[root@bigdata137 bin]# ./yarn-session.sh -nm test
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/flink-1.17.0/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop-3.3.5/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2026-02-13 14:35:16,215 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.memory.process.size, 1728m
2026-02-13 14:35:16,220 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.bind-host, 0.0.0.0
2026-02-13 14:35:16,221 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.execution.failover-strategy, region
2026-02-13 14:35:16,221 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.address, 192.168.67.137
2026-02-13 14:35:16,221 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.memory.process.size, 1024m
2026-02-13 14:35:16,221 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.port, 6123
2026-02-13 14:35:16,221 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.bind-address, 0.0.0.0
2026-02-13 14:35:16,221 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.port, 8081
2026-02-13 14:35:16,221 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.bind-host, 0.0.0.0
2026-02-13 14:35:16,221 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.host, 192.168.67.137
2026-02-13 14:35:16,221 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: parallelism.default, 1
2026-02-13 14:35:16,221 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.numberOfTaskSlots, 1
2026-02-13 14:35:16,221 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.address, 192.168.67.137
2026-02-13 14:35:16,420 WARN org.apache.hadoop.util.NativeCodeLoader [] - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2026-02-13 14:35:16,445 INFO org.apache.flink.runtime.security.modules.HadoopModule [] - Hadoop user set to root (auth:SIMPLE)
2026-02-13 14:35:16,445 INFO org.apache.flink.runtime.security.modules.HadoopModule [] - Kerberos security is disabled.
2026-02-13 14:35:16,455 INFO org.apache.flink.runtime.security.modules.JaasModule [] - Jaas file will be created as /tmp/jaas-2140832887329830020.conf.
2026-02-13 14:35:16,484 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/usr/local/src/flink-1.17.0/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2026-02-13 14:35:16,531 INFO org.apache.hadoop.yarn.client.DefaultNoHARMFailoverProxyProvider [] - Connecting to ResourceManager at bigdata138/192.168.67.138:8032
2026-02-13 14:35:16,722 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (102.400mb (107374184 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2026-02-13 14:35:16,737 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (172.800mb (181193935 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2026-02-13 14:35:16,860 INFO org.apache.hadoop.conf.Configuration [] - resource-types.xml not found
2026-02-13 14:35:16,860 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils [] - Unable to find 'resource-types.xml'.
2026-02-13 14:35:16,932 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured TaskManager memory is 1728 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 320 MB may not be used by Flink.
2026-02-13 14:35:16,932 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1728, slotsPerTaskManager=1}
2026-02-13 14:35:16,989 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: metrics-datadog
2026-02-13 14:35:16,992 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: external-resource-gpu
2026-02-13 14:35:16,992 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: metrics-graphite
2026-02-13 14:35:16,992 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: metrics-influx
2026-02-13 14:35:16,992 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: metrics-slf4j
2026-02-13 14:35:16,992 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: metrics-prometheus
2026-02-13 14:35:16,992 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: metrics-statsd
2026-02-13 14:35:16,992 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: metrics-jmx
2026-02-13 14:35:21,040 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (102.400mb (107374184 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2026-02-13 14:35:21,051 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cannot use kerberos delegation token manager, no valid kerberos credentials provided.
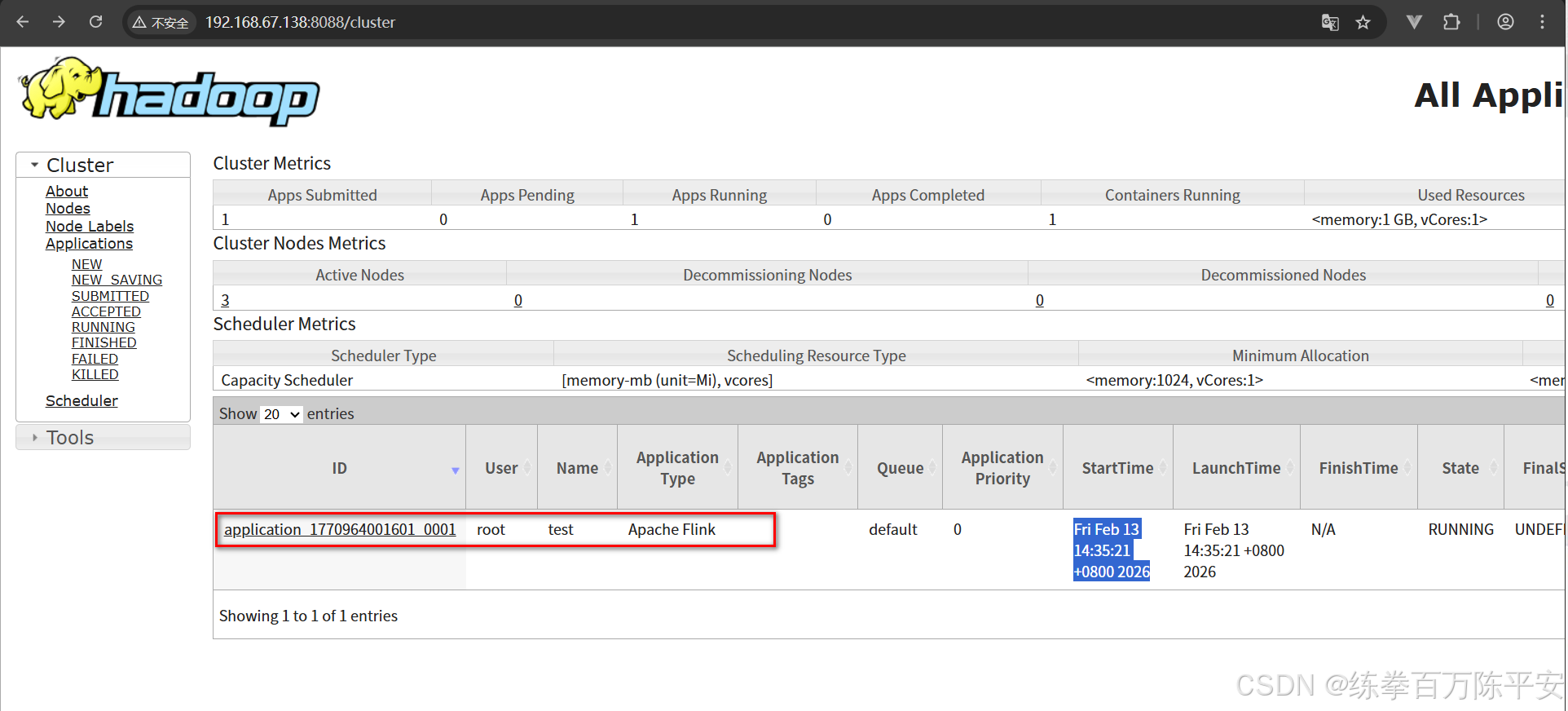
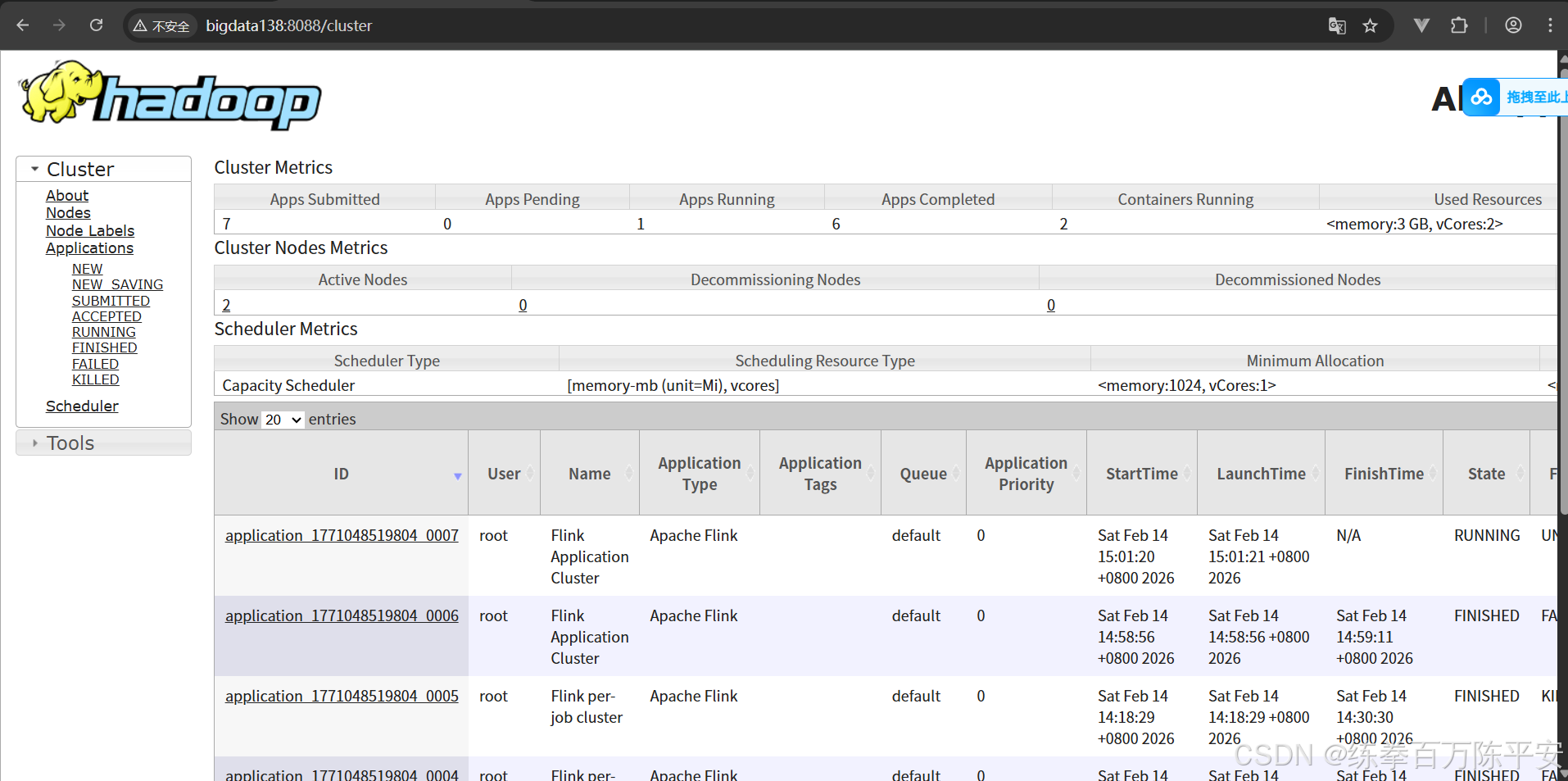
2026-02-13 14:35:21,055 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1770964001601_0001
2026-02-13 14:35:21,385 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1770964001601_0001
2026-02-13 14:35:21,385 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2026-02-13 14:35:21,388 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2026-02-13 14:35:26,197 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2026-02-13 14:35:26,198 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface bigdata139:8081 of application 'application_1770964001601_0001'.
JobManager Web Interface: http://bigdata139:8081
[root@bigdata137 bin]# yarn-session.sh -d -nm flinkdemo
bash: yarn-session.sh: command not found...
[root@bigdata137 bin]# ./yarn-session.sh -d -nm flinkdemo
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/flink-1.17.0/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop-3.3.5/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2026-02-13 23:06:38,973 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.memory.process.size, 1728m
