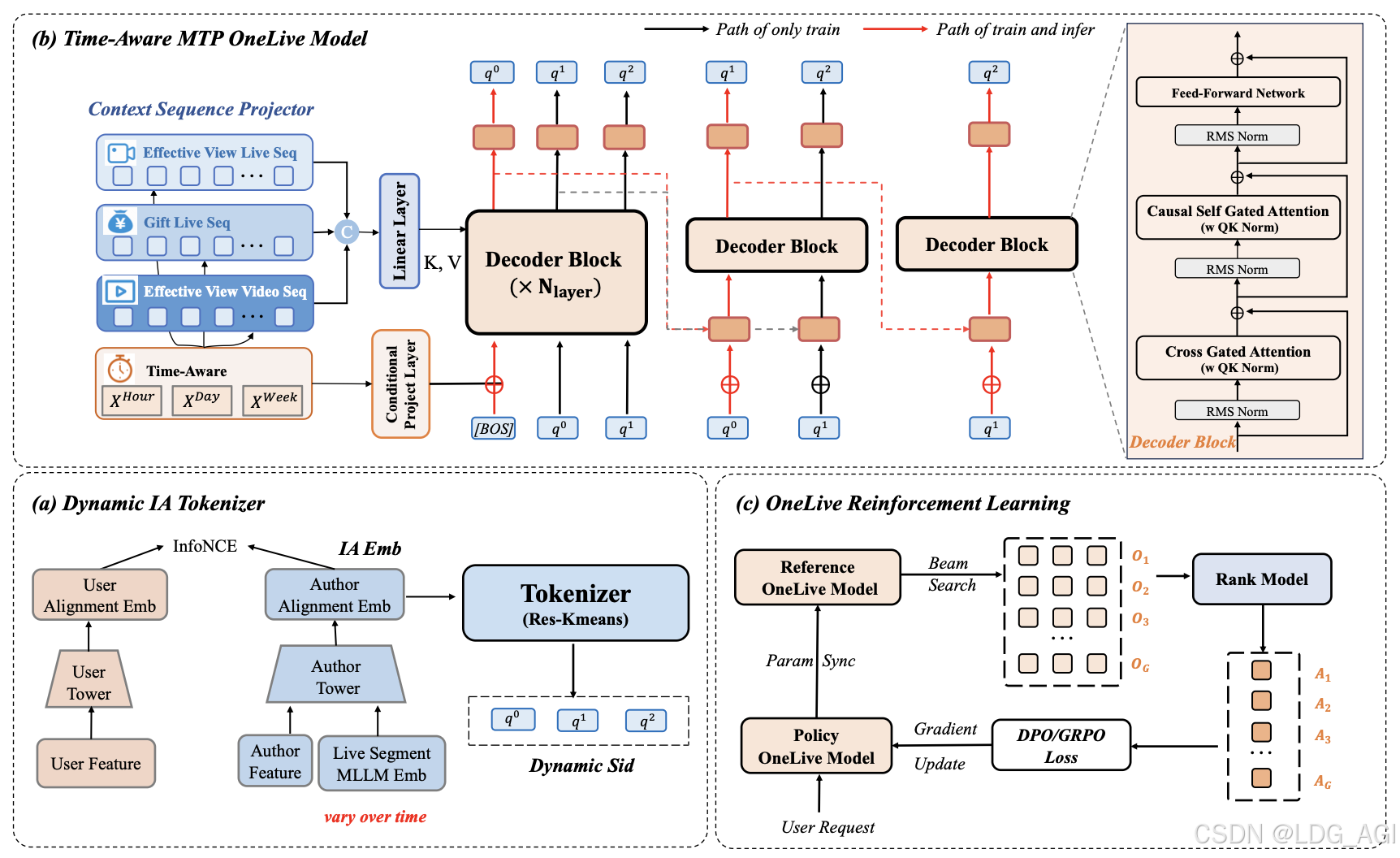
一. 直播推荐的独特挑战:为何传统方法失效?
