1. 背景:为什么默认调度会出现倾斜
当一个作业内各个 JobVertex 的 parallelism 不一致,并且它们共享同一个 slot sharing group 时,一个 slot 里会塞进多个 vertex 的 subtask(这本来是为了更高的 slot 复用率)。问题在于默认策略在"把 tasks 放到各个 TM"时,可能会出现明显的不均匀:
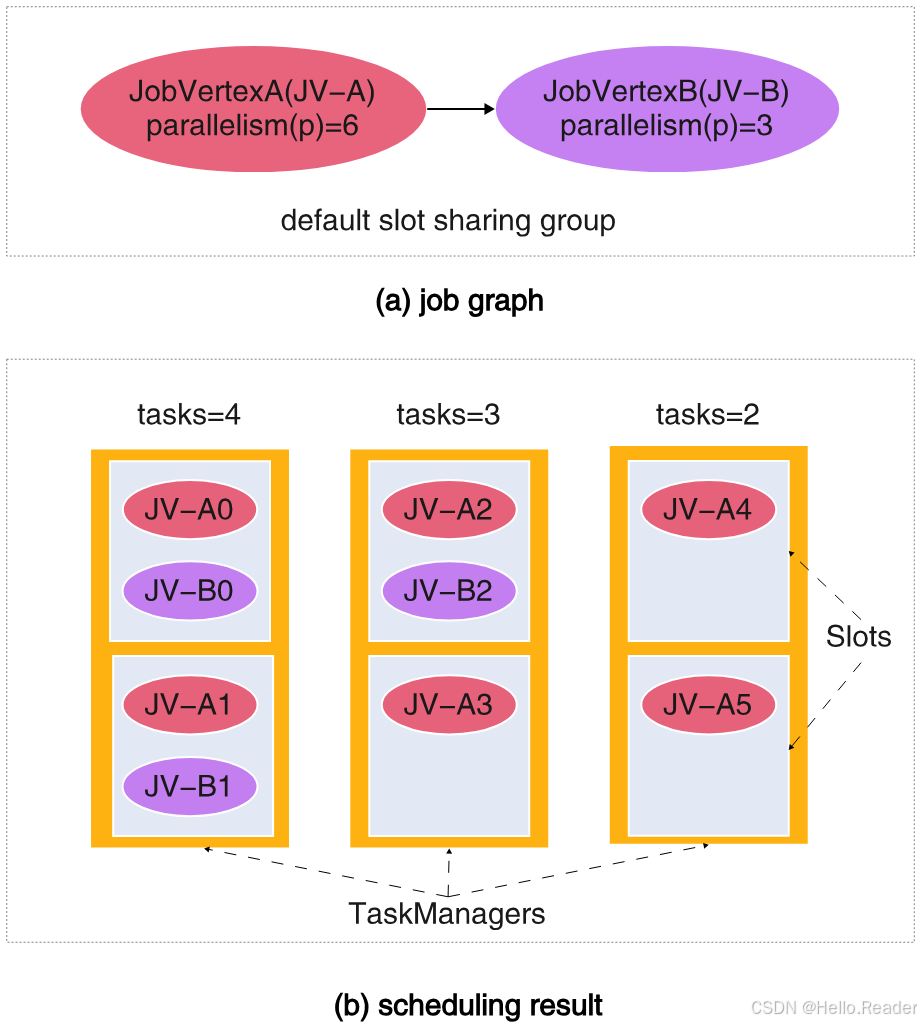
- 例子:JV-A 并行度 6,JV-B 并行度 3,同一个 slot sharing group
- 默认调度可能出现:最忙的 TM 上有 4 个 tasks,最闲的 TM 只有 2 个 tasks
- 直观后果:4 个 tasks 的 TM 更容易成为全局瓶颈(CPU 忙、GC 多、网络更拥塞、反压更严重)
注意:并行度不一致并不必然导致瓶颈。有时算子很轻、链路很短、TM 资源充裕,默认策略也能跑得很好,所以不要看到并行度不一致就条件反射去开。
2. Balanced Tasks Scheduling 解决的是什么
它的目标很明确也很"朴素":
在一个作业的资源视角中,让每个 TaskManager 承载的 task 数尽量接近(max-min 差值尽可能小),从而改善 TaskManager 间的资源使用倾斜。
它只看 "task 数量" 这个指标,因此也有天然边界:如果 task 的"重量"差异极大(比如一个是重 CPU 的 Python UDF,另一个是轻量 map),只均衡数量未必能均衡负载。
3. 原理:两阶段分配(tasks → slots,再 slots → TaskManagers)
这个策略分两步做分配:
阶段一:tasks-to-slots(先把任务尽量均匀塞进 slot)
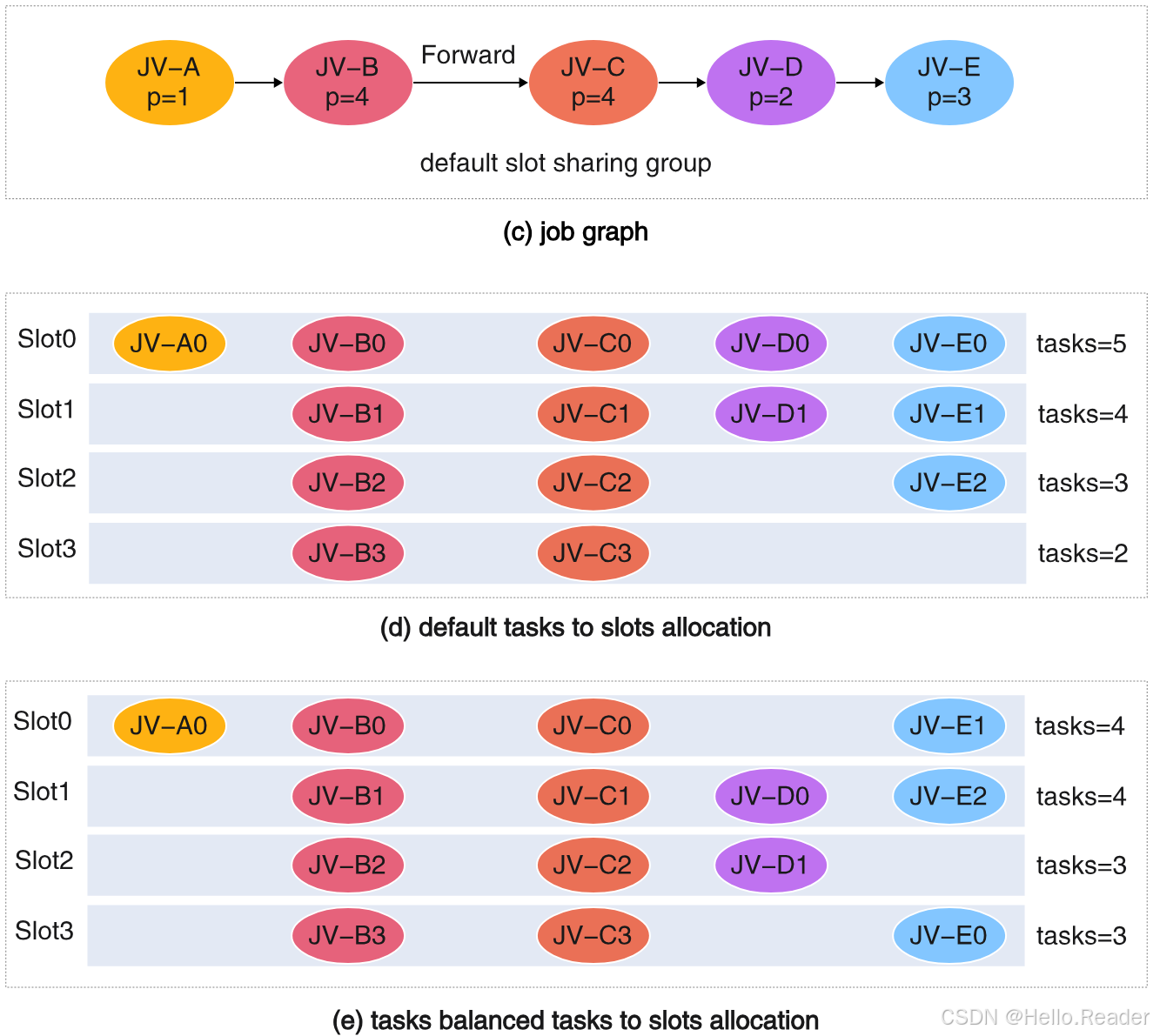
以包含 5 个 JobVertex 的例子说明:并行度分别是 1、4、4、2、3,且都在默认 slot sharing group。
做法是:
1)先找出当前 slot sharing group 内"最大并行度"的顶级选手(例如 p=4 的 JV-B、JV-C)
2)对这些最大并行度的 vertex:直接把第 i 个 subtask 放进第 i 个 slot
- JV-B0 → Slot0,JV-B1 → Slot1 ...
- JV-C0 → Slot0,JV-C1 → Slot1 ...
3)对并行度较小的 vertex:把它们的 subtasks 用 round-robin 的方式轮流塞到这些 slots 里,直到放完
- 这样各个 slot 里的 task 数差距会被压得很小
效果怎么衡量?看 "每个 slot 里 task 数量"的范围(max-min):
- 默认策略可能 range=3(差距大)
- 任务数均衡策略可以把 range 压到 1(更均匀)
直觉理解:先把"数量最多的那几组任务"铺满所有 slot,再把剩下的小并行度任务均匀点缀进去。
阶段二:slots-to-TaskManagers(再把 slot 均匀分给 TM)
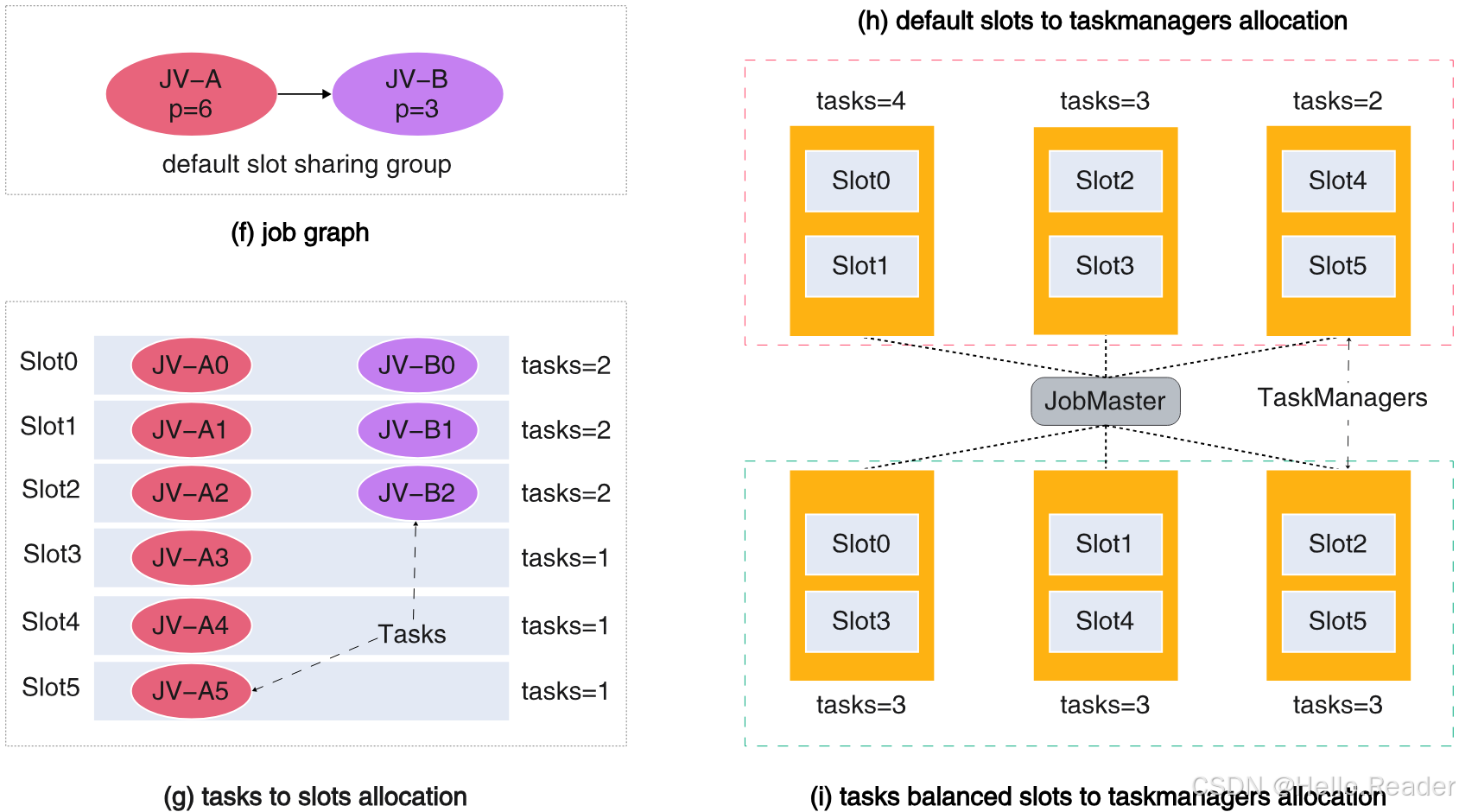
继续用 JV-A(p=6) 与 JV-B(p=3) 的例子说明。
阶段一结束后你会得到一组 slot 请求,每个 slot 请求里包含若干 tasks。可能出现这种结构:
- Slot0/1/2:每个有 2 个 tasks
- Slot3/4/5:每个有 1 个 task
接着阶段二做的是:
1)一次性提交所有 slot 请求,等资源都 ready(确保"全局视角"下做均衡)
2)按 slot 内 task 数量从高到低排序(先处理"重 slot")
3)依次把 slot 分配给当前 task 数最少的 TaskManager(贪心地填最空的 TM)
4)直到所有 slots 分配完成
最终效果(对应图里的对比):
- 默认策略:TM 之间 task 数差值可能是 2
- Balanced 策略:可以做到每个 TM 恰好 3 个 tasks,差值为 0
一句话:先把 slot 内部塞得均匀,再把 slot 当成"装着若干 tasks 的包裹",把这些包裹按重量从大到小分给最空的 TM。
4. 怎么启用:一行配置搞定
在 flink-conf.yaml 里启用:
yaml
taskmanager.load-balance.mode: tasks如果你更喜欢作业级覆盖(例如提交时临时开关),通常可以用 -D 方式把配置带进去:
bash
flink run -Dtaskmanager.load-balance.mode=tasks -c your.Main job.jar5. 什么时候该用,什么时候别用
适合开启的典型信号:
- 作业图里明显存在并行度不一致,且大量 vertex 在同一个 slot sharing group
- Flink Web UI/指标能观察到:个别 TM 长期更忙(CPU、GC、网络、反压都更重)
- 任务数倾斜与性能瓶颈高度相关:最忙 TM 就是吞吐"卡脖子点"
不建议开启的情况:
- 你没有观察到 TM 层面的"任务数倾斜导致的瓶颈",只是看到并行度不一致
- 你遇到的瓶颈其实是数据倾斜、热点 key、外部系统限流、反压链路过长等问题
- 你的 task "重量"差异很大(均衡数量不代表均衡资源),可能开了也不改善,甚至引入额外调度开销
文档也明确提醒:如果你没有上述瓶颈,开启可能带来性能下降。
6. 实战建议:把它用在刀刃上
1)先验证问题是不是"任务数倾斜"
看每个 TM 的 task 数量、CPU busy、mailbox busy、GC、网络吞吐、反压分布。如果"任务数最多的 TM 总是最慢",这招很对症。
2)别忘了 slot sharing group 本身就是杠杆
如果某些算子特别重,单靠均衡策略不如直接把它们拆到独立 slot sharing group,让资源隔离更确定。
3)把"均衡数量"当作第一步,不要神化
Balanced tasks 解决的是"调度分配层面的倾斜",不解决数据倾斜、外部依赖慢、算子实现低效等更常见的问题。
4)上线前后对比一组指标
建议至少对比:吞吐、端到端延迟、反压、最忙 TM CPU/GC、checkpoint 时长与失败率。只看"平均值"容易误判,重点看"最忙 TM 是否降下来了"。