一.实验目的
- 熟悉Logistic回归优化算法。
- 熟悉分类问题的度量方法。
- 熟悉softmax回归模型。
二.实验内容
1.上机实验题一
用书中图5.3中的梯度下降算法实现Logistic回归算法来求解山鸢尾识别问题。
2.上机实验题二
乳腺癌预测问题
乳腺癌预测问题的任务是:根据患者的病理特征,预测患者的乳腺肿瘤是良性还是恶性。数据集。来自Sklearn工具库中的乳腺癌数据集。该数据集包含569例乳腺肿瘤病例。每一条病例含有患者的30个病例特征以及该患者的肿瘤是良性还是恶性的结果。
图5.25中的程序导入乳腺癌数据集,并生成特征矩阵与标签矩阵。请基于图5.25,用Logistic回归算法完成乳腺癌预测问题。完成预测后,还需要计算模型的准确率、精确率与召回率。最后,绘制出ROC曲线,并计算AUC测度。

3.上机实验题三
调用书中图5.21中的softmax回归的梯度下降算法求解鸢尾花问题。并算出准确率。
4.红酒产地预测问题
红酒产地预测问题的任务是:根据红酒的各项指标,鉴定红酒的产地。数据来自Sklearn工具库中的红酒数据集。该数据集中包含来自3个不同产地的178瓶红酒。每一条数据表示一瓶红酒,其中记录了13种指标作为特征,例如酒的颜色、蒸留度、酸碱度、花青素浓度等,同时还记录了红酒的产地作为标签。
图5.26中的程序导入红酒数据集,并生成特征矩阵与标签矩阵。请基于图5.26,用Softmax回归算法完成红酒产地预测问题。

三.实验要求
1.结合上课内容,写出程序,并调试程序,要给出测试数据和实验结果。
2.整理上机步骤,总结经验和体会。
3.完成实验报告和上交源程序
四 .实验 内容
1、 上机实验题一
定义一个使用梯度下降算法的逻辑回归模型,以及用于评估分类性能的一系列指标。在 逻辑回归模型通过fit方法进行训练,该方法实现了梯度下降算法,用于最小化交叉熵损失函数。predict_proba方法用于预测测试数据的概率,而predict方法则根据这些概率给出最终的分类结果。为了评估模型的性能,采用了一组标准的分类指标,包括交叉熵损失、精确率、召回率和准确率
首先对鸢尾花数据集进行了处理,将其转换为二分类问题,然后分割为训练集和测试集。接着,使用逻辑回归模型对训练集进行训练,并在测试集上进行预测。最后,使用评估函数计算了模型的交叉熵损失、精确率、召回率和准确率。
运行结果显示,模型在测试集上的表现非常出色,交叉熵损失非常低,精确率、召回率和准确率都达到了1.0,这意味着模型在测试集上的所有预测都是正确的,没有出现任何误分类的情况。这表明模型对于这个特定的数据集和问题具有很高的分类性能。然而,这种完美的表现可能也暗示了过拟合的风险,特别是在数据集较小或者模型过于复杂的情况下。
(1)定义sigmoid、交叉熵损失、逻辑回归模型
python
import numpy as np
def sigmoid(scores):
return 1 / (1 + np.exp(-scores))
def get_cross_entropy(y_true, y_pred):
return np.average(-y_true * np.log(y_pred) - (1 - y_true) * np.log(1 - y_pred))
class LogisticRegression:
def fit(self, X, y, eta=0.1, N = 1000):
m, n = X.shape
w = np.zeros((n,1))
for t in range(N):
h = sigmoid(X.dot(w))
g = 1.0 / m * X.T.dot(h - y)
w = w - eta * g
self.w = w
def predict_proba(self, X):
return sigmoid(X.dot(self.w))
def predict(self, X):
proba = self.predict_proba(X)
return (proba >= 0.5).astype(np.int32)(2)定义交叉熵、准确率、精确率、召回率
python
import numpy as np
def cross_entropy(y_true, y_pred):
return np.average(-y_true * np.log(y_pred) - (1 - y_true) * np.log(1 - y_pred))
def accuracy_score(y_true, y_pred):
