🖥️ 第十章:RAID 磁盘阵列与 LVM 逻辑卷管理
本章从小白视角 讲解 RAID 与 LVM------它们分别解决什么问题、是什么、怎么用。附带全部 Shell 脚本(菜单、循环、颜色)、完整命令输出、ANSI 控制码、awk 等补充知识。原文内容全部保留,仅做结构化整理与补充。
📑 目录
- [一、先弄懂:RAID 是什么?为什么需要它?](#一、先弄懂:RAID 是什么?为什么需要它?)
- [二、RAID 级别详解](#二、RAID 级别详解)
- 二补充、各级别选择原因与使用场景
- [三、硬件 RAID 与软件 RAID](#三、硬件 RAID 与软件 RAID)
- [四、mdadm 命令详解](#四、mdadm 命令详解)
- [五、软件 RAID 实战(含完整命令输出)](#五、软件 RAID 实战(含完整命令输出))
- [六、先弄懂:LVM 是什么?为什么需要它?](#六、先弄懂:LVM 是什么?为什么需要它?)
- [七、LVM 命令详解](#七、LVM 命令详解)
- [八、LVM 实战(创建、扩展、缩减)](#八、LVM 实战(创建、扩展、缩减))
- 九、快照卷(Snapshot)
- [九补充、RAID 与 LVM 对比](#九补充、RAID 与 LVM 对比)
- [十、Shell 脚本与命令补充](#十、Shell 脚本与命令补充)
- 十一、练习题汇总
- [附录:控制器与适配器、ANSI 颜色码、awk 基础](#附录:控制器与适配器、ANSI 颜色码、awk 基础)
一、先弄懂:RAID 是什么?为什么需要它? 🤔
1.1 一句话解释
RAID (Redundant Arrays of Independent Disks,独立冗余磁盘阵列)= 把多块便宜的硬盘 组合成一个逻辑盘,获得更大容量、更高性能或更好的容错能力。
1.2 生活类比
搬砖版:
- 一个人搬(单盘):慢,而且这个人倒下就全停了。
- RAID 0 :两个人各搬一半砖(条带)→ 搬得快,但一个人倒了砖就散了(没冗余)。
- RAID 1 :两个人搬同样的砖(镜像)→ 速度没快多少,但一个人倒了另一个还在(有冗余)。
- RAID 5:三个人搬砖,每人还额外记个"校验条"→ 任何一个人倒了,靠剩下两人 + 校验条还能把砖凑齐。
其他生活例子:
- RAID 0:像把一份长报告拆成两半,两人同时抄写------交卷快,但一人丢稿就凑不齐。
- RAID 1:像重要合同一式两份存在两个保险柜------随时能拿,坏一个柜子也不怕。
- RAID 5:像三个人记会议纪要,每人记一部分内容,还多记一条"校验和"------谁缺勤,另外两人加校验能还原完整记录。
- JBOD:像几个收纳箱首尾相接摆成一排,东西先塞满第一个再塞第二个------容量变大了,但拿东西不会变快,也没有备份。
1.3 RAID 解决两个核心问题
🛡️ RAID
⚡ 性能
将 I/O 分散到多块盘
🔒 冗余
数据存在至少两块盘
一块坏了不丢数据
磁盘阵列(RAID) 是由很多价格较便宜的磁盘,组合成一个容量巨大的磁盘组,利用个别磁盘提供数据所产生加成效果提升整个磁盘系统效能。利用这项技术,将数据切割成许多区段,分别存放在各个硬盘上。磁盘阵列还能利用同位检查(Parity Check)的观念,在数组中任意一个硬盘故障时,仍可读出数据,在数据重构时,将数据经计算后重新置入新硬盘中。
⚠️ 注意 :有冗余能力的 RAID 仅避免因硬件损坏而导致业务终止,也能避免因硬件损坏而导致数据丢失,它不能取代备份的功能。
二、RAID 级别详解 📊
级别仅代表磁盘组织方式不同,没有上下之分。
2.1 RAID 级别总览图
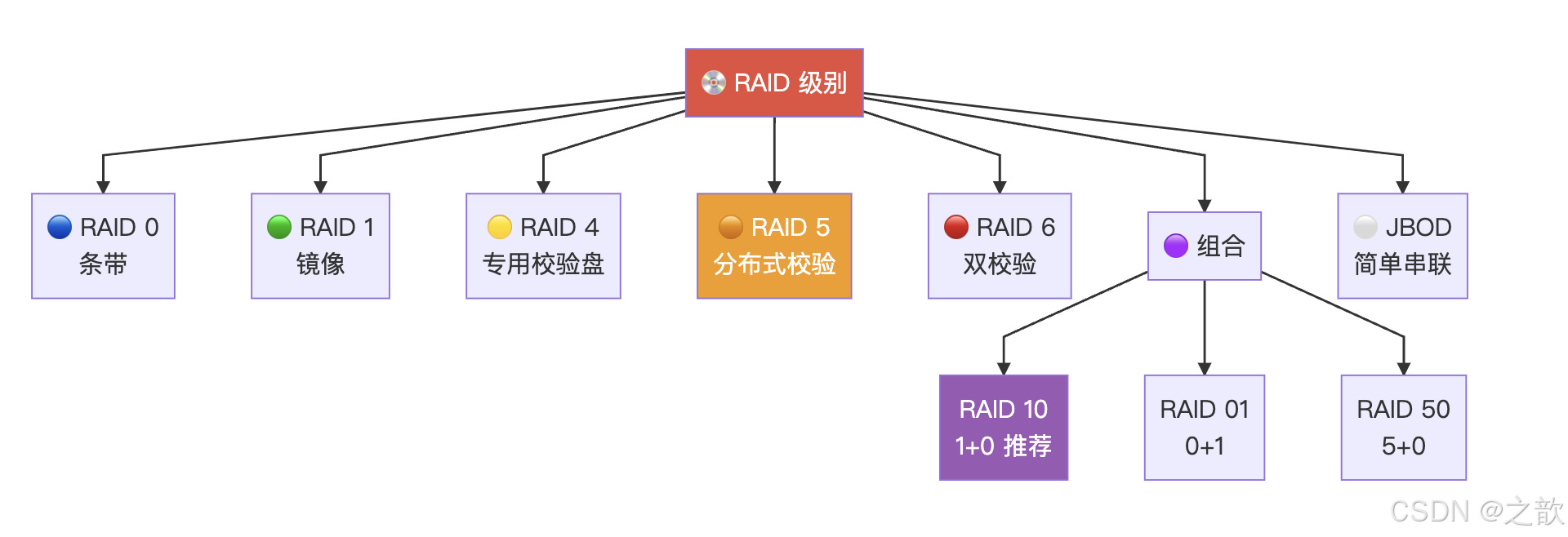
2.2 各级别详细对比
| 级别 | 名称 | 最少盘 | 读性能 | 写性能 | 冗余 | 空间利用率 | 说明 |
|---|---|---|---|---|---|---|---|
| RAID 0 | 条带卷 | 2 | ⬆️ 提升 | ⬆️ 提升 | ❌ 无 | n×S(100%) | 数据分散到各盘,一块坏全丢;性能不是越多盘越好,有拐点(抛物线) |
| RAID 1 | 镜像卷 | 2 | ⬆️ 提升 | ⬇️ 略降 | ✅ 有 | 1/2(50%) | 两块盘同步写入互为备份,成对出现 |
| RAID 4 | 专用校验盘 | 3 | ⬆️ 提升 | ⬆️ 提升 | ✅ 有 | (n-1)/n | 一块盘专门存校验码(异或运算),至多坏一块;校验盘易成瓶颈 |
| RAID 5 | 分布式校验 | 3 | ⬆️ 提升 | ⬆️ 提升 | ✅ 有 | (n-1)/n | 校验码分散到各盘(不需专门校验盘),分散访问频率,常用 |
