大家除夕快乐!!!祝大家新的一年都万事顺心,吉祥如意~~~~~~~~~
开篇介绍:
hello 大家,我们见面了,那么在前面几篇博客中,我们成功的模拟实现了C++中的vector,并且深度的了解了它,那么接下来,我们就要去了解一下,另外一个数据结构------list
在 C++ 标准库的序列容器家族中,std::list 是一个极具特色的存在 ------ 它以双向链表为底层实现,专为高效插入、删除操作而生,完美弥补了 std::vector 在中间位置修改元素时的性能短板。本文将从底层原理、核心特性、常用接口、实战场景到性能对比,全方位拆解 std::list,帮你彻底掌握这个 "灵活高效" 的容器。
一、开篇:为什么需要 std::list?
在学习 std::list 之前,我们先思考一个问题:有了 std::vector 这种 "万能容器",为什么还需要 std::list?
答案藏在 内存布局与操作效率 的权衡中:
std::vector是连续内存数组,优势是随机访问([]操作 O (1))、缓存友好,但中间位置插入 / 删除需移动大量元素(O (n) 时间),且扩容时可能复制整个数组;std::list是双向链表,元素非连续存储,优势是任意位置插入 / 删除仅需调整指针(O (1) 时间),无需扩容,但不支持随机访问,缓存命中率较低。
简单说:频繁访问用 vector,频繁修改用 list。这也是 STL 容器设计的核心思想 ------ 没有万能容器,只有最适合场景的容器。
二、底层原理:双向链表的结构解密
要真正理解 std::list 的特性,必须先搞懂其底层结构。std::list 的本质是 双向链表,每个元素被封装在独立的 "节点" 中,节点间通过指针相互连接。
2.1 节点结构设计
一个典型的 std::list 节点包含三部分(不同编译器实现略有差异,但核心一致):
template <typename T>
struct ListNode {
T data; // 数据域:存储元素值
ListNode* prev; // 前驱指针:指向前一个节点
ListNode* next; // 后继指针:指向后一个节点
// 节点构造函数
ListNode(const T& val) : data(val), prev(nullptr), next(nullptr) {}
};2.2 链表整体结构
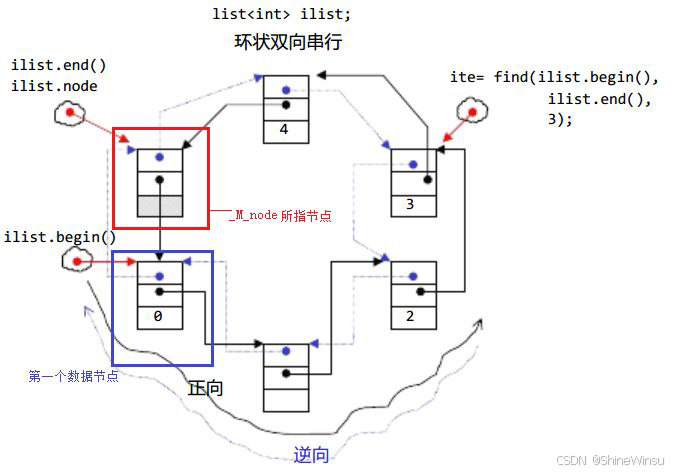
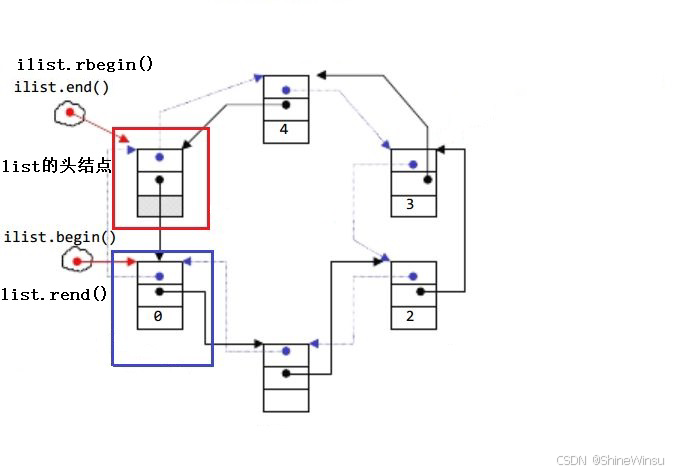
std::list 通常会使用 哨兵节点(Sentinel Node)(也叫 "伪头节点""伪尾节点")来简化边界处理。哨兵节点不存储有效数据,仅用于标记链表的首尾,使得空链表和非空链表的操作逻辑统一。
结构示意图(以存储 int 为例):
[哨兵头节点] <-> [节点1: data=1] <-> [节点2: data=2] <-> [节点3: data=3] <-> [哨兵尾节点]
↑ ↑
begin() end()begin():返回指向第一个有效节点(节点 1)的迭代器;end():返回指向哨兵尾节点的迭代器(尾后迭代器,不指向有效元素);- 空链表时,哨兵头节点的
next指向哨兵尾节点,prev也指向哨兵尾节点。
2.3 核心优势的底层支撑
正是这种双向链表结构,赋予了 std::list 两大核心优势:
- 插入 / 删除高效 :无需移动元素,仅需修改相邻节点的
prev和next指针(比如在节点 1 和节点 2 之间插入新节点,只需让节点 1 的next指向新节点,新节点的prev指向节点 1,新节点的next指向节点 2,节点 2 的prev指向新节点); - 无需扩容 :插入元素时动态分配单个节点,删除时释放单个节点,不会像
std::vector那样因扩容复制大量元素。
三、核心特性:std::list 的关键特点
3.1 非连续内存存储
- 元素在内存中分散存储,节点地址无需连续;
- 优点:插入 / 删除不影响其他节点的内存地址,迭代器(除被删除节点的迭代器)始终有效;
- 缺点:不支持随机访问(无法通过下标
[]或at()直接访问第 n 个元素,需从头部 / 尾部遍历,时间复杂度 O (n))。
3.2 双向迭代器
std::list 的迭代器是 双向迭代器(BidirectionalIterator),支持:
++it:向后移动到下一个元素;--it:向前移动到上一个元素;- 解引用