2026-02-13 23:06:38,976 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.bind-host, 0.0.0.0
2026-02-13 23:06:38,976 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.execution.failover-strategy, region
2026-02-13 23:06:38,976 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.address, 192.168.67.137
2026-02-13 23:06:38,976 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.memory.process.size, 1024m
2026-02-13 23:06:38,976 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.port, 6123
2026-02-13 23:06:38,976 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.bind-address, 0.0.0.0
2026-02-13 23:06:38,976 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.port, 8081
2026-02-13 23:06:38,976 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.bind-host, 0.0.0.0
2026-02-13 23:06:38,976 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.host, 192.168.67.137
2026-02-13 23:06:38,976 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: parallelism.default, 1
2026-02-13 23:06:38,976 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.numberOfTaskSlots, 1
2026-02-13 23:06:38,976 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.address, 192.168.67.137
2026-02-13 23:06:38,993 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
2026-02-13 23:06:39,162 WARN org.apache.hadoop.util.NativeCodeLoader [] - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2026-02-13 23:06:39,178 INFO org.apache.flink.runtime.security.modules.HadoopModule [] - Hadoop user set to root (auth:SIMPLE)
2026-02-13 23:06:39,179 INFO org.apache.flink.runtime.security.modules.HadoopModule [] - Kerberos security is disabled.
2026-02-13 23:06:39,186 INFO org.apache.flink.runtime.security.modules.JaasModule [] - Jaas file will be created as /tmp/jaas-776283340901102364.conf.
2026-02-13 23:06:39,203 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/usr/local/src/flink-1.17.0/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2026-02-13 23:06:39,243 INFO org.apache.hadoop.yarn.client.DefaultNoHARMFailoverProxyProvider [] - Connecting to ResourceManager at bigdata138/192.168.67.138:8032
2026-02-13 23:06:39,418 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (102.400mb (107374184 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2026-02-13 23:06:39,427 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (172.800mb (181193935 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2026-02-13 23:06:39,536 INFO org.apache.hadoop.conf.Configuration [] - resource-types.xml not found
2026-02-13 23:06:39,536 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils [] - Unable to find 'resource-types.xml'.
2026-02-13 23:06:39,604 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured TaskManager memory is 1728 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 320 MB may not be used by Flink.
2026-02-13 23:06:39,604 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1728, slotsPerTaskManager=1}
2026-02-13 23:06:39,635 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: metrics-datadog
2026-02-13 23:06:39,637 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: external-resource-gpu
2026-02-13 23:06:39,637 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: metrics-graphite
2026-02-13 23:06:39,637 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: metrics-influx
2026-02-13 23:06:39,637 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: metrics-slf4j
2026-02-13 23:06:39,637 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: metrics-prometheus
2026-02-13 23:06:39,637 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: metrics-statsd
2026-02-13 23:06:39,637 INFO org.apache.flink.core.plugin.DefaultPluginManager [] - Plugin loader with ID not found, creating it: metrics-jmx
2026-02-13 23:06:43,624 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (102.400mb (107374184 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2026-02-13 23:06:43,633 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cannot use kerberos delegation token manager, no valid kerberos credentials provided.
2026-02-13 23:06:43,638 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1770995005496_0001
2026-02-13 23:06:43,971 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1770995005496_0001
2026-02-13 23:06:43,971 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2026-02-13 23:06:44,002 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2026-02-13 23:06:48,570 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2026-02-13 23:06:48,571 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface bigdata138:8081 of application 'application_1770995005496_0001'.
JobManager Web Interface: http://bigdata138:8081
2026-02-13 23:06:48,748 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - The Flink YARN session cluster has been started in detached mode. In order to stop Flink gracefully, use the following command:
$ echo "stop" | ./bin/yarn-session.sh -id application_1770995005496_0001
If this should not be possible, then you can also kill Flink via YARN's web interface or via:
$ yarn application -kill application_1770995005496_0001
Note that killing Flink might not clean up all job artifacts and temporary files.
