目录
[1.CV领域的Base Model是什么?](#1.CV领域的Base Model是什么?)
(3)Florence模型的分层视觉Transformer架构在具体实现上,是如何平衡感受野大小和计算效率的?
(4)移位窗口机制在扩展感受野的同时,是否会引入新的伪影或边界效应?Florence模型是如何处理这些潜在问题的?
[窗口不连续性伪影 (Window Discontinuity Artifacts):](#窗口不连续性伪影 (Window Discontinuity Artifacts):)
[计算开销和内存冗余 (Computational Overhead & Memory Redundancy):](#计算开销和内存冗余 (Computational Overhead & Memory Redundancy):)
[对齐问题 (Alignment Issues):](#对齐问题 (Alignment Issues):)
[【Florence模型(Swin Transformer)如何处理这些潜在问题】](#【Florence模型(Swin Transformer)如何处理这些潜在问题】)
四、基于Transformer的Florence的预训练模型
一、引言
今天我们要精读的论文来自2021年微软提出的多模态基础模型Florence,可以面向多种视觉任务,本文在多模态大模型领域也是在经典不过的文章了,论文原文地址:Florence: A New Foundation Model for Computer Vision。咱们闲言少叙,让博主带你一起走进多模态大模型中的Florence,一起探讨Florence为何提出,又是为什么这么构思的吧!
二、方法概览与基础定义
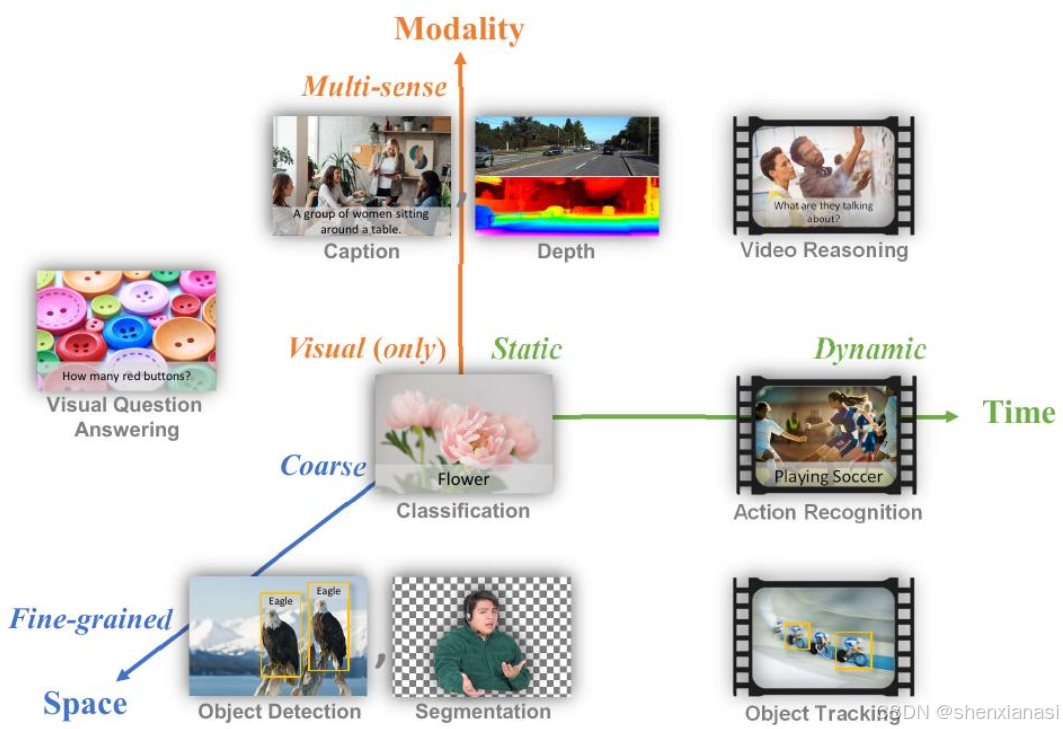
Figure 1. Common computer vision tasks are mapped to a SpaceTime-Modality space. A computer vision foundation model should serve as general purpose vision system for all of these tasks.
1.CV领域的Base Model是什么?