*it访问元素; - 不支持随机访问操作(如
it + 5、it -= 2),因此依赖随机访问迭代器的算法(如std::sort)无法直接使用,需用list自带的sort成员函数。
3.3 迭代器有效性
std::list 的迭代器有效性规则是其一大亮点,对比 std::vector 更友好:
- 插入元素后:所有迭代器(包括指向插入位置的迭代器)均有效(节点未移动,仅指针调整);
- 删除元素后:仅指向被删除节点的迭代器失效,其他迭代器(包括前后节点的迭代器)仍有效;
- 对比
std::vector:vector插入可能导致扩容(所有迭代器失效),删除中间元素会导致后续迭代器失效。
3.4 内存开销
每个节点需额外存储两个指针(prev 和 next),因此内存开销比 std::vector 大:
- 对于 64 位系统,每个指针占 8 字节,一个存储
int(4 字节)的节点总占用 4 + 8 + 8 = 20 字节,指针开销占 80%; - 对于大数据类型(如自定义类
Person),指针开销占比会降低,内存效率会提升。
四、常用接口:从基础到进阶(附示例)
std::list 的接口设计遵循 STL 容器的统一风格,同时提供了链表特有的操作(如 splice、merge)。以下是分类整理的核心接口,结合示例代码帮助理解。
4.1 构造与析构
| 接口 | 功能 | 示例 |
|---|---|---|
list() |
默认构造:创建空链表 | std::list<int> l; |
list(size_t n, const T& val) |
构造包含 n 个 val 的链表 | std::list<int> l(3, 10); // {10, 10, 10} |
list(InputIt first, InputIt last) |
用迭代器范围构造 | std::vector<int> v = {1,2,3}; std::list<int> l(v.begin(), v.end()); |
list(const list& other) |
拷贝构造 | std::list<int> l1 = {1,2}; std::list<int> l2(l1); |
list(list&& other) |
移动构造(C++11) | std::list<int> l1 = {1,2}; std::list<int> l2(std::move(l1)); // l1为空 |
~list() |
析构:销毁所有元素并释放节点内存 | - |
4.2 迭代器与遍历
| 接口 | 功能 |
|---|---|
begin() / end() |
普通迭代器(首元素 / 尾后) |
rbegin() / rend() |
反向迭代器(尾元素 / 首前) |
cbegin() / cend() |
const 迭代器(只读) |
遍历示例:
std::list<int> l = {1,2,3,4,5};
// 1. 范围for循环(推荐)
for (int val : l) {
std::cout << val << " "; // 输出:1 2 3 4 5
}
// 2. 普通迭代器
for (auto it = l.begin(); it != l.end(); ++it) {
std::cout << *it << " ";
}
// 3. 反向迭代器
for (auto it = l.rbegin(); it != l.rend(); ++it) {
std::cout << *it << " "; // 输出:5 4 3 2 1
}
4.3 容量与状态查询
| 接口 | 功能 | 时间复杂度 |
|---|---|---|
empty() |
判断链表是否为空 | O(1) |
size() |
返回元素个数(C++11 后 O (1)) | O(1) |
max_size() |
返回理论最大容量(系统内存限制) | O(1) |
4.4 元素访问
std::list 不支持随机访问,仅提供首尾元素的直接访问:
| 接口 | 功能 | 示例 |
|---|---|---|
front() |
返回首元素的引用(非 const) | l.front() = 10; // 修改首元素为10 |
back() |
返回尾元素的引用(非 const) | std::cout << l.back(); // 输出尾元素 |
const_front() / const_back() |