correct = (y_pred == y_true).astype(np.int32)
return np.average(correct)
def precision_score(y, z):
tp = (z * y).sum()
fp = (z * (1 - y)).sum()
if tp + fp == 0:
return 1.0
else:
return tp / (tp + fp)
def recall_score(y, z):
tp = (z * y).sum()
fn = ((1 - z) * y).sum()
if tp + fn == 0:
return 1
else:
return tp / (tp + fn)(3)梯度下降算法实现Logistic回归算法来求解山鸢尾识别问题
python
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from logistic_regression.lib.logistic_regression_gd import LogisticRegression
import logistic_regression.lib.classification_metrics as metrics
def process_features(X):
m, n = X.shape
X = np.c_[np.ones((m, 1)), X]
return X
iris = datasets.load_iris()
X = iris["data"]
y = (iris["target"]==2).astype(np.int32).reshape(-1,1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
X_train = process_features(X_train)
X_test = process_features(X_test)
model = LogisticRegression()
model.fit(X_train, y_train, eta=0.1, N=50000)
proba = model.predict_proba(X_test)
y_pred = model.predict(X_test)
entropy = metrics.cross_entropy(y_test, proba)
precision = metrics.precision_score(y_test, y_pred)
recall = metrics.recall_score(y_test, y_pred)
accuracy = metrics.accuracy_score(y_test, y_pred)
print("cross entropy = {}".format(entropy))
print("precision = {}".format(precision))
print("recall = {}".format(recall))
print("accuracy = {}".format(accuracy))
2.上机实验题二 乳腺癌预测问题
首先导入必要的库,然后从sklearn.datasets中加载乳腺癌数据集,该数据集包含多个特征和对应的标签,用于判断肿瘤是良性还是恶性。接着,使用将数据集划分为训练集和测试集,其中30%用于测试。之后,对训练集和测试集进行标准化处理,以消除不同量纲的影响,确保模型训练的稳定性。然后,实例化LogisticRegression模型,并设置最大迭代次数为1000,确保模型有足够的迭代次数来达到收敛。在标准化后的训练集上训练逻辑回归模型,并对标准化后的测试集进行预测。模型的性能通过计算准确率、精确率和召回率来评估,并打印出来。此外,还计算预测概率,绘制ROC曲线和计算AUC值,以评估模型在不同阈值下的性能。运行结果显示,该模型在乳腺癌数据集上的表现非常出色,准确率为98%,精确率为99%,召回率为98%,表明模型在正确识别良性和恶性肿瘤方面具有很高的准确性,几乎能够准确预测绝大多数的病例,同时在预测恶性肿瘤时的准确度也非常。
python
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score, roc_curve
import matplotlib.pyplot as plt
# 加载数据集
data = load_breast_cancer()