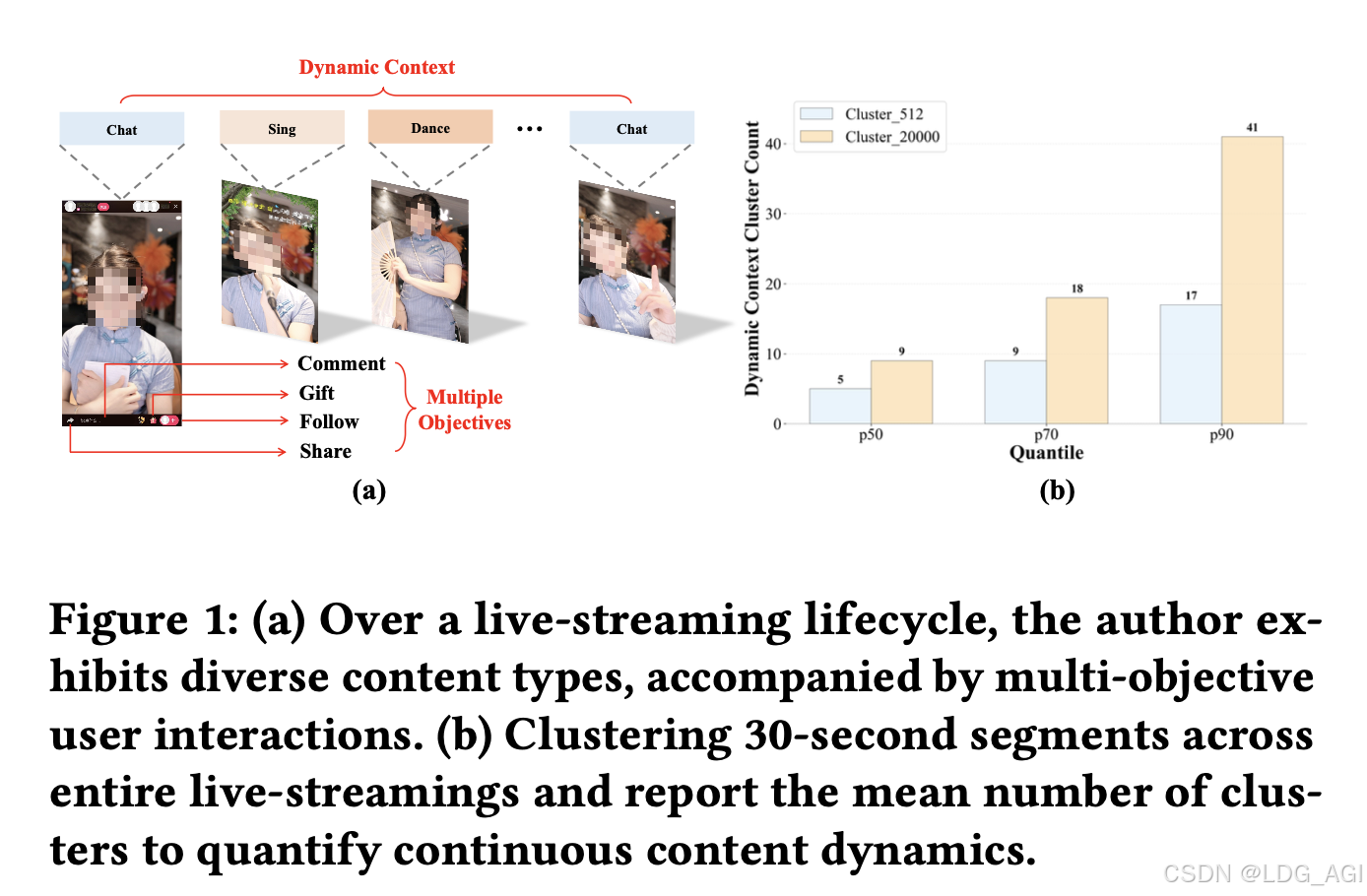
直播推荐与传统短视频/电商推荐存在本质差异,主要体现在四大维度:
| 挑战维度 | 传统内容(短视频/商品) | 直播内容 | 对推荐系统的影响 |
|---|---|---|---|
| 内容动态性 | 上传后内容固定不变 | 作者实时切换聊天/唱歌/跳舞等行为,内容持续演化 | 静态Tokenization失效,需实时捕捉内容漂移 |
| 生命周期 | 持久化内容库存,长期可推荐 | 严格时间窗口约束(开播→增长→峰值→衰退→下播) | 候选池高度动态,需在"黄金曝光窗口"内完成分发 |
| 实时性要求 | 秒级响应可接受 | 毫秒级延迟约束,高并发场景下需维持稳定吞吐 | 生成式模型推理效率面临严峻挑战 |
| 目标多样性 | 单一点击目标为主 | 点击、长播、关注、打赏等多目标异构反馈 | 需灵活融合用户异构偏好,避免刚性加权 |
二. 传统架构瓶颈:为何需要生成式范式革命?
