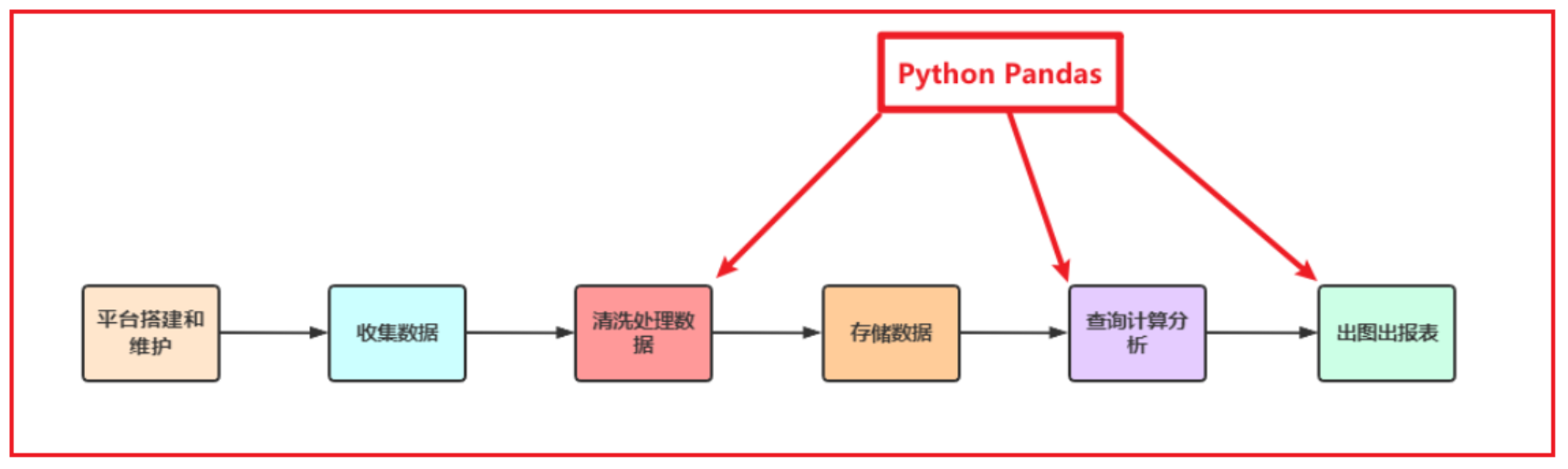
Python在数据处理上独步天下:代码灵活、开发快速;尤其是Python的Pandas包,无论是在数据分析领域、还是大数据开发场景中都具有显著的优势:
Pandas是Python的一个第三方包,也是商业和工程领域最流行的结构化数据工具集,用于数据清洗、处理以及分析
Pandas在数据处理上具有独特的优势:
底层是基于Numpy构建的,所以运行速度特别的快
有专门的处理缺失数据的API
强大而灵活的分组、聚合、转换功能
适用场景:
数据量大到Excel严重卡顿,且又都是单机数据的时候,我们使用Pandas
- Pandas用于处理单机数据(小数据集(相对于大数据来说))
在大数据ETL数据仓库中,对数据进行清洗及处理的环节使用Pandas
1.pandas初体验
python
import pandas as pd
import numpy as np
import os
os.chdir(r'D:\LLM\pandasProject') # 修改相对路径的位置.
# os.getcwd()
# 解决中文显示问题,下面的代码只需运行一次即可
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 如果是Mac本, 不支持SimHei的时候, 可以修改为 'Microsoft YaHei' 或者 'Arial Unicode MS'
plt.rcParams['axes.unicode_minus'] = False1.1折线图绘制 各国GDP变化趋势
python
# 1. 读取数据.
# 绝对路径
# df = pd.read_csv(r'\LLM\pandasProject\data\1960-2019全球GDP数据.csv', encoding='gbk')
# 相对路径
df = pd.read_csv('./data/1960-2019全球GDP数据.csv', encoding='gbk')
df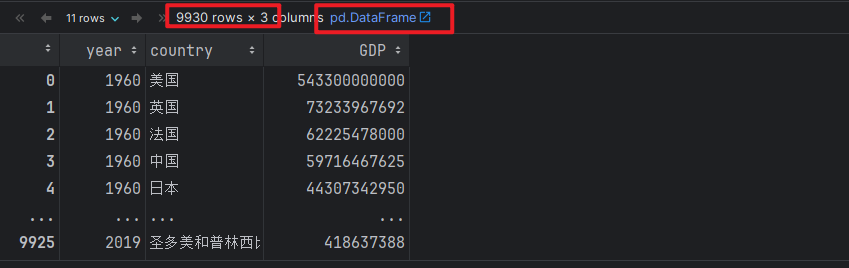
python
# 2. 加载中国的数据.
china_df = df[df.country == '中国']
china_df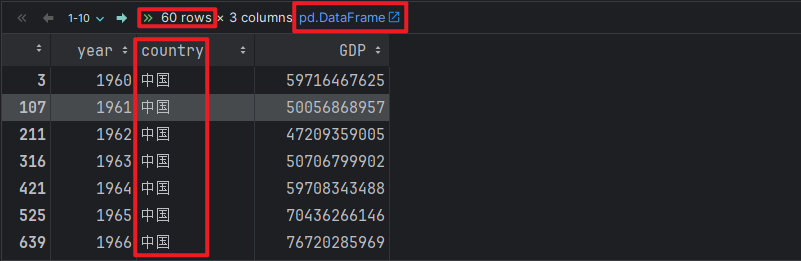
python
# 3. 设置 year字段为 索引列.
china_df.set_index('year', inplace=True) # inplace=True, 表示修改原数据.
china_df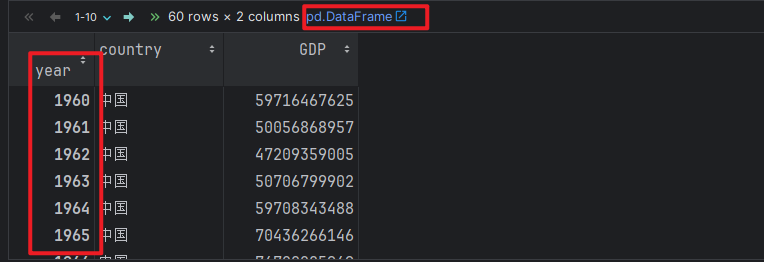
python
# 4. 绘制折线图
# china_df.plot()
china_df.GDP.plot()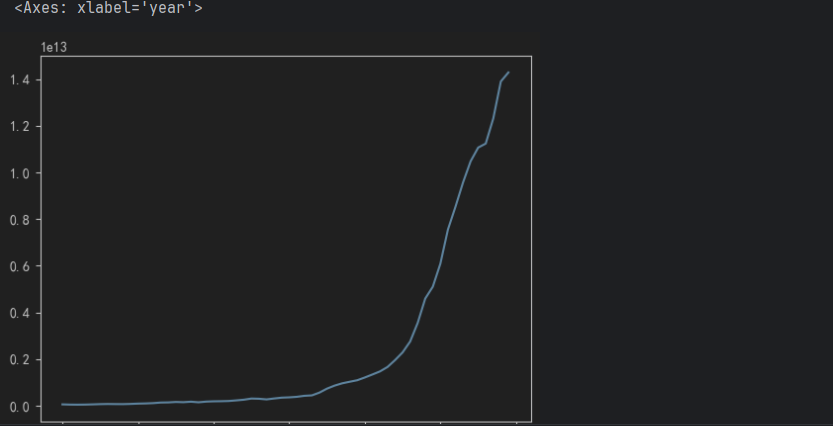
python
# 5. 参考上述思路, 绘制中美日 三国GDP折线图.
usa_df = df[df.country == '美国'].set_index('year')
jp_df = df[df.country == '日本'].set_index('year')
usa_df
jp_df
python
# 6. 绘制三国折线图
china_df.GDP.plot()
usa_df.GDP.plot()