用三个正交轴捕捉问题空间中的任务范围(图1):1)空间:从粗略(例如场景级分类)到细粒度(例如目标检测);2)时间:从静态(例如图像)到动态(例如视频);3)模态:从仅RGB到多种感知(例如图像描述和深度)。
由于视觉理解的多样性本质,将CV领域的Base Model重新定义为一种预训练模型及其适配器,用于解决此空间-时间-模态空间中的所有视觉任务,具有诸如零样本/少样本学习和完全微调等可迁移性。
可迁移性的适配被限制为对预训练基础模型的最小定制,例如继续训练、少量epoch或少量层数的微调,而不会显着增加或改变模型参数。
Florence在嘈杂的网络规模数据上进行端到端训练,并采用统一的目标,从而使该模型在各种基准测试中实现一流的性能。
2.数据整理
由于网络爬取的数据通常是嘈杂的自由文本(例如,单词、短语或句子),为了获得更有效的学习效果,我们考虑了 UniCL,这是一种统一的图像-文本对比学习目标,最近(针对于当时而言的)提出,该方法已证明优于对比学习和监督学习方法。
3.模型预训练
Florence采用双塔结构,包括图像编码器和语言编码器。对于Image Encoder,Florence选择了分层视觉Transformer(例如Swin,CvT,Vision Longformer,Focal Transformer和CSwin),在 继承 了Transformer自注意力操作的性能优势(Dosovitskiy et al., 2021b)的同时,这些分层架构模拟了图像的尺度不变性,并且具有相对于图像大小的线性计算复杂度。
(1)模拟图像尺度不变性
在计算机视觉任务中,图像的尺度变化是一个常见挑战。分层视觉Transformer通过其固有的设计(例如,通过不同层次的处理来聚合多尺度信息),能够有效地模拟和学习图像的尺度不变性 (scale invariance)。这意味着模型能够识别不同大小的目标或特征,而无需对每个尺度进行单独训练。
(2)线性计算复杂度
传统Transformer模型在处理高分辨率图像时,其计算复杂度通常与图像尺寸的平方成正比,这会带来巨大的计算负担。而文中提到的分层架构(如Swin Transformer通过移位窗口机制)则能实现相对于图像大小的线性计算复杂度 。这一特性对于需要处理大尺寸图像的密集预测任务 (dense prediction tasks) ,如目标检测 (object detection)和图像分割 ( segmentation ),是至关重要的,因为它显著降低了计算资源需求并提高了效率。
(3)Florence模型的分层视觉Transformer架构在具体实现上,是如何平衡 感受野 大小和计算效率的?
**【核心机制】:**分层设计与局部-全局注意力
Florence模型通过采用分层(Hierarchical)结构和局部(Local)自注意力结合移位窗口(Shifted Window)机制 ,有效地解决了传统Transformer在处理高分辨率图像时计算复杂度高的问题,同时保证了模型能够捕获不同尺度的信息,即平衡了感受野大小和计算效率。
(1)分层架构(Hierarchical Architecture)
-
设计动机:图像的视觉信息具有天然的层级结构------从像素到边缘、纹理,再到局部对象,最后到整个场景。分层架构模仿了这种自然层级,能够逐步聚合信息,从而在不同层次上获取不同大小的感受野。
-
具体实现:
-
多阶段特征提取:Florence的图像编码器(CoSwin)将图像分成多个阶段(Stage),每个阶段都会降低特征图的分辨率(例如,通过"Patch Merging"操作),并增加通道数。
-
感受野 逐渐扩大 :在早期阶段,模型处理的是高分辨率的局部特征,感受野相对较小。随着进入更深的阶段,特征图分辨率降低,每个特征点代表的原始图像区域变大,从而有效扩大了感受野,能够捕获更宏观的上下文信息。
