前言
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net
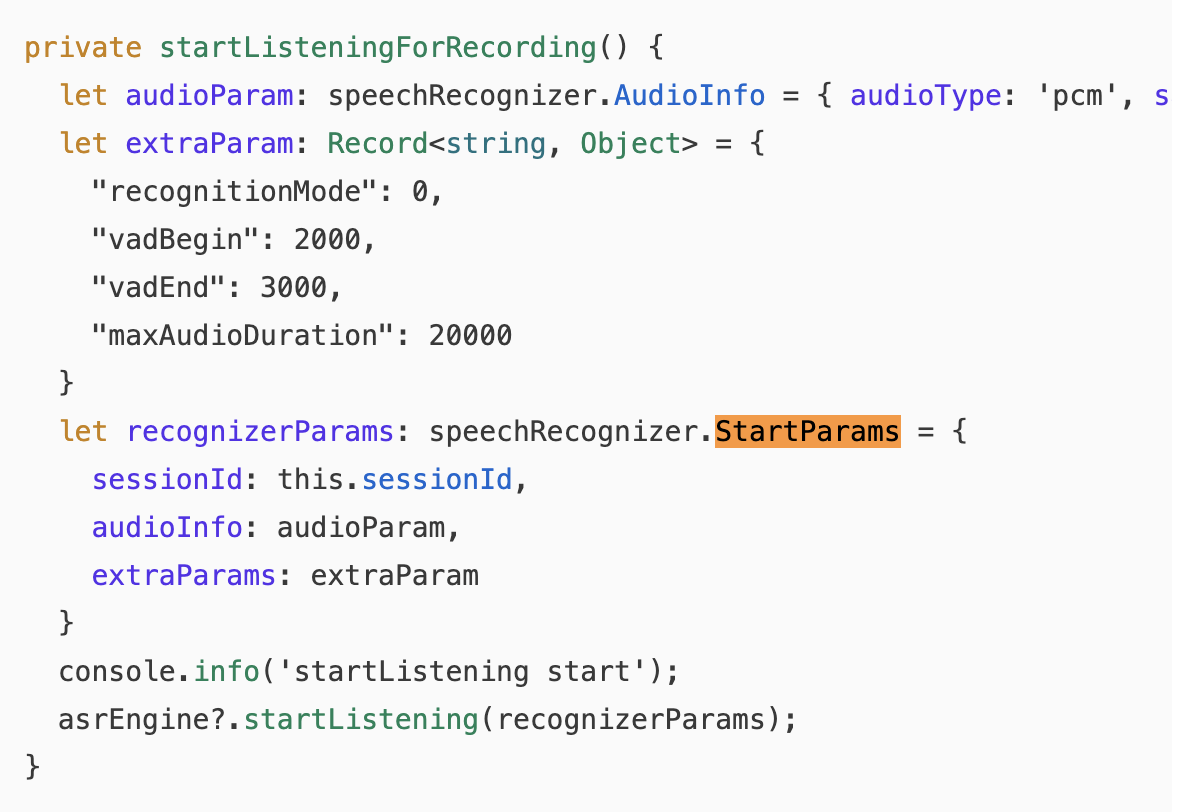
引擎创建好了,监听器也设置好了,现在终于可以开始识别 了。startListening方法是用户按下"开始"按钮后真正触发的动作,也是整个语音识别流程中参数最多的一个环节。
Core Speech Kit的startListening需要传入一个StartParams对象,里面包含了音频参数、扩展参数、会话ID等配置。这些参数直接影响识别的质量和行为------采样率设错了识别不出来,VAD参数设错了要么截断用户的话,要么等半天才返回结果。
我在调试这些参数的时候,反复试了十几种组合才找到比较平衡的配置。今天把这些经验分享出来。
💡 本文对应源码 :
FlutterSpeechPlugin.ets的startListening方法,第180-222行。
一、StartParams 参数结构详解
1.1 整体结构
typescript
interface StartParams {
sessionId: string; // 会话ID
audioInfo: AudioInfo; // 音频参数
extraParams: Record<string, Object>; // 扩展参数
}三个字段,每个都有讲究:
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| sessionId | string | ✅ | 标识本次识别会话 |
| audioInfo | AudioInfo | ✅ | 音频采集参数 |
| extraParams | Record<string, Object> | ✅ | 识别行为控制参数 |
1.2 flutter_speech中的完整构建
typescript
private startListening(result: MethodResult): void {
// ... 前置检查 ...
