Elasticsearch 概念与基础实操 (索引、映射与文档操作)
在海量数据的搜索与分析场景中,Elasticsearch (简称 ES) 凭借其分布式、高扩展和近实时的搜索特性,成为了众多开发者的首选。因此了解es的使用的原理和操作必不可少
Rabbit高级篇的总结内容:RabbitMQ高级篇总结Rabbit入门篇的总结内容:Rabbit入门篇总结
📚 目录(点击跳转对应章节)
[1. 核心概念:正向索引与倒排索引](#1. 核心概念:正向索引与倒排索引)
[2. 中文分词利器:IK 分词器](#2. 中文分词利器:IK 分词器)
[3. ES 与 MySQL 概念对比](#3. ES 与 MySQL 概念对比)
[4. Mapping 映射属性](#4. Mapping 映射属性)
[5. 索引库操作 (Index CRUD)](#5. 索引库操作 (Index CRUD))
[6. 文档操作 (Document CRUD)](#6. 文档操作 (Document CRUD))
1. 核心概念:正向索引与倒排索引
理解 ES 的高效查询,首先要理解它的索引机制。
- 正向索引 :类似传统关系型数据库的主键查询,通过 ID 找内容。如果是模糊查询(如
LIKE),需要全表扫描,效率极低。

- 倒排索引 :ES 搜索的核心。它将文档内容进行分词 ,提取出词条(Term),并记录该词条所在的文档 ID 列表。搜索时,先对关键词分词,再去词条列表中快速定位文档 ID,最后根据 ID 获取文档。这种方式极大地提高了全文检索的速度。
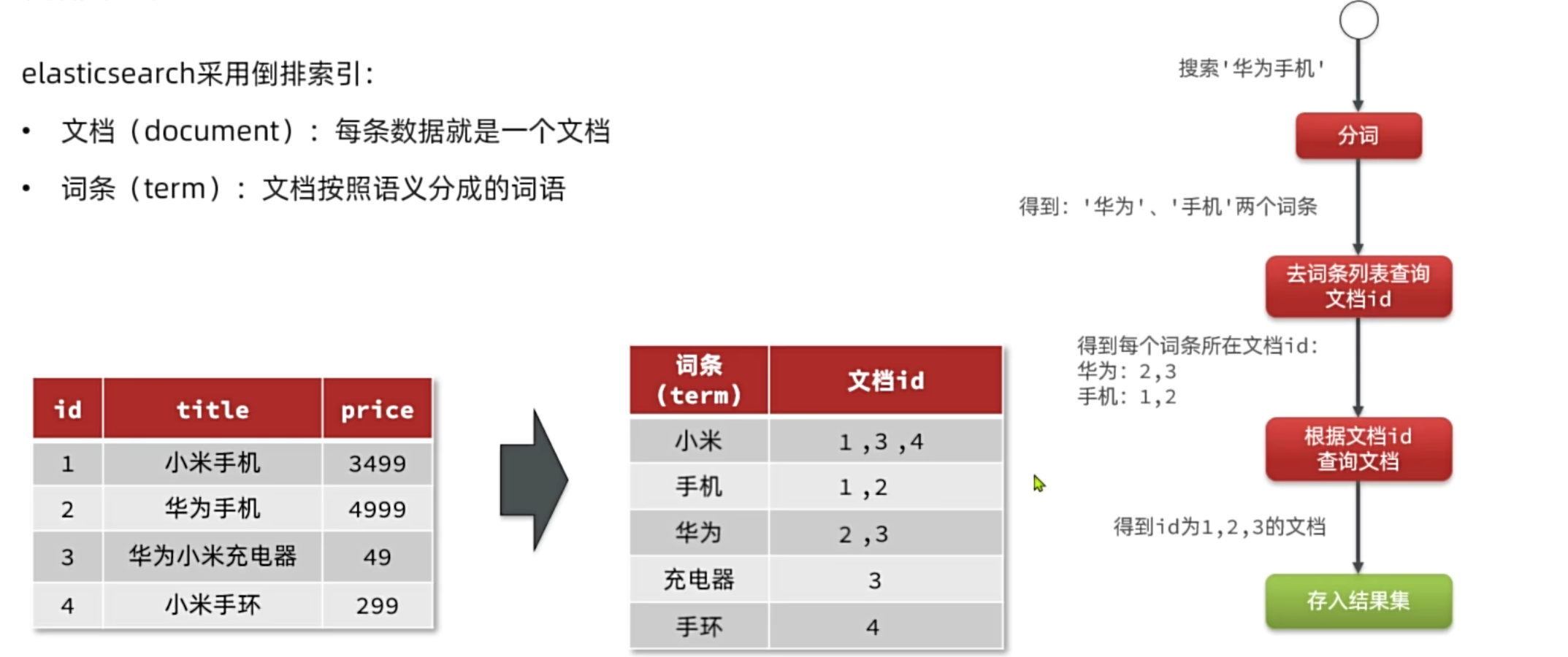
小结

2. 中文分词利器:IK 分词器
倒排索引依赖于分词,而 ES 默认的标准分词器对中文支持很不友好(会将中文逐字切分)。在实际项目中,我们通常会接入 IK 分词器。
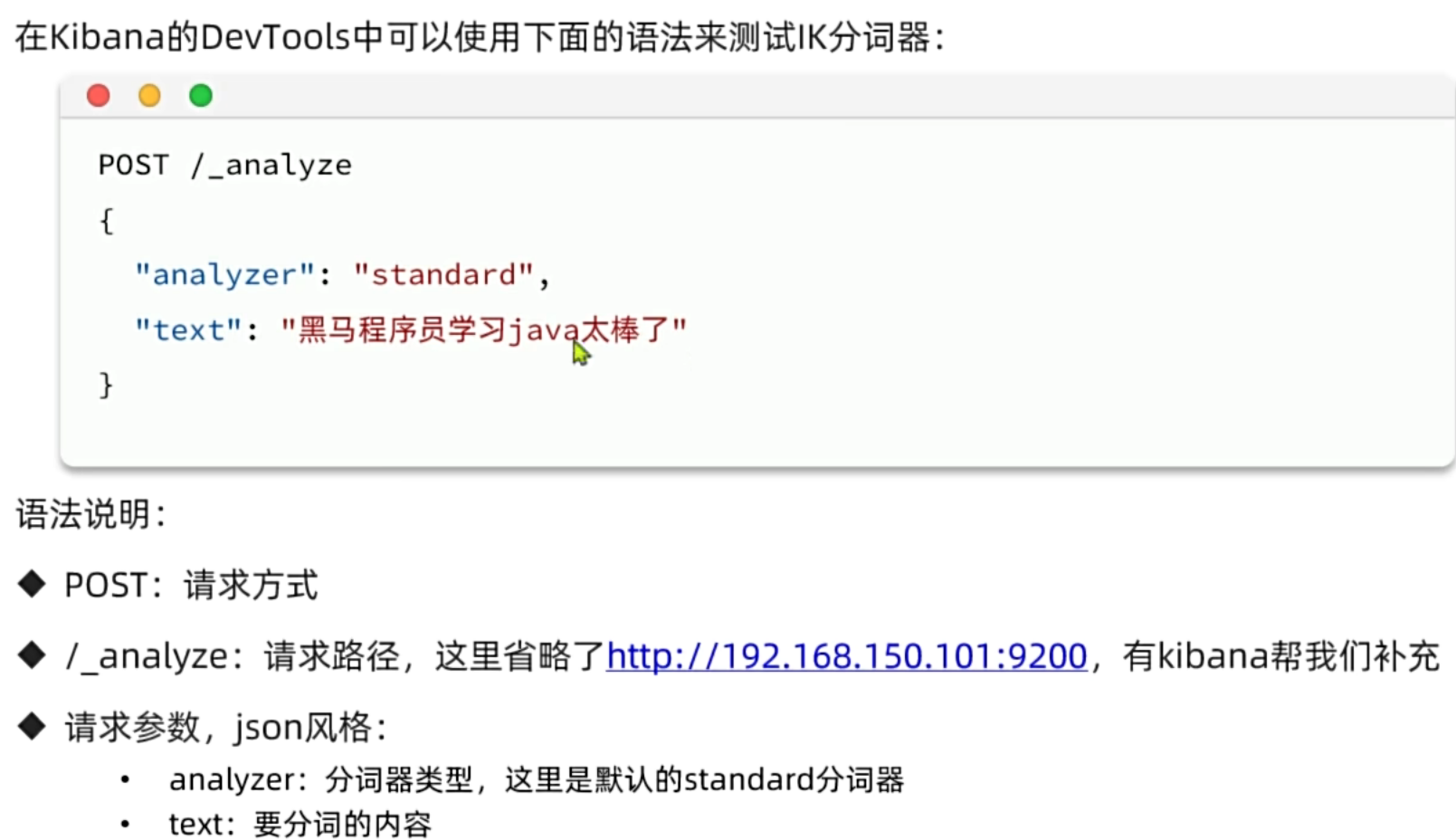
IK 分词器提供两种常用的分词模式:
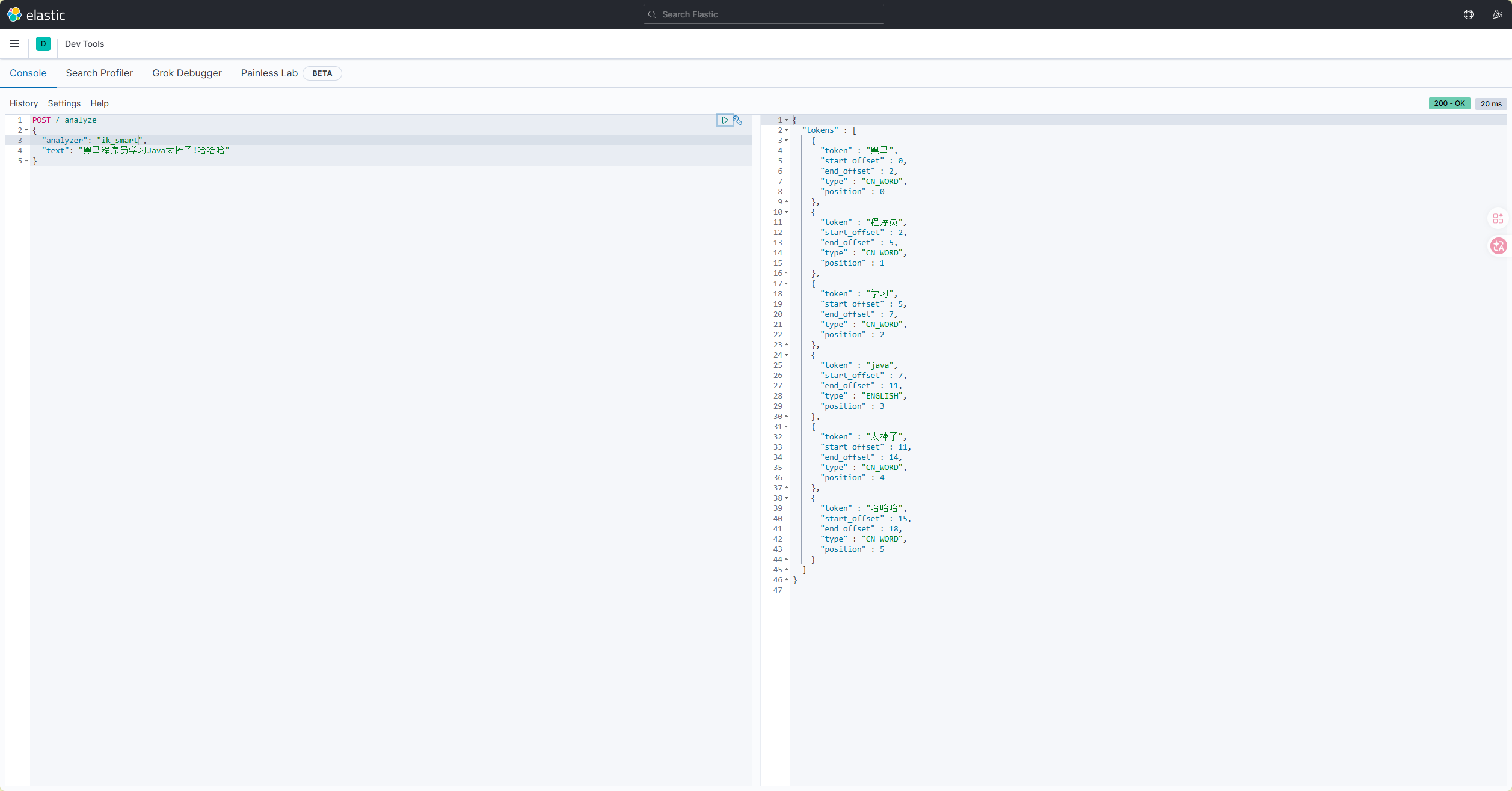
-
ik_smart :最少切分,追求粗粒度的精准。