| RAID 6 | 双校验 | 4 | ⬆️ 提升 | ⬆️ 提升 | ✅ 有 | (n-2)/n | 两块校验盘,至多允许坏 2 块 |
| RAID 10 | 1+0 | 4 | ⬆️ 提升 | ⬆️ 提升 | ✅ 有 | 1/2 | 先做 RAID1 镜像组,再做 RAID0 条带;同组不能同时坏;推荐 |
| RAID 01 | 0+1 | 4 | ⬆️ 提升 | ⬆️ 提升 | ✅ 有 | 1/2 | 先做 RAID0 再做 RAID1;不同组不能都坏盘 |
| RAID 50 | 5+0 | 6 | ⬆️ 提升 | ⬆️ 提升 | ✅ 有 | (n-2)/n | 多组 RAID5 再条带;同组 RAID5 内不允许同时坏 2 盘 |
| JBOD | 简单串联 | 2 | --- 无提升 | --- 无提升 | ❌ 无 | 100% | Just a Bunch Of Disks;多盘串联当一块用,数据写满一块再写下一块 |
各级别一句话生活例子 :RAID 10 = 先两两备份(像夫妻各有一份钥匙),再让多对一起干活,既快又稳;RAID 01 = 先两两分工干得快,再给这两组各备一份------一组全坏就没了;RAID 50 = 多组"三人带校验"小队再一起条带干活,适合大盘阵;JBOD = 几个箱子首尾相接,先塞满第一个再塞第二个,没有分工也没有备份。
2.3 RAID 10 vs RAID 01 图解
RAID 10 结构(推荐):先镜像再条带
RAID 0 条带层
RAID 1 镜像组 1
RAID 1 镜像组 2
盘 A
盘 B
盘 C
盘 D
RAID 01 结构:先条带再镜像
RAID 1 镜像层
RAID 0 条带组 1
RAID 0 条带组 2
盘 A
盘 B
盘 C
盘 D
- RAID 10 :假设 disk0 坏掉,只需在同组内部修复;推荐。
- RAID 01:假设两个条带组各坏一块盘,整个阵列可能挂掉("牵一发动全身")。
2.4 RAID 5 原理说明
RAID 5 不单独指定的奇偶盘,而是在所有磁盘上交叉地存取数据及奇偶校验信息(异或运算校验码)。相比 RAID 4,不需要专门的校验盘,这样就能分散开访问频率,避免校验盘成为瓶颈。可以挂掉一个盘,但是不能挂掉两个以上。
生活例子 :RAID 4 像小组里固定一个人专门记"校验本" ,每次交作业都要找他核对,这个人特别忙、容易坏;RAID 5 是大家轮流记校验,每个人的本子上既有自己的数据也有一部分校验,谁坏了别人都能补上,而且没有"单点忙人"。
2.5 各级别选择原因与使用场景 📌
下面按「为什么选它」「典型使用场景」「不适合场景」说明,便于在实际环境中做选择。
| 级别 | 选择原因 | 典型使用场景 | 不适合场景 |
|---|---|---|---|
| RAID 0 | 需要最高顺序读写、容量合并,能接受单盘故障即全丢 | 临时/缓存盘、视频剪辑缓存、科学计算中间结果、游戏盘 | 任何需要数据安全或 7×24 业务的系统 |
| RAID 1 | 需要简单镜像、一块坏不影响业务,容量要求不高 | 系统盘 /boot、数据库日志盘、小容量高可用 | 大容量存储(空间浪费 50%) |
| RAID 4 | 需要校验冗余但可接受专用校验盘瓶颈 | 读多写少且对校验盘压力可控的场景;实际较少用 | 写密集、随机写多的应用 |
| RAID 5 | 需要冗余 + 较高空间利用率 + 读写都提升,成本适中 | 文件服务器、通用数据库、备份存储、NAS | 写非常密集或对单盘故障重建时间敏感 |
| RAID 6 | 允许同时坏 2 块盘,重建期间更安全 | 大容量归档、长期备份、监控录像、冷数据 | 盘数少(4 盘时利用率仅 50%)或追求极致写性能 |
| RAID 10 | 既要性能又要冗余,可接受 50% 空间 | 数据库库文件、虚拟化存储、高并发 OLTP | 预算紧且需要更大可用容量时 |
| RAID 01 | 理论上与 RAID10 类似,但故障域更大 | 一般不推荐,仅在已有架构约束下才考虑 | 新建项目优先选 RAID10 |
| RAID 50 | 大容量 + 多组 RAID5 条带,冗余与性能折中 | 大型文件服务器、多盘位存储、视频/媒体库 | 盘数不足 6 块或运维能力有限 |
| JBOD | 仅需把多盘当一块大盘用,不关心性能与冗余 | 简单扩容、冷数据堆放、实验环境 | 生产业务、需要性能或可靠性的场景 |
选择决策简图(按需求优先考虑):
容量灵活、可扩缩
性能或容错
能
不能
要最大容量
要最好性能+冗余
只要简单镜像
需要多块盘组合
最在意什么?