2.1 级联架构的固有缺陷
工业推荐系统长期采用检索→粗排→精排的漏斗式级联架构,存在两大根本性问题:
- 目标错位:上游检索追求覆盖率与多样性,下游精排追求精准度,导致全局次优解
- 信息瓶颈:优质直播在早期阶段被过滤后无法恢复,形成不可逆损失
2.2 计算图碎片化
传统架构混合稀疏Embedding Lookup、序列建模、特征交叉等异构组件,导致:
- 内存带宽成为瓶颈(MFU < 3%)
- 有效浮点运算占比低,难以通过硬件升级线性提升性能
2.3 生成式推荐的机遇
Transformer架构为推荐系统带来范式转变:
- 统一建模接口:将异构信号组织为Token序列,实现端到端学习
- 计算效率提升:注意力与FFN以大规模矩阵运算为主,MFU显著提升(论文达22.78%)
⚠️ 关键洞察:现有生成式推荐方法(如OneRec、TIGER)直接迁移至直播场景会失效------其静态Tokenization无法适应内容动态演化,且未考虑直播生命周期约束。
三. OneLive核心技术创新
3.1 动态Tokenizer:实时内容-行为联合编码
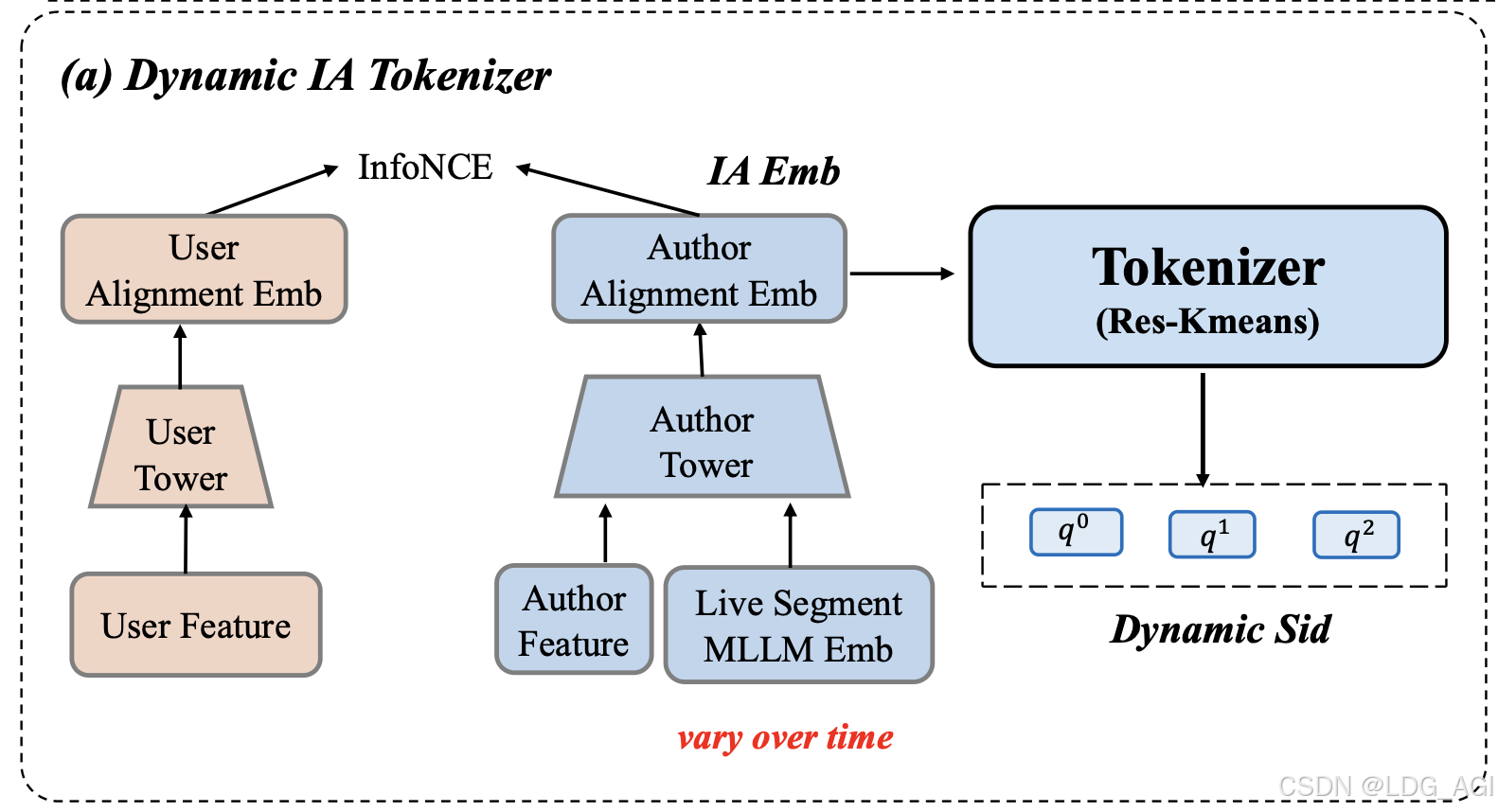
传统方法将物品编码为静态语义ID(SID),但直播内容持续变化导致表征失真。OneLive提出两阶段动态对齐机制:
python
# 伪代码:动态Tokenizer核心流程
class DynamicTokenizer:
def __init__(self):
self.mllm = LightweightMLLM() # 30秒滑动窗口实时编码
self.user_tower = MLP()
self.author_tower = GatedFusion() # 融合静态属性+动态内容
def forward(self, live_stream, user_interactions):
# 阶段1: 动态内容理解
x_mllm_30s = self.mllm(live_stream[-30s]) # 实时状态
x_mllm_pool = avg_pool(live_stream) # 长期主题
