😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本专栏《人工智能》旨在记录最新的科研前沿,包括
大模型、具身智能、智能体、强化学习等相关领域,期待与你一同探索、学习、进步,一起卷起来叭!🚩Paper:Reasoning Vectors: Transferring Chain-of-Thought Capabilities via Task Arithmetic
💻时间:202509
💭推荐指数:🌟🌟🌟🌟🌟
往期精彩专栏内容,欢迎订阅:
🔗【免训练&测试时推理】20251014:不确定性影响模型输出
🔗【低训练&测试时推理】20251014:测试时针对特定样本进行语言模型优化
🔗【免训练&强化学习】】20250619:训练无关的组相对策略优化
🔗【多智能体&强化学习】20250619:基于统一多模态思维链的奖励模型
🔗【多智能体&强化学习】20250615:构建端到端的自主信息检索代理
🔗【多智能体】20250611:基于嵌套进化算法的多代理工作流
🔗【多智能体】20250610:受木偶戏启发实现多智能体协作编排
🔗【多智能体】20250609:基于LLM自进化多学科团队医疗咨询多智能体框架
🔗【具身智能体】20250608:EvoAgent:针对长时程任务具有持续世界模型的自主进化智能体
介绍
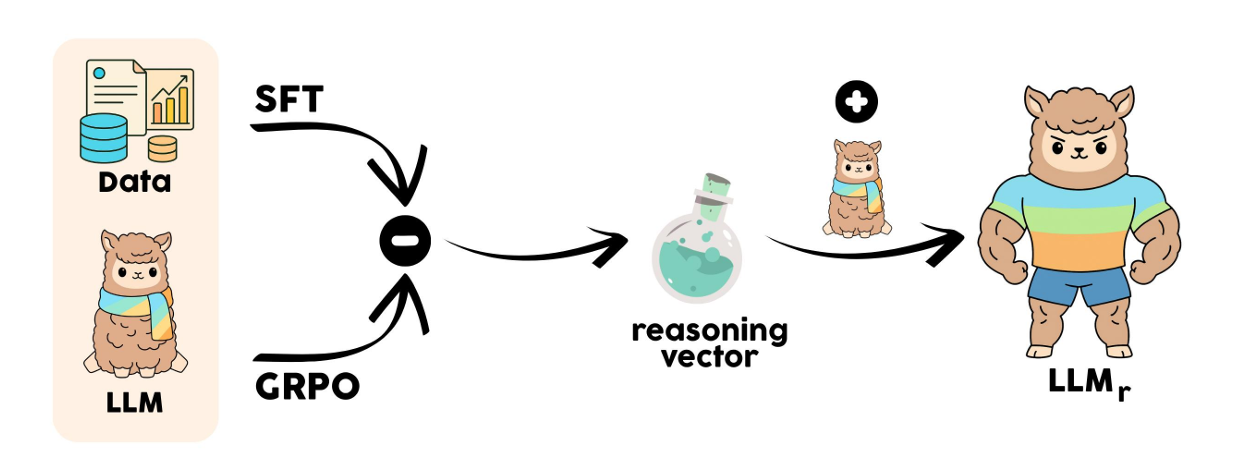
- 研究问题:这篇文章要解决的问题是如何从现有的开源大型语言模型(LLMs)中提取出推理能力,并将其作为任务向量转移到其他模型中,从而增强这些模型的推理能力。
- 研究难点:该问题的研究难点包括:推理能力通常需要通过昂贵的训练方法(如强化学习)来获得,而这些方法需要大量的计算资源和精细的调整;此外,如何确保提取的推理向量能够在不同模型和领域之间有效迁移也是一个挑战。
- 相关工作:该问题的研究相关工作包括:通过提示策略生成推理的方法(如链式思维提示、自一致性、树状思维等)、程序辅助方法(如Program-of-Thought、PAL等)、以及基于训练的方法(如监督微调、强化学习等)。此外,任务算术和模型合并技术也被提出用于表示和转移微调能力。
研究方法
这篇论文提出了通过任务算术提取和转移推理能力的方法。具体来说,
- 模型选择:首先,作者选择了两个初始化和预训练历史相同的公开可用的QWEN2.5模型,一个通过监督微调(SFT)进行优化,另一个通过组相对策略优化(GRPO)进行优化。
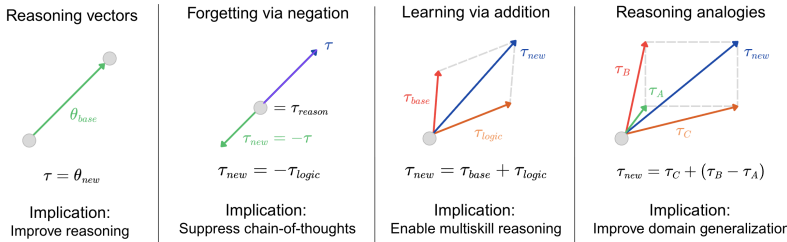
- 推理向量的定义和提取 :定义推理向量 v reason v_{\text{reason}} vreason 为两个模型参数的差: v reason = θ G R P O − θ S F T v_{\text{reason}}=\theta_{GRPO}-\theta_{SFT} vreason=θGRPO−θSFT
该向量旨在隔离由强化学习引入的推理增强参数变化,同时最小化两个模型共享的数据集特定知识的影响。 - 向量的应用 :将推理向量添加到兼容的指令微调模型中,以提高其推理能力: θ enhanced = θ target + α ⋅ v reason \theta_{\text{enhanced}}=\theta_{\text{target}}+\alpha\cdot v_{\text{reason}} θenhanced=θtarget+α⋅vreason其中, α \alpha α是一个控制转移向量幅度的标量系数,可以通过引入二进制掩码 m m m对特定层或模块进行更细粒度的控制:
θ enhanced = θ target + α ⋅ ( m ⊙ v reason ) \theta_{\text{enhanced}}=\theta_{\text{target}}+\alpha\cdot(m\odot v_{\text{reason}}) θenhanced=θtarget+α⋅(m⊙vreason)
实验设计
- 数据收集:使用了公开可用的QWEN2.5模型,参数规模分别为1.5亿和7亿。每个规模下,供体模型包括一个通过SFT在GSM8K训练集上微调的检查点和一个进一步使用GRPO在同一数据集上进行优化的对应模型。
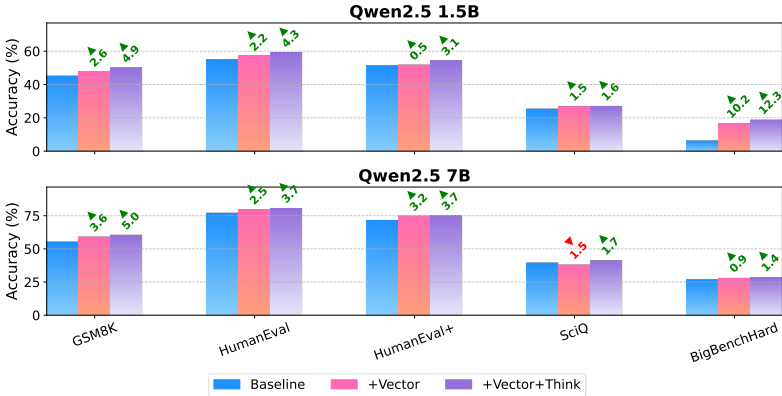
- 实验配置:为了隔离向量和提示的效果,作者在所有基准测试中比较了四种配置:基线模型、GRPO调优的供体模型(G+T)、添加推理向量的基线模型(+Vector)、以及添加推理向量和提示的模型(+Vector+Think)。
- 基准测试:在五个多样化的推理基准上评估性能,包括GSM8K、HumanEval、HumanEval+、SciQ和BigBenchHard。评估协议以准确性为主要指标,对于确定性任务使用贪婪解码,对于创造性生成使用温度为0.5的采样。
结果分析
-
主要结果:添加推理向量通常可以提高模型性能,进一步的收益通常通过添加简单的推理提示获得。例如,对于1.5亿参数的模型,仅添加推理向量使GSM8K的准确性从45.1%提高到47.7%(+2.6%),结合提示后达到50.0%,总提升+4.9%。在其他领域也表现出一致的正向趋势。
-
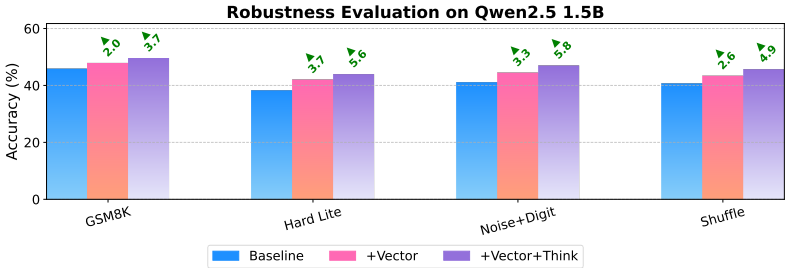
鲁棒性分析:在定制的对抗性修改版本的GSM8K数据集上评估1.5亿参数模型,结果表明推理向量的优势在所有对抗条件下都能保持。即使在注入噪声和结构打乱的情况下,增强模型仍能一致性地优于基线模型。
- 消融研究:通过一系列系统性的消融实验,发现移除推理向量会导致性能急剧下降(例如,GSM8K的准确性从45.1%下降到33.4%,下降了11.8%),而添加推理向量则始终能提高结果。
总体结论
这篇论文证明了推理能力可以作为紧凑的任务向量在兼容模型之间提取和转移。通过隔离SFT和GRPO检查点之间的参数差异,展示了 v reason = θ G R P O − θ S F T v_{\text{reason}}=\theta_{GRPO}-\theta_{SFT} vreason=θGRPO−θSFT 捕获了可迁移的认知能力,并在不同领域具有泛化性。推理行为表现为参数空间中的模块化可转移组件。通过简单的张量操作,这种方法将推理增强从计算密集的训练转变为轻量级的模型编辑,从而在开源AI时代实现了高效的模型增强。
不足与反思
-
架构和初始化约束:方法的成功依赖于供体和目标模型之间的严格兼容性,包括相同的架构、分词器和共享的预训练初始化家族。跨不同模型家族(例如从Llama模型到Qwen模型)的推理向量转移尚未得到保证,仍是一个重要的开放问题。
-
对现有供体模型的依赖:该方法依赖于公开可用的SFT和RL调优供体模型,这些模型的成本很高。方法的适用性与开源模型生态系统的丰富程度密切相关。
📌 [ 笔者 ] 文艺倾年
📃 [ 更新 ] 2026.02.11
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!