返回 const 引用(只读) | - |
4.5 核心修改操作
4.5.1 首尾操作(O (1))
| 接口 | 功能 | 示例 |
|---|---|---|
push_front(const T& val) |
头部插入元素 | l.push_front(0); // 链表变为 {0,1,2,3,4,5} |
pop_front() |
删除头部元素(需非空) | l.pop_front(); // 链表变为 {1,2,3,4,5} |
push_back(const T& val) |
尾部插入元素 | l.push_back(6); // 链表变为 {1,2,3,4,5,6} |
pop_back() |
删除尾部元素(需非空) | l.pop_back(); // 链表变为 {1,2,3,4,5} |
4.5.2 任意位置插入 / 删除(O (1),已知迭代器)
| 接口 | 功能 | 示例 |
|---|---|---|
insert(iterator pos, const T& val) |
在 pos 前插入 val,返回新元素迭代器 | auto it = l.begin(); ++it; l.insert(it, 10); // 在1后插入10,链表变为 {1,10,2,3,4,5} |
insert(iterator pos, size_t n, const T& val) |
在 pos 前插入 n 个 val | l.insert(l.end(), 2, 6); // 尾部插入2个6,链表变为 {1,10,2,3,4,5,6,6} |
erase(iterator pos) |
删除 pos 指向的元素,返回下一个元素迭代器 | auto it = l.begin(); ++it; it = l.erase(it); // 删除10,it指向2,链表变为 {1,2,3,4,5,6,6} |
erase(iterator first, iterator last) |
删除 [first, last) 范围元素 | auto first = l.begin(); ++first; auto last = l.end(); l.erase(first, last); // 删除2及之后元素,链表变为 {1} |
clear() |
删除所有元素,链表为空 | l.clear(); |
4.5.3 链表特有操作(核心优势)
这些操作是 std::list 区别于其他容器的关键,充分利用了链表的指针特性,效率极高:
(1)splice:元素转移(O (1) 或 O (n))
将一个链表的元素 "剪切" 到另一个链表,无需复制元素,仅调整指针。
// 重载1:转移整个链表
void splice(iterator pos, list& other);
// 重载2:转移单个元素
void splice(iterator pos, list& other, iterator it);
// 重载3:转移范围元素
void splice(iterator pos, list& other, iterator first, iterator last);示例:
std::list<int> l1 = {1,2,3};
std::list<int> l2 = {4,5,6};
// 转移l2的所有元素到l1尾部
l1.splice(l1.end(), l2); // l1: {1,2,3,4,5,6}, l2: 空
// 转移l1中第2个元素(2)到l1头部
auto it = l1.begin(); ++it;
l1.splice(l1.begin(), l1, it); // l1: {2,1,3,4,5,6}
// 转移l1中[3,5)范围元素到尾部
auto first = l1.begin(); std::advance(first, 2); // 指向3
auto last = l1.begin(); std::advance(last, 5); // 指向6
l1.splice(l1.end(), l1, first, last); // l1: {2,1,6,3,4,5}(2)merge:合并两个有序链表(O (n+m))
合并两个已排序的链表,合并后仍保持有序,源链表变为空。
std::list<int> l1 = {1,3,5};
std::list<int> l2 = {2,4,6};
l1.merge(l2); // l1: {1,2,3,4,5,6}, l2: 空(3)reverse:反转链表(O (n))