# 阶段2: 协同信号后对齐
x_author = λ * x_author_id + (1-λ) * MLP(concat(x_mllm_30s, x_mllm_pool))
x_user = self.user_tower(user_id)
# InfoNCE损失优化用户-作者对齐
loss_align = in_batch_softmax(x_user, x_author)
# 残差量化生成动态SID
ia_embedding = x_author # 语义+协同对齐的表征
sid = res_kmeans_quantize(ia_embedding, layers=3, size=8192)
return sid关键优势:
- 代码本利用率提升 :表1显示,IA Embedding + Res-Kmeans (8192×3) 实现100%层级利用率 与1.76%碰撞率,显著优于MLLM Embedding(碰撞率28.10%)
- 动态适应性:图6案例显示,同一作者直播内容从"推广化妆品"切换至"与猫玩耍"时,SID第三层代码实时更新(7964 → 2462)
3.2 时序感知门控注意力:建模生命周期约束
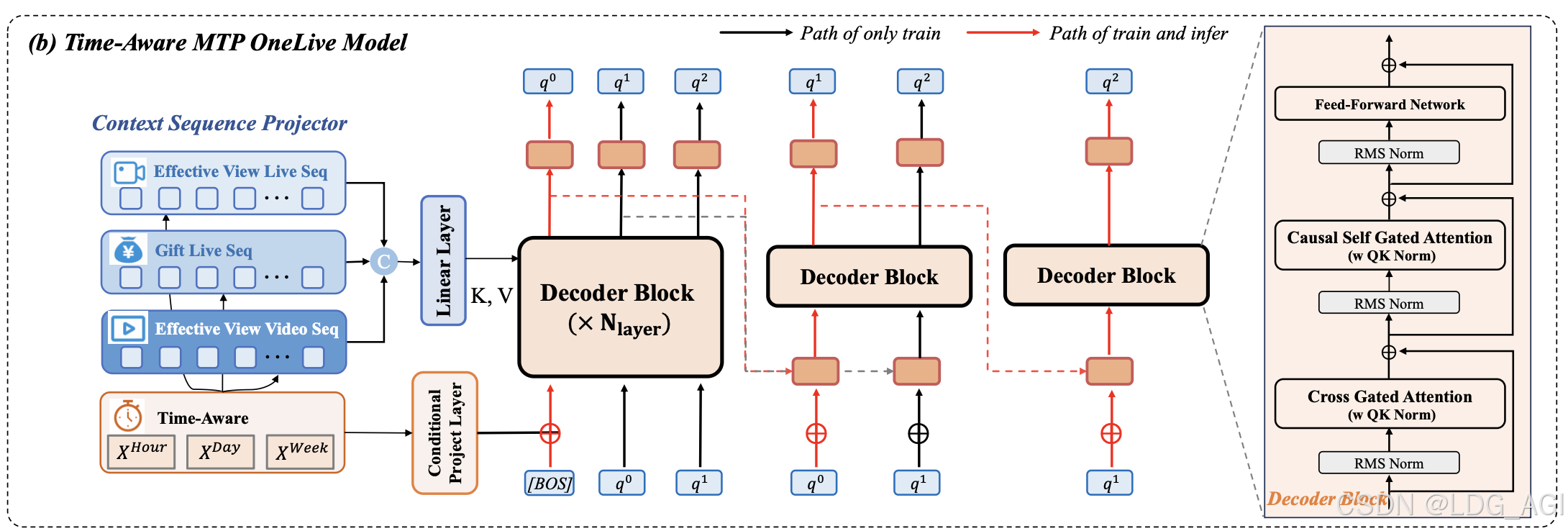
直播推荐本质是时间约束分发问题------仅在线直播可被推荐。OneLive从三层面注入时序感知:
| 时序感知维度 | 实现机制 | 作用 |
|---|---|---|
| 历史序列时序感知 | 为每个历史Item注入小时/日/周粒度时间偏置 | 捕捉用户时序兴趣漂移 |
| 生成锚点时序感知 | 在BOS Token融合查询时刻多粒度时间特征 | 实现时间条件化生成 |
| 注意力门控时序感知 | 引入门控机制动态调节注意力权重: Score(X) = σ(XW_θ) |
自适应强调时效相关上下文 |
💡 效果验证 :消融实验表明,仅门控注意力无显著增益(+0.98%),但结合时序特征后推理有效率提升14.29%(避免推荐已下播直播)。
3.3 序列多Token预测(Sequential MTP)+ QK Norm