[root@bigdata137 bin]# jpsall
=============== bigdata137 ===============
90326 DataNode
90731 NodeManager
90092 NameNode
92575 Jps
=============== bigdata138 ===============
37271 YarnSessionClusterEntrypoint
36266 ResourceManager
37354 Jps
36460 NodeManager
36030 DataNode
=============== bigdata139 ===============
20630 NodeManager
20537 SecondaryNameNode
20925 Jps
20415 DataNode
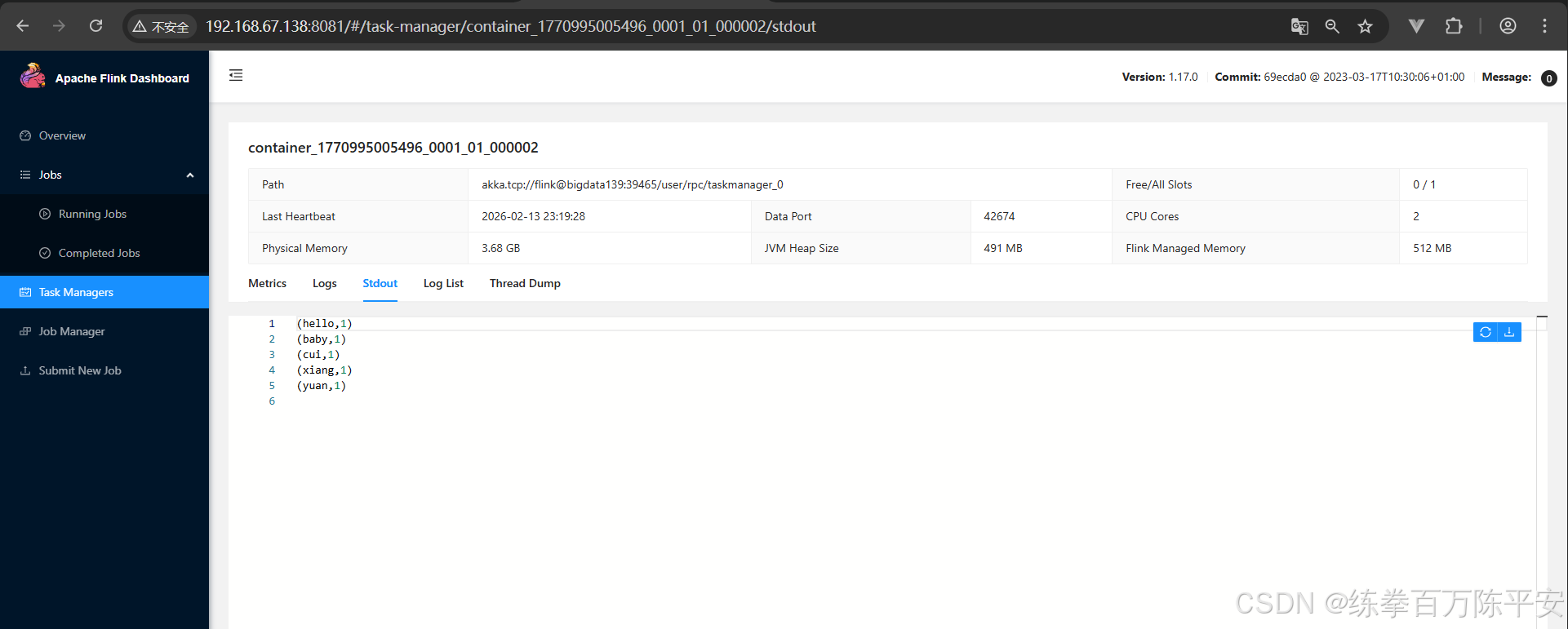
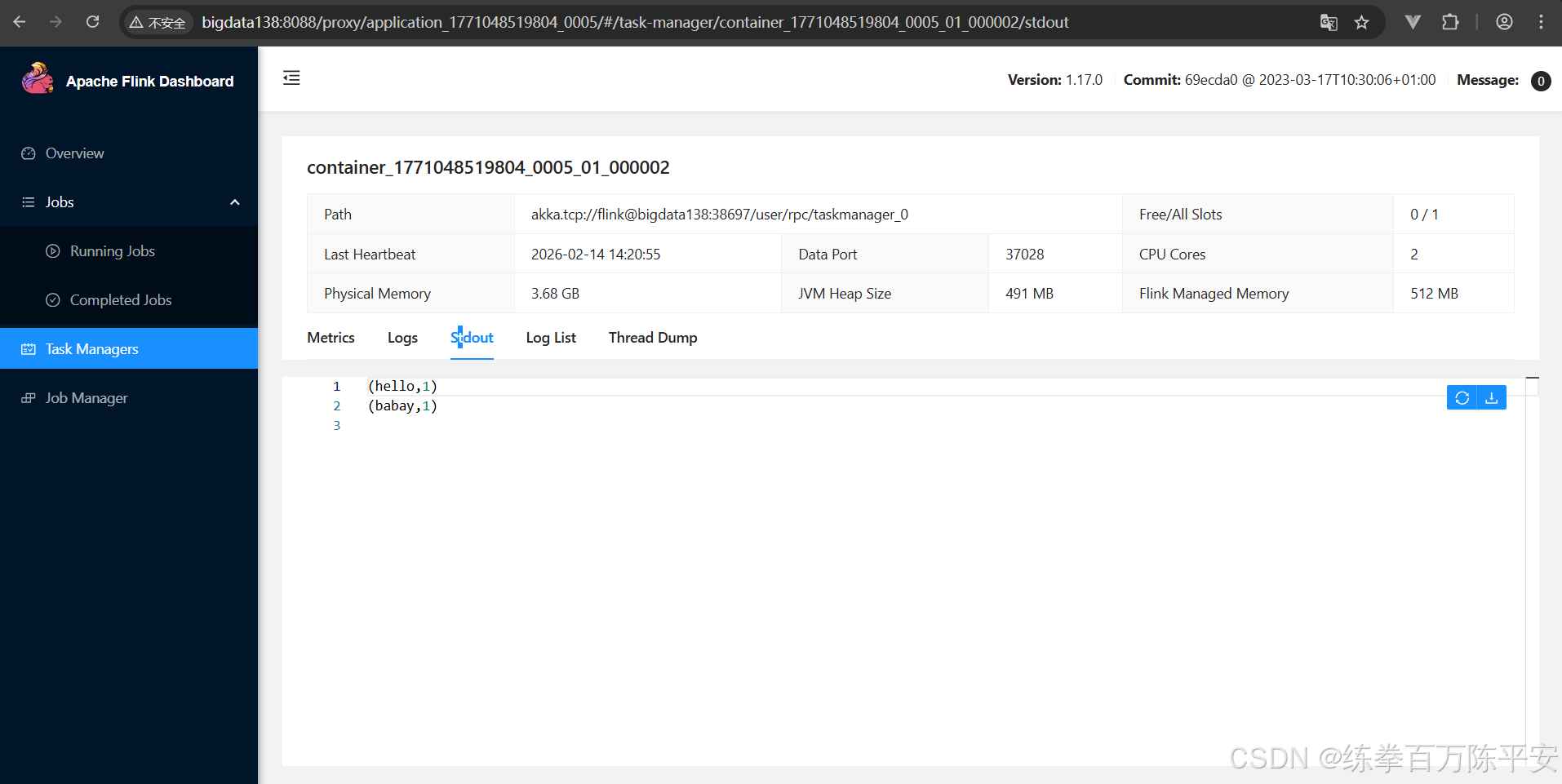
[root@bigdata137 bin]# ./flink run -m 192.168.67.138:8081 -c com.dashu.worldcount.wordCountUnboundedStream ../lib/flink170-1.0-SNAPSHOT.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/flink-1.17.0/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop-3.3.5/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2026-02-13 23:09:32,706 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
2026-02-13 23:09:32,706 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
Job has been submitted with JobID e591cdd8d259fd2202a888d6844185bd
^C[root@bigdata137 bin]#
[root@bigdata137 bin]# ./flink run -t yarn-per-job -c com.dashu.worldcount.wordCountUnboundedStream ../lib/flink170-1.0-SNAPSHOT.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/flink-1.17.0/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop-3.3.5/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2026-02-14 13:58:09,093 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/usr/local/src/flink-1.17.0/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2026-02-14 13:58:09,149 INFO org.apache.hadoop.yarn.client.DefaultNoHARMFailoverProxyProvider [] - Connecting to ResourceManager at bigdata138/192.168.67.138:8032
2026-02-14 13:58:09,442 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2026-02-14 13:58:09,461 WARN org.apache.flink.yarn.YarnClusterDescriptor [] - Job Clusters are deprecated since Flink 1.15. Please use an Application Cluster/Application Mode instead.