jp_df.GDP.plot()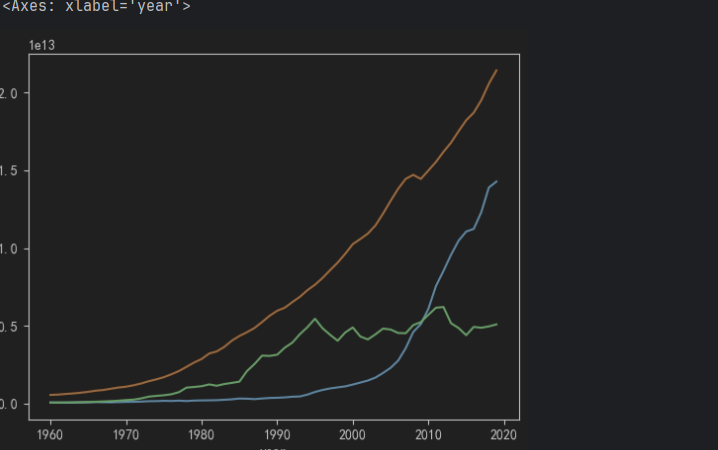
1.2绘制中美日三国 GDP 折线图, 加入图例 -> 拼音
python
# 1. 获取中美日三国的数据.
china_df = df[df.country == '中国'].set_index('year')
usa_df = df[df.country == '美国'].set_index('year')
jp_df = df[df.country == '日本'].set_index('year')
china_df
python
# 2. 分别修改 中美日三国的 GDP字段名为: 'china', 'usa', 'jp'
china_df.rename(columns={'GDP': 'china'}, inplace=True)
usa_df.rename(columns={'GDP': 'usa'}, inplace=True)
jp_df.rename(columns={'GDP': 'jp'}, inplace=True)
# 3. 查看修改后的数据
china_df
python
# 4. 绘制折线图.
china_df.china.plot(legend=True) # 设置图例
usa_df.usa.plot(legend=True)
jp_df.jp.plot(legend=True)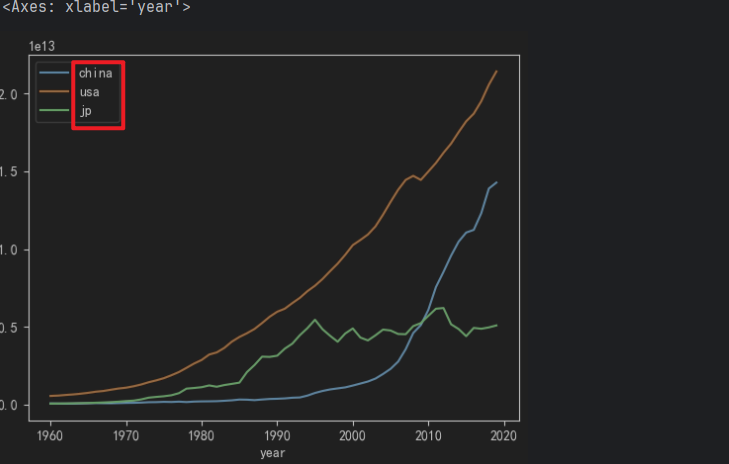
1.3绘制中美日三国 GDP 折线图, 加入图例 -> 中文
python
# 1. 获取中美日三国的数据.
china_df = df[df.country == '中国'].set_index('year')
usa_df = df[df.country == '美国'].set_index('year')
jp_df = df[df.country == '日本'].set_index('year')
china_df
python
# 2. 分别修改 中美日三国的 GDP字段名为: '中国', '美国', '日本'
china_df.rename(columns={'GDP': '中国'}, inplace=True)
usa_df.rename(columns={'GDP': '美国'}, inplace=True)
jp_df.rename(columns={'GDP': '日本'}, inplace=True)
# 3. 查看修改后的数据
china_df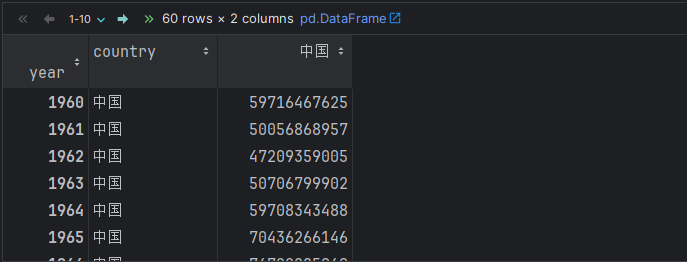
python
# 4. 绘制折线图.
china_df.中国.plot(legend=True) # 设置图例
usa_df.美国.plot(legend=True)
jp_df.日本.plot(legend=True)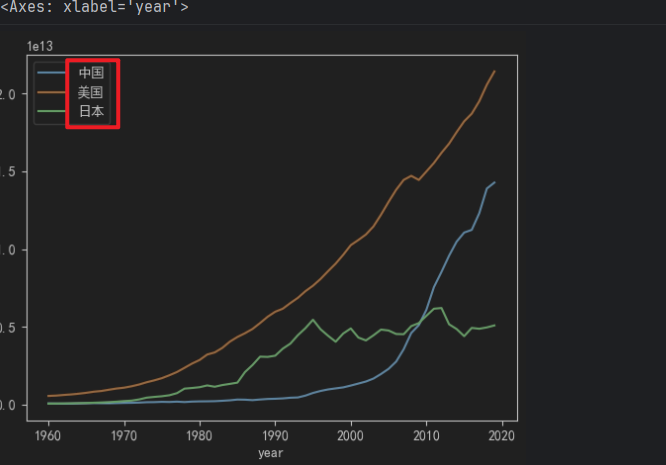
2.Series对象入门
python
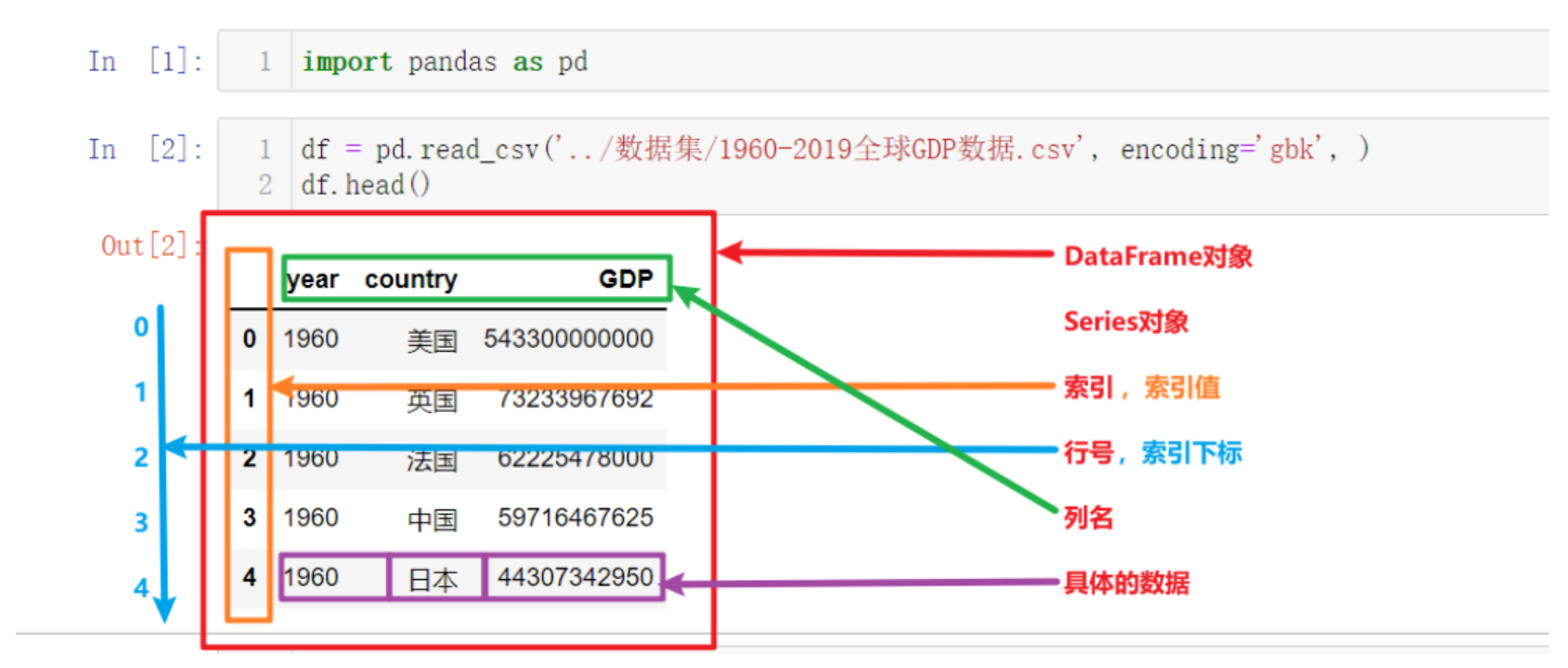
# Pandas中有两大核心对象, 分别是: DataFrame和Series,
# 其中, Series -> 一列数据, DataFrame -> 多列数据2.1创建Series对象
python
# 1. 创建Series对象, 采用: 默认自增索引.
s1 = pd.Series([1,2,3,4,5])
print(s1)
python
# 2. 创建Series对象, 采用: 自定义索引.
s2 = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
print(s2)