-
多尺度特征输出:这种分层结构允许模型输出多尺度的特征金字塔(Feature Pyramid),这对于目标检测和语义分割等密集预测任务至关重要,因为这些任务需要同时处理不同大小的目标。
-
(2)局部自注意力与移位窗口机制(Local Self-Attention with Shifted Windows)
这是Swin Transformer(也是CoSwin Transformer的基础)在平衡效率和感受野上的核心创新。
-
设计动机:
-
传统Transformer的挑战 :标准Vision Transformer (ViT) 通常在全局范围内计算自注意力,导致计算复杂度与图像块数量的平方成正比(
,其中 N 是图像块数量)。对于高分辨率图像,这会迅速变得不可接受。
-
局部自注意力的引入:为了降低计算量,可以限制自注意力只在局部窗口内进行。这样,计算复杂度可以降低到与窗口大小相关的线性关系,大大提升了效率。
-
-
具体实现:
-
窗口划分 (Window Partitioning):在每个Transformer块中,图像特征图被均匀地划分为不重叠的固定大小的局部窗口(例如,7×7 像素的窗口)。自注意力计算只在这些独立的窗口内部进行。
-
效率提升 :将 N 个图像块分成 M 个窗口,每个窗口有 k 个图像块,则全局自注意力的
-
感受野 局限:然而,纯粹的局部自注意力意味着不同窗口之间无法直接进行信息交互,从而限制了感受野,无法捕获全局依赖。
-
-
移位窗口机制 (Shifted Window Mechanism):为了解决局部自注意力的感受野局限性,Swin Transformer引入了移位窗口机制。
-
交替使用:在连续的两个Transformer块中,交替使用两种窗口划分方式:
-
标准窗口划分 (W-MSA):将特征图划分为不重叠的窗口。
-
移位窗口划分 (SW-MSA):在前一个块的窗口划分基础上,将窗口整体向某个方向(例如,右下)移动半个窗口大小的距离,形成新的窗口划分。
-
-
信息交互:通过这种移位,原本在不同窗口中的图像块现在可能被划分到同一个移位后的窗口中。这使得在移位窗口中计算自注意力时,能够捕获到跨越前一个块中窗口边界的信息。
-
感受野 扩展 :随着层数的加深,移位窗口机制确保了信息可以在所有窗口之间逐渐传播,从而有效扩展了模型的感受野,使其能够学习到全局的上下文信息,而无需承担全局自注意力的计算成本。
-
-
(3)CoSwin Transformer的卷积嵌入(Convolutional Embedding)
Florence模型特别指出其使用了CoSwin Transformer ,它在Swin Transformer的基础上进行了改进,用卷积嵌入层 (convolutional embedding layers) 替换了原始的Patch Embedding和Patch Merging模块。
-
设计动机:卷积操作在捕获局部特征和保持空间信息方面具有天然优势,且能更好地处理图像的局部结构。
-
具体实现 :通过引入卷积,CoSwin Transformer可以更好地整合局部纹理和结构信息,进一步增强了模型对图像尺度不变性的建模能力,同时卷积操作本身也具有一定的局部感受野,与分层结构相辅相成。
(4)移位窗口机制在扩展 感受野 的同时,是否会引入新的伪影或边界效应?Florence模型是如何处理这些潜在问题的?
【移位窗口机制可能引入的潜在问题】
窗口不连续性伪影 (Window Discontinuity Artifacts):
-
问题:当窗口发生移位时,一个图像区域可能在第一个块中被划分到某个窗口的边缘,而在第二个块中被划分到另一个窗口的边缘。这种在窗口边界处的人为分割和重组,可能导致模型在处理这些边界区域时出现不一致或不自然的特征表示。