2026-02-14 13:58:09,663 INFO org.apache.hadoop.conf.Configuration [] - resource-types.xml not found
2026-02-14 13:58:09,664 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils [] - Unable to find 'resource-types.xml'.
2026-02-14 13:58:09,817 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured TaskManager memory is 1728 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 320 MB may not be used by Flink.
2026-02-14 13:58:09,818 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1728, slotsPerTaskManager=1}
2026-02-14 13:58:16,562 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cannot use kerberos delegation token manager, no valid kerberos credentials provided.
2026-02-14 13:58:16,567 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1771048519804_0001
2026-02-14 13:58:16,965 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1771048519804_0001
2026-02-14 13:58:16,965 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2026-02-14 13:58:17,009 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2026-02-14 13:58:25,393 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2026-02-14 13:58:25,394 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface bigdata139:8081 of application 'application_1771048519804_0001'.
Job has been submitted with JobID 17e4520479aadb5dcdbe31bbe080bf4d
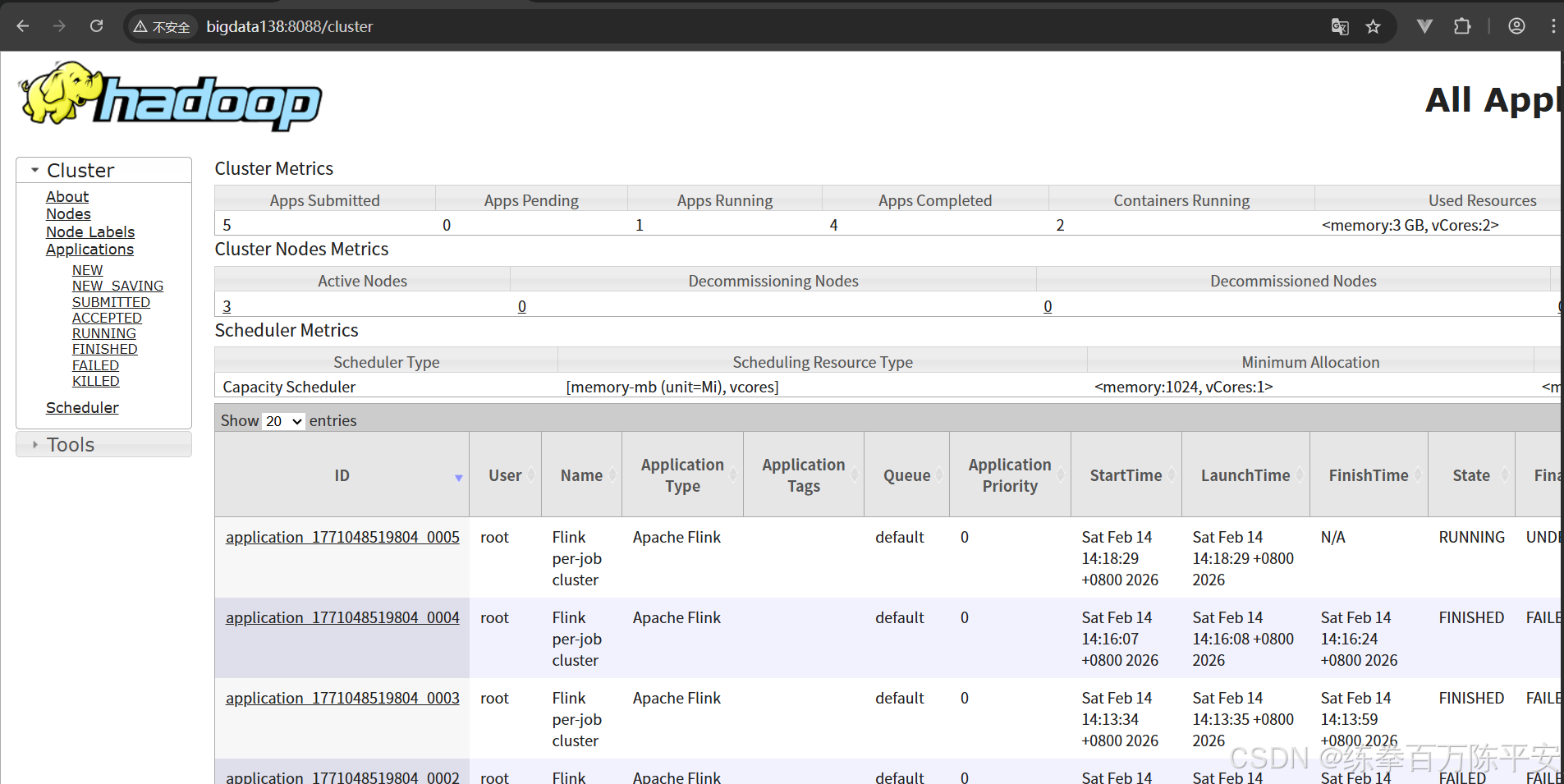
[root@bigdata137 bin]# flink list -t yarn-per-job -Dyarn.application.id=application_1771048519804_0005
bash: flink: command not found...
Similar command is: 'link'
[root@bigdata137 bin]# ./flink list -t yarn-per-job -Dyarn.application.id=application_1771048519804_0005
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/flink-1.17.0/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop-3.3.5/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2026-02-14 14:28:18,433 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/usr/local/src/flink-1.17.0/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2026-02-14 14:28:18,525 INFO org.apache.hadoop.yarn.client.DefaultNoHARMFailoverProxyProvider [] - Connecting to ResourceManager at bigdata138/192.168.67.138:8032
2026-02-14 14:28:18,670 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2026-02-14 14:28:18,762 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface bigdata138:8081 of application 'application_1771048519804_0005'.
Waiting for response...