python
# 3. 使用字典, 元组创建Series对象.
# 元组形式
s3 = pd.Series((11, 22, 33, 44, 55))
print(s3)
# 字典形式.
s4 = pd.Series({'a': 1, 'b': 3, 'c': 5})
print(s4)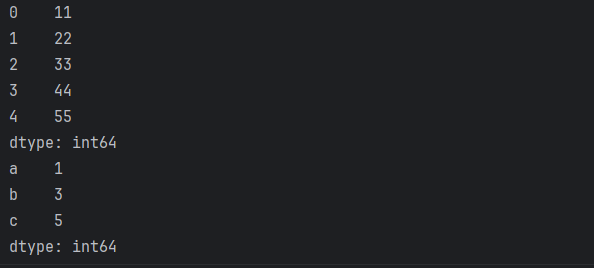
python
# 4. 使用numpy -> 创建Series对象.
s5 = pd.Series(np.arange(5))
print(np.arange(5))
print(s5)
2.2Series对象的属性
python
# 1. 构建Series对象, 索引为: A-F, 值为: 0-5
# s6 = pd.Series(data=[0, 1, 2, 3, 4, 5], index=['A', 'B', 'C', 'D', 'E', 'F'])
# 加入列表推导式
s6 = pd.Series(data=[i for i in range(6)], index=[i for i in 'ABCDEF'])
print(s6)
# Series对象的init方法内部参数
# def __init__(
# self,
# data=None,
# index=None,
# dtype: Dtype | None = None,
# name=None,
# copy: bool | None = None,
# fastpath: bool | lib.NoDefault = lib.no_default,
# ) -> None:
python
# 2. 获取Series对象的 索引列(的值)
print(s6.index) # Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object')
# 3. 获取Series对象的 值列(的值)
print(s6.values) #[0 1 2 3 4 5]
# 4. Series支持根据 索引 获取元素, 即: Series对象[索引值]
print(s6['D']) # 3
# 5. 根据索引, 修改Series对象的 元素值
s6['D'] = 99
print(s6)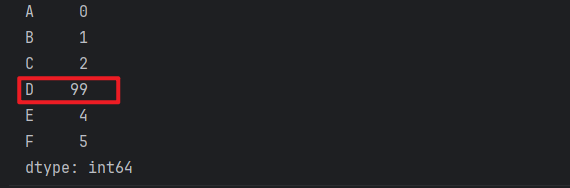
3.DataFrame对象入门
3.1创建DataFrame对象
python
# 场景1: 通过 字典 + 列表的方式实现.
# 1. 准备数据集, 每个键值对 = 1列数据
info = {
'name': ['路人甲', '路人乙', '路人丙', '路人丁'],
'gender': ['女', '男', '保密', '保密'],
'age': [81, 80, 66, 55]
}
# 2. 把上述的数据集, 封装成DataFrame对象.
df1 = pd.DataFrame(data=info)
# 3. 打印结果.
df1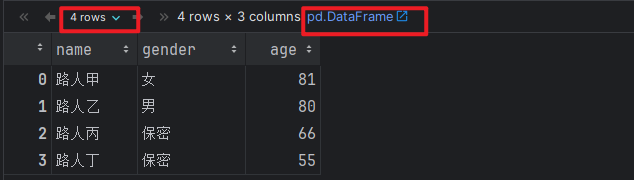
python
# 场景2: 通过 列表 + 元组(或者列表) 的方式实现.
# 1. 准备数据集, 每个元组 = 1行数据
info = [
('刘亦菲', '女', 39),
('迪丽热巴', '女', 31),
('王四', '未知', 66),
]
# info = [
# ['刘亦菲', '女', 39],
# ['迪丽热巴', '女', 31],
# ['王四', '未知', 66],
# ]
# 2. 把上述的数据集, 封装成DataFrame对象.
df2 = pd.DataFrame(data=info, columns=['姓名', '性别', '年龄'])
df2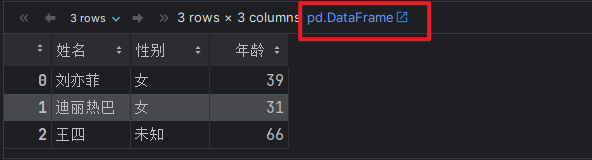
python
# 场景3: 通过 numpy的ndarray -> pandas DataFrame 的方式实现.
# 1. 创建numpy的 ndarray对象.
arr1 = np.arange(12).reshape(3, 4)
arr1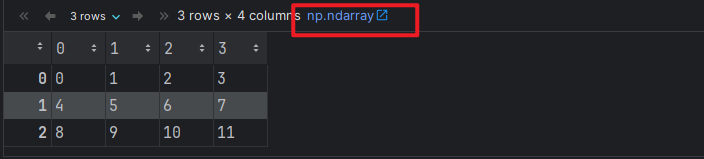
python
# 2. 把上述的ndarray对象, 封装成DataFrame对象.
df3 = pd.DataFrame(data=arr1, columns=['a', 'b', 'c', 'd'])
df3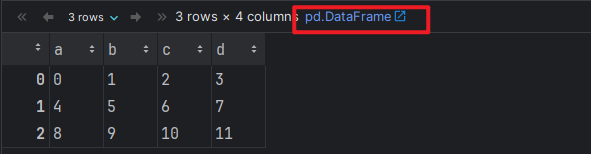
3.2DataFrame小案例
python
# 1. 生成10名同学, 5门功课的成绩, 成绩范围: 40 ~ 100
score_df = pd.DataFrame(np.random.randint(40, 101, (10, 5))) # 10行, 5列 包左不包右
score_df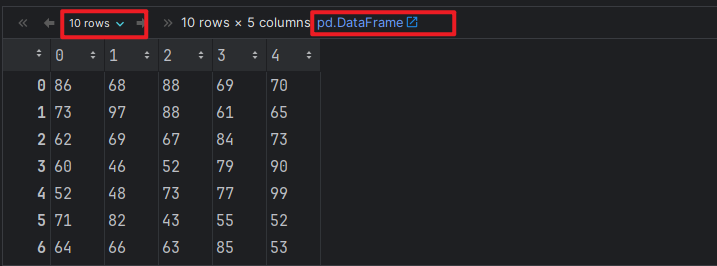
python
# 2. 修改DataFrame对象的 列名 和 索引列值.
column_names = ['语文', '数学', '英语', '政治', '体育']
# print(score_df.shape) # (10, 5)
# index_names = ['同学0', '同学1', '同学2', '同学3', '同学4', '同学5', '同学6', '同学7', '同学8', '同学9']
index_names = ['同学' + str(i) for i in range(score_df.shape[0])]
# 3. 具体的修改DataFrame对象 列名 和 索引值的动作.
# score_df.columns = column_names
# score_df.index = index_names
# rename函数也可以.
# score_df.rename(index={0:'同学0', 1:'同学1'}, columns={0: '数学', 1: '语文'}, inplace=True)
# i的值: 0 ~ 9 i的值: 0 ~ 4
score_df.rename(
index={i:index_names[i] for i in range(score_df.shape[0])},
columns={i: column_names[i] for i in range(score_df.shape[1])},
inplace=True
)
# 4. 打印修改后的结果.
score_df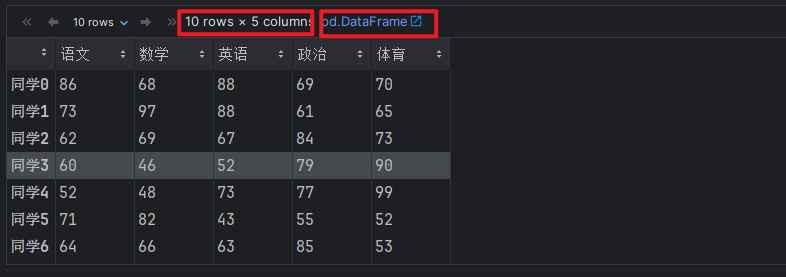
3.3DataFrame的基本属性
python
# shape 维度, 即: 行列数
print(score_df.shape) # (10, 5)
# index: 索引列
print(score_df.index)
# Index(['同学0', '同学1', '同学2', '同学3', '同学4', '同学5', '同学6', '同学7', '同学8', '同学9'], dtype='object')
# columns: 列名
print(score_df.columns)
# Index(['语文', '数学', '英语', '政治', '体育'], dtype='object')
# values: 数据(值)
print(score_df.values)
