总目录 大模型相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://arxiv.org/pdf/2601.10825
https://www.doubao.com/chat/38410792270930946
https://www.bilibili.com/video/BV1NsFNzrETC
速览
一段话总结
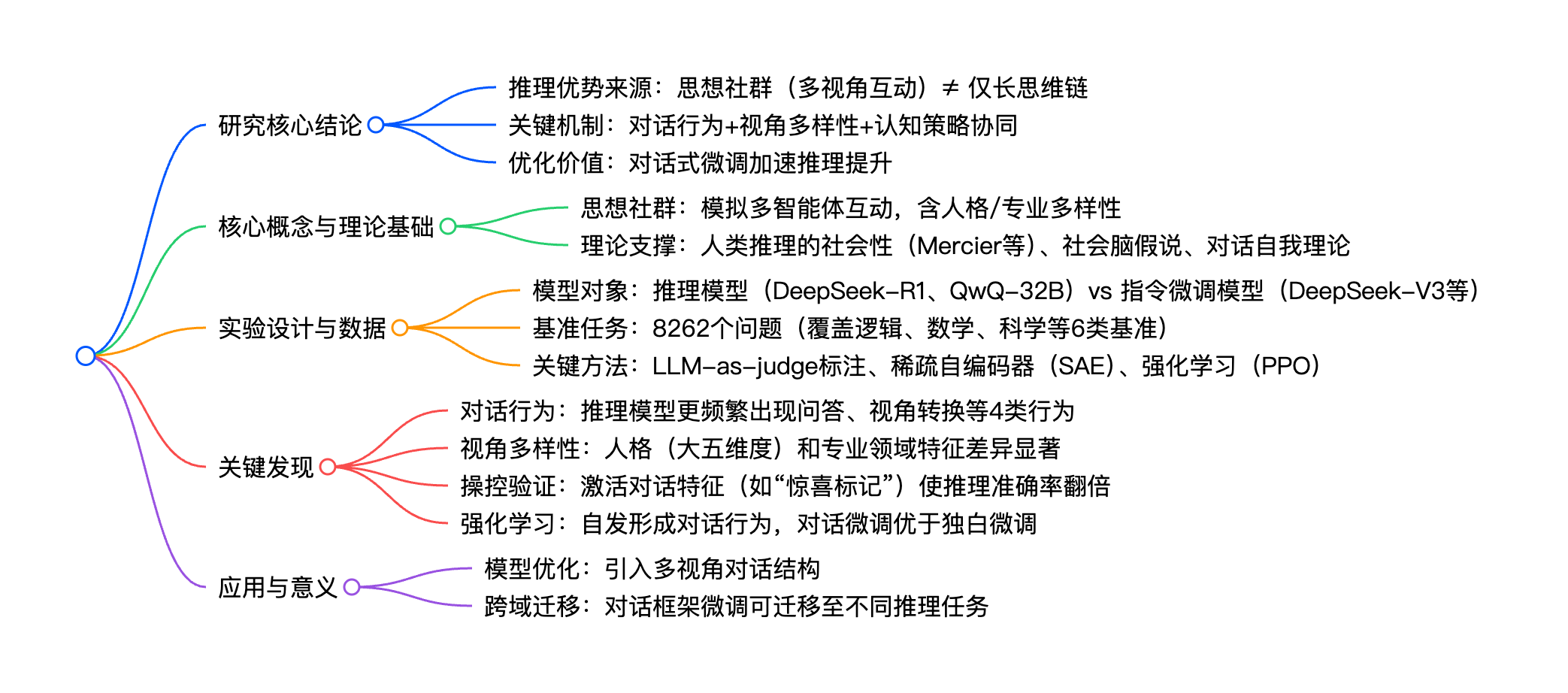
该研究揭示,DeepSeek-R1、QwQ-32B等推理模型的卓越推理能力并非仅源于更长的思维链,核心在于其隐含模拟的**"思想社群"(society of thought)** ------通过多视角互动(含问答、视角转换、观点冲突与调和)、多样化的人格与专业领域特征,以及对话式行为,直接或间接促进验证、回溯等认知策略,提升推理准确性;强化学习实验表明,模型在仅以准确性为奖励时会自发形成对话行为,且基于对话框架微调比独白式微调能更快提升推理性能,这为AI推理的"社会结构化"优化提供了新方向。
思维导图
mindmap
## 研究核心结论
- 推理优势来源:思想社群(多视角互动)≠ 仅长思维链
- 关键机制:对话行为+视角多样性+认知策略协同
- 优化价值:对话式微调加速推理提升
## 核心概念与理论基础
- 思想社群:模拟多智能体互动,含人格/专业多样性
- 理论支撑:人类推理的社会性(Mercier等)、社会脑假说、对话自我理论
## 实验设计与数据
- 模型对象:推理模型(DeepSeek-R1、QwQ-32B)vs 指令微调模型(DeepSeek-V3等)
- 基准任务:8262个问题(覆盖逻辑、数学、科学等6类基准)
- 关键方法:LLM-as-judge标注、稀疏自编码器(SAE)、强化学习(PPO)
## 关键发现
- 对话行为:推理模型更频繁出现问答、视角转换等4类行为
- 视角多样性:人格(大五维度)和专业领域特征差异显著
- 操控验证:激活对话特征(如"惊喜标记")使推理准确率翻倍