用 LVM
能接受丢盘即丢数据吗?
RAID 0
容量 vs 冗余?
RAID 5/6
RAID 10
RAID 1
常见场景一句话:
- 个人/游戏机、临时数据:RAID 0 或单盘 + 备份。
- 公司文件服务器、NAS:RAID 5 或 RAID 6(盘多时)。
- 数据库、虚拟化:RAID 10 更常见。
- 归档、备份、监控:RAID 6 或 RAID 5,视盘数与预算而定。
- 系统盘、关键小容量:RAID 1。
三、硬件 RAID 与软件 RAID 🔧
| 对比项 | 🖲️ 硬件 RAID | 💻 软件 RAID |
|---|---|---|
| 实现方式 | 主板含 RAID 卡,在 BIOS 中配置 | 内核 md(Multi Disk) 模块实现 |
| 设备文件 | 系统看到的是"一块 RAID 盘" | /dev/md0、/dev/md1 ... |
| 管理工具 | RAID 卡自带管理程序 | mdadm 命令 |
| 性能 | 独立处理器,不占 CPU | 性能取决于 CPU 能力与空闲度 |
| 分区类型 | 按需 | 必须设为 fd(Linux raid autodetect) |
| 驱动 | 装系统时需要 RAID 卡驱动 | 内核自带 md 模块 |
| 生产建议 | ✅ 推荐 | ⚠️ 仅用于学习了解 |
生活例子 :硬件 RAID 像请搬家公司------他们自带卡车和工人(独立芯片),你只负责说"把这几个箱子拼成一组";软件 RAID 像自己找几个朋友一起搬------用你家的 CPU 来算怎么分数据、怎么校验,电脑越忙,搬得越慢。所以生产环境一般用"搬家公司"(硬件 RAID),学习或临时用才用"自己搬"(软件 RAID)。
软件 RAID 注意事项:
- 做软 RAID 的硬盘必须标识为 fd 类型,这样操作系统使用 RAID 设备时会在硬盘上存储元数据(记录软 RAID 信息),否则系统挂掉后 RAID 数据将无法使用。
- 不应该使用同一个磁盘上的多个分区创建 RAID 设备(虽然技术上可行)。
- Linux 通过设备文件访问设备,硬盘在 Linux 中被模拟成 sda/hda 等,md 模块将硬盘模拟成
/dev/md#文件,操作系统通过它操作 RAID 设备。
四、mdadm 命令详解 🛠️
4.1 mdadm 模式总览
生活类比 :把 mdadm 想成组乐队 ------创建 -C = 第一次把几个人拉成一支乐队;管理(-f/-r/-a) = 谁不行就标记下岗、谁走了就除名、招新成员顶替;监控 -F = 盯着乐队状态看有没有人掉线;装配 -A = 按之前记下来的名单(/etc/mdadm.conf)重新把乐队组起来;停止 -S = 乐队解散,下次要用再"装配"一次。
🛠️ mdadm
📦 创建模式 -C
🔧 管理模式
👁️ 监控模式 -F
📈 增长模式 -G
🔗 装配模式 -A
⏹️ 停止 -S
📋 详情 -D
4.2 创建模式(-C)专用选项
| 选项 | 说明 | 生活例子 |
|---|---|---|
-l # |
指明 RAID 级别(0/1/5/10 等) | 乐队类型:二人对半分(0)、二人同唱(1)、三人带校验(5)等 |
-n # |
用于创建 RAID 的磁盘设备个数 | 正式队员人数 |
| `-a yes | no` | 是否自动创建设备文件(/dev/md#) |
-c CHUNK_SIZE |
Chunk 大小,默认 64K;存大文件可改大,存小文件可改小;需为 2^n | 每次"分活儿"的最小单位:大文件用大块、小文件用小块,减少拆装 |
-x # |
空闲盘(热备)个数;某盘坏掉时空闲盘自动替补;-x + -n = 后面设备总数 | 替补队员人数,有人下场自动顶上去 |
4.3 管理模式
| 选项 | 说明 | 生活例子 |
|---|---|---|
-f /dev/sdX |
将某成员标记为 faulty(坏的) | 宣布"这名队员受伤下场"(模拟坏盘时用) |
-r /dev/sdX |
从阵列中移出某成员 | 正式除名,不再用这块盘 |
-a /dev/sdX |
向阵列添加新成员(添加的盘大小必须和之前的一致) | 招新队员顶替,新盘大小要和原来的盘一致,否则"身高不齐"没法排 |
4.4 其他操作
| 操作 | 命令 | 生活例子 |
|---|---|---|
| 查看阵列详情 | mdadm -D /dev/md# |
看这支"乐队"谁在岗、谁坏了、级别和容量 |
| 查看状态 | cat /proc/mdstat |
看系统里有哪些 RAID"乐队"、是否在同步 |
| 动态查看同步进度 | watch -n 1 'cat /proc/mdstat' |
每隔 1 秒刷新,像盯着进度条看重建/同步到哪了 |
| 停止阵列 | mdadm -S /dev/md# |
乐队解散,设备暂时不用了 |
| 装配阵列 | mdadm -A /dev/md# |
按名单(配置文件)把乐队重新组起来,重启后常用 |
| 保存配置 | mdadm -D --scan > /etc/mdadm.conf |
把当前乐队名单写到本子上,下次开机按名单装配 |
4.5 格式化与 stride 优化
创建 RAID 时如果没指定 chunk 大小,则默认 64K。一个 chunk 有几个数据块取决于 block 大小:假设 block=4096,则 64K/4K=16 块。RAID 每次都要计算块数,因此格式化时直接指定 block 和 stride 可以优化性能:
bash
# chunk=64K, block=4096 → stride=64K/4K=16
mke2fs -j -E stride=16 -b 4096 /dev/md0生活例子 :RAID 做好后还是一块"毛坯空间",mke2fs/mkfs 相当于在这块空间里画格子、贴标签 (建文件系统),以后文件才能按格子存。stride 相当于告诉文件系统:"我底层是条带盘,你每画 16 个小格(block)对应 RAID 的一 stripe",这样读写对齐,少做多余计算,就像搬货时按托盘大小摆,一托盘正好一车,不用拆来拆去。
五、软件 RAID 实战(含完整命令输出)🎯
5.1 创建 RAID0(2 块盘)
一句话 :先给两块盘"分区并贴上 RAID 用的标签"(fd),再用 mdadm 组队 成一块逻辑盘,画格子 (格式化),最后挂到目录上才能用------就像新买了一个柜子,先组装好、打好格子,再放到某个房间门口(挂载点),以后从那个门进去就是开这个柜子。
bash
# 首先用 fdisk 创建分区,类型改为 fd
mdadm -C /dev/md0 -a yes -l 0 -n 2 /dev/sda{5,6}
cat /proc/mdstat # 查看当前系统的 RAID 设备
mke2fs -j /dev/md0 # 格式化
fdisk -l # 查看所有挂载设备
mount /dev/md0 /mnt # 挂载
# 如果设备中有 lost+found 那么表示挂载成功5.2 创建 RAID1(2 块盘)------ 含完整操作
bash
# fdisk 创建分区
fdisk /dev/sdb
# n: 创建新的分区
# p: 查看分区
# t: 修改分区参数
# fd: 将分区参数改成 fd (Linux raid autodetect)
# w: 保存退出
cat /proc/partitions # 查看分区
# 创建 RAID1
mdadm -C /dev/md1 -a yes -n 2 -l 1 /dev/sda7 /dev/sda8
cat /proc/mdstat # 查看状态
fdisk -l # 查看分区
mke2fs -j /dev/md1 # 格式化
mount /dev/md1 /media/ # 挂载
cd /media/ # 进入分区
# 看到 lost+found 即挂载成功5.3 RAID1 模拟损坏、移除与添加
完整命令输出:
bash
# 查看 RAID1 详细信息
# mdadm -D /dev/md1 效果同 mdadm --detail /dev/md1
mdadm -D /dev/md0
Number Major Minor RaidDevice State
0 8 17 0 active sync /dev/sdb1
1 8 18 1 active sync /dev/sdb2
# 模拟 sdb1 挂掉
mdadm /dev/md0 -f /dev/sdb1
# mdadm: set /dev/sdb1 faulty in /dev/md0
# 此时文件仍可正常访问(镜像盘还在)
cat inittab
# inittab is only used by upstart for the default runlevel.
# 查看状态:sdb1 已变为 faulty
mdadm -D /dev/md0
# Number Major Minor RaidDevice State
# 0 0 0 0 removed
# 1 8 18 1 active sync /dev/sdb2
# 0 8 17 - faulty /dev/sdb1
# 新建分区 sdb3(类型 fd),然后:
# 移除坏盘
mdadm /dev/md0 -r /dev/sdb1
# mdadm: hot remove /dev/sdb1
# 添加新盘(大小必须一致)
mdadm /dev/md0 -a /dev/sdb3
# mdadm: added /dev/sdb3
# 查看同步进度
cat /proc/mdstat
# 最终状态
mdadm -D /dev/md0
# Number Major Minor RaidDevice State
# 2 8 19 0 active sync /dev/sdb3
# 1 8 18 1 active sync /dev/sdb25.4 停止与装配 RAID
bash
# 停止前必须先卸载
umount /dev/md0
mdadm -S /dev/md0
# mdadm: stopped /dev/md0
# 保存装配信息
mdadm -D --scan > /etc/mdadm.conf
# 重新装配
mdadm -A /dev/md1
# 会读取 /etc/mdadm.conf(不存在则需手动创建)5.5 RAID 0 不支持热备(空闲盘)
bash
mdadm -C /dev/md0 -a yes -n 2 -l 0 /dev/sdb1 /dev/sdb2 -x 1 /dev/sdb3
# mdadm: spare-devices setting is incompatible with raid level 0
# RAID 0 没有冗余能力,所以不支持设置空闲盘5.6 练习 1 完整输出:10G RAID1 + 1 块热备 + chunk 128K
bash
mdadm -C /dev/md0 -a yes -n 2 -x 1 -l 1 -c 128 /dev/sda{6,7} /dev/sdb1
# Continue creating array? y
# mdadm: array /dev/md0 started.
mkfs.ext4 /dev/md0
mdadm -D /dev/md0
# /dev/md0:
# Version : 1.2
# Creation Time : Wed Oct 28 01:25:39 2015
# Raid Level : raid1
# Array Size : 10479232 (9.99 GiB 10.73 GB)
# Raid Devices : 2
# Total Devices : 3
# Active Devices : 2
# Working Devices : 3
# Spare Devices : 1
#
# Number Major Minor RaidDevice State
# 0 8 6 0 active sync /dev/sda6
# 1 8 7 1 active sync /dev/sda7
# 2 8 17 - spare /dev/sdb15.7 练习 2 完整输出:5G RAID5 + chunk 256K + ext4 + 开机挂载
bash
# 创建三个分区各约 2560M(+2.5G 不行,写 +2560M),类型 fd
mdadm -C /dev/md1 -a yes -n 3 -l 5 -c 256 /dev/sda8 /dev/sdb{5,6}
# mdadm: array /dev/md1 started.
mdadm -D /dev/md1
# Raid Level : raid5
# Array Size : 5249024 (5.01 GiB 5.38 GB)
# Chunk Size : 256K
# Layout : left-symmetric
#
# Number Major Minor RaidDevice State
# 0 8 8 0 active sync /dev/sda8
# 1 8 21 1 active sync /dev/sdb5
# 3 8 22 2 active sync /dev/sdb6
mkfs -t ext4 /dev/md1
blkid /dev/md1
# /dev/md1: UUID="786b54c9-d523-421f-80e3-535618f88b4a" TYPE="ext4"
mkdir /backup
# 在 /etc/fstab 添加:
# UUID=786b54c9-d523-421f-80e3-535618f88b4a /backup ext4 defaults,noatime,acl 0 0
mount -a
mount
# ...
# /dev/md1 on /backup type ext4 (rw,noatime,acl)
# df 查看结果:
# /dev/md1 ext4 4.9G 11M 4.6G 1% /backup六、先弄懂:LVM 是什么?为什么需要它? 🤔
6.1 一句话解释
LVM (Logical Volume Manager,逻辑卷管理器)= 在物理磁盘之上加一层"虚拟层",让你可以像玩积木一样灵活调整分区大小------扩大、缩小、跨盘合并,而不用重新分区。
6.2 生活类比
- 传统分区:像砌好的墙,隔间大小固定,想改得拆墙重建。
- LVM:像可移动的隔断,随时拉宽拉窄,还能加新板子扩展。
再举几个例子:
- PV:像把几个抽屉贴上"可调配"标签,表示这些空间可以统一分配。
- VG :像把多个带标签的抽屉合并成一个大储物间,不关心东西具体在哪个抽屉,只关心总共还能放多少。
