https://openai.com/index/introducing-gpt-5-3-codex-spark/
今天我们发布研究预览版GPT-5.3-Codex-Spark,这是GPT-5.3-Codex的精简版本,也是我们首个专为实时编程设计的模型。Codex-Spark标志着与Cerebras合作的首个里程碑(今年一月宣布)。该模型经优化可在超低延迟硬件上实现近即时响应------每秒生成超1000个token的同时,仍保持强大的实际编程任务处理能力。
我们将通过Cerebras平台向ChatGPT Pro用户开放Codex-Spark研究预览版,以便开发者在早期就能进行测试。与此同时,我们正与Cerebras合作提升数据中心容量、优化端到端用户体验,并为部署更大规模的尖端模型做准备。
我们最新的尖端模型在长时间任务处理方面表现突出,能自主运行数小时、数天甚至数周无需干预。Codex-Spark是首款专为与Codex实时协作设计的模型------可即时执行针对性编辑、逻辑重构或界面优化并立即查看结果。通过Codex-Spark,Codex现在既能处理长期复杂任务,也能完成即时工作。我们期待通过开发者的使用反馈来持续改进,并逐步扩大访问范围。
首发版Codex-Spark支持128k上下文窗口且仅限文本处理。在研究预览期间,该模型将采用独立频控机制,其使用量不计入标准频控统计。但在高负载时段,为保证服务稳定性,用户可能会遇到访问限制或临时排队情况。
速度与智能
Codex-Spark专为交互式工作优化,在响应速度与智能表现上同样出色。您可以实时与模型协作,在其运行过程中随时打断或调整方向,并通过近乎即时的反馈快速迭代。由于专注于速度优化,Codex-Spark默认采用轻量化工作模式:仅进行最小限度的针对性编辑,且除非您明确要求,否则不会自动运行测试。
编程
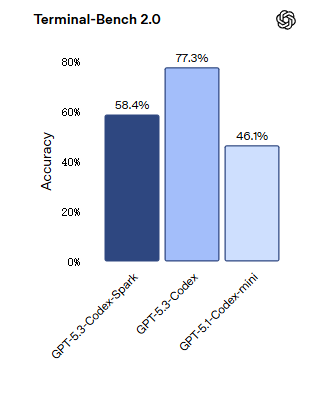
Codex-Spark是一款高性能的小型模型,专为快速推理优化。在评估智能体软件工程能力的SWE-Bench Pro和Terminal-Bench 2.0两项基准测试中,GPT-5.3-Codex-Spark展现出强劲性能,同时完成任务所需时间仅为GPT-5.3-Codex的一小部分。
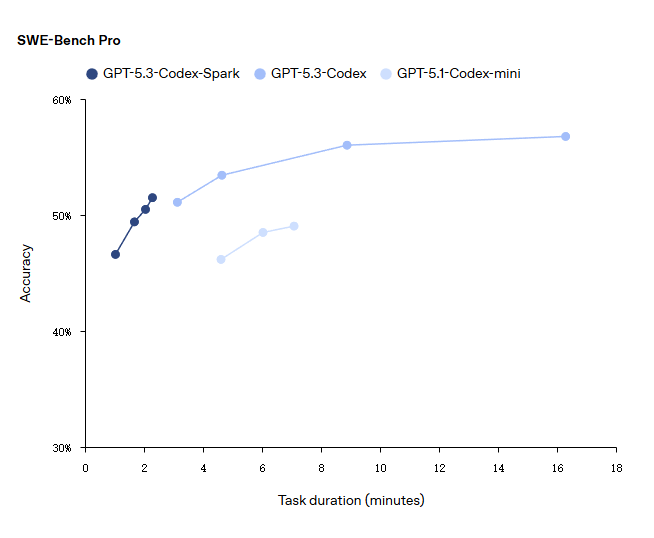
持续时间估算为以下四项之和:(1) 输出生成时间(输出令牌数 ÷ 采样速度);(2) 预填充时间(预填充令牌数 ÷ 预填充速度);(3) 工具总执行时间;(4) 网络总开销。
全模型延迟优化
在训练Codex-Spark过程中,我们发现模型速度只是实时协作环节的一部分------还需要降低整个请求-响应管道的延迟。我们在框架中实施了端到端延迟优化措施,这将使所有模型受益。具体而言,我们优化了客户端与服务器之间的响应流传输机制,重写了推理栈的关键组件,并改进了会话初始化方式,使得首个可见标记更快出现,且Codex在迭代过程中始终保持响应能力。通过引入持久化WebSocket连接及针对性优化Responses API内部机制,我们将每次客户端/服务器往返开销降低80%,单标记处理开销减少30%,首标记生成时间缩短50%。该WebSocket路径默认已在Codex-Spark启用,并将很快成为所有模型的默认配置。
Powered by Cerebras
Codex-Spark运行在Cerebras公司的Wafer Scale Engine 3上------这是一个专为高速推理设计的人工智能加速器,为Codex提供优先考虑低延迟的服务层级。我们与Cerebras合作,将这个低延迟路径添加到与我们整个服务集群相同的生产服务栈中,因此它可以无缝地在Codex上运行,并为我们支持未来模型做好准备。
"关于GPT-5.3-Codex-Spark最让我们兴奋的是能与OpenAI和开发者社区合作,共同探索快速推理带来的可能性------新的交互模式、新的应用场景以及全然不同的模型体验。本次预览仅仅是个开始。"
--- Sean Lie, CTO and Co-Founder of Cerebras
GPU在我们整个训练和推理流程中仍发挥着基础性作用,能为广泛使用场景提供最具成本效益的计算单元。Cerebras系统则通过擅长处理需要极低延迟的工作流来强化这一基础架构,它能缩短端到端处理回路,使您在迭代时明显感受到Codex响应更迅捷。针对单一工作负载,我们可协同使用GPU与Cerebras系统以达到最佳性能表现。
可用性与详情
Codex-Spark今日起作为研究预览版,面向最新版Codex应用、CLI及VS Code扩展中的ChatGPT Pro用户开放。由于运行在专用低延迟硬件上,其使用受独立速率限制管控,在研究预览期间可能根据需求调整。此外,我们正通过API向少量设计合作伙伴开放Codex-Spark,以了解开发者如何将其集成至产品中。随着我们在真实工作负载下持续优化集成方案,未来数周将逐步扩大访问范围。
当前Codex-Spark仅支持文本处理,上下文窗口为128k,是超快模型家族的首个成员。通过与开发者社区共同探索快模型在编码场景的优势后,我们将引入更多功能------包括更大模型、更长上下文及多模态输入。
Codex-Spark采用与主线模型相同的安全训练机制,包含网络安全相关训练。经标准部署流程评估(含网络安全等基线能力测试),我们确认其达到网络安全或生物领域高能力预备框架阈值的可能性微乎其微。
未来展望
Codex-Spark是实现双模式Codex的第一步:既支持长周期推理与执行,也支持快速迭代的实时协作。未来两种模式将融合------Codex既能保持紧密的交互循环,又能将耗时任务委派给后台子代理;当需要广度与速度时,可并行分发任务至多个模型,用户无需预先选择单一模式。
随着模型能力提升,交互速度已成明显瓶颈。超快推理技术将压缩这一循环,使Codex使用体验更自然,助力任何人将创意转化为可运行软件。