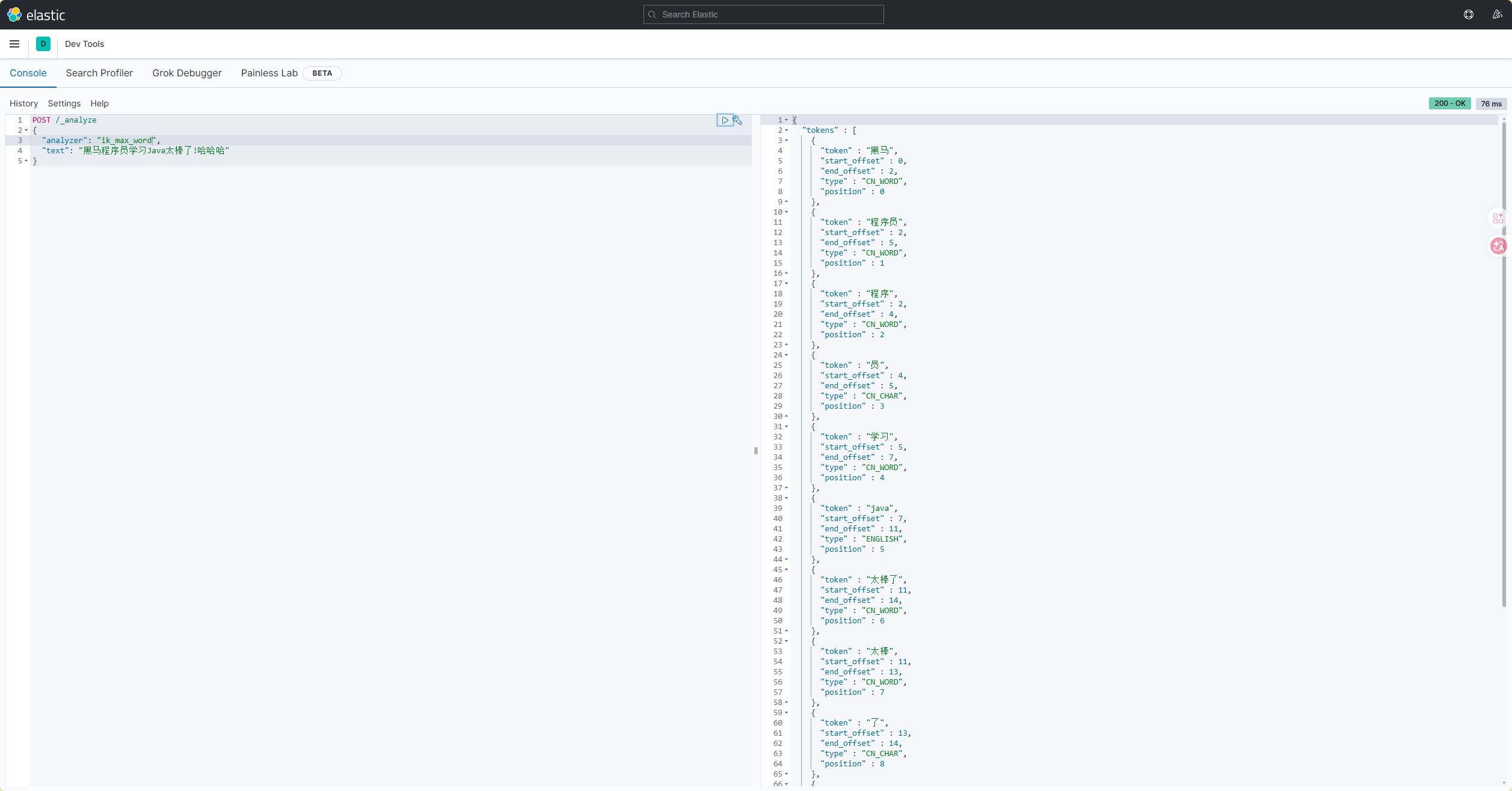
-
ik_max_word :最细切分,穷尽词库的可能,适合搜索场景。
拓展分词词库中的词条:

3. ES 与 MySQL 概念对比
为了方便具备关系型数据库背景的开发者理解,我们可以将 ES 的概念与 MySQL 进行类比:
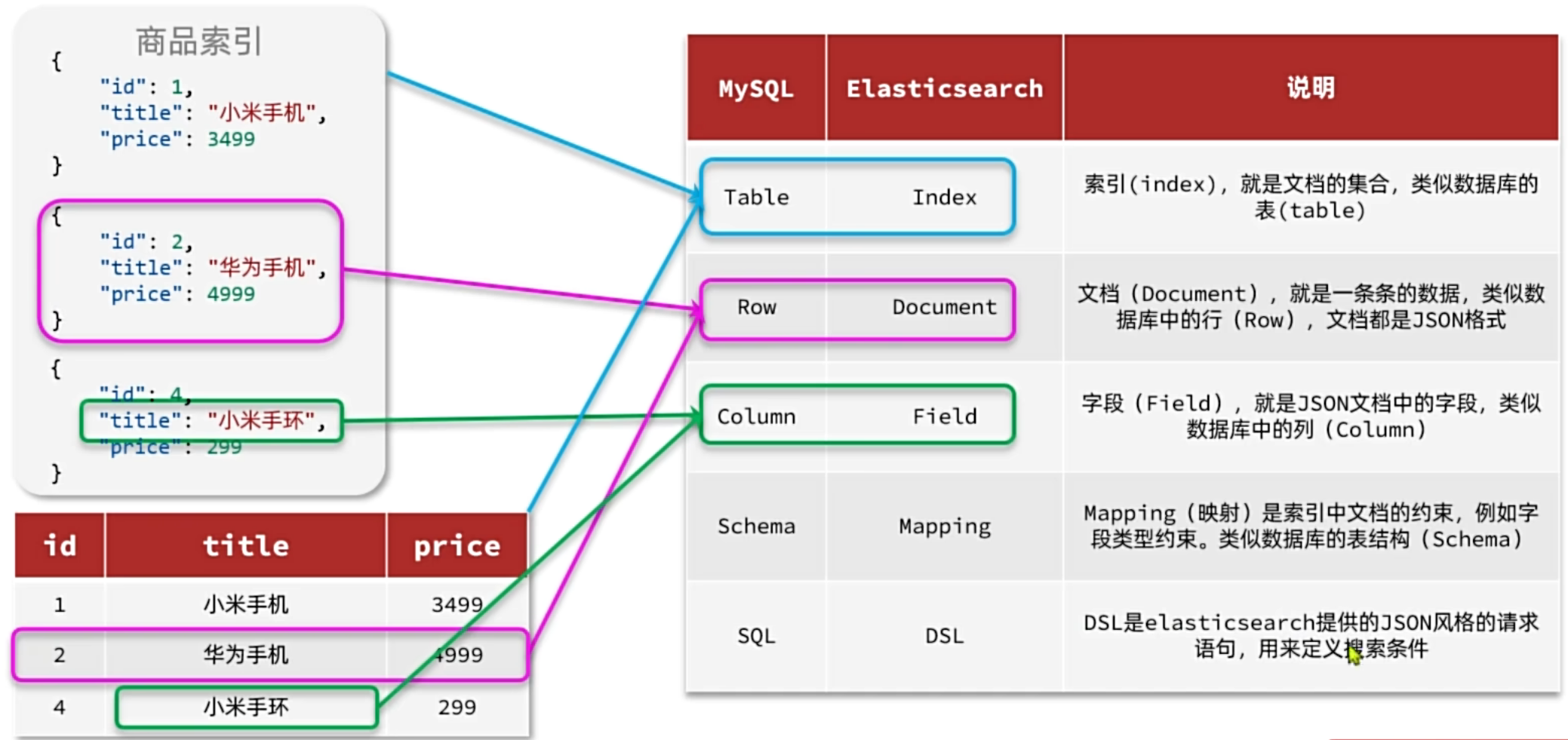
- MySQL:数据库 (Database) -> 表 (Table) -> 行 (Row) -> 列 (Column)
- Elasticsearch :索引库 (Index) -> 类型 (Type,ES 7.x 之后已废弃,默认
_doc) -> 文档 (Document) -> 字段 (Field)
此外,ES 的 Mapping 映射就相当于 MySQL 中的表结构定义(Schema)。
4. Mapping 映射属性
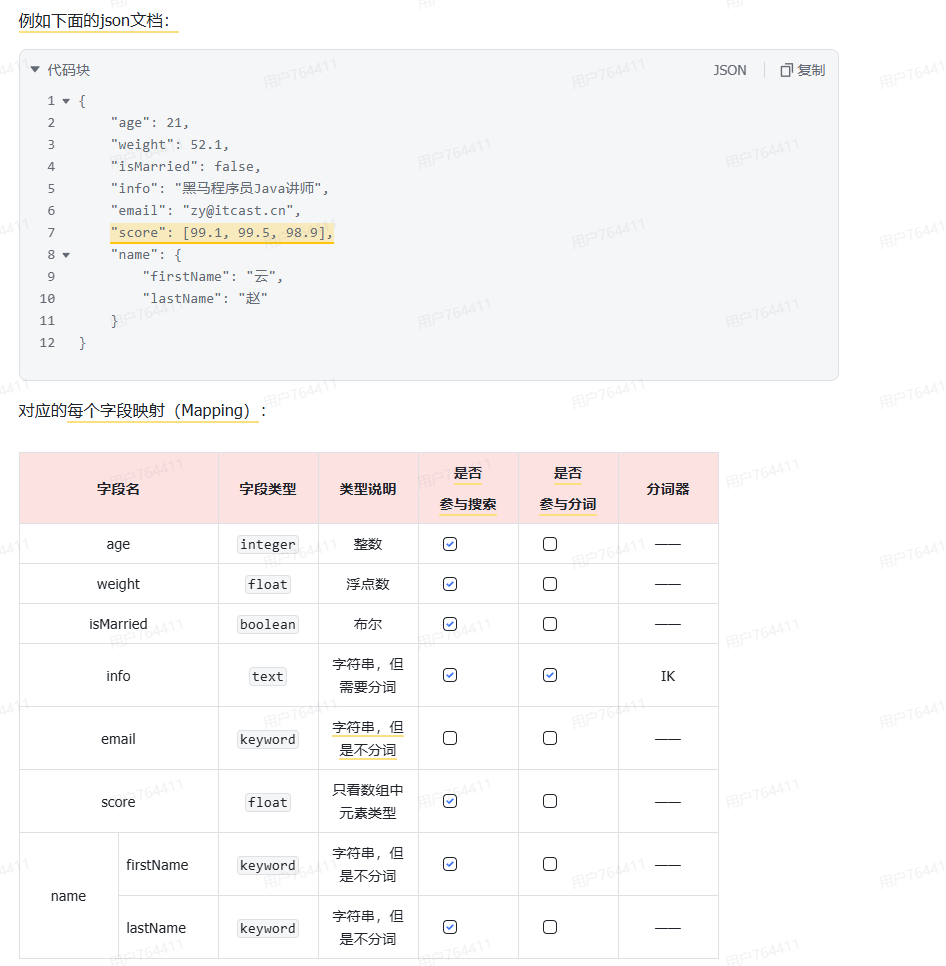
Mapping 是对索引库中整篇文档及其包含字段的结构定义。常见的数据类型包括:

- 字符串 :
text(可分词的文本)、keyword(精确值,如品牌、邮箱,不分词) - 数值 :
long,integer,short,byte,double,float - 布尔 :
boolean - 日期 :
date - 对象 :
object(JSON 嵌套)
核心注意 :只有
text类型的字段需要进行分词,并可以配置analyzer属性。
具体实例:
5. 索引库操作 (Index CRUD)
RESTful API 风格贯穿了整个 ES 操作。对于索引库的操作,核心原则是:一旦创建,无法修改已有的 Mapping 字段(因为这会导致原有倒排索引失效),但可以新增字段。
5.1 创建索引库和映射
使用 PUT 请求,明确表达"创建或覆盖"的语义。
json
PUT /heima
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
"name":{
"properties": {
"firstName": {
"type": "keyword"
}
}
}
}
}
}5.2 查询索引库
使用 GET 请求。
http
GET /heima5.3 修改索引库 (仅限新增字段)
使用 PUT 向已有的 mapping 中追加新字段。
json
PUT /heima/_mapping
{
"properties": {
"age":{
"type": "integer"
}
}
}倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。因此修改索引库能做的就是向索引库中添加新字段,或者更新索引库的基础属性。
5.4 删除索引库
使用 DELETE 请求。
http
DELETE /heima6. 文档操作 (Document CRUD)
对具体数据的增删改查同样遵循 RESTful 原则。
6.1 新增文档
使用 POST 请求,并指定索引库、_doc 以及文档 ID。
json
POST /heima/_doc/1
{
"info": "黑马程序员Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}6.2 查询文档
使用 GET 请求加文档 ID。
json
GET /heima/_doc/16.3 删除文档
使用 DELETE 请求加文档 ID。
json
DELETE /heima/_doc/16.4 修改文档
ES 的修改分为全量修改和局部修改:
全量修改 (PUT):底层逻辑是先根据 ID 删除旧文档,再新增同 ID 文档。如果原 ID 不存在,则直接变为新增操作。
json
PUT /heima/_doc/1
{
"info": "黑马程序员高级Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}局部修改 (POST + _update):仅修改指定的字段值。
json
POST /heima/_update/1
{
"doc": {
"email": "ZhaoYun@itcast.cn"
}
}6.5 批处理 (Bulk)
在处理大量数据时,使用 _bulk 接口可以极大提高网络吞吐量。批处理的内容格式比较特殊,每一组操作由两行 JSON 组成(操作类型与元数据 + 操作的实际数据)。
批量新增示例:
json
POST /_bulk
{"index": {"_index":"heima", "_id": "3"}}
{"info": "黑马程序员C++讲师", "email": "ww@itcast.cn", "name":{"firstName": "五", "lastName":"王"}}
{"index": {"_index":"heima", "_id": "4"}}
{"info": "黑马程序员前端讲师", "email": "zhangsan@itcast.cn", "name":{"firstName": "三", "lastName":"张"}}批量删除示例:
json
POST /_bulk
{"delete":{"_index":"heima", "_id": "3"}}
{"delete":{"_index":"heima", "_id": "4"}}