std::list<int> l = {1,2,3};
l.reverse(); // l: {3,2,1}(4)unique:移除连续重复元素(O (n))
仅保留连续重复元素的第一个,需确保链表已排序(否则仅移除相邻重复元素)。
std::list<int> l = {1,1,2,2,3};
l.unique(); // l: {1,2,3}(5)sort:链表排序(O (n log n))
std::sort 要求随机访问迭代器,因此 std::list 自带 sort 成员函数(基于归并排序,稳定排序)。
std::list<int> l = {3,1,4,2,5};
l.sort(); // l: {1,2,3,4,5}五、std::list 与 std::vector 全面对比
| 特性 | std::list | std::vector |
|---|---|---|
| 内存布局 | 非连续(双向链表) | 连续数组 |
| 随机访问 | 不支持(O (n)) | 支持(O (1)) |
| 插入 / 删除(中间位置) | O (1)(已知迭代器) | O (n)(需移动元素) |
| 插入 / 删除(首尾) | O(1) | 尾部 O (1)(无扩容),头部 O (n) |
| 扩容 | 无需扩容(动态分配节点) | 可能扩容(复制旧元素,O (n)) |
| 迭代器类型 | 双向迭代器 | 随机访问迭代器 |
| 迭代器有效性 | 插入后均有效,删除后仅被删节点迭代器失效 | 插入可能失效,删除后后续迭代器失效 |
| 内存开销 | 高(每个节点 2 个指针) | 低(仅存储数据) |
| 缓存友好性 | 差(节点分散) | 好(连续内存,缓存命中率高) |
| 适用场景 | 频繁中间插入 / 删除、元素数量不确定 | 频繁随机访问、元素数量稳定 |
六、实战场景:什么时候用 std::list?
6.1 适合的场景
- 实现队列 / 栈 :链表的首尾操作 O (1),比
std::vector更适合(vector头部操作 O (n)); - 频繁在中间位置插入 / 删除:如日志系统(频繁插入日志)、任务调度队列(频繁添加 / 移除任务);
- 元素数量不确定:无需提前预留内存,动态分配节点更灵活;
- 自定义数据结构:如链表、双向队列等基础数据结构的实现。
6.2 不适合的场景
- 需要随机访问元素 :如根据下标查找元素(优先用
std::vector或std::deque); - 元素体积小且访问频繁 :
std::vector的缓存友好性更优,性能更胜一筹; - 内存资源紧张 :
std::list的额外指针开销可能成为瓶颈。
七、进阶注意事项
7.1 迭代器使用禁忌
- 不要用
it + n或it -= 2等随机访问操作(双向迭代器不支持),需用std::advance(it, n)移动迭代器; - 删除元素后,避免使用指向被删除节点的迭代器(已失效),应使用
erase返回的下一个有效迭代器。
7.2 自定义类型的要求
- 若存储自定义类型,需确保该类型有默认构造函数(用于节点初始化)、拷贝构造函数 / 赋值运算符(用于元素拷贝);
- 若自定义类型有动态资源(如
char*),需手动实现深拷贝,避免浅拷贝导致的资源泄漏。
7.3 性能优化技巧
- 尽量使用
emplace_front()/emplace_back()/emplace()(C++11)替代push_front()/push_back()/insert(),直接在节点中构造元素,避免临时对象拷贝; - 批量插入元素时,优先用
insert的迭代器范围重载(O (n)),比循环调用push_back()更高效; - 若需频繁遍历,可考虑先用
std::vector暂存数据(缓存友好),遍历完成后再转存回std::list。
八、总结
std::list 是 C++ 标准库中双向链表的经典实现,其设计核心是 "通过指针连接节点,实现高效的插入与删除"。它不是 std::vector 的替代品,而是互补品 ------ 两者分别针对 "修改密集型" 和 "访问密集型" 场景优化。
理解 std::list 的关键在于:
- 底层是双向链表,非连续内存存储;
- 插入 / 删除高效,但不支持随机访问;
- 迭代器有效性规则友好,适合频繁修改的场景。
在实际开发中,选择 std::list 还是 std::vector,本质是权衡 "访问效率" 和 "修改效率"。掌握两者的差异,才能在不同场景中做出最优选择 ------ 这也是 STL 容器设计的精髓所在。
示例代码:
那么我再给大家示例代码,帮助大家进一步理解:
cpp
#include <iostream>
#include <list>
#include <vector>
#include <algorithm>
#include <cmath>
using namespace std;
void testlistconstructor()
{
//注意:list不是指单向链表,而是指双向带头链表
//那么其实list也是和vector的初始化差不多
//都是需要显式实例化的
//即由我们告诉编译器,我们要往链表里面传什么类型的数据
list<int> lt1;
//要注意,list和vector一样,我们想要输入和输出数据
//也都需要我们自己通过循环手动实现
list<int> lt2(5, 2);//和vector的构造函数差不多
//创建有5个节点的链表,同时节点里面的数据都指定为1
//要是不传入第二个参数,那么就是默认为0或者其他类型的默认构造函数所生成的
list<double> lt3(5);
//注意:循环list,我们就不能再用下标访问的方式了
//因为链表是一个一个节点,而不是像数组一样的连续的存储
//所以呢,list中也没有提供对[]的运算符重载函数
//所以我们就要用迭代器或者for auto循环
list<int>::iterator it2 = lt2.begin();
cout << "lt2:" << endl;
while (it2 != lt2.end())
{
cout << *it2 << " ";
++it2;
}
cout << endl;
for (auto n : lt2)
{
cout << n << " ";
}
cout << endl;
cout << endl;
cout << "lt3:" << endl;
list<double>::iterator it3 = lt3.begin();
while (it3 != lt3.end())
{
cout << *it3 << " ";
++it3;
}
cout << endl;
for (auto n : lt3)
{
cout << n << " ";
}
cout << endl;
list<int> lt4;
lt4 = lt2;
cout << endl;
cout << "lt4(赋值运算符重载函数):" << endl;
for (auto n : lt4)
{
cout << n << " ";
}
cout << endl;
list<int> lt5(lt2.begin(),lt2.end());
cout << endl;
cout << "lt5(迭代器构造函数):" << endl;
for (auto n : lt5)
{
cout << n << " ";
}
//其实总结一下,构造函数的使用是和vector如出一辙的
//但是循环遍历list就不支持下标[]访问了
}
void testlistModifiers()
{
//接下来就是要了解一下
//list中的尾插尾删,头插头删
//insert、erase等等一些比较常用的函数
//而同样的,list中这些函数的操作也都是传入迭代器的
//而不是整型下标
//但是关于list的迭代器
//就和vector的迭代器的使用不是一模一样了
//是有一个比较大的区别的
//就是在vector中的迭代器中,我们是可以直接对迭代器+一个数的
//比如
vector<int> v1(5, 3);
vector<int>::iterator vit = v1.begin();
//那么我们想要指定到v1的某一个位置时,我们是可以直接对vit进行+一个数来指定位置
v1.insert(vit + 2, 4);//可以看到,可以直接对vit迭代器+2
cout << "v1.insert:" << endl;
for (auto n : v1)
{
cout << n << " ";
}
cout << endl;
cout << endl;
//但是在list的迭代器中,就不能像上面一样直接对迭代器进行+一个数来移动迭代器的指向
//因为list迭代器是单向迭代器,它只支持++和--
//是不支持直接+一个数的,这是一个很重要也很大的区别,一定要注意
//那么要怎么让list的迭代器移动多个位置呢?