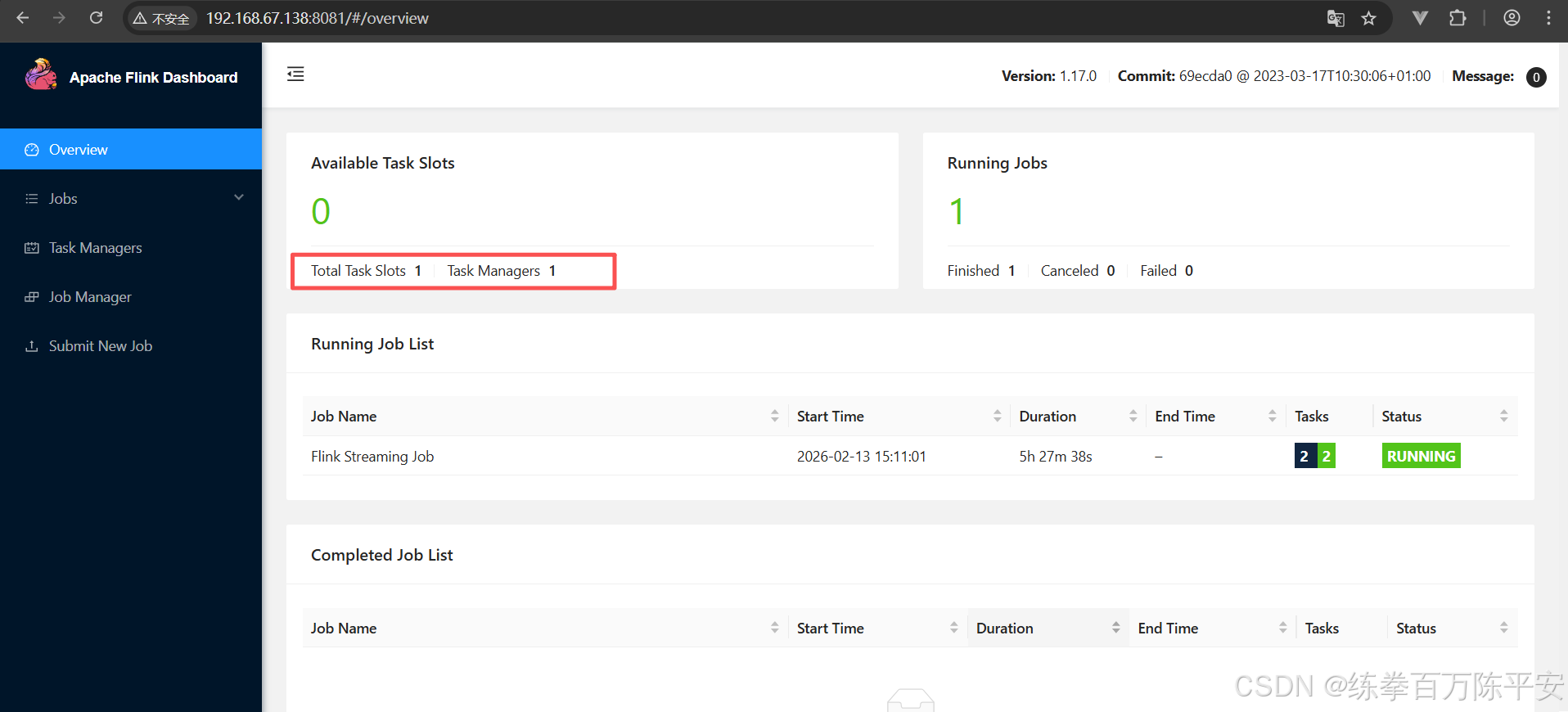
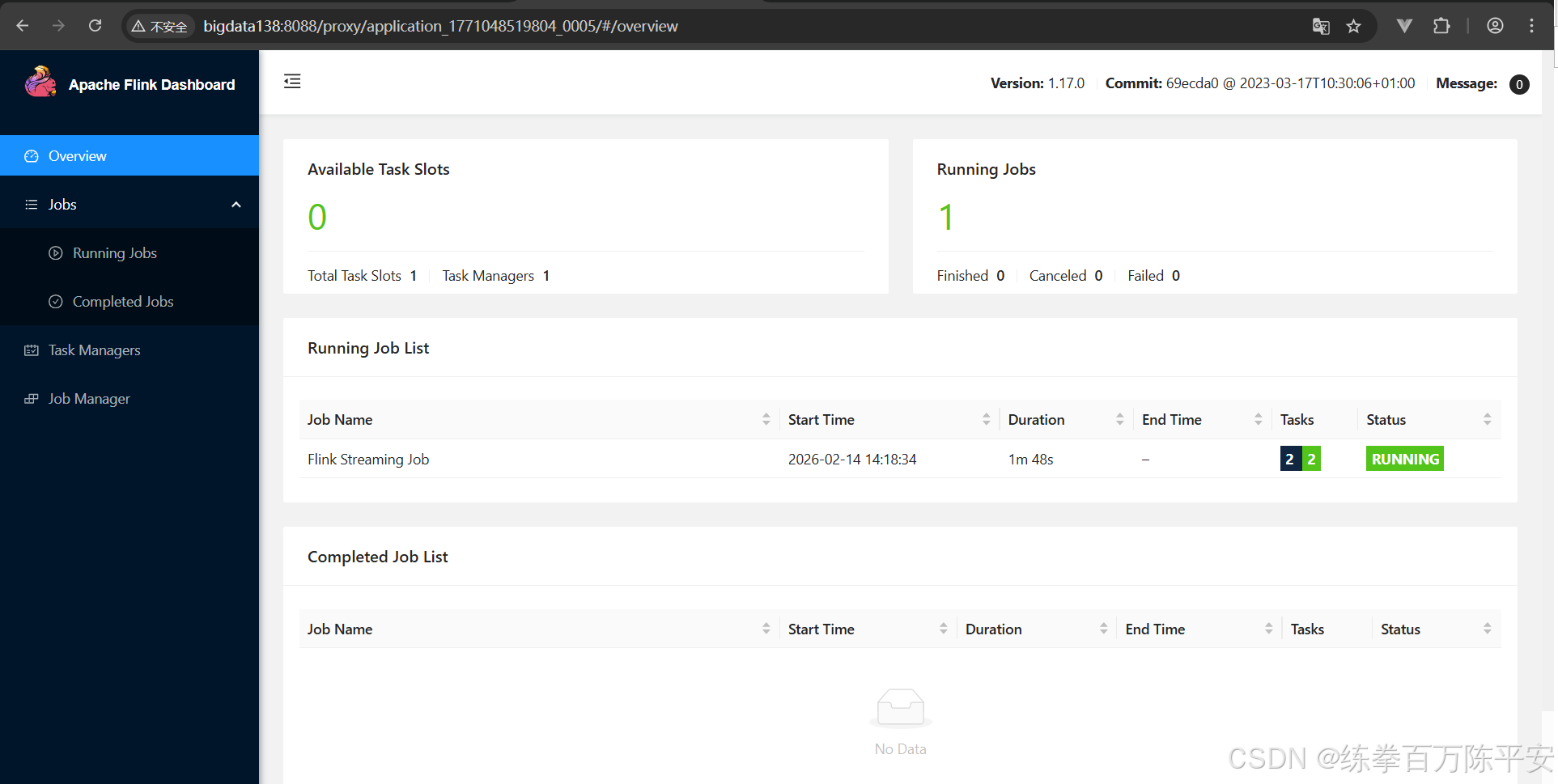
------------------ Running/Restarting Jobs -------------------
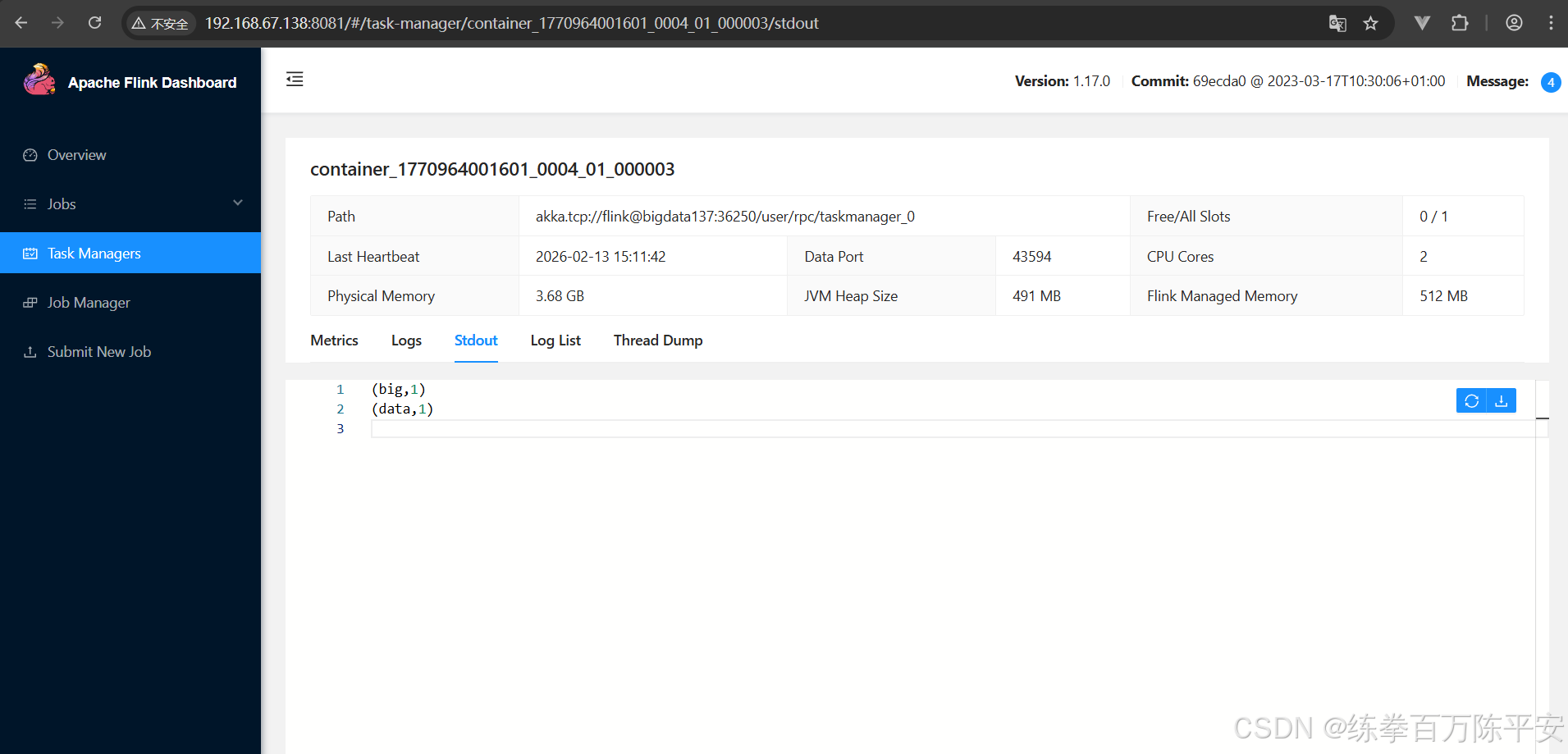
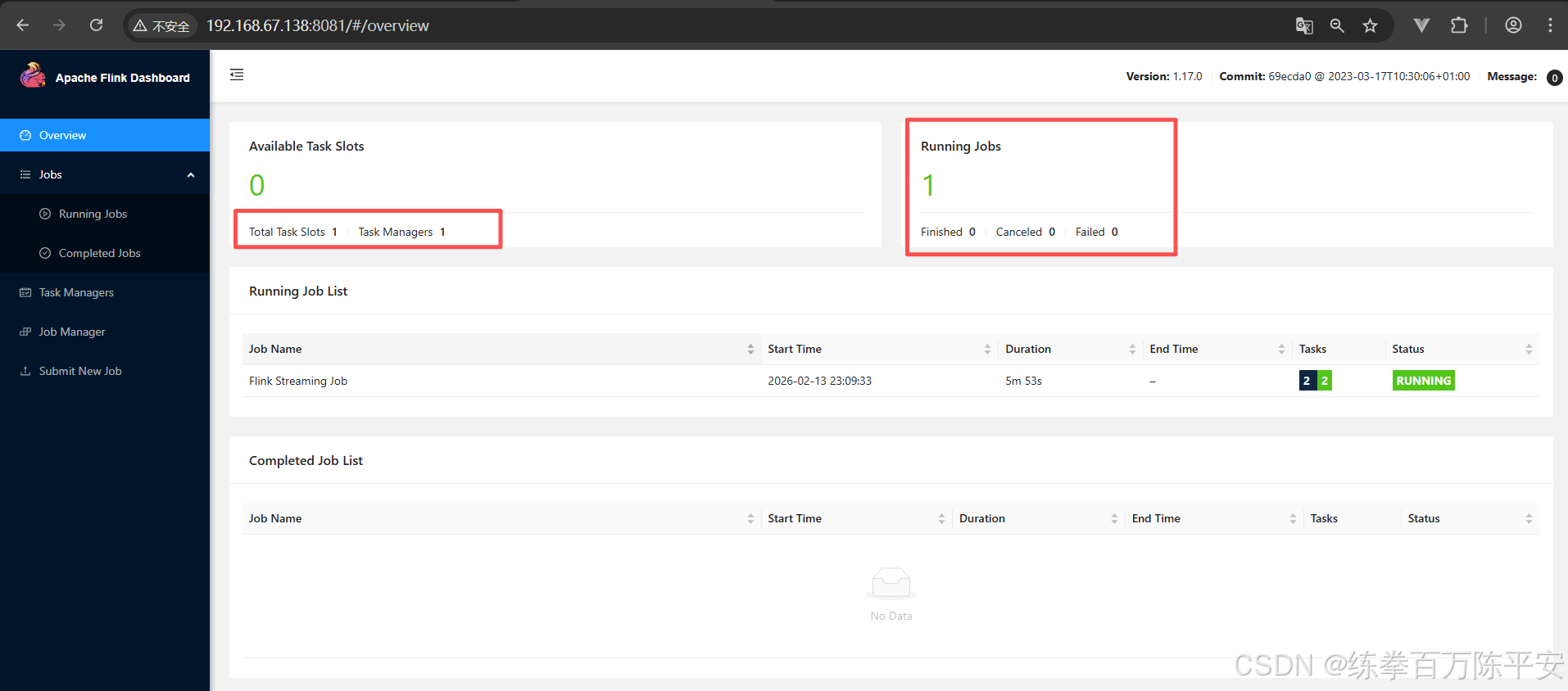
14.02.2026 14:18:34 : aa315a1351ef01f19a1e178b457adf4d : Flink Streaming Job (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
[root@bigdata137 bin]# ./flink cancel -t yarn-per-job -Dyarn.application.id=application_1771048519804_0005 aa315a1351ef01f19a1e178b457adf4d
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/flink-1.17.0/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop-3.3.5/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Cancelling job aa315a1351ef01f19a1e178b457adf4d.