3.3.1 推理加速:Sequential MTP
标准自回归生成需3次前向传播(q₀→q₁→q₂),计算开销大。OneLive设计级联轻量化解码器:
- 主解码器:完整L层Transformer,生成q₀
- 轻量子解码器:共享首层KV Cache的单层Block,分别生成q₁、q₂
BOS + Context
Main Decoder L layers
q₀ Prediction
Lite Decoder 1 layer
q₁ Prediction
Lite Decoder 1 layer
q₂ Prediction
性能收益(表4):
- 6层模型:QPS提升62.0%,P99延迟从13.34ms降至5.04ms
- 3层模型:QPS提升31.8%,平均延迟降低55.45%
3.3.2 训练稳定性:QK Norm
深层模型训练中QK logits易爆炸(图3),导致Softmax饱和与梯度消失。OneLive引入RMSNorm归一化:
Attn ( Q , K , V ) = Softmax ( RMSNorm ( Q ) RMSNorm ( K ) T d ) V \text{Attn}(Q,K,V) = \text{Softmax}\left(\frac{\text{RMSNorm}(Q)\text{RMSNorm}(K)^T}{\sqrt{d}}\right)V Attn(Q,K,V)=Softmax(d RMSNorm(Q)RMSNorm(K)T)V
✅ 效果:消除训练中偶发的Loss尖峰,保障bf16混合精度下深层模型稳定收敛。
3.4 多目标对齐强化学习框架
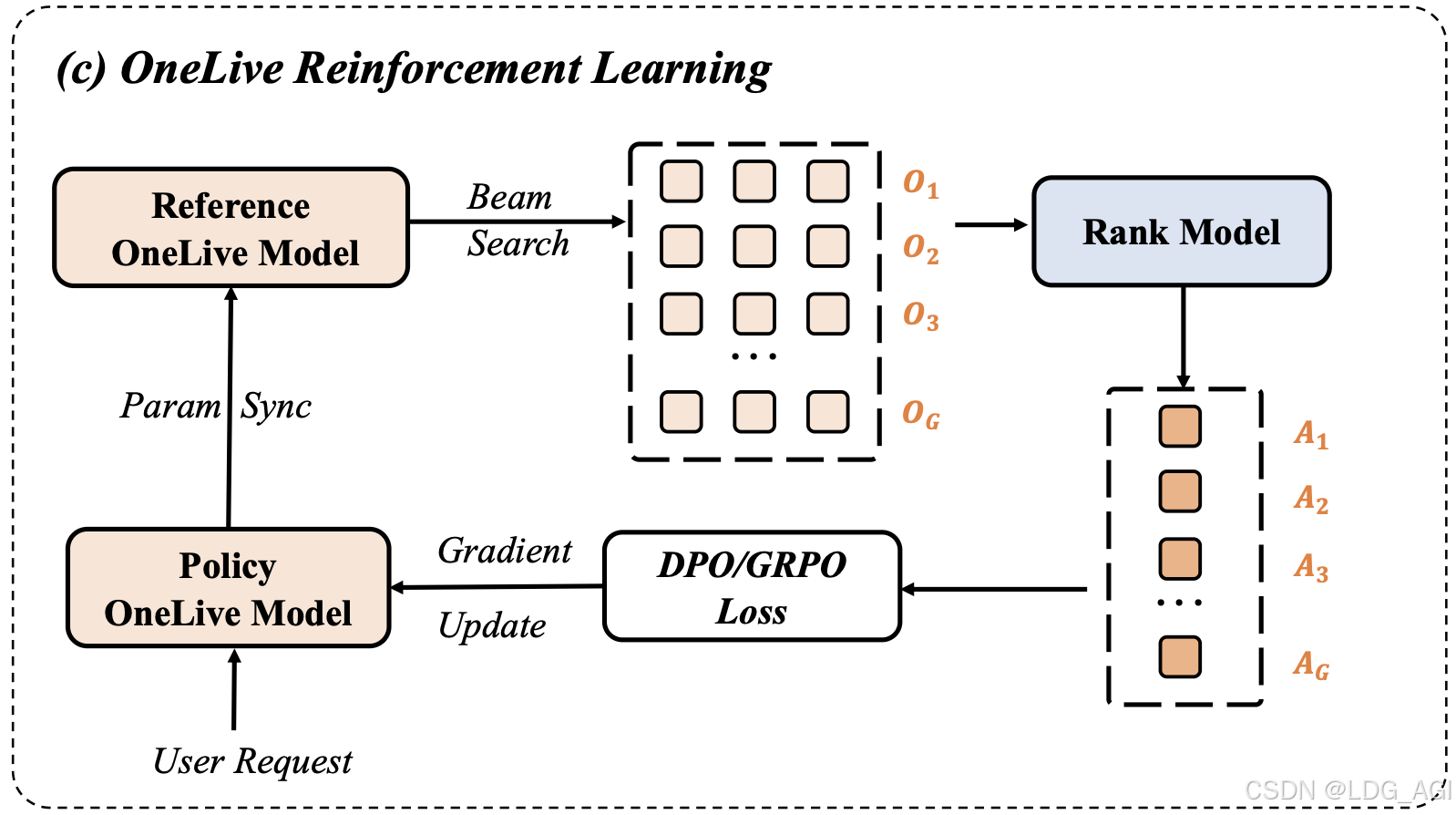
单纯行为克隆(Behavior Cloning)受限于历史策略天花板。OneLive采用Pantheon多目标集成排序模型作为奖励函数:
r = Pantheon ( User , Author ) = ∑ XTR ∈ { CTR,LVTR,GTR } w XTR ⋅ Score XTR r = \text{Pantheon}(\text{User}, \text{Author}) = \sum_{\text{XTR} \in \{\text{CTR,LVTR,GTR}\}} w_{\text{XTR}} \cdot \text{Score}_{\text{XTR}} r=Pantheon(User,Author)=XTR∈{CTR,LVTR,GTR}∑wXTR⋅ScoreXTR
对比DPO与GRPO优化策略(表5):
- GRPO优势:利用组内所有候选的相对优势进行优化,在Top64/Top256均带来**+6.88% LVTR**提升
- DPO局限:仅依赖正负样本对,在小Beam Size下易受噪声干扰
🔑 关键设计 :仅1%查询触发RL训练,平衡稳定性与探索性,最终损失函数:
L OneLive = L MTP + w ⋅ L RL L_{\text{OneLive}} = L_{\text{MTP}} + w \cdot L_{\text{RL}} LOneLive=LMTP+w⋅LRL
四. 实验验证:离线与在线双重验证
4.1 离线指标全面领先
表2显示,OneLive在长播/点击双场景下显著超越基线:
- HR@128提升16.70%(vs OneRec)
- MRR@128提升14.26%
- 甚至超越精心设计的ANN检索架构(KuaiFormer/GNN)
4.2 在线A/B测试:真实业务增益
在快手主站与快手极速版全量部署近1个月(表6):
| 应用 | 曝光量 | CTR | 点击量 | 观看时长 | 关注 |
|---|---|---|---|---|---|
| 快手主站 | +1.32% | +0.41% | +1.73% | +0.58% | +1.36% |
| 快手极速版 | +1.96% | +0.72% | +2.70% | +0.41% | +2.07% |
分层测试亮点(图5):
- 低活用户增益最显著(曝光+3.2%),缓解级联架构的长尾忽视问题
- 核心付费用户同样获益,证明模型泛化能力
4.3 模型缩放定律验证
图4显示,随着参数量增加(0.02B→0.16B),Loss持续下降但边际收益递减,最终选择0.08B版本平衡效果与部署成本。