//其实就是要借助循环,去让迭代器++或者--n次,就能移动到了
//比如下面这样子:
list<int> lt1(5, 6);
list<int>::iterator lit1 = lt1.begin();
for (auto n : lt1)
{
cout << n << " ";
}
cout << endl;
//比如想要实现像上面的对迭代器+2
//即让迭代器移动到指向第三个节点去
//(从1开始计数的话就是第三个节点,从0开始计数的话就是第二个节点)
//但是由于链表不像数组,它就是从1开始计数的
//所以我们指定为2,其实就是第二个节点,而不是像数组的第三个数据
//(即从第一个节点开始往后走两步)
for (int i = 0; i < 1; i++)
{
++lit1;
}
//出了循环之后,就达到了我们所指定的位置
lt1.insert(lit1,2);
cout << "在原本的第二个节点之前插入数据(即在第2个节点插入数据):" << endl;
for (auto n : lt1)
{
cout << n << " ";
}
cout << endl;
//上面说到的是非常重要的知识点。
//在list里面,就没有reserve函数了,需要注意
//因为本质上就是需要一个节点,就创建一个节点,不用去提前预留空间
//这也是链表比顺序表好的一个点
list<int> lt2;
for (int i = 1; i <= 5; ++i)
{
lt2.push_back(i);//直接尾插就完事了
}
cout << endl;
cout << "lt2:" << endl;
for (auto n : lt2)
{
cout << n <<"->";
}
cout << "nullptr";
cout << endl;
cout << endl;
//尾删
lt2.pop_back();//不用传入参数,尾删哪里需要参数
cout << "lt2 pop_back:" << endl;
for (auto n : lt2)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
cout << endl;
//头插
lt2.push_front(0);//不用传入参数,尾删哪里需要参数
cout << "lt2 pushfront:" << endl;
for (auto n : lt2)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
cout << endl;
//头删
lt2.pop_front();//不用传入参数,尾删哪里需要参数
cout << "lt2 pop_front:" << endl;
for (auto n : lt2)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
cout << endl;
//删除第二个节点的数据
list<int>::iterator lit2 = lt2.begin();
for (int i = 0; i < 1; i++)
{
++lit2;
}
//出了循环之后,就达到了我们所指定的位置
lt2.erase(lit2);
cout << "删除原本的第二个节点的数据:" << endl;
for (auto n : lt2)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
cout << endl;
//最后clear一下
lt2.clear();
cout << "clear:" << endl;
for (auto n : lt2)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
}
void testlistOperations()
{
//那么这一块的就是list里面比较独特的一些函数了
list<int> lt1;
for (int i = 1; i <= 8; ++i)
{
lt1.push_back(i);//直接尾插就完事了
}
cout << "lt1:" << endl;
for (auto n : lt1)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
cout << endl;
//list里面提供的一个reserve函数
lt1.reverse();
cout << "lt1 reverse:" << endl;
for (auto n : lt1)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
cout << endl;
//remove函数,即将指定的数据给移除掉
//不是像erase一样去删除指定位置的数据
//所以是传入要删除的数据,而不是迭代器
lt1.remove(2);
cout << "lt1 remove2:" << endl;
for (auto n : lt1)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
cout << endl;
list<int> lt2;
lt2.push_back(5);
lt2.push_back(8);
lt2.push_back(45);
lt2.push_back(4);
lt2.push_back(9);
lt2.push_back(0);
lt2.push_back(1);
lt2.push_back(5);
lt2.push_back(4);
lt2.push_back(98);
lt2.push_back(100);
cout << "lt2:" << endl;
for (auto n : lt2)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
cout << endl;
//因为std里面的sort函数不支持传入list的迭代器
//所以在list中,专门提供了一个sort排序函数
lt2.sort();
cout << "lt2 sort:" << endl;
for (auto n : lt2)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