- LV:像在储物间里用隔板划出一块区域,专门放"工作资料"或"电影"------这块区域可以以后拉大或缩小,甚至跨多个抽屉。
- 扩展 LV :像发现"工作资料"那块不够放了,从储物间里再划一点空间给它,不用把别的东西搬走(在线扩展)。
- 快照:像给当前房间拍一张照,以后房间再怎么乱,照片里的样子还能拿出来看(只读备份)。
6.3 LVM 三层结构
💾 硬盘分区
/dev/sda10
💾 硬盘分区
/dev/sda11
💾 硬盘分区
/dev/sda12
📦 PV 物理卷
📦 PV 物理卷
📦 PV 物理卷
🏗️ VG 卷组 myvg
(多个 PV 合成一个大池子)
📁 LV 逻辑卷 testlv
(从池子里划出一块)
📁 LV 逻辑卷 datalv
🔧 文件系统 ext4
📂 挂载点 /mnt
| 层级 | 全称 | 作用 | 类比 |
|---|---|---|---|
| PV | Physical Volume 物理卷 | 在分区上打标记,告诉系统"这块可以给 LVM 用" | 一块积木 / 一个贴上"可调配"的抽屉 |
| VG | Volume Group 卷组 | 把多个 PV 合成一个大池子;按 PE(Physical Extent,默认 4MB)分配空间 | 一桶积木 / 一个大储物间 |
| LV | Logical Volume 逻辑卷 | 从 VG 里划出一块空间,格式化后当分区用 | 从桶里取几块积木拼出来 / 在储物间里划出的一个隔间 |
生活例子 :PE 就像储物间里的最小单位格子(默认 4MB 一格)。你要划 100MB 给一个 LV,系统就给你 25 个格子拼在一起;你要 8MB 的 PE,格子变大,同样容量用的格子数就少,管理更省事,但分配时粒度变粗。
设备文件:/dev/myvg/testlv 或 /dev/mapper/myvg-testlv(两者等价)。
6.4 MD 与 DM
| 缩写 | 全称 | 设备文件 | 用途 |
|---|---|---|---|
| MD | Multi Device | /dev/md# |
软件 RAID |
| DM | Device Mapper | /dev/mapper/xxx |
LVM2、快照、多路径 |
七、LVM 命令详解 📋
整体生活类比 :LVM 就像管理一个储物间 ------pvcreate 把抽屉标成"可调配";vgcreate 把几个抽屉合成一间房;lvcreate 在房里划出一块区域并起名;lvextend 把这块区域扩大;lvreduce 把这块区域缩小(要先清空多余东西);pvmove 是把某个抽屉里的东西搬到另一个抽屉,腾出抽屉撤掉。
7.1 PV(物理卷)命令
| 命令 | 作用 | 示例 | 生活例子 |
|---|---|---|---|
pvcreate |
创建 PV | pvcreate /dev/sda{10,11} |
给这几个分区贴上"归 LVM 管"的标签,相当于把抽屉标成可调配 |
pvremove |
移除 PV | pvremove /dev/sda10 |
撕掉标签,这块不再参与 LVM(要先搬空数据或移出 VG) |
pvs |
简洁查看 PV 列表 | pvs |
一眼看到哪些抽屉是"可调配"的、在哪个房间 |
pvdisplay |
查看 PV 详细信息 | pvdisplay /dev/sda10 |
看这个抽屉多大、用了多少、属于哪个 VG |
pvscan |
扫描有多少 PV | pvscan |
全屋扫一遍,找出所有贴了标签的抽屉 |
pvmove |
移动 PV 上的数据 | pvmove /dev/sda10 /dev/sda11 |
把 A 抽屉里的东西搬到 B 抽屉,腾空 A 以便撤掉或送修 |
7.2 VG(卷组)命令
| 命令 | 作用 | 示例 | 生活例子 |
|---|---|---|---|
vgcreate |
创建 VG | vgcreate myvg /dev/sda{10,11} |
把几个抽屉合并成一间"储物间",起名叫 myvg |
vgcreate -s 8M |
创建时指定 PE 大小(默认 4MB) | vgcreate -s 8M myvg /dev/sda{10,11} |
这间房里的最小格子定为 8MB,以后划分按 8MB 为单位 |
vgremove |
删除 VG | vgremove myvg |
解散这间房(要先清空所有 LV) |
vgextend |
扩展 VG(加入新 PV) | vgextend myvg /dev/sda12 |
再搬进来一个抽屉,房间变大了 |
vgreduce |
缩减 VG(移出 PV) | vgreduce myvg /dev/sda11 |
把一个抽屉移出房间(要先 pvmove 把上面的数据迁走) |
vgs / vgdisplay / vgscan |
查看 / 详细查看 / 扫描 | 略 | 看房间有多大、用了多少、还有多少空闲 |
7.3 LV(逻辑卷)命令
| 命令 | 作用 | 示例 | 生活例子 |
|---|---|---|---|
lvcreate |
创建 LV | lvcreate -L 50M -n testlv myvg |
在 myvg 这间房里划出 50MB,起名叫 testlv,像划出一块"工作区" |
lvremove |
删除 LV(需先卸载) | lvremove /dev/myvg/testlv |
取消这块区域,空间收回给房间(要先 umount 并确认数据不要了) |
lvextend |
扩展 LV | lvextend -L 5G /dev/myvg/testlv |
把"工作区"从 2G 扩到 5G,从房间剩余空间里再划一块接上 |
lvreduce |
缩减 LV | lvreduce -L 3G /dev/myvg/testlv |
把工作区缩小(要先缩小文件系统、确保数据能装下) |
lvs / lvdisplay |
查看 LV | 略 | 看划了哪些区、各自多大、用了多少 |
八、LVM 实战(创建、扩展、缩减)🎯
8.1 完整创建流程
bash
# 1. 用 fdisk 创建分区,类型改为 8e (Linux LVM)
fdisk /dev/sda
# p n +7G n +3G n +5G
# t → 10 → 8e t → 11 → 8e t → 12 → 8e
# w: 保存退出
# 2. 创建 PV
pvcreate /dev/sda{10,11}
pvs # 查看 PV 列表
pvdisplay /dev/sda10 # 查看某 PV 详细信息
pvscan # 查看有多少 PV
# 3. 创建 VG(可指定 PE 大小)
vgcreate -s 8M myvg /dev/sda{10,11}
vgdisplay myvg
# 4. VG 的缩减与扩展
vgreduce myvg /dev/sda11 # 减少 myvg
vgextend myvg /dev/sda12 # 扩展 VG
# 5. 创建 LV
lvcreate -L 50M -n testlv myvg # 创建 50M 的逻辑卷
lvs # 查看逻辑卷信息
lvdisplay /dev/myvg/testlv # 详细查看
# 6. 格式化并挂载
mke2fs -j /dev/myvg/testlv # 在 LV 上"画格子",建立 ext3 文件系统
mount /dev/myvg/testlv /mnt # 把这块空间"放到" /mnt 这扇门后面,访问 /mnt 就是在用这个 LV
ls /mnt # 看到 lost+found 即成功
# 7. 删除 LV(先卸载)
umount /mnt
lvremove /dev/myvg/testlv
# lvremove /dev/mapper/myvg-testlv 效果一样
# 如果移除不掉,先取消挂载再移除8.2 扩展逻辑卷 ⬆️
lvextend -L 5G
resize2fs -p
📦 LV 当前 2G
📦 LV 扩到 5G
📂 文件系统也扩到 5G
bash
lvcreate -L 2G -n testlv myvg # 创建 2G 分区
mke2fs -j /dev/myvg/testlv # 格式化
mkdir /users
# vi /etc/fstab 添加:
# /dev/myvg/testlv /users ext3 defaults,acl 0 0
mount -a
cd /users
ls
# lost+found 目录出现了
lvextend -L 5G /dev/myvg/testlv # 将逻辑分区扩展到 5G
df -lh # 此时文件系统还没扩
resize2fs -p /dev/myvg/testlv # 扩展文件系统(-p 能有多大就扩多大)
df -lh # 现在是 5G 了生活例子 :lvextend 相当于把"工作区"的隔板往外挪,房间里的空间变大了,但文件系统 还不知道------它还以为自己只有原来的格子。resize2fs 就是告诉文件系统:"你这块地方变大了,多出来的格子也可以用了",就像给柜子多加了几层隔板并登记在册。
8.3 缩减逻辑卷 ⬇️(注意顺序!)
⏹️ umount 卸载
🔍 e2fsck -f 强检
📉 resize2fs 缩文件系统
📉 lvreduce 缩 LV
▶️ mount 重新挂载
⚠️ 缩减三大注意:
- 不能在线缩减,得先卸载。
- 确保缩减后的空间大小依然能存储原有的所有数据。
- 在缩减之前应该先强行检查文件,以确保文件系统处于一致性状态。
生活例子 :缩减像把柜子改小------必须先停用(umount)、清点东西确保能装进新尺寸(df 看用量)、检查柜子没坏(e2fsck),再把"格子"改小(resize2fs),最后把隔板往里挪(lvreduce),再重新启用。顺序反了就会"隔板比格子小",数据错乱。
bash
df -lh # 确保剩余空间大小
umount /users # 卸载
e2fsck -f /dev/myvg/testlv # 强制检测
resize2fs /dev/myvg/testlv 3G # 缩减文件系统到 3G
lvreduce -L 3G /dev/myvg/testlv # 缩减 LV 到 3G
mount -a # 重新挂载九、快照卷(Snapshot)📸
9.1 快照是什么
快照 = 某一刻数据的"定格照片"。创建快照后,可以挂载快照卷进行只读备份,而源卷继续正常使用。
生活例子 :像给桌面拍一张照------之后你继续在桌上堆东西、删文件,但照片里的那一刻 永远可以拿出来看;或者像合同复印一份锁进柜子,原件继续用,需要时拿复印件对照。快照卷就是那个"复印件",只读,用来备份或对比,用完了可以删掉(lvremove)。
9.2 快照三个要点
- 生命周期 为整个数据时长;在这段时长内,数据的增长量不能超出快照卷大小。
- 快照卷应该是只读的 (
-p r)。 - 跟原卷在同一卷组内。
9.3 快照操作流程
📸 lvcreate -s
创建快照
📂 mount
挂载快照
📦 tar 打包
备份数据
⏹️ umount
卸载
🗑️ lvremove
删除快照
bash
# 创建只读快照,50M
lvcreate -L 50M -n test-snap -s -p r /dev/myvg/testlv
# -s: 表示快照卷
# -p r|w: r 表示只读,w 表示读写
lvs # 查看
# 挂载快照并打包备份
mount /dev/myvg/test-snap /mnt # 注意是挂载快照卷名:testlv-snap
cd /mnt
tar -jcf /tmp/users.tar.bz2 /users/inittab # 压缩快照卷
# 卸载并删除快照
umount /mnt
lvremove /dev/myvg/test-snap # 移除快照卷
# 从备份恢复
tar xf /tmp/users.tar.bz2 -C ./ # 将文件解压到当前目录九补充、RAID 与 LVM 对比 ⚖️
RAID 和 LVM 解决的是不同层面的问题 :RAID 管「多块盘如何组成一块更可靠/更快的盘」,LVM 管「这一块(或几块)盘上的空间如何灵活划分与调整」。二者可以同时使用(例如先做 RAID,再在 RAID 设备上做 LVM)。
核心对比表
| 对比维度 | RAID 磁盘阵列 | LVM 逻辑卷管理 |
|---|---|---|
| 主要目标 | 提高可靠性 (冗余)或性能(条带),或两者兼顾 | 提高容量管理灵活性(扩缩、合并多盘为一池) |
| 作用层次 | 底层块设备:多块物理盘 → 一个逻辑块设备(如 /dev/md0) |
在块设备之上:多个 PV → VG → 多个 LV,再格式化 |
| 是否改盘上数据布局 | 是(条带/镜像/校验分布在不同盘上) | 否(只是把若干块设备合成池再切分) |
| 典型操作 | 创建阵列、加/拔盘、热备、重建 | 创建/删除/扩展/缩减 LV,做快照,跨盘迁移 |
| 单盘坏掉 | 有冗余的级别:可继续用,换盘重建;RAID0:整阵列为不可用 | 若该盘是某 PV,仅影响该 PV 上的数据;VG 中其他 PV 上的 LV 可正常用(取决于该 LV 是否跨此盘) |
| 容量 | 由级别决定(如 RAID1 为 50%,RAID5 为 (n-1)/n) | 由 VG 内 PV 总和决定,可随时加 PV 扩 VG |
| 能否替代对方 | 不能替代 LVM(不提供「随意扩缩分区」) | 不能替代 RAID(不提供冗余或条带性能) |
为什么需要 RAID?为什么需要 LVM?
| 技术 | 要解决的核心问题 | 典型原因 |
|---|---|---|
| RAID | 单盘故障导致业务中断或数据丢失;单盘 I/O 成为瓶颈 | 需要高可用、更高读写带宽、在有限预算下用多块小盘替代一块大盘 |
| LVM | 分区大小固定,扩缩都要备份、重分区、恢复,多盘空间无法统一调配 | 需要在线扩盘、多盘合成一个池再划分、快照备份、灵活迁移 |
使用场景简表
| 场景 | 更依赖 RAID | 更依赖 LVM | 说明 |
|---|---|---|---|
| 数据库数据目录 | ✅ 常用 RAID10/5 | ✅ 常用 LVM | RAID 保证性能与容错,LVM 方便扩缩与快照 |
| 文件服务器 / NAS | ✅ RAID5/6/10 | ✅ 常配合 LVM | RAID 提供冗余,LVM 方便按目录分配/扩展空间 |
| 系统盘 /boot | ✅ 可用 RAID1 | ❌ 少用 | 小容量、高可用即可,一般不需 LVM |
| 云主机/虚拟化底层存储 | ✅ 存储层 RAID | ✅ 常见 LVM | 底层 RAID,上层 LVM 划分给不同 VM 或卷 |
| 仅想「把多块盘当一块用」且不关心冗余 | 可用 JBOD/RAID0 | ✅ 也可 LVM | 要灵活就 LVM,要极致顺序性能可 RAID0 |
| 只想在线扩大某个分区 | ❌ | ✅ | 纯 LVM 场景 |
组合使用关系(Mermaid)
盘1
/dev/md0
盘2
盘3
VG 卷组
LV1
LV2
ext4
xfs
层次 :物理盘 → RAID 阵列(如 /dev/md0)→ LVM 的 PV/VG/LV → 文件系统。
生活例子 :格式化(mke2fs/mkfs) = 在空房间里画格子、贴标签,规定以后文件按什么规则存;挂载(mount) = 把这块空间"放到"某个目录门口,进这个目录就是在用这块空间;umount = 把柜子从门口移开,门后面就看不到它了;/etc/fstab = 一张"开机时自动把哪些柜子放到哪些门口"的清单,重启后不用再手动 mount。
典型组合 :多块盘 → 做 RAID(如 RAID5)得到 /dev/md0 → 将 /dev/md0 做成 PV 加入 VG → 在 VG 上创建 LV 并格式化为 ext4/xfs 等 → 挂载使用。这样既有 RAID 的冗余/性能,又有 LVM 的扩缩与快照能力。
十、Shell 脚本与命令补充 🖥️
10.1 菜单脚本(版本一:带颜色)
bash
#!/bin/bash
#
cat << EOF
d|D) show disk usages.
m|M) show memory usages.
s|S) show swap usages.
*) quit.
EOF
#read -p "Your choice: " CHOICE
echo -n -e "\033[31mYour choice:\033[0m"
while [ $CHOICE != 'quit' ];do
case $CHOICE in
d|D)
echo "Disk usage: "
df -Ph ;;
m|M)
echo "Memory usage: "
free -m | grep "Mem" ;;
s|S)
echo "Swap usage: "
free -m | grep "Swap" ;;
*)
echo "Unknown.." ;;
esac
read -p "Again, your choice: " CHOICE
done10.2 菜单脚本(版本二:while 无限循环)
bash
#!/bin/bash
while [ 1 -eq 1 ]; do
echo ""
read -p "d|D) show disk usages.
m|M) show memory usages.
s|S) show swap usages.
quit|q) quit
your choice: " choice
case $choice in
d|D)
df -h ;;
m|M)
free -m|grep "Mem";;
s|S)
free -m|grep "Swap";;
quit|q)
exit 0 ;;
*)
echo "Unknow choice."
esac
done10.3 脚本编程控制结构
🖥️ 脚本控制结构
➡️ 顺序
🔀 选择
if / case
🔄 循环
for / while / until
while 循环(条件满足进入,不满足退出):
bash
while CONDITION; do
statement
doneuntil 循环(条件不满足进入,满足退出):
bash
until CONDITION; do
statement
donefor 循环(两种形式):
bash
for 变量 in 列表; do
循环体
done
for (( expr1; expr2; expr3 )); do
循环体
done10.4 脚本示例:小写转大写(until)
bash
#!/bin/bash
#
read -p "Input something :" STRING
until [ $STRING == 'quit' ]; do
echo $STRING | tr 'a-z' 'A-Z'
read -p "INPUT something:" STRING
done10.5 脚本示例:每隔 5 秒检测 hadoop 是否登录(until)
bash
#!/bin/bash
#
who | grep "hadoop" &> /dev/null
RETVAL=$?
until [ $RETVAL -eq 0 ]; do
sleep 5
echo "hadoop not login."
who | grep "hadoop" &> /dev/null
RETVAL=$?
done
echo "hadoop is logged in"也可以简写为:
bash
#!/bin/bash
#
until who | grep "hadoop" &> /dev/null; do
sleep 5
echo "hadoop not login."