-
原因 :自注意力机制在窗口内部是完全连接的,但窗口之间没有直接连接。移位窗口通过"间接"方式实现连接,这种间接性可能在局部引入一些不自然的偏好。
计算开销和 内存 冗余 (Computational Overhead & Memory Redundancy):
-
问题 :为了实现移位窗口内的自注意力计算,通常需要对特征图进行循环移位 (cyclic shift) 操作,并将特征图进行填充 (padding) 以保持窗口数量。这会引入额外的计算和内存开销。
-
原因 :移位后,如果直接对每个窗口进行计算,窗口数量会增加。为了保持窗口数量不变,Swin Transformer通常采用"循环移位"并结合掩码 (masking) 的方式,将不属于同一逻辑窗口的区域标记为不可见,但这本身也增加了操作的复杂性。
对齐问题 (Alignment Issues):
-
问题:移位窗口的目的是让不同窗口中的元素能够相互作用。但如果移位不当或窗口大小选择不合适,可能无法最优地捕获所有有用的跨窗口依赖,或者引入不必要的噪声连接。
-
原因:窗口大小和移位步长是超参数,需要精心设计以适应图像的尺度和内容的特性。
【Florence模型(Swin Transformer)如何处理这些潜在问题】
Florence模型基于Swin Transformer,其设计中已经考虑并采取措施来缓解上述问题:
1.通过 掩码机制****处理窗口不连续性伪影和计算开销
-
解决方案:高效的批量计算与注意力掩码 (Efficient Batching with Attention Masking)
-
核心思想 :为了避免在移位后处理零填充(zero-padding)带来的额外计算,Swin Transformer(以及Florence的CoSwin)采用了循环移位 (cyclic shift) 的策略。这意味着特征图在空间维度上是周期性移位的。
-
具体操作:
-
循环移位:将特征图沿水平和垂直方向循环移位。这样,移位后的窗口仍然是规整的,没有额外的填充。
-
注意力掩码 (Attention Mask) :在计算自注意力时,引入一个注意力掩码 。这个掩码的目的是阻止不同原始窗口的元素在移位后的窗口中进行注意力计算 。换句话说,即使通过循环移位后,原本不属于同一个"逻辑"窗口的像素被物理地放在了同一个计算窗口中,注意力掩码也会确保它们之间不会相互作用。
-
-
效果:
-
避免伪影 :通过注意力掩码,模型明确地将不同原始窗口的元素隔离开来,防止了在人为拼接区域进行不自然的特征融合,从而避免了窗口不连续性导致的伪影。
-
维持计算效率:循环移位避免了稀疏填充,使得所有窗口可以高效地进行批量计算。注意力掩码虽然引入了额外的逻辑,但它是在注意力分数计算阶段进行的,通常不会显著增加计算瓶颈。
-
-
2.分层架构和多阶段融合缓解对齐问题
-
解决方案:多尺度特征聚合 (Multi-scale Feature Aggregation)
-
核心思想:分层架构本身提供了一种鲁棒性。即使在某个特定窗口大小或移位步长下存在次优的对齐,模型在不同层次上捕获的特征以及后续的融合操作可以弥补这些局部不足。
-
具体操作:
-
不同阶段的窗口大小:虽然论文没有明确指出,但通常情况下,Swin Transformer在不同阶段会使用相对尺寸的窗口(例如,在分辨率降低的深层,窗口可能覆盖更大的原始图像区域)。
-
特征金字塔 :Florence的CoSwin输出特征金字塔,用于下游任务(如目标检测的Dynamic Head)。这意味着不同尺度(分辨率)的特征会被融合利用,可以缓解单一窗口尺寸选择不当带来的问题。
-
-
3.大规模预训练和数据多样性
-
解决方案:数据驱动的 鲁棒性 (Data-driven Robustness)