# [[86 68 88 69 70]
# [73 97 88 61 65]
# [62 69 67 84 73]
# [60 46 52 79 90]
# [52 48 73 77 99]
# [71 82 43 55 52]
# [64 66 63 85 53]
# [99 96 81 81 75]
# [69 57 80 87 63]
# [88 67 41 58 54]]
python
# 行列转置, T
score_df.T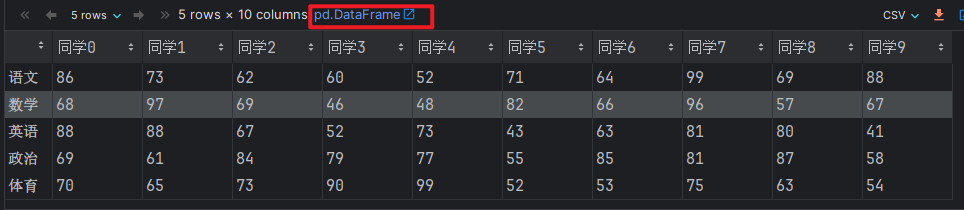
3.4DataFrame的基本函数
python
# 1. 查看df对象
score_df
# 2. head(n), 查看前n行数据
# score_df.head() # 默认是 5 条
score_df.head(3) # 指定数据条数
# 3. tail(n), 查看后n行数据
# score_df.tail() # 默认是 5 条
score_df.tail(2) # 指定数据条数
python
# 4. info(), 查看df对象的详细信息
score_df.info()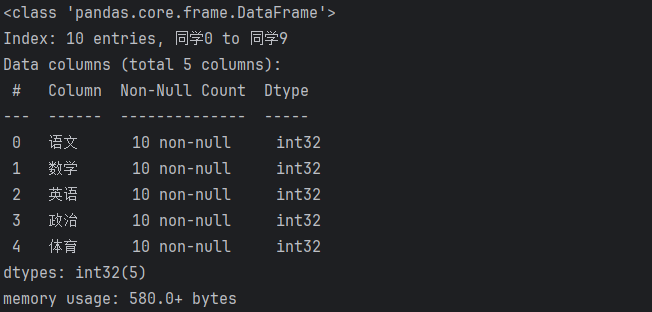
python
# 5. describe(), 查看df对象的 描述性 统计信息
score_df.describe()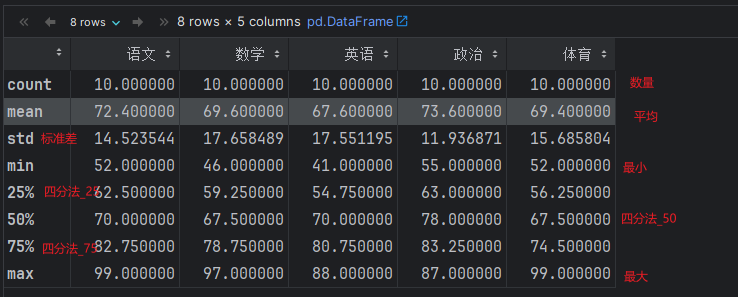
python
# 6. reset_index() 重置索引列.
# score_df.reset_index(drop=False) # drop=False, 默认值, 不删除原索引列.
score_df.reset_index(drop=True) # drop=True, 删除原索引列.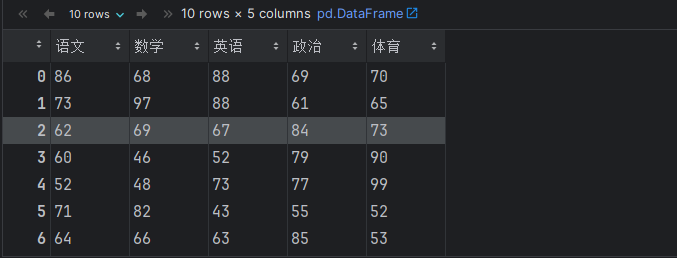
python
# 7. set_index(): 重新设置索引.
# score_df.set_index('语文') # 语文成绩充当索引列.
# 语文, 英语充当索引列.
score_df.set_index(['语文', '英语'])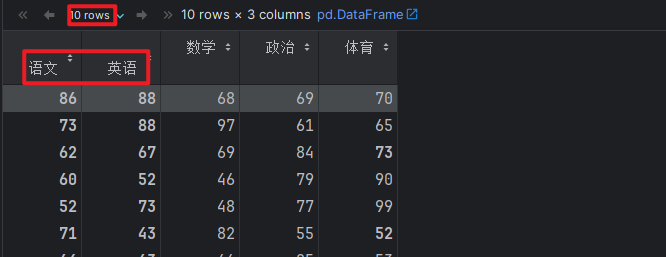
3.5Pandas的数据类型介绍
python
# Pandas中的数据类型几乎和Python中是一致的, 只不过有几个不太一样.
# 例如: Python: str -> Pandas: object, Python: None -> Pandas: nan,NAN,NaN,
# Pandas还支持category分类类型, 针对于分类数据操作更快, 更节省内存.
# 1. 创建DataFrame对象.
df = pd.DataFrame({
'name': [np.NaN, '路人甲', '路人乙', '路人cc'],
'gender': ['女', '男', '保密', np.nan],
'age': [81, 80, np.NAN, 55]
})
df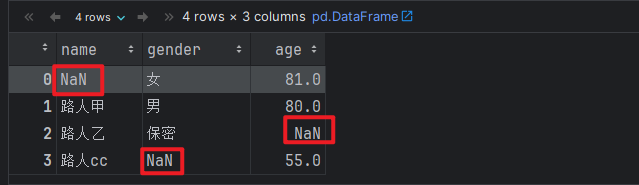
python
# 2. 查看df对象的 详细信息
df.info()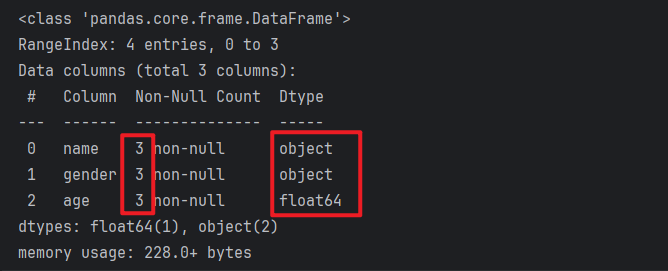
python
# 3. 演示 日期类型 datetime
df2 = pd.DataFrame(['2025-03-29', '2025-03-30', '2025-03-31'], columns=['date'],dtype='datetime64[ns]')
print(df2)
print(df2.dtypes)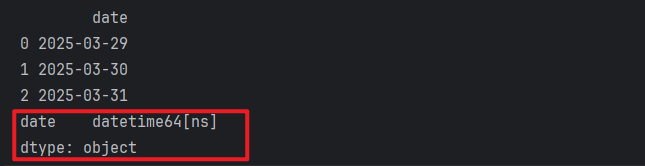
python
# 4. 演示 日期差类型 timedelta
start_date = pd.to_datetime('2004-08-21')
end_date = pd.to_datetime('2025-03-29')
# 打印结果
print(end_date - start_date)
print(type(end_date - start_date))
# 7525 days 00:00:00
# <class 'pandas._libs.tslibs.timedeltas.Timedelta'>
python
# 5. 演示下 category类型
s1 = pd.Series(['男', '女', '保密'], dtype='category')
print(s1)
print(type(s1))
print(s1.dtypes) # category4.Pandas的基本操作
4.1加载数据
python
# 1. 加载数据
df = pd.read_csv('./data/stock_day.csv')
df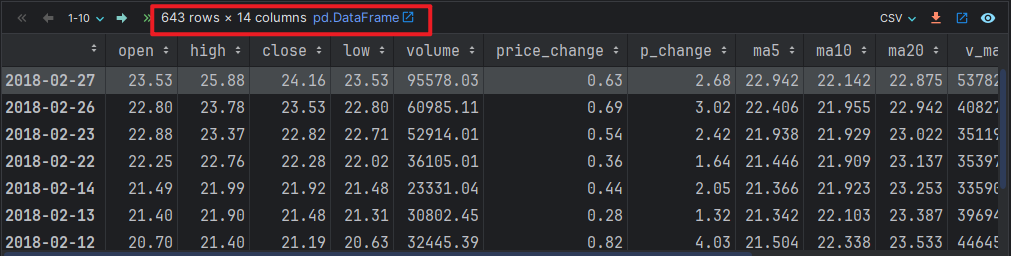
python
# 2. 移除不需要的字段.
df.drop(columns=['ma5', 'ma10', 'ma20', 'v_ma5', 'v_ma10', 'v_ma20'], axis=0, inplace=True) # 0: 列, 1: 行
# 注意:删除过后,重复删除会因找不到对应的 列索引列 而报错哈 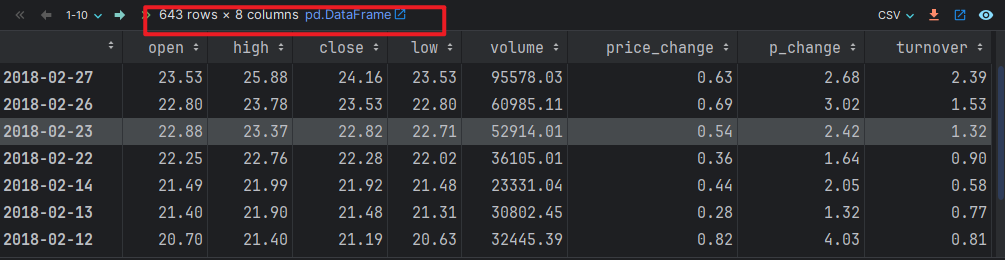
python
# 3. 查看处理后的数据.
df # 查看数据.