done
echo "hadoop is logged in"10.6 脚本示例:1 到 100 求和(C 风格 for)
bash
#!/bin/bash
#
declare -i SUM=0
for ((I=1;I<=100;I++));do
let SUM+=$I
done
echo "1..100 value is $SUM"10.7 ext2 文件系统块组组成(复习)
超级块、GDT、block bitmap、inode bitmap、data blocks
10.8 文件系统挂载注意事项(复习)
- 挂载点事先存在
- 目录是否已经被其它进程使用
- 目录中的原有文件会被暂时隐藏(卸载以后又可以看见)
mount 指定设备方式:设备文件、LABEL=""、UUID=""
10.9 /etc/fstab 文件格式(复习)
text
设备 挂载点 文件系统类型 挂载选项 转储频率 检测次序
/dev/sda5 /mnt/test ext3 defaults 0 0如果是交换分区,挂载点是 swap,而不是一个目录。
10.10 tune2fs / dumpe2fs(复习)
tune2fs -l:显示超级块信息tune2fs -L:设定卷标tune2fs -o:设定默认挂载选项dumpe2fs -h:仅显示超级块信息
10.11 watch 命令
周期性执行指定命令,并以全屏方式显示结果(类似 tail -f):
bash
watch -n 1 'cat /proc/mdstat' # 每 1 秒刷新
watch -n 2 'df -h' # 每 2 秒查看磁盘10.12 文件系统类型
- ext2、ext3
- 查看当前内核支持的文件系统类型:
cat /proc/filesystems
10.13 安装 RHEL6.3 的方法
前提:CPU 支持硬件虚拟化技术。
- 创建虚拟机
- 下载 isos 目录中的
rhci-rhel-6.3-1.iso,并导入虚拟机的虚拟光驱 - 在 boot 提示符输入:
linux ip=172.16.x.1 netmask=255.255.0.0 gateway=172.16.0.1 dns=172.16.0.1 ks=http://172.16.0.1/rhel6.cfg
64 位系统:/lib(32 位库)、/lib64(64 位库)。
十一、练习题汇总 📝
11.1 RAID 练习
- 创建一个大小为 10G 的 RAID 1,要求有一个空闲盘,而且 CHUNK 大小为 128K。
- 创建一个大小为 5G 的 RAID5 设备,chunk 大小为 256K,格式化为 ext4 文件系统,要求开机自动挂载 /backup 目录,而且不更新访问时间戳,而且支持 acl 功能。
- 创建一个空间大小为 10G 的 RAID5 设备;其 chunk 大小为 32k;要求此设备开机时可以自动挂载至 /backup 目录。
11.2 LVM 练习
- 创建一个由两个物理卷组成的大小为 20G 的卷组 myvg,要求其 PE 大小为 16M;而后在此卷组中创建一个大小为 5G 的逻辑卷 lv1,此逻辑卷要能在开机后自动挂载至 /users 目录,且支持 ACL 功能。
- 缩减前面创建的逻辑卷 lv1 的大小至 2G。
11.3 脚本练习
-
写一个脚本:通过 ping 命令测试 192.168.0.151 到 192.168.0.254 之间的所有主机是否在线,如果在线就显示 "ip is up." 以绿色 显示;如果不在线就显示 "ip is down." 以红色显示。要求分别使用 while、until 和 for(两种形式)循环实现。
提示:
ping -c 1 -W 1 IP
附录
A. 控制器与适配器区别 🔌
- 控制器:集成在主板上的具有完善功能的模块(如集成网卡)。
- 适配器:只提供插槽还需要其他条件的(如独立网卡插在 PCI 上)。
B. Shell 颜色显示(ANSI 转义码)🎨
格式 :echo -e "\033[字背景颜色;字体颜色m字符串\033[控制码"
bash
echo -e "\033[1mHello\033[0m,world." # 高亮
echo -e "\033[32mHello\033[0m,world." # 绿色
echo -e "\033[1;32mHello\033[0m,world." # 高亮+绿色
echo -e "\033[1;37;41mHello\033[0m,world." # 白字红底让字体变为红色并闪烁:
bash
echo -e "\033[31m \033[05m 请确认您的操作,输入 [Y/N] \033[0m"字体颜色(30--37):
| 编码 | 颜色 | 编码 | 颜色 |
|---|---|---|---|
| 30 | 黑 | 34 | 蓝 |
| 31 | 红 | 35 | 紫 |
| 32 | 绿 | 36 | 深绿 |
| 33 | 黄 | 37 | 白 |
背景颜色(40--47):
| 编码 | 颜色 | 编码 | 颜色 |
|---|---|---|---|
| 40 | 黑 | 44 | 蓝 |
| 41 | 深红 | 45 | 紫 |
| 42 | 绿 | 46 | 深绿 |
| 43 | 黄 | 47 | 白 |
ANSI 控制码:
| 控制码 | 效果 | 控制码 | 效果 |
|---|---|---|---|
\33[0m |
关闭所有属性 | \33[07m |
反显 |
\33[01m |
高亮 | \33[08m |
消隐 |
\33[04m |
下划线 | \33[nA |
光标上移 n 行 |
\33[05m |
闪烁 | \33[nB |
光标下移 n 行 |
\33[nC |
光标右移 n 行 | \33[nD |
光标左移 n 行 |
\33[y;xH |
设置光标位置 | \33[2J |
清屏 |
\33[K |
清到行尾 | \33[s |
保存光标位置 |
\33[u |
恢复光标位置 | \33[?25l |
隐藏光标 |
\33[?25h |
显示光标 |
C. awk 基础 📊
bash
df -Ph | awk '{print $1}' # 取第一列
df -Ph | awk '{print $1,$3}' # 取第 1、3 列
df -Ph | awk '{print $0}' # 显示每一行所有字段
df -Ph | awk '{print $NF}' # 每行最后一个字段
awk -F: '{print $1,$3}' /etc/passwd # 以冒号分隔取第 1、3 列
fdisk -l 2>/dev/null | grep "^Disk /dev/[sh]d[a-z]" | awk -F: '{print $1}'
# 2> 去除错误信息;-F: 以冒号 split;print $1 打印第一段D. 其他命令
lsmod:显示已载入系统的模块bss:Block Started by Symbolreadelf -h、readelf -S、objdump -h:查看 ELF 文件信息shutdown -h now:Linux 关机命令