-
核心思想:Florence在9亿图像-文本对的Web-scale数据集(FLD-900M)上进行预训练。如此大规模和多样化的数据,使得模型能够学习到非常泛化和鲁棒的视觉表示。
-
具体操作:
-
强大的泛化能力:在海量数据上训练的模型,能够更好地理解图像的真实结构和上下文,即使在窗口边界处存在轻微的"人工痕迹",模型也能通过其强大的泛化能力将其视为一种数据变体并学会鲁棒处理。
-
减少对特定窗口配置的敏感性:广泛的视觉模式暴露有助于模型减少对特定窗口划分模式的过度依赖,使其对局部结构的不完美处理更加不敏感。
-
-
4.损失函数 和下游任务适应性
-
解决方案:任务导向的优化 (Task-Oriented Optimization )
-
核心思想:Florence采用统一的对比学习目标 (UniCL) 进行预训练,其目标是学习判别性强的图像-文本表示。在下游任务微调时,模型会根据任务特定的损失函数进一步优化。
-
具体操作:
-
对比学习的 鲁棒性:对比学习鼓励模型将语义相似的样本拉近,语义不相似的样本推远。这种高层次的语义对齐目标,有助于模型学习到对局部扰动或边界效应不敏感的特征。
-
适配器 微调:Florence通过特定的适配器(如Dynamic Head for object detection, METER for V+L tasks)适应下游任务。这些适配器本身可以学习如何有效地利用CoSwin提供的特征,包括处理可能存在的局部不一致性。
-
-
综上,移位窗口机制确实有引入伪影或边界效应的理论可能性。但Florence模型(及其基础Swin Transformer)通过注意力掩码(配合循环移位)来显式阻止不合理的信息交互,通过分层结构和多尺度融合来提高鲁棒性,并通过大规模数据预训练来增强泛化能力,以及通过下游任务的优化,有效地处理和缓解了这些潜在问题,使其成为一个高效且高性能的视觉基础模型。
三、统一的图像-文本对比学习
1.存在问题及解决办法
CLIP隐式地假设每个图像-文本对都有其唯一的标题,这使得其他标题可以被视为负例。然而,在网络规模的数据中,多个图像可能与相同的标题相关联。例如,在 FLD-900M 中,有 3.5 亿个图像-文本对,其中多个图像对应于一个相同的文本,并且与同一文本相关联的所有图像都可以被视为对比学习中的正例对。
Florence在图像-标签-描述空间中进行预训练。给定一个图像-文本对,我们通过文本哈希表生成一个三元组(x, t, y),其中x是图像,t是语言描述(即,哈希值),y是语言标签(即,哈希键),表示数据集中唯一语言描述的索引。
只将相同的语言描述映射到相同的哈希键,即,语言标签。因此,所有映射到相同标签y的图像-文本对都被视为通用图像-文本对比学习中的正例。其他的仍然被视为负例。
我们的经验性实验表明,与简短的描述(例如,一两个词)相比,内容丰富的长语言描述更有利于图像-文本表征学习。我们必须通过生成提示模板(如"一张WORD的照片"、"一张WORD的裁剪照片")作为数据增强来丰富简短的描述。在训练期间,我们随机选择一个模板来为每个简短的语言描述生成t。
2.研究方法
在第一阶段,我们使用包括增强文本在内的所有数据进行训练;而在第二阶段,我们排除所有增强数据以继续训练。
四、基于Transformer的Florence的预训练模型
Florence预训练模型采用双塔结构:
一个12层的Transformer作为Text Encoder,类似于CLIP,以及一个分层ViT作为Image Encoder。分层ViT是一个改进的Swin Transformer(CoSwin Transformer),将 Swin Transformer中的 patch embedding 和 patch merging 模块替换为 CvT 中描述的卷积嵌入层。