2026-02-14 14:30:29,759 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/usr/local/src/flink-1.17.0/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2026-02-14 14:30:29,852 INFO org.apache.hadoop.yarn.client.DefaultNoHARMFailoverProxyProvider [] - Connecting to ResourceManager at bigdata138/192.168.67.138:8032
2026-02-14 14:30:30,004 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2026-02-14 14:30:30,094 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface bigdata138:8081 of application 'application_1771048519804_0005'.
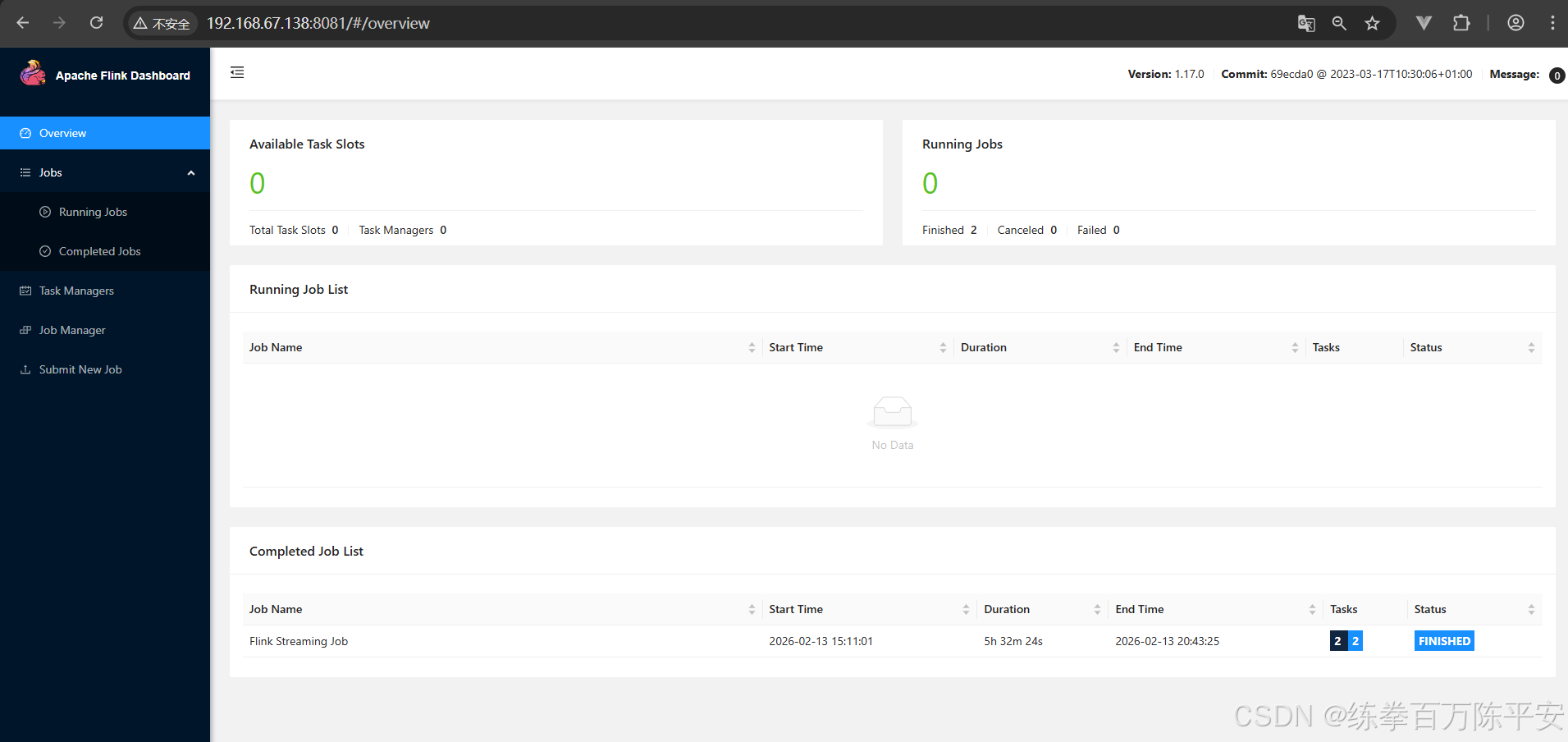
Cancelled job aa315a1351ef01f19a1e178b457adf4d.
[root@bigdata137 bin]#
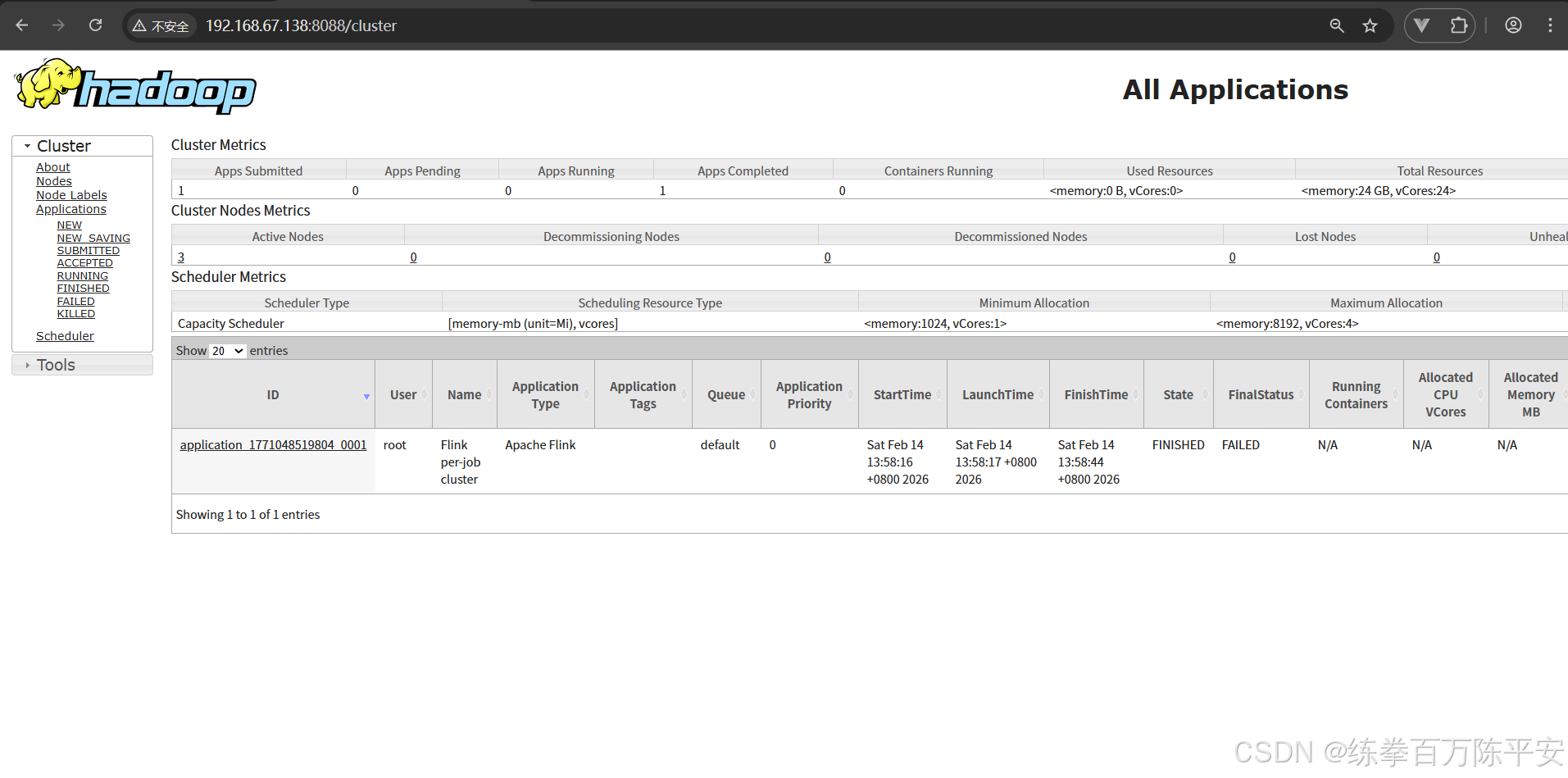
3:这个作业取消和页面取消没有任何问题。
4:应用模式部署
1:应用模式部署详情
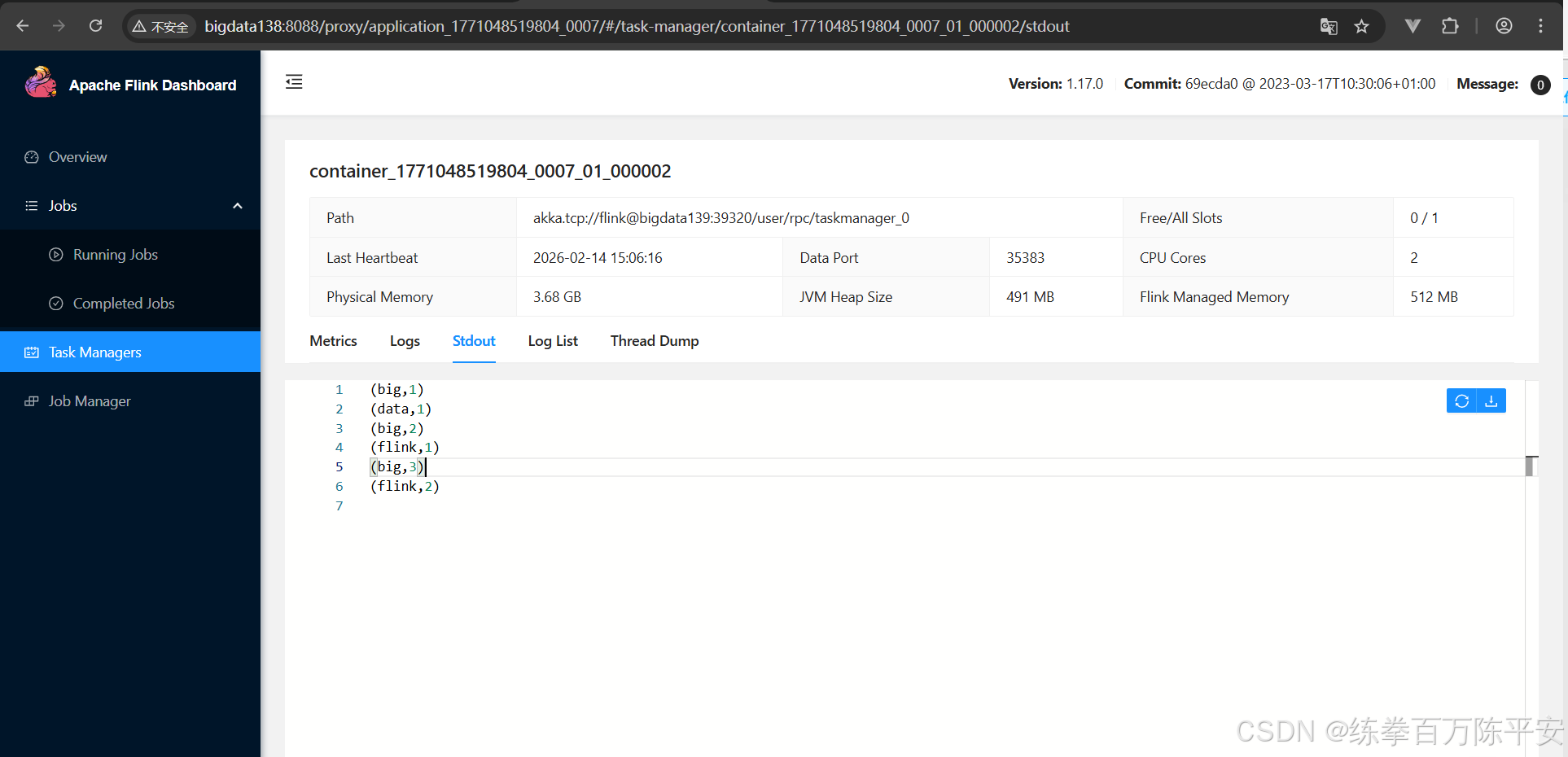
应用模式同样非常简单,与单作业模式类似,直接执行flink run-application命令即可
区别就是代码不再有client解析,而是由resourceManager进行解析。节省网络带宽
提交作业:
复制代码
[root@bigdata137 bin]# ./flink run-application -t yarn-application -c com.dashu.worldcount.wordCountUnboundedStream ../lib/flink170-1.0-SNAPSHOT.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/flink-1.17.0/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop-3.3.5/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2026-02-14 15:01:16,657 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/usr/local/src/flink-1.17.0/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2026-02-14 15:01:16,706 INFO org.apache.hadoop.yarn.client.DefaultNoHARMFailoverProxyProvider [] - Connecting to ResourceManager at bigdata138/192.168.67.138:8032
2026-02-14 15:01:16,897 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2026-02-14 15:01:17,037 INFO org.apache.hadoop.conf.Configuration [] - resource-types.xml not found
2026-02-14 15:01:17,037 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils [] - Unable to find 'resource-types.xml'.