- 强化学习:自发形成对话行为,对话微调优于独白微调
## 应用与意义
- 模型优化:引入多视角对话结构
- 跨域迁移:对话框架微调可迁移至不同推理任务详细总结
一、研究背景与核心假设
- 现状与问题:大型语言模型(LLMs)在复杂推理任务中仍有挑战,近期推理增强模型(如DeepSeek-R1)通过长思维链提升准确率,但背后机制未明确,传统观点认为是"更长计算",研究提出新假设。
- 核心假设:推理模型的优势源于隐含模拟"思想社群"------即多智能体式的内部互动,通过多样化视角(人格、专业)的对话与辩论,促进有效推理,而非仅依赖计算长度。
- 理论支撑 :
- 人类推理的社会性:Mercier等提出推理是社会过程,群体通过多样化视角协作提升问题解决能力;
- 认知理论:对话自我理论(Bakhtin)、社会脑假说(Dunbar)认为个体思维本质是内部对话;
- AI领域先例:Minsky"心智社会"理论,多智能体对话可提升LLM准确性与发散思维。
二、实验设计
| 维度 | 具体内容 |
|---|---|
| 模型对比 | 推理模型:DeepSeek-R1(671B)、QwQ-32B; 指令微调模型:DeepSeek-V3(671B)、Qwen-2.5-32B-IT等4个模型(8B-70B参数) |
| 任务数据集 | 8262个推理问题,涵盖6类基准:BigBench Hard、GPQA、MATH(Hard)等,覆盖逻辑、数学、科学推理等 |
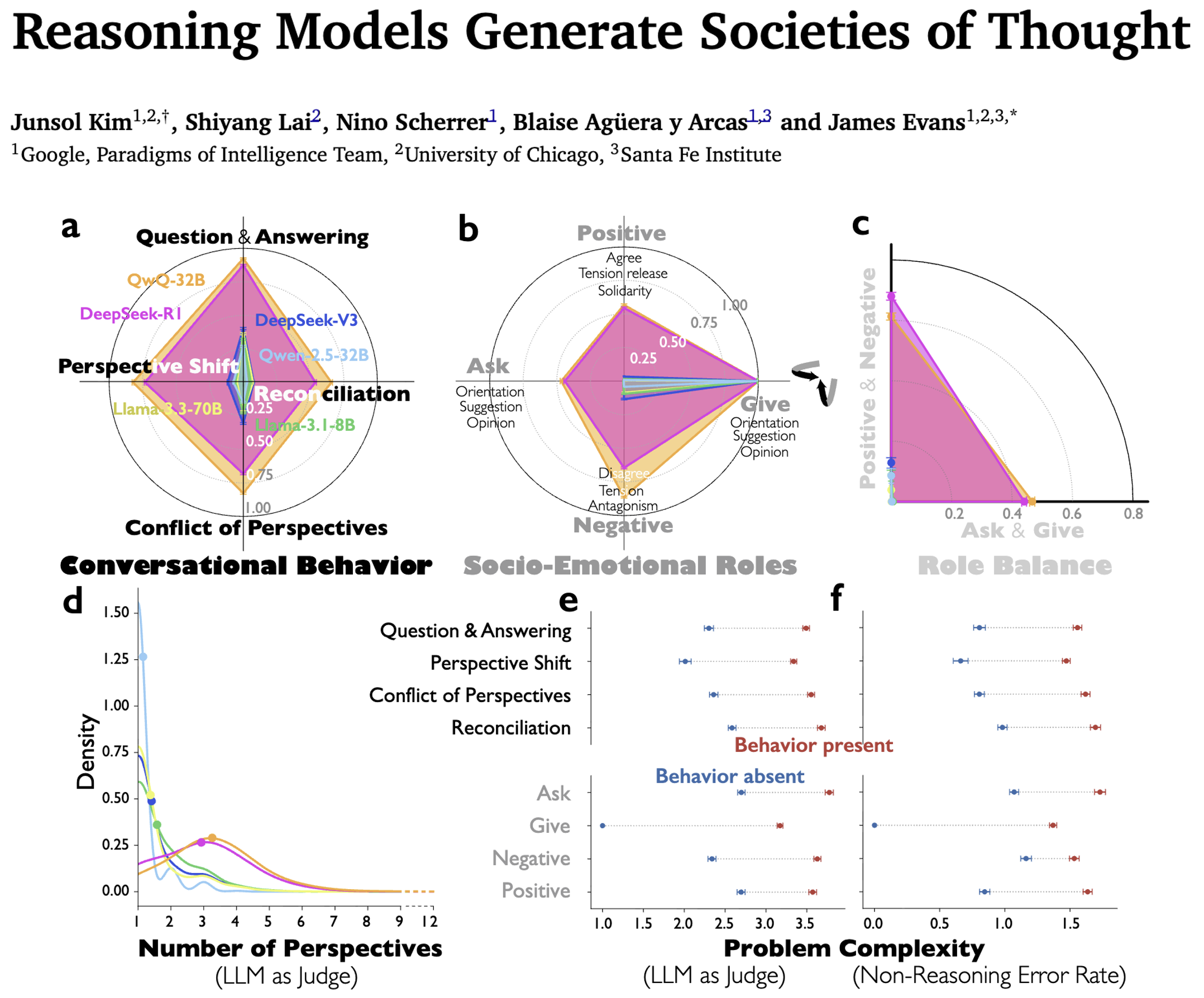
| 关键方法 | 1. LLM-as-judge:标注对话行为、社会情感角色、视角多样性(一致性ICC=0.756-0.939); 2. 稀疏自编码器(SAE):识别模型激活的对话特征; 3. 强化学习(PPO):验证对话行为的自发形成与微调效果 |
| 测量指标 | 1. 对话行为:问答、视角转换、观点冲突、调和; 2. 社会情感角色:基于Bales IPA框架(4类12项,如信息索取/给予、正负情绪); 3. 视角多样性:人格(大五维度)、专业领域(语义嵌入距离); 4. 认知策略:验证、回溯、子目标设定、逆向推理 |