# df.info() # 查看详细信息
# df.describe() # 查看描述性统计信息4.2索引操作
python
# 场景1: 根据行列索引获取元素, 先列后行.
df['open']['2018-02-23'] # 22.88
# 尝试用: 先行后列
# df['2018-02-23']['open'] # 错误写法
python
# 场景2: 结合 loc 根据: 行索引值 和 列索引值 来获取元素.
# 格式: df.loc[行索引值, 列索引值]
# 格式: df.iloc[行索引号, 列索引号]
df.loc['2018-02-27', 'high'] # 获取一条数据
df.loc['2018-02-27':'2018-02-14', ['open', 'high']] #多条数据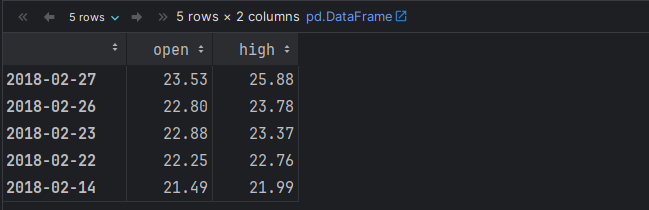
python
# 场景3: 结合 iloc 根据: 行索引号 和 列索引号 来获取元素.
df.iloc[0:5, 0:2] # 获取多条数据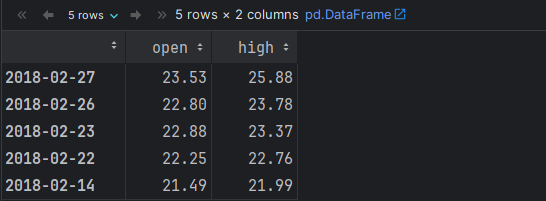
4.3赋值操作
python
# 1. 查看源数据.
df
# 2. 赋值操作
df['open'] = 23
df.low = 1
# 效果同上, 更简单, 但是有弊端, 如果 字段有空格等, 该方式不行.
#例如: df.max value 必须写成 df['max value']
# 3. 查看结果
df4.4排序操作
python
# 1. 查看原数据
df
# 2. 基于开盘价格做 升序 排列.
# df.sort_values(by='open', ascending=True) # 升序.
df.sort_values(by='open', ascending=False) # 降序.
# 3. 基于开盘价格降序排列, 价格一样, 基于 当日最高价格(high) 降序排列.
df.sort_values(by=['open', 'high'], ascending=[False, False])
# 4. 按照索引排序.
df.sort_index(ascending=True) # 默认升序.
# 5. 演示 Series对象也有 sort_index(), sort_values() 排序方法.
# df.open.sort_index(ascending=True) # 索引升序
df.open.sort_values(ascending=False) # 价格降序5.DataFrame运算
5.1算数运算
python
# 1. 查看源数据.
df
# 2. 针对于 close列值 + 2 处理.
# df.close.add(2) # 效果同下
df.close + 2 # Series对象 和 数值运算, 则 Series中的每个数值都会和该数字进行运算.
# 3. 针对于 low列的值 - 10 处理
# df.low.sub(10)
df.low - 10 # 效果同上5.2逻辑运算符 & |
python
# 1. 查看源数据.
df
# 2. 完成需求.
# 需求1: 筛选出 open列值 > 23的数据.
df[df.open > 23]
# 需求2: 筛选出 open列值 > 23, 且 < 24的数据.
df[(df.open > 23) & (df.open < 24)] # 细节: 多组判断记得加 小括号.
df[(df['open'] > 23) & (df['open'] < 24)] # 标准写法.
# 3. 可以通过 query()函数, 优化上述的代码.
df.query('open > 23 & open < 24')
# 4. 固定值的筛选, isin
# 需求: 查询 open价格为 23.53, 23.67价格数据.
df[(df.open == 23.53) | (df.open == 23.67)]
df[df.open.isin([23.53, 23.67])]
df.query('open == 23.53 | open == 23.67')
df.query('open in [23.67, 23.53]')5.3统计函数
python
# 1. 查看源数据
df
# 2. 演示常用的统计函数
df.describe() # 查看各列的描述性的 统计信息, 例如: 个数, 最大值, 最小值, 平均值, 中位数, 25%分位数, 75%分位数.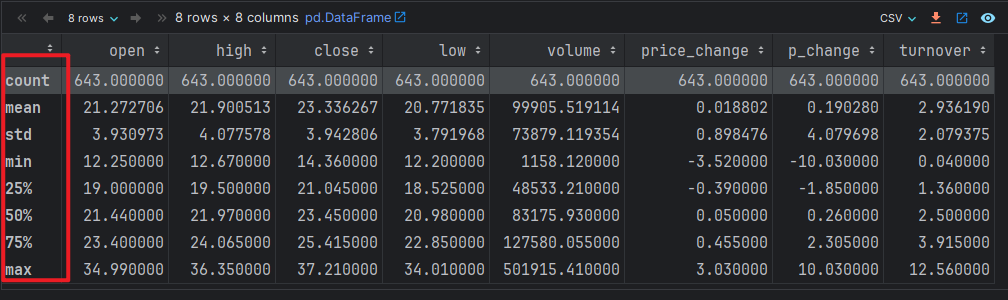
python
# 统计函数 count(), mean(), median(), min(), max(), std(), var(), sum()
df.sum() # 针对于 每列(DataFrame对象) 进行求和.
df.high.sum() # 针对于 high列(Series对象) 进行求和.
df.mean() # 针对于 每列(DataFrame对象) 进行求平均值.
df.median() # 针对于 每列(DataFrame对象) 进行求中位数.
df.cumsum() # 针对于 每列(DataFrame对象) 进行求累计求和.
python
# - apply()函数 -> 它可以执行自定义函数
# 背景: 目前我们用的都是Pandas提供好的函数, 例如: count(), max(), min()...
# 如果要传入一些自定义的逻辑, 此时就需要用到 apply()函数了
# 格式: df.apply(自定义函数, axis=0) # 0 -> 列, 1 -> 行
# 需求: 同时 获取到 多列的 最大值 和 最小值的差值. 例如: open列, close列
# df.open.max() - df.open.min()
# df.close.max() - df.close.min()
# 思路1: 分解版.
# 1. 自定义函数 my_func, 接收 某列的数据, 计算该列的最大值和最小值, 返回差值.
def my_func(col):
return col.max() - col.min()
# 2. 获取到 open列和 close列.
df[['open', 'close']]
df.loc[:, ['open', 'close']]
df.iloc[:, [0, 2]]
df.iloc[:, 0:3:2]
# 3. 通过apply()函数, 调用上述的自定义函数, 作用到 指定的列.
df[['open', 'close']].apply(my_func, axis=1) # axis=1, 表示对 行 进行操作.
df[['open', 'close']].apply(my_func, axis=0) # axis=0, 表示对 列 进行操作.
# df[['open', 'close']].apply(my_func) # 效果同上, 默认是axis=0, 底层 -> 把df的各列分别传入函数, 计算结果.
# 思路2: 合并版, 通过 lambda函数实现.
df[['open', 'close']].apply(lambda col: col.max() - col.min())6.Pandas读写操作
python
import pandas as pd
import numpy as np
import os
os.chdir(r'D:\LLM\pandasProject') # 修改相对路径的位置.
# os.getcwd()
# 解决中文显示问题,下面的代码只需运行一次即可
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 如果是Mac本, 不支持SimHei的时候, 可以修改为 'Microsoft YaHei' 或者 'Arial Unicode MS'
plt.rcParams['axes.unicode_minus'] = False
from sqlalchemy import create_engine # 导入sql引擎对象6.1Pandas操作csv文件
python
# 1. 读取csv文件, 获取数据.
# 参数解释: 参1: 文件路径, 参2: 分隔符, 参3: 读取的列名.
df = pd.read_csv('./data/stock_day.csv', sep=',', usecols=['open', 'high', 'close', 'low'])
df
# 2. 把读取到的数据, 写到文件中.
df[:10].to_csv('./data/my_file1.csv', sep=',', index=False) # 参数3: 是否写入索引.
print('写入成功!')
# 3. 特殊的csv文件 -> tsv文件.
# 区别: csv文件 -> 以,做分割, tsv文件 -> 是以tab键分隔的.
df[:5].to_csv('./data/my_file2.tsv', sep='\t', index=True)
print('写入成功!')
# 4. 读取tsv文件.
# 参1: 文件路径, 参2: 分隔符, 参3: 把索引为0的列(第1列) 设置为索引.
df2 = pd.read_csv('./data/my_file2.tsv', sep='\t', index_col=0)
df26.2Pandas操作MySql数据表
python
# 前提: 你的Anaconda要先装: pymysql 和 sqlalchemy 模块.
# 安装方式: pip install 模块名
# pip install pymysql==1.0.2 -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 如果后边的代码运行提示找不到sqlalchemy的包,和pymysql一样进行安装即可
# pip install sqlalchemy==2.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 此外, 你的电脑还需要安装并运行: mysql数据库
# 需求: 把数据写入到MySQL数据表.
# 1. 准备写到MySQL数据表的 数据.
data = pd.read_csv('./data/csv示例文件.csv', encoding='gbk', index_col=0)
data
# 2. 导包
# from sqlalchemy import create_engine # 导入引擎对象, 我们写到第1个单元格了.
# 3. 创建引擎对象.
# 数据库+模块名://数据库的用户名:密码@主机名:端口号/要操作的数据库名?编码方式'
engine = create_engine('mysql+pymysql://root:root@localhost:3306/tb?charset=utf8')
# 4. 具体的往数据库写数据的动作.
# 参1: 数据表名, 参2: 引擎对象, 参3: 是否把索引写入数据库,
# 参4: 如果数据表存在, 则如何处理(append->追加数据; replace->覆盖数据)
data.to_sql('my_table', engine, index=False, if_exists='append')
# 5. 提示
print('写入成功!')