cout << endl;
//unique函数,即去重函数
//即将链表中有相同的元素都去掉,只留下一个
//但是要求是在已经排序后的list才行
lt2.unique();
cout << "lt2 unique(去重):" << endl;
for (auto n : lt2)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
cout << endl;
//merge函数,即将一个list合并进另一个list
//但是也是要求两个list都是已经排好序的
//而且合并之后,也是自动有序的
//但是比较鸡贼的是
//在merge之后,被合并到另一个list的list
//是会变为空的
lt1.sort();
lt1.merge(lt2);
cout << "lt1.merge(lt2),把lt2合并到lt1中:" << endl;
for (auto n : lt1)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
//lt1不为空,kt2为空
cout << "lt2:nullptr";
cout << endl;
cout << endl;
//splice函数,即剪切函数
//一个挺好用的函数
//就是把一个list剪切了
//或者是一个list里面的我们所指定的位置的数据给剪切了
//注意:被剪切的那一个,就没了
//然后放在另一个list里面我们所指定的位置(迭代器)
list<int> lt3;
for (int i = 10; i <= 15; ++i)
{
lt3.push_back(i);//直接尾插就完事了
}
auto lt3it = lt3.begin();
cout << "lt3:" << endl;
for (auto n : lt3)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
list<int> lt4;
lt4.push_back(85);
lt4.push_back(24);
lt4.push_back(56);
lt4.push_back(45);
lt4.push_back(55);
cout << "lt4:" << endl;
for (auto n : lt4)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
cout << endl;
lt3.splice(lt3it, lt4);
cout << "将lt4插入到lt3原本的第一个节点前面" << endl;
//splice之后,lt4里面就没有数据了
for (auto n : lt3)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
cout << "lt4:nullptr" << endl;
cout << endl;
list<int> lt5;
for (int i = 10; i <= 15; ++i)
{
lt5.push_back(i);//直接尾插就完事了
}
auto lt5it = lt5.begin();
cout << "lt5:" << endl;
for (auto n : lt5)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
//我们可以将lt5中的某一个迭代器指向的数据给剪切到lt5中另一个迭代器指向的位置
auto lt5it1 = lt5.begin();
for (int i = 1; i < 3; ++i)
{
++lt5it1;
}
cout << endl;
lt5.splice(lt5it, lt5, lt5it1);
//第一个参数是要插入的位置迭代器
//第二个参数是被剪切的list
//第三个参数是被剪切中的list的要被剪切的数据的位置迭代器
cout << "将lt5中原本的第3个节点的数据剪切到原本的第2个节点的数据之前:" << endl;
for (auto n : lt5)
{
cout << n << "->";
}
cout << "nullptr";
cout << endl;
}
//测试一下list提供的排序的效率
//和std里面的sort函数比较
void test_op1()
{
srand(time(0));
const int N = 1000000;
list<int> lt1;
vector<int> v;
for (int i = 0; i < N; ++i)
{
auto e = rand() + i;
lt1.push_back(e);
v.push_back(e);
}
int begin1 = clock();
// 排序
sort(v.begin(), v.end());
int end1 = clock();
int begin2 = clock();
lt1.sort();
int end2 = clock();
printf("vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}
//先将要排序的list的数据都丢进vector里面
//然后对vector进行std里面的sort
//排好序后再转移回list里面
void test_op2()
{
srand(time(0));
const int N = 1000000;
list<int> lt1;
list<int> lt2;
for (int i = 0; i < N; ++i)
{
auto e = rand() + i;
lt1.push_back(e);
lt2.push_back(e);
}
int begin1 = clock();
// 拷贝vector
//vector的迭代器构造函数
vector<int> v(lt2.begin(), lt2.end());
// 排序
sort(v.begin(), v.end());
// 拷贝回lt2
lt2.assign(v.begin(), v.end());
int end1 = clock();
int begin2 = clock();
