人工智能不仅在棋类游戏上展现出强大的智力,还能打电子游戏。这两者有相似之处:它们都需要在对战中学习战胜对手的技能,因此都适合强化学习。不同之处在于游戏环境更复杂、不确定性更强。特别是像《星际争霸》这种开放环境下的多人对战游戏,需要机器掌握更复杂的策略。本节将探讨人工智能打游戏背后的基本原理,并重温强化学习方法。
打游戏 VS. 下棋
对机器而言,打游戏和下棋在本质上相似,都是在特定状态下学习行为策略,只不过面对的场景不同。下棋时,机器看到的是当前棋盘,需要分析棋盘局势和对手的可能应对,选择收益最大的走棋步骤,反馈是"是否获胜"。在电子游戏中,机器看到的是游戏画面,需要通过画面确定最有利的行动方式,反馈则是"得分多少"或"是否通关"。
总体来看,电子游戏的复杂度远高于棋类游戏。机器必须应对快速变化的环境并做出实时决策,这对状态评估和动作选择提出了更高要求。
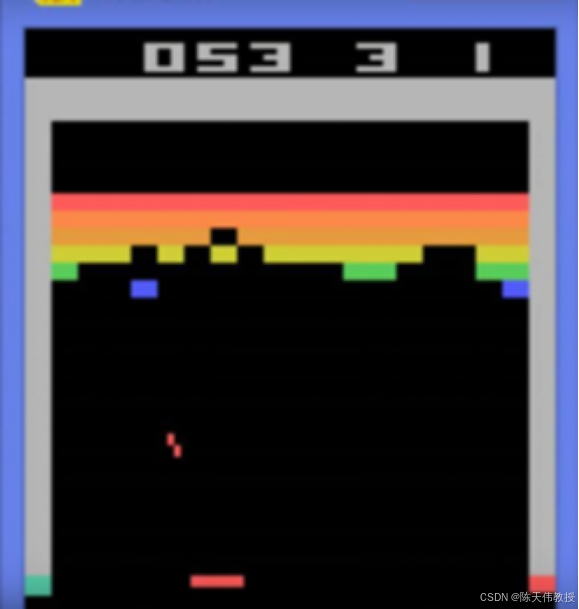
例如,在经典的《Breakout》游戏中,玩家控制一个托板接住掉落的小球,使其反弹并击碎彩色壁板,得分取决于击碎的壁板数量。要掌握这款游戏,机器首先需要"观察"屏幕,准确识别小球和托板的位置、壁板的破裂情况等。基于这些观察,机器还需要实时预测小球轨迹,并迅速生成控制托板的动作,以确保小球不会掉落。