# 6. 从SQL表中读取数据.
# 参1: 数据表名, 参2: 引擎对象.
sql_df = pd.read_sql('my_table', engine) # 读取全表.
sql_df = pd.read_sql('select name, AKA from my_table limit 0,2', engine) # 读取表中指定数据..
sql_df原生的pymysql
python
# 这个代码是原生pymysql, 掌握 pandas 读写mysql的方式已经够用了.
# 导包
import pymysql
# 1. 获取连接对象(Python -> MySQL) 前台小姐姐
conn = pymysql.connect(
host='127.0.0.1', # 数据库地址
port=3306, # 数据库端口
user='root', # 数据库用户名
password='root', # 数据库密码
database='tb', # 数据库名称
charset='utf8' # 数据库编码
)
# 2. 根据连接对象, 获取游标对象 我 ->找人的
cursor = conn.cursor()
# 3. 定义SQL语句
sql = 'select name, AKA from my_table limit 0,2'
# 4. 并执行SQL语句
cursor.execute(sql)
# 5. 获取结果集
result = cursor.fetchall()
# 6. 遍历结果集.
for row in result:
print(row)
# 7. 释放资源.
cursor.close()
conn.close()6.3Pandas读写josn文件
python
# 1. 读取json文件.
# 参1: 文件路径, 参2: 读取的格式, 参3: 是否按行读取.
json_df = pd.read_json('./data/test.json', orient='records', lines=True)
# 2. 打印读取到的内容.
json_df

python
# 2. 把上述的数据, 写到json文件中.
# json_df.to_json('./data/my_file3.json', orient='records') # 结果为: [{}, {}, {}...]
# json_df.to_json('./data/my_file3.json', orient='records', lines=True) # 结果为: {} {} {}... 逐行形式
# json_df.to_json('./data/my_file3.json') # 格式为: columns: {...}
# json_df.to_json('./data/my_file3.json', orient='index') # 格式为: index: {...}
json_df.to_json('./data/my_file3.json', orient='records', lines=True) # 结果为: {} {} {}... 逐行形式
print('写入成功!')
# - ``'split'`` : dict like
# ``{{index -> [index], columns -> [columns], data -> [values]}}``
# - ``'records'`` : list like
# ``[{{column -> value}}, ... , {{column -> value}}]``
# - ``'index'`` : dict like ``{{index -> {{column -> value}}}}``
# - ``'columns'`` : dict like ``{{column -> {{index -> value}}}}``
# - ``'values'`` : just the values array
# - ``'table'`` : dict like ``{{'schema': {{schema}}, 'data': {{data}}}}```7.Pandas的CURD操作
7.1Pandas的CURD操作-增
python
# 1. 准备数据.
df = pd.read_csv('./data/1960-2019全球GDP数据.csv', encoding='gbk')
# 2. 从原始数据集中 拷贝一部分出来 做操作.
df2 = df[:5].copy()
# 3. 新增列.
# 思路1: 通过直接 赋值 的方式 新增1列. column, 列
df2['c1'] = 23 # 写法1: 固定值
df2['c2'] = ['cxk', 'lyf', 'wyf', 'wyb', '水冷哥'] # 写法2: 传入列表
df2['c3'] = df2.year * 2 # 写法3: 通过已有的列(Series) 来计算新列的值.
def my_fun1():
return 25000
df2['c4'] = my_fun1() # 写法4: 通过函数来计算新列的值.
# 思路2: 通过 assign() 的方式 新增1列.
# 写法1: 通过 assign()函数 -> 新增1列.
df3.assign(c1 = 23)
# 写法2: 通过 assign()函数 -> 新增n列.
df3.assign(
c1 = 23,
c2 = ['cxk', 'lyf', 'wyf', 'wyb', '水冷哥'],
c3 = df3.year * 2,
c4 = my_fun1()
)7.2Pandas的CURD操作-删和去重
python
# 1. 准备数据.
df4 = df[:10].copy()
# 2. 删除行 -> drop()函数, 除非指定inplace=True, 否则不会修改原始数据.
# df4.drop(index=[0, 2, 4]) # 不会修改原始数据.
df4.drop(index=[0], inplace=True) # 会修改原始数据.
# 3. 删除列 -> del关键字, 会直接修改原数据.
del df4['year'] # 删除year列.
# 4. 删除列 -> drop()函数
# df4.drop(columns=['country'], inplace=True)
# 5. 去重.
# 场景1: DataFrame去重 -> 以 行 做单位比较.
# 拼接df5 和 df5 -> 组合成 有重复数据的 DataFrame.
df6 = pd.concat([df5, df5])
# DataFrame去重
df6.drop_duplicates() # 如果设置inplace=True, 则会修改原始数据.
# 场景2: Series去重 -> 以 列 做单位比较.
df6.country.drop_duplicates()7.3Pandas的CURD操作-改
python
# 1. 准备源数据.
df7 = df[:5].copy()
# 2. 新增1列
df7['c1'] = 23
# 3. 修改GDP列值.
df7['GDP'] = [1, 2, 1, 66666666, -123] # 直接修改原数据了.
# 4. 采用 replace()替换.
# 美国 -> usa
df7.country.replace('美国','usa', inplace=True)
# 日本 -> 岛国
df7.country.replace('日本','jp', inplace=True)7.4Pandas的CURD操作-查和排序
python
# 1. 查看源数据
df
# 2. 获取前5条数据.
df.head(5)
df.head() # 效果同上, 默认是5条
# 3. 获取后3条数据.
df.tail(3)
# 4. 根据列名获取数据.
df['year'] # 获取year列 -> Series对象
df.year # 获取year列 -> Series对象, 效果同上.
df[['year']] # 获取year列 -> DataFrame对象
df[['year', 'country']] # 获取year和country列 -> DataFrame对象
# 5. 根据 行索引值来获取数据.
df[:5] # 前5条
df[1:5:2] # 1, 3, 包左不包右.
df[10::5] # 从10开始, 到末尾结束, 步长为 5
# 6. 通过query()函数, 结合条件获取.
# 需求: 查询中美日三国 2015 ~ 2019年的数据.
df.query('country in ["中国", "美国", "日本"] and year in [2015, 2016, 2017, 2018, 2019]')
df.query('country in ["中国", "美国", "日本"] and (year >= 2015 and year <= 2019)')
# 7. 排序.
df.sort_index(ascending=False) # 根据 行索引值排序, 降序.
# 根据内容, 例如: year 降序, 一致就根据 GDP降序.
df.sort_values(['year', 'GDP'], ascending=False)
df.sort_values(['year', 'GDP'], ascending=[False, True]) # year 降序, GDP升序.
# 8. rank()函数, 类似于SQL的窗口函数.
df7 = pd.DataFrame({
'姓名':['小a', '小b', '小c', '小d'],
'成绩':[100, 90, 90, 80]
})
# 9. rank()直接排名
# df7.rank() # 针对于每列都会排名
# 给df新增1列, 用于显示排名.
df7['成绩排名_min'] = df7.成绩.rank(method='min', ascending=False) # 最小值排名
df7['成绩排名_max'] = df7.成绩.rank(method='max', ascending=False) # 最大值排名
df7['成绩排名_dense'] = df7.成绩.rank(method='dense', ascending=False) # 稠密排名
df7['成绩排名_avg'] = df7.成绩.rank(method='average', ascending=False) # 平均值排名
df7['成绩排名_默认'] = df7.成绩.rank(ascending=False) # 默认
df7
8.Pandas进阶语法
python
import pandas as pd
import numpy as np
import os
os.chdir(r'D:\LLM\pandasProject') # 修改相对路径的位置.
# os.getcwd()
# 解决中文显示问题,下面的代码只需运行一次即可
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 如果是Mac本, 不支持SimHei的时候, 可以修改为 'Microsoft YaHei' 或者 'Arial Unicode MS'
plt.rcParams['axes.unicode_minus'] = False8.1缺失值处理
思路1:删除缺失值
python
#思路1: 删除缺失值
# 1. 读取数据.
movie_df = pd.read_csv('./data/movie.csv')
# 2. 查看下数据的介绍.
movie_df.columns # 所有的列名
movie_df.info() # 查看数据的 基本信息(列名, 数据类型, 非缺失值数量等)
movie_df.describe() # 查看数据的 描述性统计信息(均值, 中位数, 标准差等)
# 3. 删除缺失值
# movie_df.dropna() # 不会修改原数据, 加入 inplace=True 即可, 默认删: axis=0, 删行, axis=1, 删列.
movie_df.dropna(axis=0) # 删行,默认删除行
movie_df.dropna(axis=1) # 删列思路2:填充缺失值
python
# 思路2:填充缺失值
# 1. 查看源数据
movie_df
# 2. 判断某列(的某个值)是否有缺失值.
pd.isnull(movie_df) # 判断df对象的 每列的 每个值 是否为空(缺失值)
pd.notnull(movie_df) # 判断df对象的 每列的 每个值 是否不为空(非缺失值)
# 3.判断某列是否是 包含缺失值的列.
np.all(pd.notnull(movie_df.Title)) # 整列都是True -> 结果是True, 但凡有False -> 结果是False, 说明该列有缺失.
np.all(pd.notnull(movie_df)) # 整表都是True -> 结果是True, 但凡有False -> 结果是False, 说明该表有缺失.