lt1.sort();
int end2 = clock();
printf("list copy vector sort copy list sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}
int main()
{
testlistconstructor();
testlistModifiers();
testlistOperations();
test_op1();
test_op2();
return 0;
}OK,到这里,就差不多OK了,而一样的,我们接下来几篇博客,就要开始着手模拟实现list1了,在这里提前预告一下,list的模拟实现,可是要比vector和string的模拟实现要难哦,大家做好心理准备。
结语:于链表的指针交错中,读懂 C++ 的设计智慧
当你敲完testlistOperations()函数的最后一个分号,看着控制台中链表元素有序地插入、删除、合并、排序,想必对std::list已经有了全新的认知。从vector的连续内存跳跃到list的非连续节点,这不仅是容器类型的切换,更是对 C++"场景化设计" 思想的深度体悟。
回顾这篇博客的内容,我们从 "为什么需要list" 的灵魂拷问出发,一步步揭开了它的底层面纱:双向链表的节点结构、哨兵节点的巧妙设计、双向迭代器的特性约束,再到insert/erase的 O (1) 高效操作、splice/merge等特有接口的实战用法。每一个知识点的背后,都藏着 STL 设计者对 "效率与灵活" 的极致追求 ------ 用额外的指针开销换取修改操作的高效,用非连续存储摆脱扩容的束缚,用哨兵节点简化边界处理,这正是list区别于vector的核心竞争力。
或许在学习过程中,你曾为 "不能用下标访问" 而困惑,为 "迭代器不能直接加减" 而烦恼,为 "splice和merge的使用场景" 而纠结。但当你亲手写出test_op2()中 "list 转 vector 排序再转回 list" 的对比代码,看着两种排序方式的时间差异,便会豁然开朗:C++ 中没有 "万能容器",只有 "适配场景的容器"。list的每一个 "不完美",都是为了在 "频繁修改" 的场景中做到极致完美。
你一定记得list的迭代器有效性规则 ------ 插入元素后所有迭代器仍有效,删除元素后仅被删节点的迭代器失效。这与vector扩容后迭代器全部失效形成鲜明对比,背后是链表 "节点独立存储" 的结构优势。这种设计让list在频繁插入删除的场景中(如日志系统、任务调度队列)具备天然优势,无需像vector那样频繁重新获取迭代器,大大降低了代码复杂度。
而list特有的spilce函数,更是将链表的 "指针操作优势" 发挥到了极致。它无需复制元素,仅通过调整节点的prev和next指针,就能实现元素的快速转移,这种 "剪切 - 粘贴" 的高效操作,是vector永远无法企及的。当你在项目中需要合并两个链表、调整元素顺序时,spilce总能以 O (1) 的时间复杂度给你惊喜,这正是理解底层原理后才能解锁的 "高效技巧"。
在实战示例部分,我们通过testlistconstructor、testlistModifiers、testlistOperations三个函数,覆盖了list从构造到修改、从特有操作到性能对比的全场景用法。尤其是test_op1和test_op2的性能测试,更是直观地告诉我们:没有绝对高效的容器,只有适合场景的选择。当数据量庞大且需要排序时,list自带的sort函数虽然便捷,但效率不如 "转 vector 排序再转回 list"------ 这并非list的缺陷,而是不同数据结构的特性使然。理解这一点,才能真正做到 "因地制宜" 地选择容器。
学习list的过程,也是对 C++ 内存管理和迭代器设计的深度复盘。你会发现,list的节点创建依赖于分配器的allocate和deallocate,元素构造依赖于 placement-new,这与vector的连续内存分配形成鲜明对比;list的双向迭代器仅支持++和--操作,这是由链表的非连续存储特性决定的。这些细节看似琐碎,却共同构成了 C++ 容器设计的底层逻辑 ------容器的特性永远由其底层数据结构决定。
或许你会觉得list的使用门槛比vector高,需要关注迭代器移动、特有接口的使用场景等细节。但正是这些细节,让你从 "只会调用 API 的使用者" 成长为 "理解设计本质的思考者"。当你能清晰地说出list和vector的内存布局差异、迭代器有效性区别、适用场景边界时,你对 C++ 的理解已经迈上了一个新的台阶。
接下来,我们将进入list模拟实现的环节。正如博客末尾预告的那样,list的模拟实现难度远超vector和string------ 它需要我们手动设计节点结构、实现双向迭代器、处理哨兵节点的边界情况,还要精准复刻insert/erase/splice等接口的底层逻辑。这无疑是一场挑战,但也是一次绝佳的成长机会。通过模拟实现,你将亲手搭建双向链表的骨架,感受指针操作的精妙,彻底吃透list的底层原理,这种 "从 0 到 1" 的构建过程,远比单纯学习接口用法更有价值。
在未来的学习和开发中,希望你能带着今天的收获,灵活运用list和vector这两个 "互补品":当需要频繁随机访问、元素数量稳定时,毫不犹豫地选择vector;当需要频繁中间插入删除、元素数量不确定时,果断使用list。这种 "根据场景选择工具" 的思维,是优秀程序员的核心素养之一。
最后,我想对你说:学习 C++ 容器的道路,就像在探索一座庞大的城堡,每一个容器都是一个独特的房间,里面藏着设计的智慧和高效的技巧。list只是这座城堡中的一个房间,接下来还有deque、map、set等更多精彩等待你去发现。或许过程中会遇到困惑和挫折,但请相信,每一次深入底层的探索,每一次亲手实践的代码,都是在为你的编程功底添砖加瓦。
请保持这份对底层原理的好奇和探索欲,在 C++ 的世界里继续深耕。当你能从容应对各种容器的选择与使用,当你能亲手模拟实现复杂的数据结构时,你会发现,曾经看似艰难的挑战,都已成为你成长路上最宝贵的财富。
下一篇,我们将正式开启list模拟实现的征程,一起攻克节点设计、迭代器实现、接口复刻等难题。准备好了吗?让我们继续在 C++ 的世界里,探索更多未知,收获更多成长!