const audioParam: speechRecognizer.AudioInfo = {
audioType: 'pcm',
sampleRate: 16000,
soundChannel: 1,
sampleBit: 16
};
const extraParam: Record<string, Object> = {
"recognitionMode": 0,
"vadBegin": 2000,
"vadEnd": 3000,
"maxAudioDuration": 60000
};
const recognizerParams: speechRecognizer.StartParams = {
sessionId: this.sessionId,
audioInfo: audioParam,
extraParams: extraParam
};
this.asrEngine.startListening(recognizerParams);
result.success(true);
}二、AudioInfo 音频参数:PCM 格式、采样率、声道、位深
2.1 AudioInfo 结构
typescript
interface AudioInfo {
audioType: string; // 音频格式
sampleRate: number; // 采样率(Hz)
soundChannel: number; // 声道数
sampleBit: number; // 位深(bit)
}2.2 各参数详解
audioType - 音频格式
typescript
audioType: 'pcm'| 值 | 说明 | flutter_speech的选择 |
|---|---|---|
| 'pcm' | 原始PCM音频 | ✅ 使用这个 |
目前Core Speech Kit只支持PCM格式。PCM(Pulse Code Modulation,脉冲编码调制)是最基础的音频格式,没有压缩,数据量大但延迟低。
📌 为什么只支持PCM:语音识别引擎需要原始音频数据来做特征提取。如果传入压缩格式(如MP3、AAC),引擎还需要先解码,增加延迟。PCM直接就能用,效率最高。
sampleRate - 采样率
typescript
sampleRate: 16000| 采样率 | 说明 | 适用场景 |
|---|---|---|
| 8000 Hz | 电话质量 | 低带宽场景 |
| 16000 Hz | 语音识别标准 | 推荐 |
| 44100 Hz | CD质量 | 音乐录制 |
| 48000 Hz | 专业音频 | 视频制作 |
16kHz是语音识别领域的事实标准。大多数语音识别模型都是用16kHz的数据训练的,使用其他采样率可能导致识别准确率下降。
💡 我的测试结果:我试过用8000Hz,识别率明显下降,尤其是声母相近的字容易混淆。用44100Hz倒是没问题,但数据量大了将近3倍,浪费带宽和内存。16000Hz是最佳平衡点。
soundChannel - 声道数
typescript
soundChannel: 1| 声道数 | 说明 | 适用场景 |
|---|---|---|
| 1 | 单声道 | 语音识别(推荐) |
| 2 | 双声道(立体声) | 音乐播放 |
语音识别只需要单声道。人说话的声音是单一音源,双声道不会带来额外的信息量,只会增加数据量。
sampleBit - 位深
typescript
sampleBit: 16| 位深 | 动态范围 | 说明 |
|---|---|---|
| 8 bit | 48 dB | 质量较低 |
| 16 bit | 96 dB | 标准质量(推荐) |
| 24 bit | 144 dB | 专业录音 |
| 32 bit | 192 dB | 极高精度 |
16bit是语音识别的标准位深,能提供足够的动态范围来区分语音中的细微差异。
2.3 音频参数的数据量计算
数据量 = 采样率 × 位深 × 声道数 × 时长
flutter_speech的配置:
16000 Hz × 16 bit × 1 channel = 256,000 bits/s = 32 KB/s
录制60秒的数据量:
32 KB/s × 60s = 1,920 KB ≈ 1.9 MB每秒32KB的数据量对于在线传输来说完全可以接受。
2.4 参数错误的后果
| 错误配置 | 后果 | 表现 |
|---|---|---|
| audioType不是'pcm' | 引擎无法处理 | startListening抛异常 |
| sampleRate设为8000 | 识别率下降 | 识别结果不准确 |
| soundChannel设为2 | 可能不兼容 | 引擎可能报错 |
| sampleBit设为8 | 音质太差 | 识别率严重下降 |
三、extraParams 扩展参数:recognitionMode、VAD 配置
3.1 extraParams 结构
typescript
const extraParam: Record<string, Object> = {
"recognitionMode": 0,
"vadBegin": 2000,
"vadEnd": 3000,
"maxAudioDuration": 60000
};3.2 recognitionMode - 识别模式
typescript
"recognitionMode": 0| 值 | 模式 | 说明 | 适用场景 |
|---|---|---|---|
| 0 | 短语音模式 | 识别短句,VAD自动停止 | 语音指令、搜索 |
| 1 | 长语音模式 | 持续识别,不自动停止 | 会议记录、听写 |
flutter_speech使用短语音模式(0),适合"说一句话就停"的交互场景。
两种模式的行为差异:
短语音模式 (recognitionMode=0):
用户说话 → 停顿 → VAD检测到静音 → 自动停止 → 返回结果
长语音模式 (recognitionMode=1):
用户说话 → 停顿 → 继续等待 → 用户继续说 → ... → 手动调用finish停止🎯 选择建议:如果你的App是"按住说话"的交互模式,用短语音模式。如果是"持续听写"的模式(比如语音笔记),用长语音模式。
3.3 vadBegin - VAD开始超时
typescript
"vadBegin": 2000 // 毫秒含义 :开始监听后,如果在vadBegin毫秒内没有检测到语音,就认为用户没有说话,自动停止识别。
startListening
│
├── 0ms: 开始等待语音
│
├── 500ms: 还没检测到语音...
