大模型 全栈工程师 ( LLM Full Stack Engineer) 是 AI 时代诞生的一种"超级个体"或新型技术角色。
简单来说,他们是**"懂 AI 的全栈开发工程师"** 。
如果说传统的全栈工程师是**"前端 + 后端 + 运维"** ,那么大模型全栈工程师的技能树就是:"前端 + 后端 + AI 模型应用" 。
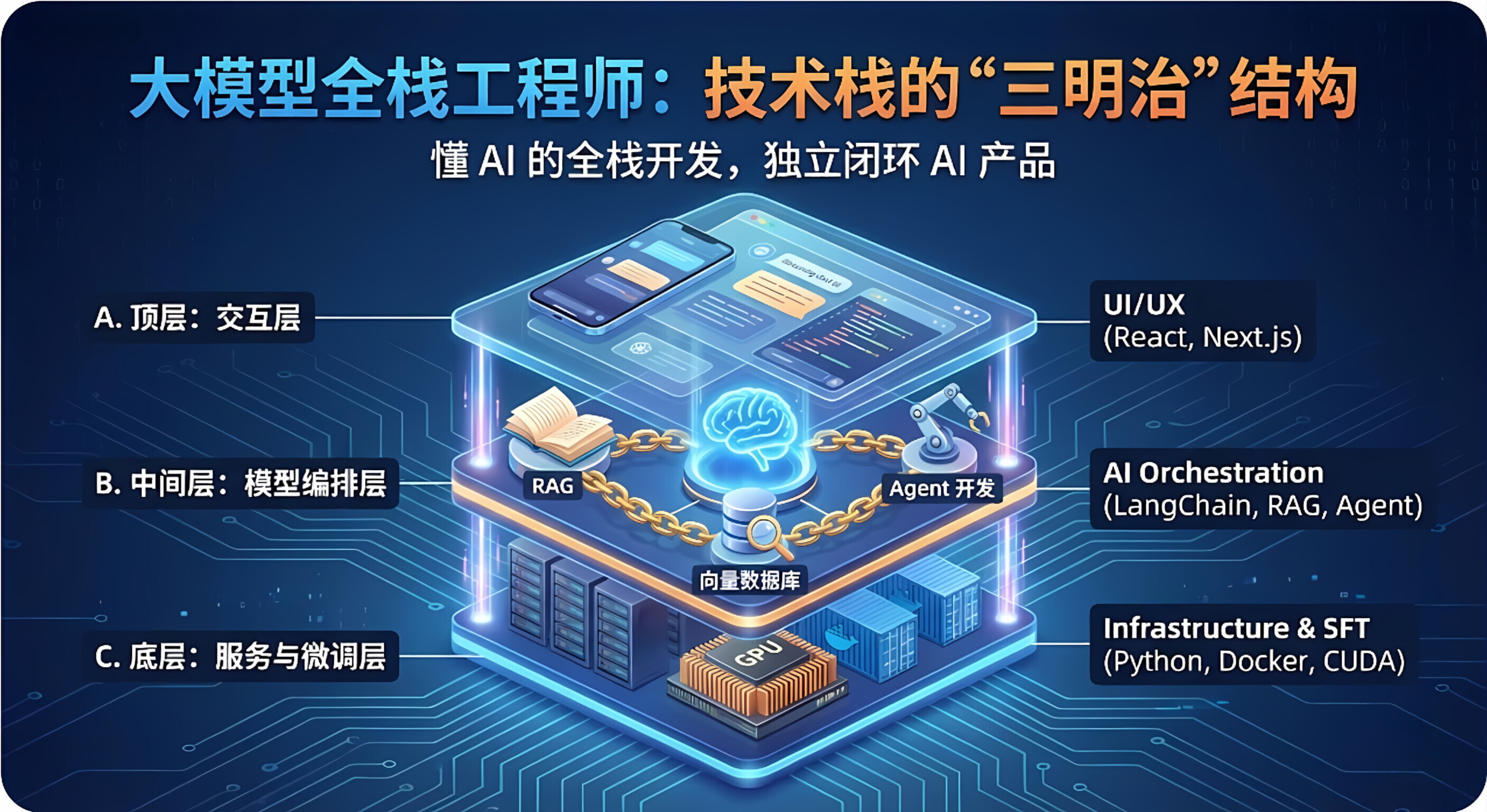
1.🔍 核心定义:技术栈的"三明治"结构
这个角色的核心价值在于**"独立完成一个 AI 产品的闭环"** 。他们不需要从头训练一个 GPT-4(那是算法科学家的事),但他们能把 GPT-4 变成一个好用的产品。
他们的技能栈通常分为三层:
A. 顶层:交互层 (UI/UX)
-
技能:React, Vue, Next.js, Vercel。
-
任务 :不再只是画简单的按钮,而是设计流式对话界面 (Streaming UI ),处理 AI 生成内容的实时渲染(比如让 AI 一边写代码一边在旁边预览)。
B. 中间层:模型编排层 (AI Orchestration) ------ 这是最核心的区别
-
技能:
-
Prompt Engineering:写出结构化的提示词。
-
RAG (检索增强生成) :熟练使用 LangChain 或 LlamaIndex,把公司私有数据喂给 AI。
-
向量数据库 :会用 Pinecone , Milvus , Chroma 来存储和搜索知识。
-
Agent 开发:会设计 AI 智能体,让 AI 学会调用工具(查天气、发邮件)。
-
C. 底层:服务与微调层 (Infrastructure & SFT)
-
技能:Python (FastAPI), Docker, CUDA 环境配置。
-
任务:
-
微调 (Fine-tuning):当开源模型(如 Llama 3)不够聪明时,能用私有数据简单微调一下。
-
模型部署:把模型部署在云端或本地显卡上,不仅要能跑,还要跑得快(推理加速)。
-
2.⚔️ 和其他角色的区别
为了让你更清楚这个定位,我们来做个对比:
|----------|------|--------------------------------------------|
| 角色 | 关注点 | 典型口头禅 |
| 算法工程师 | 模型本身 | "这个 Transformer 架构改一下,Loss 还能降 0.01。" |
| 传统全栈工程师 | 业务逻辑 | "数据库在这个高并发场景下锁死了,得优化 SQL。" |
| 大模型全栈工程师 | 落地应用 | "怎么把 RAG 的检索准确率从 80% 提到 95%?怎么降低 API 的延迟?" |
总结:算法工程师负责"造大脑", 大模型 全栈工程师负责"给大脑装上手脚和身体",让它变成一个能干活的机器人。
3.💼 为什么这个岗位现在这么火?
-
门槛降低:以前搞 AI 需要数学博士学位,现在有了 Hugging Face 和 OpenAI API,会写 Python 的工程师就能玩转 AI。
-
企业刚需 :大部分公司不需要从头训练大模型(太贵),但所有公司都需要**"把大模型接入自己的业务"** (比如做一个智能客服、智能文档助手)。这正是大模型全栈工程师最擅长的。
-
效率革命:一个大模型全栈工程师,配合 AI 编程助手(Cursor/Copilot),现在的产出能力相当于以前的一个 3-5 人小团队。
总结
大模型 全栈工程师是目前市场上薪资最高、最抢手的技术岗位之一。
他们是 AI 时代的**"应用架构师"** ,如果你想在 2025-2026 年保持技术竞争力,"左手 Next.js,右手 LangChain" 是你必须掌握的各种技能。