2026-02-14 15:01:17,087 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured TaskManager memory is 1728 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 320 MB may not be used by Flink.
2026-02-14 15:01:17,088 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1728, slotsPerTaskManager=1}
2026-02-14 15:01:20,778 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cannot use kerberos delegation token manager, no valid kerberos credentials provided.
2026-02-14 15:01:20,782 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1771048519804_0007
2026-02-14 15:01:20,832 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1771048519804_0007
2026-02-14 15:01:20,832 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2026-02-14 15:01:20,834 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2026-02-14 15:01:26,158 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2026-02-14 15:01:26,159 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface bigdata139:8081 of application 'application_1771048519804_0007'.
[roo
2:停止应用模式
1:flink页面上cancle任务
2:查看并取消作业
在命令行中查看或取消作业。
./flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
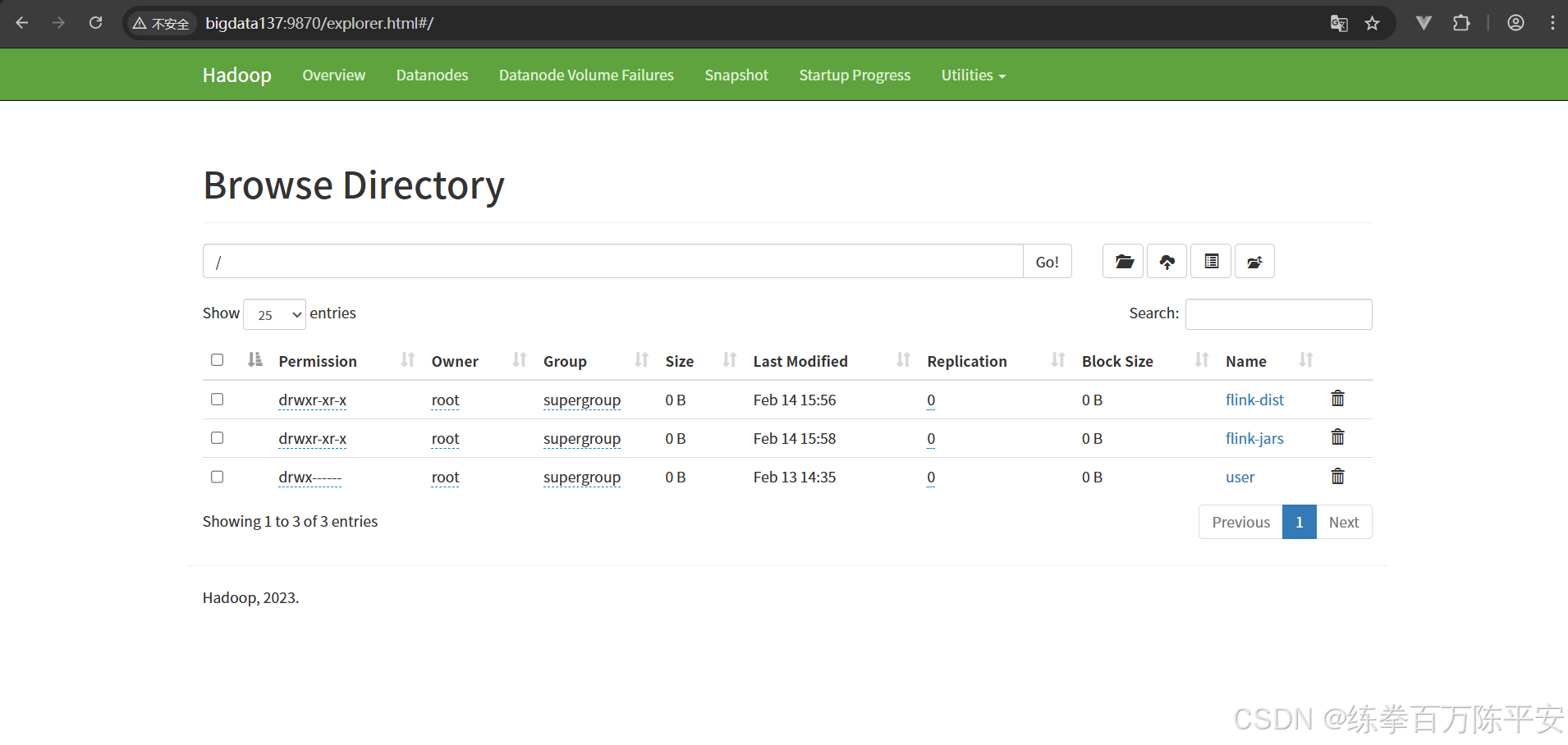
[root@bigdata137 bin]# ./flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://bigdata137:8020/flink-dist" -c com.dashu.worldcount.wordCountUnboundedStream hdfs://bigdata137:8020/flink-jars/flink170-1.0-SNAPSHOT.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/flink-1.17.0/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop-3.3.5/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2026-02-14 16:12:08,743 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/usr/local/src/flink-1.17.0/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2026-02-14 16:12:08,796 INFO org.apache.hadoop.yarn.client.DefaultNoHARMFailoverProxyProvider [] - Connecting to ResourceManager at bigdata138/192.168.67.138:8032
2026-02-14 16:12:08,981 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2026-02-14 16:12:09,121 INFO org.apache.hadoop.conf.Configuration [] - resource-types.xml not found
2026-02-14 16:12:09,122 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils [] - Unable to find 'resource-types.xml'.
2026-02-14 16:12:09,171 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured TaskManager memory is 1728 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 320 MB may not be used by Flink.
2026-02-14 16:12:09,171 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1728, slotsPerTaskManager=1}
2026-02-14 16:12:09,974 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cannot use kerberos delegation token manager, no valid kerberos credentials provided.
2026-02-14 16:12:09,980 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1771048519804_0010
2026-02-14 16:12:10,028 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1771048519804_0010
2026-02-14 16:12:10,028 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2026-02-14 16:12:10,031 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2026-02-14 16:12:14,358 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2026-02-14 16:12:14,359 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface bigdata138:8081 of application 'application_1771048519804_0010'.
[root@bigdata137 bin]#