# 4. 填充缺失值.
# 写法1: 填充固定值.
movie_df.fillna(23)
# 写法2: 填充 每列的平均值.
movie_df['Revenue (Millions)'].fillna(movie_df['Revenue (Millions)'].mean(), inplace=True)
movie_df['Metascore'].fillna(movie_df['Metascore'].mean(), inplace=True)
# 5. for循环的方式, 使用 每列的平均值 来填充各列的缺失值.
# 5.1 获取每个列名
for col_name in movie_df.columns:
# 5.2 判断某列是否有缺失值.
# movie_df[col_name]: 根据列名, 找到 df中的某个列 -> Series对象.
# pd.notnull(某列数据): 判断该列的每个值是否为非缺失值, True -> 不为空, False -> 为空(缺失值)
# np.all([True, False...]): 里边的值全部为True -> 结果为True, 只要有一个为False -> 结果为False.
if np.all(pd.notnull(movie_df[col_name])) == False:
# 5.3 走到这里, 说明该列有缺失值.
print(col_name) # 打印列名
# 5.4 打印这两列的平均值.
print(movie_df[col_name].mean())
# 5.5 用该列的平均值来填充该列的缺失值.
movie_df[col_name].fillna(movie_df[col_name].mean(), inplace=True)思路3:转换,然后填充或者删除缺失值
python
# 背景: 实际开发中, 不是所有的缺失值都会用NaN来表示, 例如: 可能用 ? 表示, 如何删除这些缺失值呢?
# 思路: 先转换, 后删除. 即: ? -> NaN -> 删除.
# 1. 加载数据.
wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data")
wis
# 2. 尝试直接删除缺失值.
wis.dropna() # ? 不是缺失值, 所以直接删, 删不掉.
# 3. 解决上述的问题, ? -> NaN -> 删. 空的三种写法: np.nan, np.NAN, np.NaN
wis.replace('?', np.nan).dropna()8.2数据合并
思路1:concat(),能行合并,能列合并
python
# 1. 准备数据.
df = pd.read_csv('./data/1960-2019全球GDP数据.csv', encoding='gbk')
df1 = df[:10]
df2 = df[10:20]
# 2. 通过 concat() 合并数据.
# 细节: 列合并默认参考 列名.
new_df = pd.concat([df1, df2], axis=0) # axis=0, 列合并(垂直合并), axis=1, 行合并(水平合并)
new_df = pd.concat([df1, df2]) # 效果同上, 默认是 垂直列合并
# 细节: 行合并, 默认参考 行索引(值)
new_df = pd.concat([df1, df2], axis=1) # 水平行合并
new_df
# 3. 行合并.
# join默认是outer: 满外连接, 即: 左表全集 + 右表全集 + 交集
pd.concat([df1, df2], axis=1, join='outer')
# 指定为: 内连接, 即: 只要交集
pd.concat([df1, df2], axis=1, join='inner') 思路2:merge() -> 只能进行 行合并(水平合并)
pd.merge(left, right, how='inner', on=None)
可以指定按照两组数据的共同键值对合并或者左右各自
left: DataFrame
right: 另一个DataFrame
on: 指定的共同键how:按照什么方式连接
python
left = pd.DataFrame({ 'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({ 'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
# 默认内连接(两表交集)
pd.merge(left, right) # 效果同上, 默认是 inner join, 且参考 同名列进行合并.
result = pd.merge(left, right, how='inner' ,on=['key1', 'key2']) #与上面等同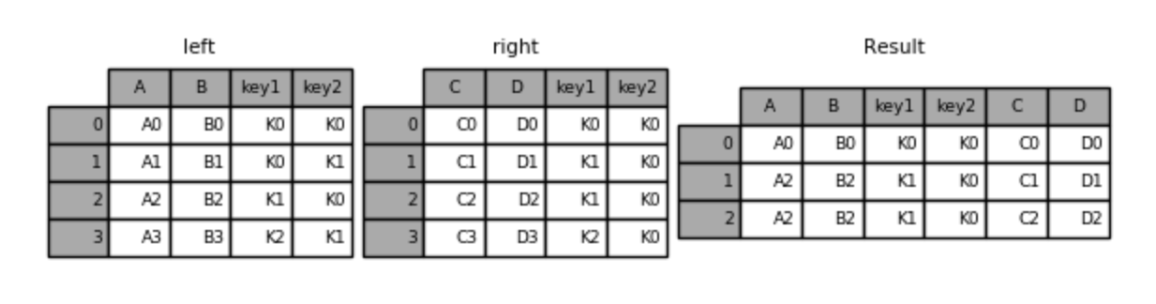
python
# 左外连接(左表全集 + 交集)
result = pd.merge(left, right, how='left', on=['key1', 'key2'])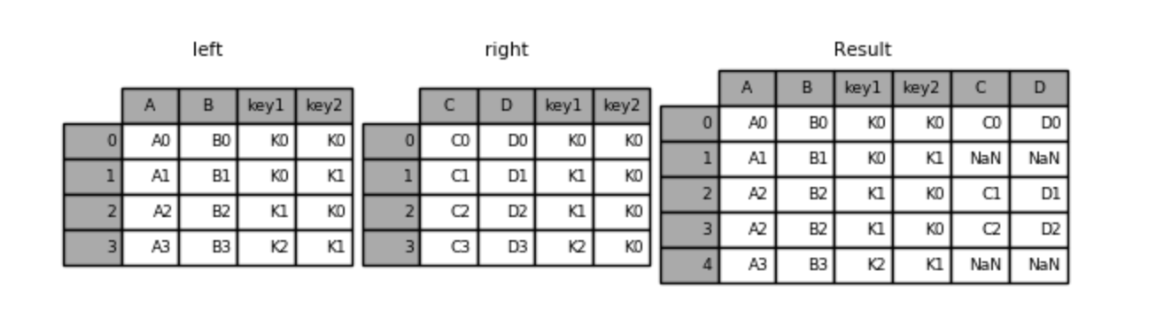
python
# 右外连接(右表全集 + 交集)
result = pd.merge(left, right, how='right', on=['key1', 'key2'])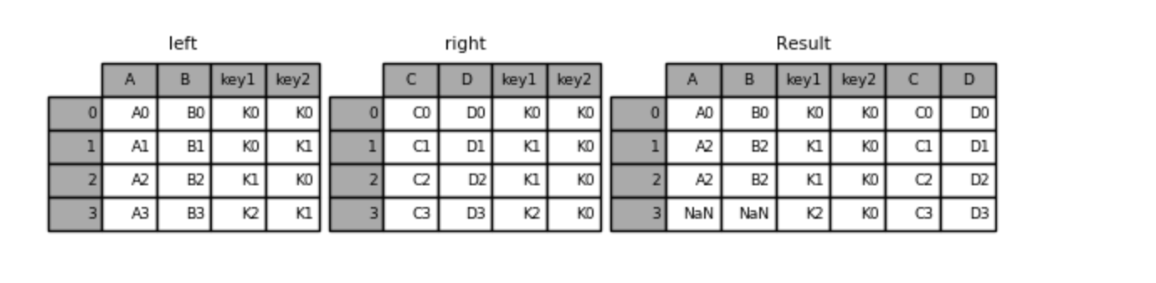
python
# 外连接(满连接)
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])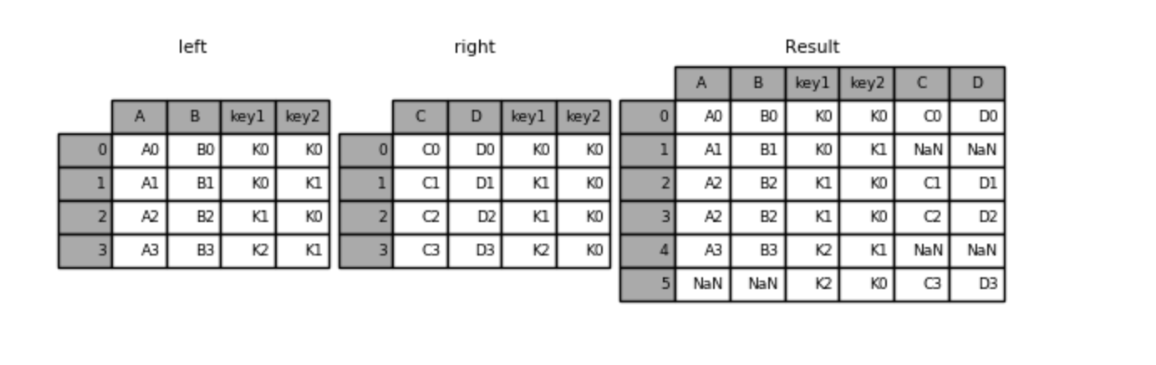
8.3分组聚合
python
# agg -> Aggregate(聚合的意思)
# 格式: df.groupby(['分组字段1', '分组字段2'...]).agg({'列名1':'聚合函数名', '列名2':'聚合函数名'...})
# 1. 场景1: 按照单列分组
df.groupby(['city']) # DataFrameGroupBy -> DataFrame分组对象
df.groupby('city') # 细节: 如果分组列只有1个, 中括号可以省略不写.
# 2. 场景2: 按照多列分组
df.groupby(['city', 'channel']) # DataFrameGroupBy -> DataFrame分组对象
df.groupby(['city', 'channel']).revenue # SeriesGroupBy -> Series分组对象
# 3. 场景3: 如何获取某个分组的数据.
df.groupby(['city', 'channel']).get_group(('北京', '线下')) # 1个分组的信息
df.groupby(['city', 'channel']).get_group(('上海', '线上')) # 另1个分组的信息
python
# 4. 场景4: 分组 + 聚合(聚合字段只有1个)
# 需求: 根据 城市 和 销售渠道分组, 计算: 销售金额.
# 写法1: 通用版(掌握)
df.groupby(['city', 'channel']).agg({'revenue':'sum'}) # 返回DataFrame对象
# 写法2: 变形版(了解)
df.groupby(['city', 'channel']).revenue.sum() # 返回Series对象
df.groupby(['city', 'channel'])['revenue'].sum() # 返回Series对象
df.groupby(['city', 'channel'])[['revenue']].sum() # 返回DataFrame对象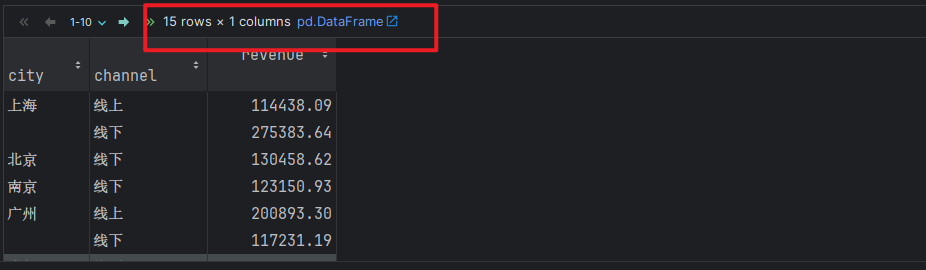
python
# 5. 场景5: 分组 + 聚合(聚合字段有2个, 聚合操作相同)
# 需求: 根据 城市 和 销售渠道分组, 计算: 销售金额, 订单数量 总和.
# 写法1: 通用版(掌握)
df.groupby(['city', 'channel']).agg({'revenue':'sum', 'order':'sum'})
# 写法2: 变形版(了解)
df.groupby(['city', 'channel'])[['revenue', 'order']].sum()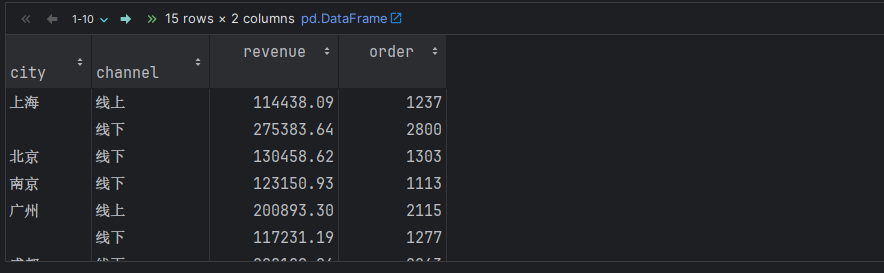
python
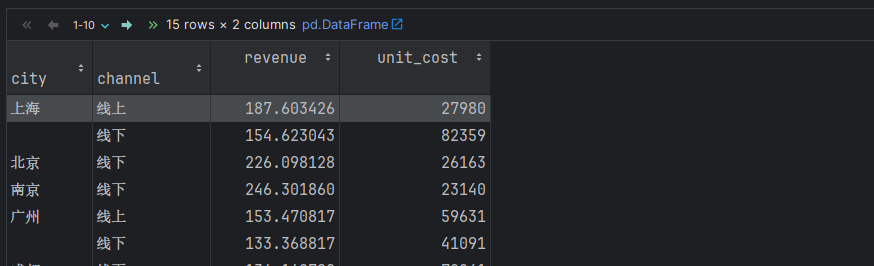
# 6. 场景6: 分组 + 聚合(聚合字段有2个, 聚合操作不同)
# 需求: 根据 城市 和 销售渠道分组, 分别计算: 销售金额的平均值, 成本的总和.
df.groupby(['city', 'channel']).agg({
'revenue': 'mean',
'unit_cost': 'sum'
})
8.4分组过滤
python
# 需求: 按照城市分组, 查询每组销售金额平均值 大于200的全部数据. 即: 算出每组的销售金额, 找到金额大于200的组, 然后显示这些组所有的信息.
# 1.根据城市分组, 计算每个城市的 销售金额的 平均值
df.groupby('city').revenue.mean()
# 2. 根据城市分组, 查看上海分组的数据.
df.groupby('city').get_group('上海')
df.query('city in ["上海"]') # 效果同上
# # 3. 完成需求.
df.groupby('city').filter(lambda x: x.revenue.mean() > 200)
df.groupby('city').revenue.filter(lambda x: x.mean() > 200)8.5交叉表(了解)、透视表(掌握)
python
# 1. 交叉表演示:
# 创建一个示例数据集
data = {
'性别': ['男', '女', '男', '女', '男', '女', '女', '男'],
'购买': ['是', '否', '是', '是', '否', '否', '是', '否']
}
df = pd.DataFrame(data)
# 创建交叉表
crosstab = pd.crosstab(df['性别'], df['购买'])
print(crosstab)
python
# 2. 用透视表完成上述的需求.
data = {
'性别': ['男', '女', '男', '女', '男', '女'],
'购买': ['是', '否', '是', '是', '否', '否'],
'金额': [100, 150, 200, 130, 160, 120]
}
df = pd.DataFrame(data)
df.pivot_table(index='性别', columns='购买', values='金额' , aggfunc='mean')
python
# 3. 透视表案例: 优衣库数据集.
# 3.1 读取数据
df = pd.read_csv('./data/uniqlo.csv')
df
# 3.2 需求: 根据城市, 销售渠道分组, 计算 销售金额 总和.
# 写法1: groupby() 分组 聚合
df.groupby(['city', 'channel']).agg({'revenue': 'sum'})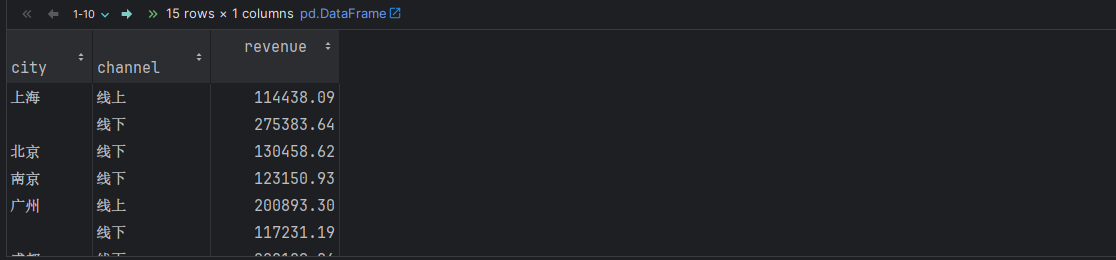
python
df.groupby(['city', 'channel'], as_index=False).agg({'revenue': 'sum'}) # as_index=False 不把分组字段当做行索引, 而是当做列.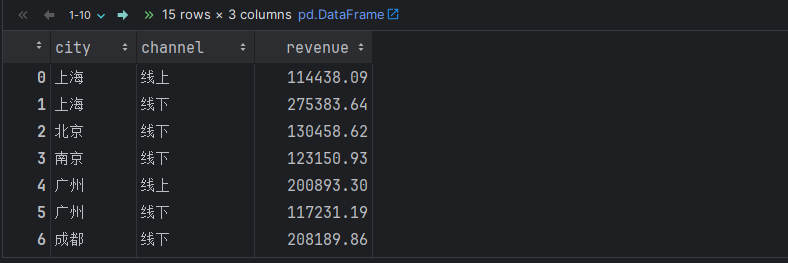
python
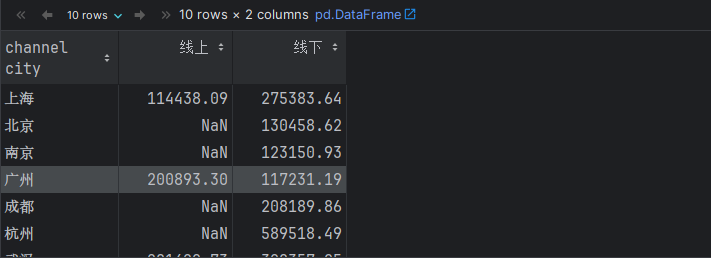
# 写法2: pivot_table() 透视表, 作用: 统计分组数据, 简化 分组聚合写法, 指定某一列对另一列的关系
# 参1: 指定分组字段, 参2: 指定分组字段, 参3: 指定聚合字段, 参4: 指定聚合函数
df.pivot_table(index='city', columns='channel', values='revenue', aggfunc='sum')