三、关键研究发现
(一)推理模型的对话行为与社会情感角色优势
- 对话行为频率:推理模型显著高于指令微调模型(控制思维链长度后),如DeepSeek-R1的问答行为β=0.345(p<1×10⁻³²³),QwQ-32B的视角转换β=0.378(p<1×10⁻³²³);
- 社会情感角色:推理模型兼具"索取/给予信息""正负情绪"的平衡(Jaccard指数更高),而指令微调模型以"给予信息"为主(单向独白);
- 任务适配性:复杂任务(如GPQA、高阶数学)中对话行为更频繁,简单任务(如布尔表达式)中极少出现。
(二)视角多样性:人格与专业领域的差异化
- 人格多样性:推理模型在神经质(DeepSeek-R1 β=0.567)、宜人性(QwQ-32B β=0.490)等维度差异显著,仅尽责性多样性较低(体现一致性);
- 专业领域多样性:推理模型的专业嵌入距离显著更高(DeepSeek-R1 β=0.179,QwQ-32B β=0.250),涵盖物理、逻辑、金融等多领域;
- 验证:LLM-as-judge能准确识别人类对话中的视角差异(Spearman相关系数ρ=0.86),与真实专业背景一致性ρ=0.55。
(三)对话特征操控与推理准确性的因果关系
- 特征识别:通过SAE找到对话相关特征(如"惊喜标记"Feature 30939,对话占比65.7%,99百分位);
- 操控效果:正向激活该特征使Countdown任务准确率从27.1%提升至54.8%(翻倍),负向激活降至23.8%;
- 作用路径:直接提升解决方案探索效率,同时间接促进认知策略(验证、回溯等),结构方程模型显示直接效应β=0.228,间接效应β=0.066(均p<0.001)。
(四)强化学习实验验证
- 自发形成对话行为:模型仅以"准确性+格式"为奖励(无对话相关奖励),训练中问答、观点冲突等行为显著增加(如Qwen-2.5-3B训练250步后准确率达58%);
- 对话微调优势:基于多智能体对话框架微调的模型,推理提升速度显著快于独白式微调,早期训练(40步)准确率差距达10%(38% vs 28%),且跨域有效(算术任务微调可迁移至虚假信息检测)。
四、研究意义与启示
- 理论意义:揭示AI推理的"社会结构化"本质,建立人类群体智能与AI推理的计算平行性;
- 实践价值:为LLM推理优化提供新方向------通过引入多视角对话框架、增强人格/专业多样性,而非仅增加模型参数或思维链长度;
- 未来方向:探索更复杂的智能体组织形式(如层级、网络结构),进一步释放"群体智慧"在AI推理中的潜力。
关键问题
问题1:推理模型的"思想社群"具体体现为哪些核心行为,与传统指令微调模型的关键差异是什么?
答案:"思想社群"核心体现为四类对话行为(问答、视角转换、观点冲突、调和)和平衡的社会情感角色(兼具信息索取/给予、正负情绪);关键差异在于:推理模型通过多视角互动形成"对话式推理",而传统指令微调模型以"单向独白"为主,缺乏视角多样性与互动性,即使控制思维链长度,对话行为频率仍显著更低(如DeepSeek-R1的调和行为β=0.191,p<1×10⁻¹²⁵)。
问题2:操控对话相关特征对推理准确性有何影响,其作用机制是什么?
答案:正向操控对话特征(如"惊喜标记"Feature 30939)可使多步推理任务准确率翻倍(从27.1%至54.8%),负向操控则降低准确率;作用机制包含两方面:一是直接促进解决方案的有效探索,二是间接激活验证、回溯、子目标设定等关键认知策略,结构方程模型验证直接效应β=0.228、间接效应β=0.066(均p<0.001)。
问题3:强化学习实验中,模型的对话行为是如何形成的?对话式微调相比传统独白式微调有何优势?
答案 :对话行为是模型在仅以"推理准确性+格式"为奖励时自发形成的,无需明确的对话训练信号;对话式微调的优势在于:推理能力提升速度更快,早期训练阶段(如40步)准确率比独白式微调高10%(38% vs 28%),且提升效果可跨域迁移(如算术任务微调后,在虚假信息检测任务中仍表现更优),说明对话框架为推理策略的发现与优化提供了更高效的脚手架。