X = data.data
y = data.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 数据缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 创建Logistic回归模型,增加max_iter参数
model = LogisticRegression(max_iter=1000)
# 训练模型
model.fit(X_train_scaled, y_train)
# 预测测试集
y_pred = model.predict(X_test_scaled)
# 计算准确率、精确率和召回率
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
# 打印性能指标
print(f"Accuracy: {accuracy:.2f}")
print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
# 计算ROC曲线和AUC值
y_pred_proba = model.predict_proba(X_test_scaled)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
auc = roc_auc_score(y_test, y_pred_proba)
# 绘制ROC曲线
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()3.上机实验题三
首先定义了几个用于评估分类模型性能的函数,包括交叉熵损失、准确率、精确度和召回率。接着,定义了一个Softmax回归模型,该模型使用梯度下降算法进行训练。模型的fit方法用于训练,predict_proba方法用于预测概率,而predict方法则用于获取最可能的类别标签。
首先加载了鸢尾花数据集,并对特征进行了归一化处理。之后,使用One-Hot编码将目标变量转换为独热编码形式。接着,将数据集分为训练集和测试集。在训练集上训练Softmax回归模型后,使用测试集进行预测,并计算了模型的准确率。
结果显示,模型在测试集上的准确率为0.8333,即83.33%。这意味着模型能够正确分类83.33%的测试样本。这个结果表明模型在鸢尾花数据集上的表现是相对不错的,但仍有改进的空间,以提高对剩余16.67%测试样本的分类准确率。
(1)定义softmax相关模型
python
import numpy as np
def softmax(scores):
e = np.exp(scores)
s = e.sum(axis=1)
for i in range(len(s)):
e[i] /= s[i]
return e
class SoftmaxRegression:
def fit(self, X, y, eta=0.1, N=5000):
m, n = X.shape
m, k = y.shape
w = np.zeros(n * k).reshape(n,k)
for t in range(N):
proba = softmax(X.dot(w))
g = X.T.dot(proba - y) / m
w = w - eta * g
self.w = w
def predict_proba(self, X):
return softmax(X.dot(self.w))
def predict(self, X):
proba = self.predict_proba(X)
return np.argmax(proba, axis=1)(2)定义交叉熵、准确率、精确率、召回率
python
import numpy as np
def cross_entropy(y_true, y_pred):
return np.average(-y_true * np.log(y_pred) - (1 - y_true) * np.log(1 - y_pred))
def accuracy_score(y_true, y_pred):
correct = (y_pred == y_true).astype(np.int32)
return np.average(correct)
def precision_score(y, z):
tp = (z * y).sum()
fp = (z * (1 - y)).sum()
if tp + fp == 0:
return 1.0
else:
return tp / (tp + fp)
def recall_score(y, z):
tp = (z * y).sum()
fn = ((1 - z) * y).sum()
if tp + fn == 0:
return 1
else:
return tp / (tp + fn)(3)softmax回归的梯度下降算法求解鸢尾花问题
python
import numpy as np
from sklearn import datasets
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from logistic_regression.lib.softmax_regression_gd import SoftmaxRegression
from logistic_regression.lib.classification_metrics import accuracy_score
def process_features(X):
scaler = MinMaxScaler(feature_range=(0,1))
X = scaler.fit_transform(1.0*X)
m, n = X.shape
X = np.c_[np.ones((m, 1)), X]
return X
iris = datasets.load_iris()
X = iris["data"]
y = iris["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
X_train = process_features(X_train)
X_test = process_features(X_test)
model = SoftmaxRegression()
encoder = OneHotEncoder()
y_train = encoder.fit_transform(y_train.reshape(-1,1)).toarray()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("accuracy = {}".format(accuracy))4.红酒产地预测问题
首先,从sklearn.datasets模块加载了红酒数据集,该数据集包含了178瓶红酒的13种特征指标和对应的产地标签。接着,将数据集划分为训练集和测试集,其中测试集占30%。
在训练模型之前,对特征进行了标准化处理,以消除不同特征量纲的影响,使得模型训练更加稳定。然后,定义了一个LogisticRegression模型,设置multi_class参数为multinomial以适应多分类问题,并通过solver='lbfgs'和max_iter=1000来确保模型能够收敛。
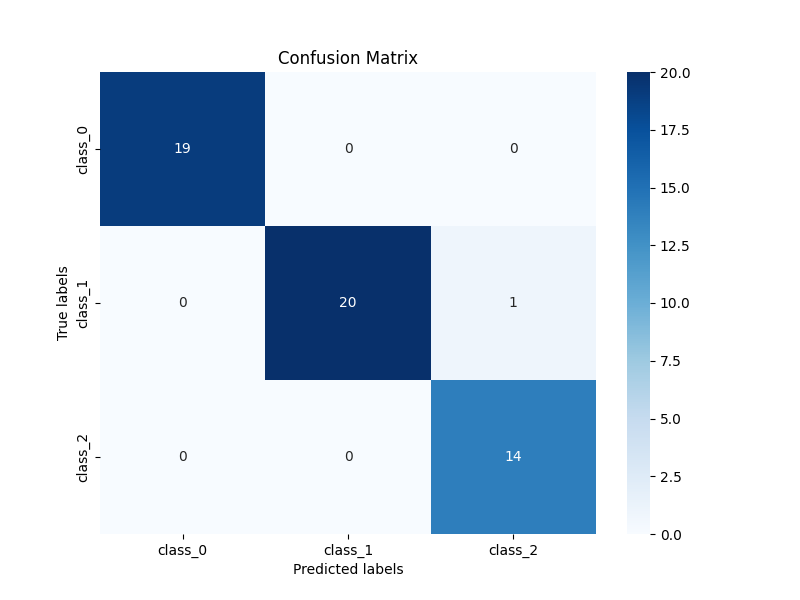
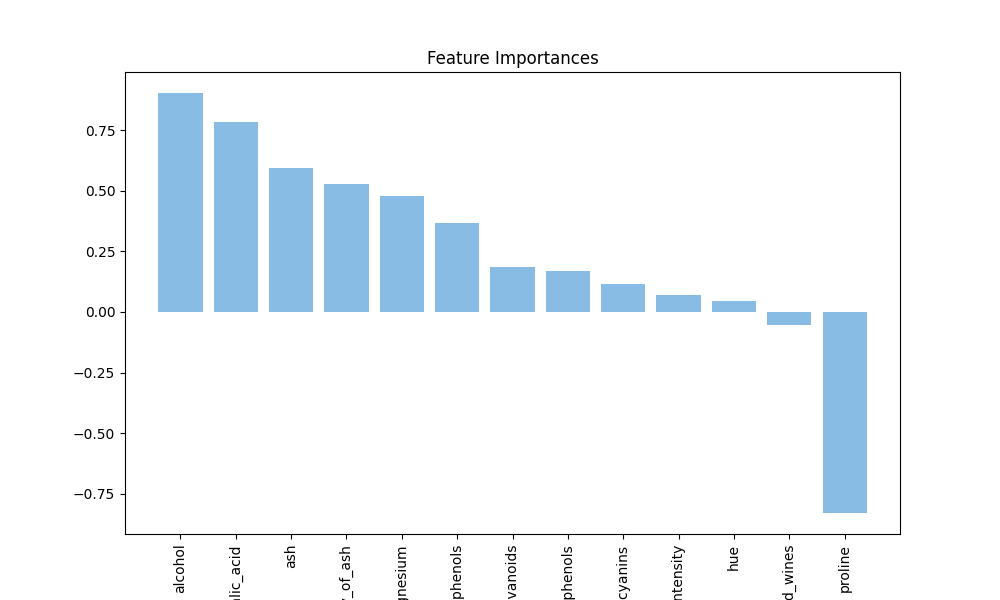
模型训练完成后,使用测试集进行了预测,并通过accuracy_score函数计算了模型的准确率,结果显示模型的预测准确率为98%,这表明模型在红酒产地预测任务上表现非常出色。此外,还绘制了混淆矩阵和特征重要性图,以直观展示模型的性能和各个特征对预测结果的贡献程度。混淆矩阵的热图显示了模型在不同产地红酒上的分类效果,而特征重要性图则展示了各个特征在模型决策中的重要性排序。
python
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix
import warnings
warnings.filterwarnings('ignore')
# 加载红酒数据集
data = load_wine()
X = data.data
y = data.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 特征缩放
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 定义Softmax回归模型
model = LogisticRegression(multi_class='multinomial', solver='lbfgs', max_iter=1000)
# 训练模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")