│
├── 1000ms: 还没检测到语音...
│
├── 1500ms: 还没检测到语音...
│
└── 2000ms: vadBegin超时!→ onError(无语音输入)| vadBegin值 | 效果 | 适用场景 |
|---|---|---|
| 1000ms | 等待1秒 | 快速响应场景 |
| 2000ms | 等待2秒 | 平衡(推荐) |
| 5000ms | 等待5秒 | 用户可能需要思考 |
| 10000ms | 等待10秒 | 极端宽松 |
💡 调优经验:2秒是比较合理的值。太短的话,用户还没来得及说话就超时了;太长的话,用户不说话时要等很久才能收到反馈。
3.4 vadEnd - VAD结束超时
typescript
"vadEnd": 3000 // 毫秒含义 :检测到语音后,如果连续vadEnd毫秒没有新的语音输入(静音),就认为用户说完了,自动停止识别。
用户说话
│
├── "今天天气" ← 正在说
│
├── 停顿 0.5秒 ← 还在vadEnd范围内,继续等待
│
├── "怎么样" ← 继续说
│
├── 停顿 1秒 ← 还在范围内
│
├── 停顿 2秒 ← 还在范围内
│
└── 停顿 3秒 ← vadEnd超时!→ 认为说完了 → 返回最终结果| vadEnd值 | 效果 | 适用场景 |
|---|---|---|
| 1000ms | 1秒静音就停 | 快速指令 |
| 2000ms | 2秒静音就停 | 短句识别 |
| 3000ms | 3秒静音就停 | 平衡(推荐) |
| 5000ms | 5秒静音就停 | 长句/思考型 |
🤔 vadEnd的取舍:设太短,用户说话中间停顿一下就被截断了(比如"我想...嗯...去北京"中间的停顿)。设太长,用户说完后要等好几秒才能看到最终结果。3秒是我测试下来的最佳平衡点。
3.5 vadBegin和vadEnd的配合
vadBegin=2000, vadEnd=3000 的完整时序:
t=0s: startListening → 开始等待语音
t=0-2s: 等待用户开口(vadBegin倒计时)
t=0.8s: 用户开始说话 → vadBegin停止计时
t=0.8-3s: 用户持续说话
t=3s: 用户停止说话 → vadEnd开始计时
t=3-6s: 等待用户继续说(vadEnd倒计时)
t=6s: vadEnd超时 → 返回最终结果四、sessionId 会话管理机制
4.1 sessionId的作用
typescript
private sessionId: string = '10000';sessionId是识别会话的唯一标识,用于:
- 区分不同的识别会话:虽然flutter_speech只有一个会话
- 在回调中关联请求:每个回调都会带上sessionId
- 停止/取消指定会话 :
finish(sessionId)和cancel(sessionId)需要指定
4.2 flutter_speech的sessionId策略
flutter_speech使用了固定的sessionId ('10000'),因为:
- 同一时间只有一个识别会话
- 不需要区分多个并发会话
- 简化了代码逻辑
typescript
// 所有操作都用同一个sessionId
this.asrEngine.startListening({ sessionId: this.sessionId, ... });
this.asrEngine.finish(this.sessionId);
this.asrEngine.cancel(this.sessionId);4.3 如果需要动态sessionId
如果你的应用需要管理多个识别会话(flutter_speech不需要),可以用时间戳生成唯一ID:
typescript
// 动态生成sessionId(flutter_speech未使用)
private generateSessionId(): string {
return `session_${Date.now()}_${Math.random().toString(36).substr(2, 9)}`;
}4.4 sessionId与回调的关联
每个监听器回调都会带上sessionId参数:
typescript
onStart(sessionId: string, eventMessage: string): void { ... }
onResult(sessionId: string, result: SpeechRecognitionResult): void { ... }
onError(sessionId: string, errorCode: number, errorMessage: string): void { ... }flutter_speech在回调中只用sessionId做日志记录,不做逻辑判断:
typescript