使用带有全局平均池化的 CoSwin Transformer 来提取图像特征。在图像编码器和语言编码器的顶部添加了两个线性投影层,以匹配图像和语言特征的维度。
五、对象级别的视觉表征学习
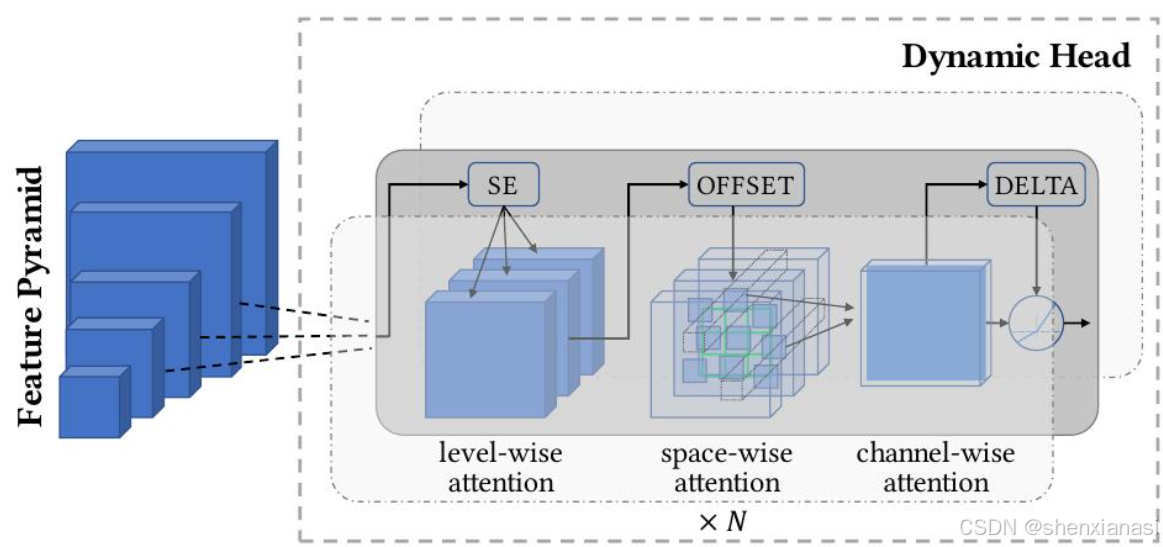
向预训练图像编码器(即,CoSwin)添加了一个适配器 Dynamic Head (或 Dynamic DETR),这是一种用于检测头的统一注意力机制,可以继续从粗略(场景)到精细(对象)进行视觉表示学习。
基于图像编码器CoSwin-H的层级结构,可以从不同的尺度级别获得输出特征金字塔。特征金字塔尺度级别可以被连接并缩小或放大成一个三维张量,其维度为层级×空间×通道。
Dynamic Head的关键思想是部署三种注意力机制,每种机制作用于张量 的一个正交维度 上,即层级层面、空间层面和通道层面。与在此张量上构建单一自注意力机制相比,Dynamic Head使计算更经济,并能实现更有效的学习。上述三种注意力机制是依次应用的,可以有效地堆叠由这三种注意力层组成的多个块
六、细粒度的V+L表征学习
使用METER适配器来扩展到细粒度的视觉-语言表示。
在 Florence V+L 适配模型中,将 METER的图像编码器替换为 Florence 预训练模型 CoSwin,并使用预训练的 Roberta作为语言编码器
Florence 预训练语言编码器可以用于此适配器,因为它采用了基于 BERT 的架构。然后,将这两种模态融合在一起,以通过基于协同注意力的 Transformer 网络学习上下文表示。协同注意力模型(下图)允许将文本和视觉特征分别馈送到两个 Transformer 中,并且每个顶部 Transformer 编码层由一个自注意力块、一个交叉注意力块和一个前馈网络块组成。
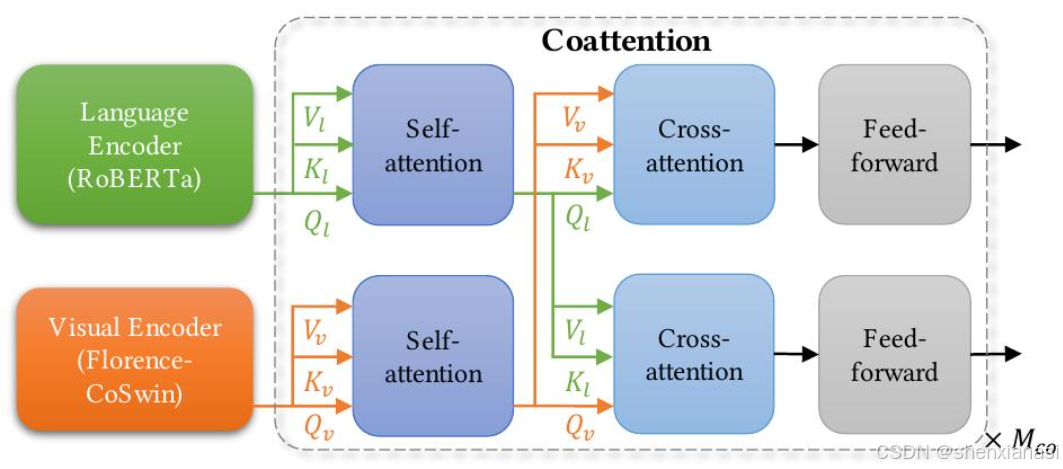
METER被用作 Florence V+L 适配模型,使用图像-文本匹配 (ITM) 损失和掩码语言建模 (MLM) 损失进行训练。
首先训练模型通过图像-文本匹配损失和掩码语言建模损失,然后,在下游任务上微调模型,例如VQA任务。
七、视频识别的适配
Transformer中基于自注意力机制的设计使其能够统一图像和视频识别系统。Video CoSwin适配器可以从CoSwin借用图像编码器用于视频领域,且只需进行最小的改动,类似于先前的工作。首先,图像标记化层 被替换为视频标记化层 。相应地,视频CoSwin将CoSwin(在第2.3节中)的标记化层从2D卷积层替换为3D卷积层 ,这会将每个3D管转换为一个标记。作为3D卷积权重的初始化,CoSwin的预训练2D卷积权重沿时间维度复制,并除以时间核大小,以保持输出的均值和 方差 不变 。其次,视频CoSwin使用基于3D卷积的patch merging算子 ,而不是2D patch merging算子。这种重叠的标记合并可以增强标记之间的空间和时间交互 。第三,遵循先前的工作,用自注意力层中的3D移位局部窗口 替换2D移位窗口设计。沿时间维度复制来自预训练CoSwin的2D相对位置嵌入矩阵,以初始化3D位置嵌入矩阵。这样,对于每个时间偏移,2D相对位置嵌入都是相同的。此外,所有其他层和权重(包括自注意力、FFN)都可以直接从预训练的CoSwin继承。为了缓解视频训练中的内存问题,采用了动态窗口大小策略 ,即在CoSwin的早期阶段使用相对较小的窗口大小,而在其后期阶段使用较大的窗口大小。
八、说明
本文仅仅是本人在读这篇Paper时的一点理解以及对我的一些疑惑解答后的整理总结,希望能够帮助大家真正深刻的理解Florence,帮助大家找到好的idea。如果大家觉得有所帮助的话,欢迎大家一键三连;如果觉得哪里有什么问题,欢迎评论区交流一下!