五. 行业价值与技术启示
5.1 范式转变意义
- 打破级联架构:端到端生成式框架消除阶段间信息瓶颈,实现全局优化
- 动态场景适配:为实时内容演化场景(如直播、实时新闻)提供可复用技术范式
- 工程-算法协同:Sequential MTP与QK Norm证明,推理优化与训练稳定性需算法层面创新
5.2 工业落地关键经验
| 挑战 | 解决方案 | 启示 |
|---|---|---|
| 动态内容表征 | 30秒滑动窗口+协同信号后对齐 | 实时性与表征质量需精细权衡 |
| 推理延迟 | 参数共享+KV Cache复用 | 轻量化解码器设计比单纯模型压缩更有效 |
| 多目标冲突 | 集成排序模型替代手工加权 | 用户异构偏好需数据驱动融合 |
六. 未来展望
OneLive已服务4亿日活用户,但仍有探索空间:
- 跨模态生成增强:结合LLM推理能力预测直播内容演化趋势(如LiveForesighter工作)
- 稀疏-稠密统一表示:融合COBRA等稀疏表示技术,进一步提升长尾覆盖
- 因果推断整合:区分相关性与因果性,缓解直播"马太效应"
结语:OneLive不仅是技术方案创新,更是推荐系统从"级联判别"到"端到端生成"范式迁移的关键里程碑。其成功验证了生成式架构在严苛工业场景的可行性,为实时动态内容分发开辟了新路径。
参考文献
1 Wang S., et al. OneLive: Dynamically Unified Generative Framework for Live-Streaming Recommendation. arXiv:2602.08612, 2026.
2 Deng J., et al. OneRec: Unifying Retrieve and Rank with Generative Recommender. arXiv:2502.18965, 2025.
3 Rajput S., et al. Recommender Systems with Generative Retrieval. NeurIPS 2023.