onStart(sessionId: string, eventMessage: string): void {
console.info(TAG, `onStart: sessionId=${sessionId}`); // 仅日志
channel?.invokeMethod('speech.onRecognitionStarted', null);
},五、maxAudioDuration 最大录音时长控制
5.1 参数含义
typescript
"maxAudioDuration": 60000 // 毫秒 = 60秒这个参数限制了单次识别的最大录音时长。超过这个时长,引擎会自动停止识别并返回结果。
5.2 为什么需要限制
- 防止资源浪费:无限制的录音会持续占用麦克风和网络
- 用户体验:超长的识别通常意味着用户忘记停止了
- 系统限制:Core Speech Kit可能有内部的时长限制
5.3 不同场景的建议值
| 场景 | 建议值 | 说明 |
|---|---|---|
| 语音搜索 | 15000 (15秒) | 搜索词通常很短 |
| 语音指令 | 10000 (10秒) | 指令更短 |
| 通用场景 | 60000 (60秒) | flutter_speech的选择 |
| 语音笔记 | 300000 (5分钟) | 长文本听写 |
| 会议记录 | 无限制 | 需要特殊处理 |
flutter_speech选择了60秒,对于大多数语音识别场景来说足够了。
5.4 超时后的行为
t=0s: startListening
t=0-60s: 正常识别
t=60s: maxAudioDuration超时
→ onResult(最终结果, isLast=true)
→ onComplete超时后引擎会自动停止,和用户主动调用stop的效果类似。
六、startListening 方法的完整实现
6.1 完整源码(带注释)
typescript
private startListening(result: MethodResult): void {
// ========== 前置检查 ==========
if (!this.asrEngine) {
result.error('ERROR_ENGINE_NOT_INITIALIZED',
'Speech engine not initialized. Call activate first.', null);
return;
}
try {
// ========== 防重入处理 ==========
if (this.isListening) {
this.asrEngine.cancel(this.sessionId);
this.isListening = false;
}
// ========== 重置状态 ==========
this.lastTranscription = '';
this.isListening = true;
// ========== 构建音频参数 ==========
const audioParam: speechRecognizer.AudioInfo = {
audioType: 'pcm',
sampleRate: 16000,
soundChannel: 1,
sampleBit: 16
};
// ========== 构建扩展参数 ==========
const extraParam: Record<string, Object> = {
"recognitionMode": 0,
"vadBegin": 2000,
"vadEnd": 3000,
"maxAudioDuration": 60000
};
// ========== 构建启动参数 ==========
const recognizerParams: speechRecognizer.StartParams = {
sessionId: this.sessionId,
audioInfo: audioParam,
extraParams: extraParam
};
// ========== 开始识别 ==========
this.asrEngine.startListening(recognizerParams);
result.success(true);
} catch (e) {
console.error(TAG, `startListening error: ${JSON.stringify(e)}`);
this.isListening = false;
result.error('ERROR_SPEECH_LISTEN',
`Failed to start listening: ${JSON.stringify(e)}`, null);
}
}6.2 流程图
startListening(result)
│
├── asrEngine == null?
│ └── 是 → error('ERROR_ENGINE_NOT_INITIALIZED') → return
│
├── isListening == true? (防重入)
│ └── 是 → cancel当前会话 → isListening = false
│
├── 重置状态
│ ├── lastTranscription = ''
│ └── isListening = true
│
├── 构建参数
│ ├── audioParam: PCM/16kHz/单声道/16bit
│ ├── extraParam: 短语音/VAD 2s+3s/最长60s
│ └── recognizerParams: sessionId + audio + extra
│
├── asrEngine.startListening(recognizerParams)
│ └── 失败 → catch → isListening = false → error
│
└── result.success(true)6.3 前置检查:引擎未初始化
typescript
if (!this.asrEngine) {
result.error('ERROR_ENGINE_NOT_INITIALIZED',
'Speech engine not initialized. Call activate first.', null);
return;
}如果用户没有先调用activate就直接调用listen,引擎还没创建,需要返回明确的错误提示。
6.4 防重入处理
typescript
if (this.isListening) {
this.asrEngine.cancel(this.sessionId);
this.isListening = false;
}如果上一次识别还没结束,用户又点了"开始",需要先取消上一次再开始新的。不做这个处理的话,可能会出现两个识别会话冲突的问题。
🤦 踩坑经历:我一开始没做防重入,测试时快速连续点击"开始"按钮,引擎就报错了。加了这个逻辑后就稳定了。
6.5 状态重置
typescript
this.lastTranscription = '';
this.isListening = true;每次开始新的识别前,清空上次的识别结果,并标记为"正在监听"状态。
七、与Android startListening的对比
7.1 代码对比
Android:
java
private void startListening(MethodChannel.Result result) {
Intent intent = new Intent(RecognizerIntent.ACTION_RECOGNIZE_SPEECH);
intent.putExtra(RecognizerIntent.EXTRA_LANGUAGE_MODEL,
RecognizerIntent.LANGUAGE_MODEL_FREE_FORM);
intent.putExtra(RecognizerIntent.EXTRA_PARTIAL_RESULTS, true);
intent.putExtra(RecognizerIntent.EXTRA_MAX_RESULTS, 3);
intent.putExtra(RecognizerIntent.EXTRA_LANGUAGE, locale);
speechRecognizer.startListening(intent);
result.success(true);
}OpenHarmony:
typescript
private startListening(result: MethodResult): void {
const recognizerParams: speechRecognizer.StartParams = {
sessionId: this.sessionId,
audioInfo: { audioType: 'pcm', sampleRate: 16000, soundChannel: 1, sampleBit: 16 },
extraParams: { "recognitionMode": 0, "vadBegin": 2000, "vadEnd": 3000, "maxAudioDuration": 60000 }
};
this.asrEngine.startListening(recognizerParams);
result.success(true);
}7.2 参数对比
| 功能 | Android (Intent) | OpenHarmony (StartParams) |
|---|---|---|
| 语言 | EXTRA_LANGUAGE | 创建引擎时指定 |
| 部分结果 | EXTRA_PARTIAL_RESULTS=true | 默认支持 |
| 最大结果数 | EXTRA_MAX_RESULTS | 不支持 |
| 音频格式 | 系统自动 | audioInfo手动指定 |
| VAD控制 | 系统默认 | vadBegin/vadEnd可配 |
| 最大时长 | 系统默认 | maxAudioDuration可配 |
| 识别模式 | LANGUAGE_MODEL_* | recognitionMode |
📌 OpenHarmony的参数控制更精细:Android的很多参数是系统默认的,开发者无法控制。OpenHarmony允许开发者精确配置音频参数和VAD参数,灵活性更高。
八、参数调优建议
8.1 不同场景的推荐配置
语音搜索场景:
typescript
const extraParam = {
"recognitionMode": 0, // 短语音
"vadBegin": 1500, // 1.5秒等待开口
"vadEnd": 2000, // 2秒静音就停
"maxAudioDuration": 15000 // 最长15秒
};语音指令场景:
typescript
const extraParam = {
"recognitionMode": 0, // 短语音
"vadBegin": 2000, // 2秒等待
"vadEnd": 1500, // 1.5秒静音就停(指令通常很短)
"maxAudioDuration": 10000 // 最长10秒
};听写/笔记场景:
typescript
const extraParam = {
"recognitionMode": 1, // 长语音
"vadBegin": 5000, // 5秒等待(用户可能在思考)
"vadEnd": 5000, // 5秒静音才停(允许长停顿)
"maxAudioDuration": 300000 // 最长5分钟
};8.2 调优原则
- vadBegin:根据用户从点击按钮到开始说话的平均时间来设置。通常1.5-3秒
- vadEnd:根据用户说话中停顿的平均时长来设置。短句1.5-2秒,长句3-5秒
- maxAudioDuration:根据业务场景的最大合理时长来设置。宁可设大一点
- recognitionMode:一句话的交互用0,持续听写用1
总结
本文详细讲解了flutter_speech语音识别启动的参数配置:
- AudioInfo:PCM格式、16kHz采样率、单声道、16bit位深------语音识别的标准配置
- recognitionMode:0=短语音(自动停止),1=长语音(手动停止)
- VAD参数:vadBegin控制等待开口时间,vadEnd控制静音停止时间
- maxAudioDuration:最大录音时长,防止无限录音
- sessionId:会话标识,flutter_speech使用固定值'10000'
- 防重入:重复调用时先cancel旧会话再开始新会话
下一篇我们讲语音识别的停止与取消 ------stop和cancel两个方法的语义区别和实现细节。
如果这篇文章对你有帮助,欢迎点赞👍、收藏⭐、关注🔔,你的支持是我持续创作的动力!
相关资源: