1. 定位与原则
LawCounsel 是一个以 Django + PostgreSQL/pgvector + Redis + Celery + Vue 为基础的中文法律检索分析(RAG)平台,目标是用最少的成本实现企业级感觉的 AI+准 SaaS。
核心设计哲学
-
数据极简主义 :默认整库维持 1GB 以下,只保留必要数据
-
开源优先:优先复用开源中文法律语料(如 CAIL2018、LeCaRDv2)
-
模型可插拔:支持可切换的向量与分析模型
-
低成本本地部署 :在低成本的本地环境下对外提供可用、可验证、能临时对外展示的检索系统
2. 架构剖析
分层架构图
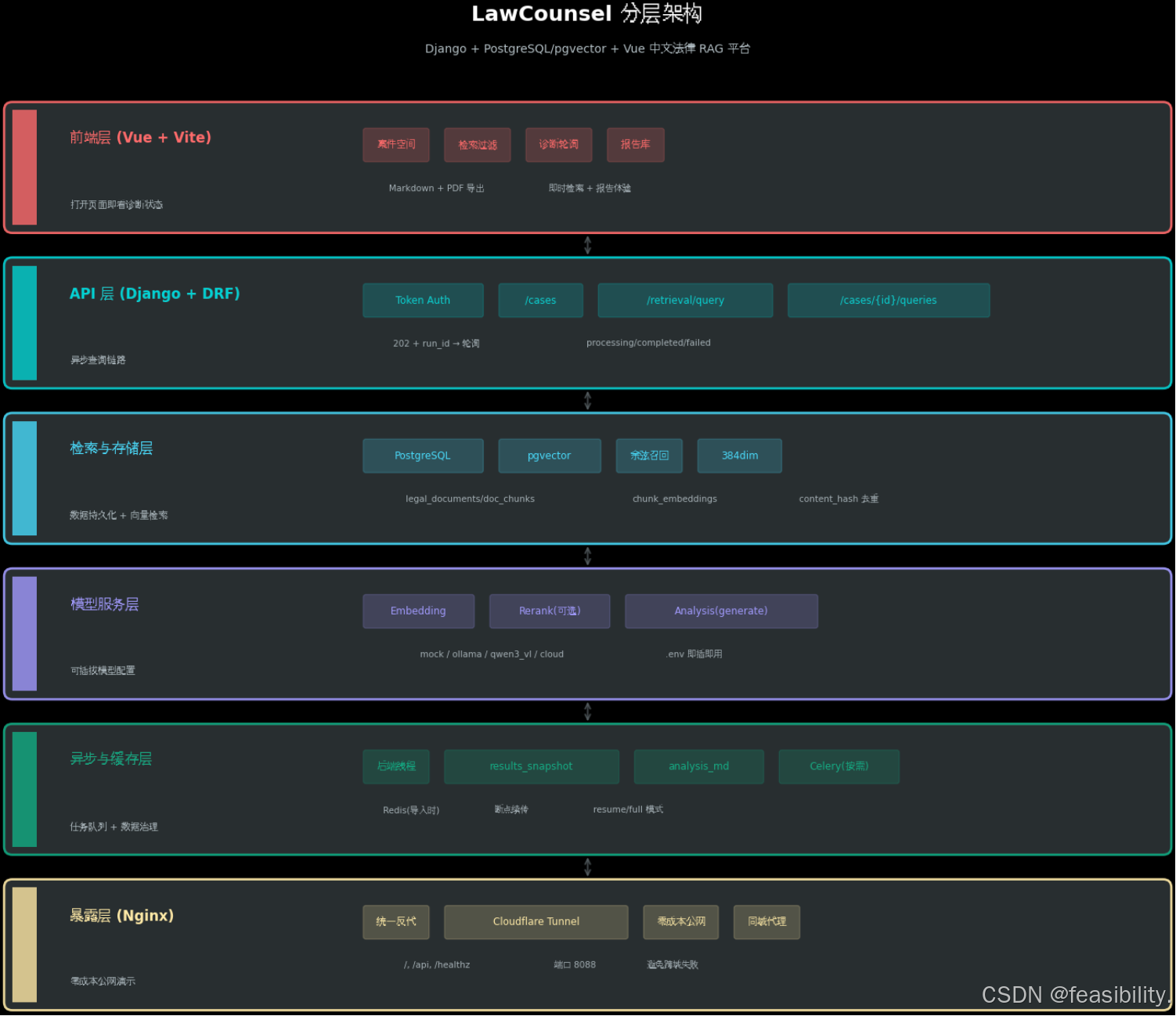
关键设计决策
| 组件 | 策略 | 说明 |
|---|---|---|
| 异步查询 | 202 Accepted + 轮询 |
POST /cases/{id}/queries 返回 run_id,前端轮询 GET /cases/{id}/queries/{run_id} 获取 processing/completed/failed 状态 |
| Celery 使用 | 按需启动 | 仅在数据导入时启动,检索/分析流程不依赖 Celery |
| 数据去重 | content_hash + near_hash |
导入时自动内容级去重(SHA-256 + near_hash),考虑到了法律文本的细微差异,支持断点续传 |
| 向量维度 | 384 dim | 平衡精度与存储,可通过环境变量切换 Provider,注意生成向量的模型需与检索模型保持一致 |
3. 数据全链路
数据处理 Pipeline
# 1. 下载源
scripts/download_legal_data.sh
# ↓ 抓取 CAIL/LeCaRDv2 等中文法律语料
# ↓ 合并到 data/raw/
# 2. 标准化
uv run python scripts/normalize_legal_jsonl.py
# ↓ 切段: 400-700 字,重叠 80-120
# ↓ 保留字段: doc_id/title/text/source/lang/publish_date/case_type
# ↓ 输出: data/processed/legal_docs.jsonl
# 3. 断点 + 去重
# ↓ 每行处理后更新 checkpoint
# ↓ content_hash + near_hash 跳过重复
# ↓ 支持 resume/full 模式
# 4. 向量生成
# ↓ Provider: mock (默认) / Qwen3-VL-Embedding-2B / 云端 API
# ↓ 写入 chunk_embeddings 表
# ↓ 每 chunk 一条 384 dim 向量
# 5. 部署准则
# ↓ 数据库体量 ≤ 1GB
# ↓ 删除原始大文件,只保存处理后 JSONL数据 Schema 核心字段
# Chunk 表结构示意
{
"doc_id": "uuid", # 文档唯一标识
"title": "str", # 标题
"text": "str", # 文本内容 (400-700字)
"source": "str", # 来源 (CAIL/LeCaRDv2)
"lang": "zh", # 语言
"case_type": "str", # 案件类型
"embedding": [384 floats], # 向量
"content_hash": "str", # 内容哈希
"near_hash": "str" # 近似哈希 (去重)
}4. 异步检索与分析体验
请求链路时序
前端 POST /cases/{id}/queries
│
▼
后端 202 Accepted → 返回 run_id
│
▼
后端线程执行:
├─ pgvector Top-K 召回 (余弦相似度)
├─ 可选 rerank (Qwen3-VL-ReRanker-2B)
├─ 写入 results_snapshot (快存)
└─ 调 analysis 生成 Markdown
│
▼
analysis_md 回写数据库
│
▼
前端 GET /cases/{id}/queries/{run_id} 轮询
├─ processing: "analysis_md": "## 分析进行中..."
├─ completed: 真实分析内容
└─ failed: 超时 (15分钟) 或错误诊断链路设计
前端展示 start/posting/posted/accepted 阶段诊断,帮助定位:
-
模型超时
-
网络卡住
-
旧包未刷新
报告导出
| 格式 | 技术方案 | 特性 |
|---|---|---|
| Markdown | 前端渲染 + 右侧草稿 | 即时编辑、预览 |
| STSong-Light 字体 | 按字符宽度换行,避免中文乱码或截断,法务可直接打印 |
模型适配配置
通过 .env 灵活切换:
EMBEDDING_PROVIDER=mock|qwen3_vl_script|cloud
RERANK_PROVIDER=none|qwen3_vl_reranker
ANALYSIS_PROVIDER=ollama|qwen3_vl|cloud_api5. 部署与对外演示
快速启动
python
# 1. 后端环境准备
cd backend
uv python install 3.11
uv venv --python 3.11
source .venv/bin/activate
uv sync
uv run python manage.py migrate说明
uv run python manage.py migrate 是 Django 的标准迁移命令,它会:
1)根据 backend/apps/*/migrations/ 中的迁移脚本对 PostgreSQL 结构(表、索引、约束、默认值)进行同步。
2) 在项目首次部署时创建所有表和关联字段,确保 pgvector 扩展、案例/报告/查询等表存在。
3) 之后每次修改模型(添加字段、换关系、增加索引)或引入新的 app,都会生成新的迁移脚本,执行 migrate 会"落盘"这些更改,保持数据库 schema 与代码一致。
数据(比如文档、chunk、报告)不靠 migrate 更新,migrate 只负责结构;如果数据量变化或追加新的 JSONL、重建向量等,只需要重新跑数据导入脚本,或用 scripts/data_import_modes.sh 控制。除非确实变更了模型定义,否则不必重复跑 migrate。
python
# 2. 启动服务
# 后端
uv run python manage.py runserver 0.0.0.0:8000
# 前端 (先 build 再 preview,避免旧 dist)
bash scripts/run_frontend_preview.sh
# 可选 Nginx 反代 (统一入口 http://127.0.0.1:8088)
bash scripts/start_nginx_proxy.shDjango runserver 命令详解
python
uv run python manage.py runserver 0.0.0.0:8000
# ↓ ↓ ↓ ↓
# uv工具 Python Django命令 绑定地址:端口1)runserver 0.0.0.0:8000 是 Django 开发环境专用命令,支持外部设备访问本地服务;
2)该命令仅用于调试,生产环境必须使用 Gunicorn/uWSGI+Nginx 部署;
3)0.0.0.0 表示监听所有网络接口,区别于仅本机访问的 127.0.0.1。
核心作用
- 启动 HTTP 服务器:在本地运行 Django 应用,监听传入的 HTTP 请求
- 开发调试:热重载代码变更,方便开发时快速测试
- API 测试:让前端可以调用后端 API 接口
地址 0.0.0.0:8000 含义
| 参数 | 具体含义 |
|---|---|
0.0.0.0 |
监听所有网络接口(允许外部设备访问,如手机、同一局域网的其他电脑) |
:8000 |
端口号,访问地址为 http://localhost:8000 |
注:若仅写
runserver,默认监听127.0.0.1:8000(仅本机可访问)。
重要警告
⚠️ 该命令仅用于开发环境 ,严禁用于生产环境!runserver 是单线程、无性能优化、无安全加固的调试服务器,无法应对生产环境的并发和安全需求。
开发 / 生产环境命令对比
| 环境类型 | 核心命令 | 主要用途 |
|---|---|---|
| 开发环境 | runserver |
本地调试、代码快速迭代、功能验证 |
| 生产环境 | gunicorn + nginx |
高性能、高可用、安全加固、多进程处理请求 |
生产环境部署示例
# 生产环境启动命令(以Gunicorn为例)
gunicorn config.wsgi:application启动演示
后端演示
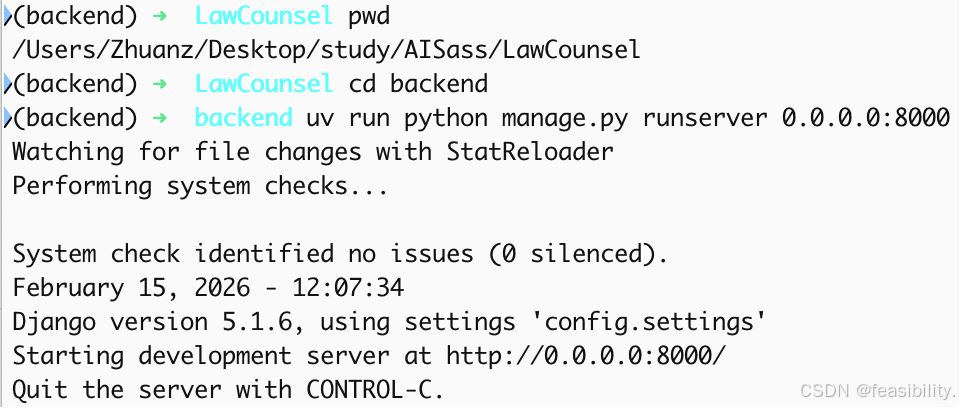
前端演示
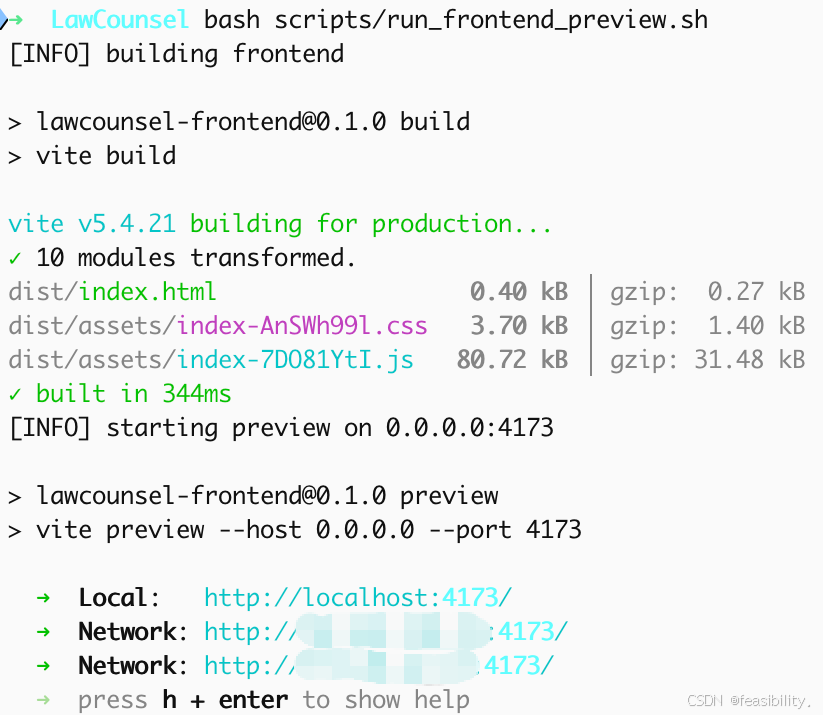
network是局域网ip
页面演示
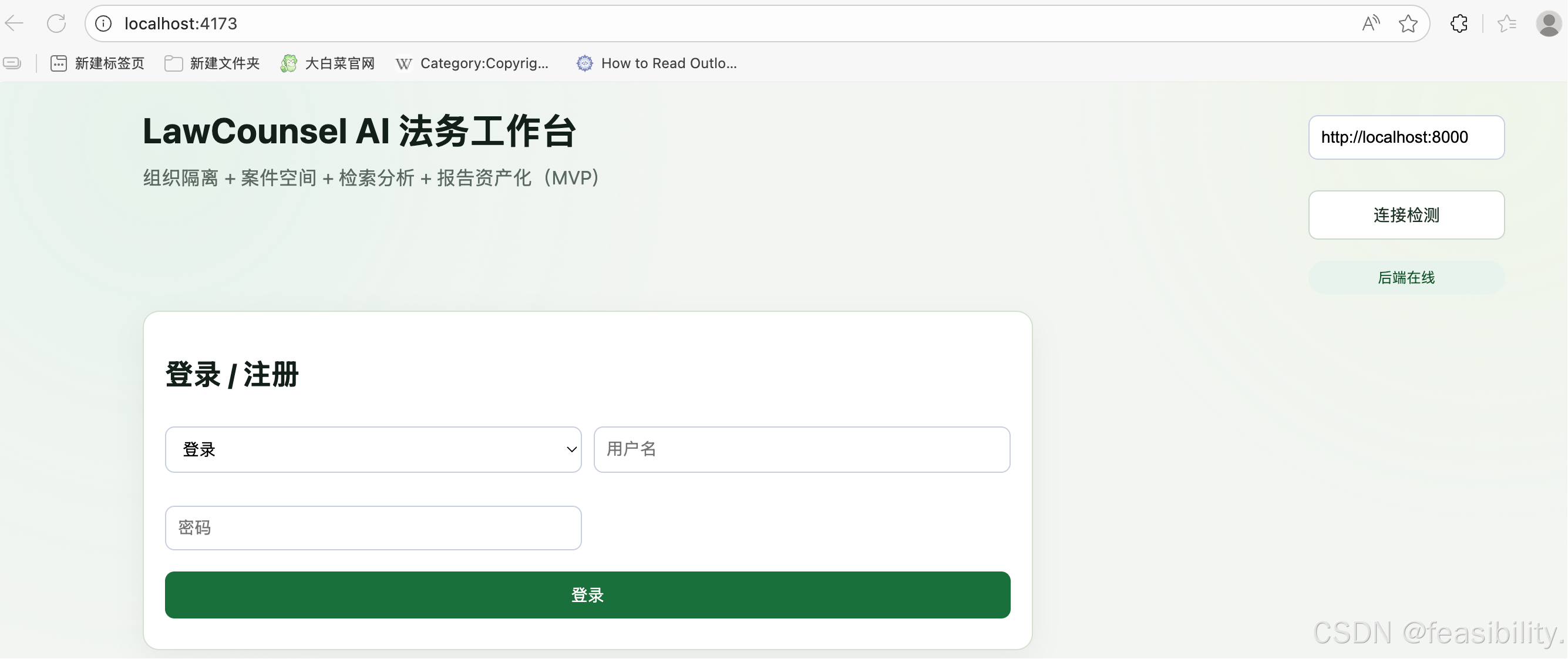
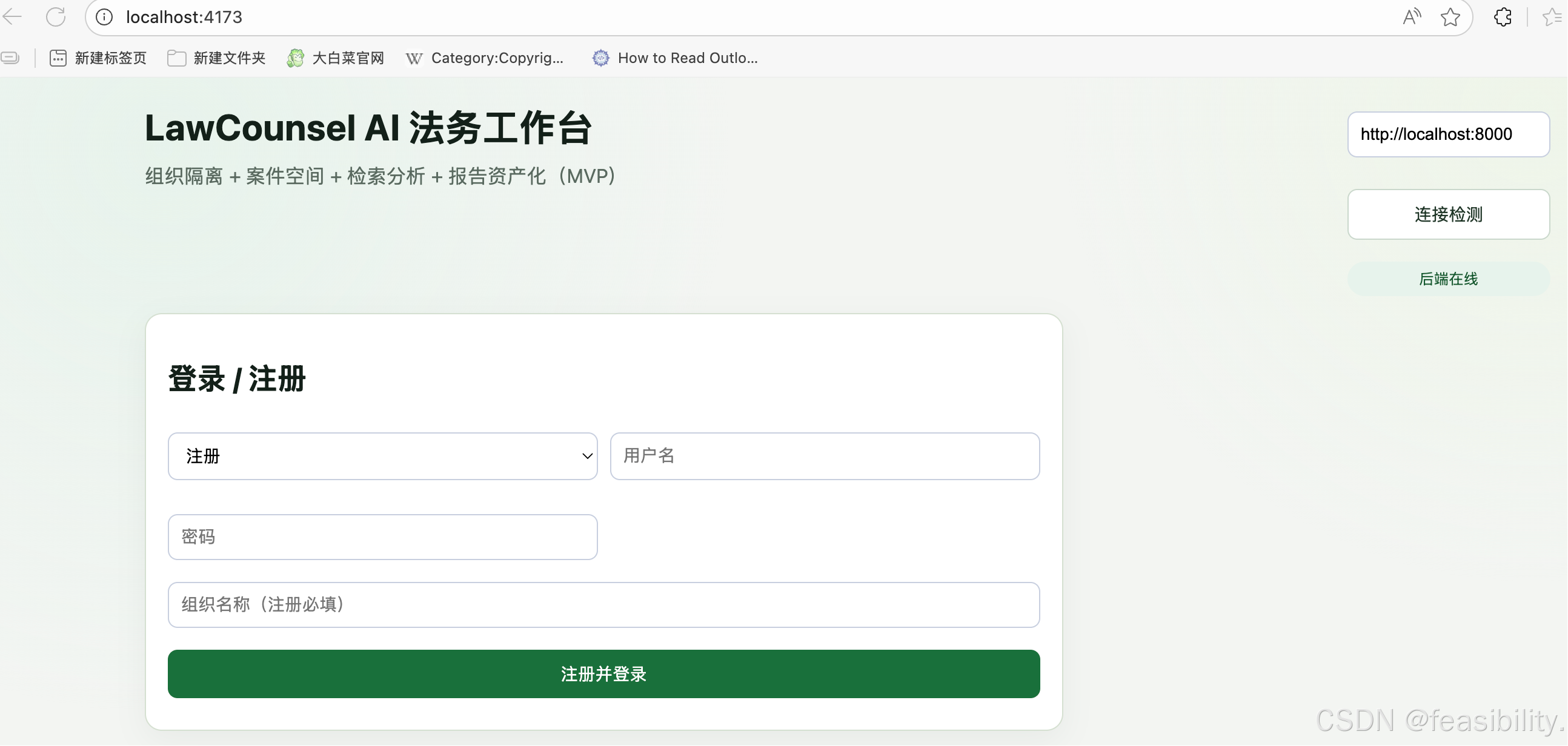
bash scripts/start_nginx_proxy.sh启动反向代理,bash scripts/stop_nginx_proxy.sh是关闭之前的反向代理
start_nginx_proxy.sh内容
bash
#!/usr/bin/env bash
set -euo pipefail
ROOT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")/.." && pwd)"
CONF_FILE="$ROOT_DIR/infra/nginx/lawcounsel.conf"
PID_FILE="/tmp/lawcounsel-nginx.pid"
if ! command -v nginx >/dev/null 2>&1; then
echo "[ERR] nginx not found."
echo "Install on macOS: brew install nginx"
exit 1
fi
echo "[INFO] testing nginx config"
nginx -t -c "$CONF_FILE"
echo "[INFO] starting nginx proxy on :8088"
exec nginx -c "$CONF_FILE" -g "pid $PID_FILE; daemon off;"这个脚本的核心作用是帮你安全、便捷式启动项目专属的 Nginx 代理服务,全程自动检查环境、验证配置,使用者不用懂复杂的 Nginx 命令,跟着看就能明白:
1)#!/usr/bin/env bash:固定开头,告诉系统用 bash 命令执行这个脚本,不用改;
2)set -euo pipefail:脚本的 "安全保护"------ 只要有一步出错就立刻停(比如配置写错),避免错下去,新手不用管,知道是防错的就行;
3)ROOT_DIR/CONF_FILE/PID_FILE:脚本自动找项目根目录、项目专用的 Nginx 配置文件,还指定了记录 Nginx 进程的文件(方便管理),不用手动找路径;
4)if ! command -v nginx...:自动检查你电脑装没装 Nginx,没装就报错提醒,还告诉 Mac 用户装的命令(brew install nginx);
5)nginx -t -c "$CONF_FILE":启动前先检查配置文件对不对(比如端口写错、语法错),有问题会提前告诉你,避免启动后出问题;
6)exec nginx ...:正式启动 Nginx------ 用项目专属配置,启动后监听 8088 端口提供代理服务,还让 Nginx 前台运行(方便看日志、管理),新手直接用就行。
简单说:只要装了 Nginx,直接运行这个脚本,它会自动做所有检查,然后启动项目的 Nginx 代理,不用手动敲复杂的 Nginx 命令,也不容易出错。
infra/nginx/lawcounsel.conf内容
bash
worker_processes 1;
events {
worker_connections 1024;
}
http {
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8088;
server_name _;
# Frontend
location / {
proxy_pass http://127.0.0.1:4173;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
# Backend API
location /api/ {
proxy_pass http://127.0.0.1:8000/api/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_connect_timeout 10s;
proxy_send_timeout 300s;
proxy_read_timeout 300s;
send_timeout 300s;
}
location = /healthz {
proxy_pass http://127.0.0.1:8000/healthz;
proxy_set_header Host $host;
}
}
}这个 Nginx 配置文件的核心作用是:让 Nginx 在 8088 端口当 "统一入口",把不同请求自动转发到前端(4173 端口)和后端(8000 端口)服务,日常使用者不用分别访问 4173/8000,只访问 8088 就行,全程不用改参数直接用:
1)worker_processes 1;:Nginx 启动 1 个工作进程处理请求,开发 / 测试场景完全够用,不用改;
2)events { worker_connections 1024; }:每个工作进程最多同时处理 1024 个连接,日常使用不会不够;
3)http {...}:是 Nginx 处理网页请求的核心配置块,里面的sendfile on是加速文件传输、keepalive_timeout 65是保持连接 65 秒(减少重复连服务器的开销),都是优化项,不用动;
4)server { listen 8088; server_name _; }:Nginx 监听 8088 端口(访问http://你的IP:8088就走这个配置),server_name _;表示不管用什么域名访问,都用这个规则;
5)location / {...}:处理所有根路径请求(比如访问http://IP:8088/),自动转发到前端服务的 4173 端口,里面的proxy_set_header是把你的真实 IP、请求协议等信息传给前端,保证前端能拿到正确的请求信息;
6)location /api/ {...}:处理所有/api/开头的请求(比如http://IP:8088/api/用户信息),转发到后端服务的 8000 端口,里面的 timeout 参数是延长连接超时时间(避免后端处理慢导致请求中断),同样传了你的真实信息给后端;
7)location = /healthz {...}:专门处理/healthz这个请求(一般用来检查服务是否活着),转发到后端 8000 端口的/healthz,用来检测后端服务是否正常运行。
简单说:你只要启动 Nginx,访问http://你的IP:8088就能打开前端页面,页面里调的/api/接口会自动转到后端 8000 端口,不用手动切换端口,新手直接用这个配置就行。
stop_nginx_proxy.sh脚本
bash
#!/usr/bin/env bash
set -euo pipefail
PID_FILE="/tmp/lawcounsel-nginx.pid"
if [ ! -f "$PID_FILE" ]; then
echo "[WARN] pid file not found: $PID_FILE"
exit 0
fi
PID="$(cat "$PID_FILE")"
if kill -0 "$PID" >/dev/null 2>&1; then
kill "$PID"
echo "[INFO] stopped nginx proxy pid=$PID"
else
echo "[WARN] process not running: pid=$PID"
fi这个脚本是用来安全停止之前启动的 Nginx 代理服务的,使用者不用手动找进程、输复杂命令,脚本会自动判断、操作,全程简单易懂:
1)#!/usr/bin/env bash:固定开头,告诉系统用 bash 执行这个脚本,不用改;
2)set -euo pipefail:脚本的 "防错保护",有一步出错就立刻停,避免误操作(比如杀错进程);
3)PID_FILE="/tmp/lawcounsel-nginx.pid":指定记录 Nginx 进程号的文件(和启动 Nginx 的脚本用的是同一个文件,保证能找到对应进程);
4)if ! -f "$PID_FILE" ; then...:先检查这个 PID 文件在不在,不在就提示 "没找到 PID 文件",然后正常退出(不报错);
5)PID="(cat "PID_FILE")":从 PID 文件里读出 Nginx 的进程号(相当于找到要停止的那个 Nginx 进程);
6)if kill -0 "$PID"...:先检查这个进程号对应的 Nginx 是不是真的在运行:
要是在运行,就执行kill "$PID"停止这个 Nginx 进程,还会提示 "已停止 Nginx,进程号是 xxx";要是没运行,就提示 "这个进程号的 Nginx 没在运行";
简单说:你只要运行这个脚本,它会自动找之前启动的 Nginx 进程,能停就停,找不到文件 / 进程就友好提示,不用手动输 kill 命令,也不用担心杀错其他程序。
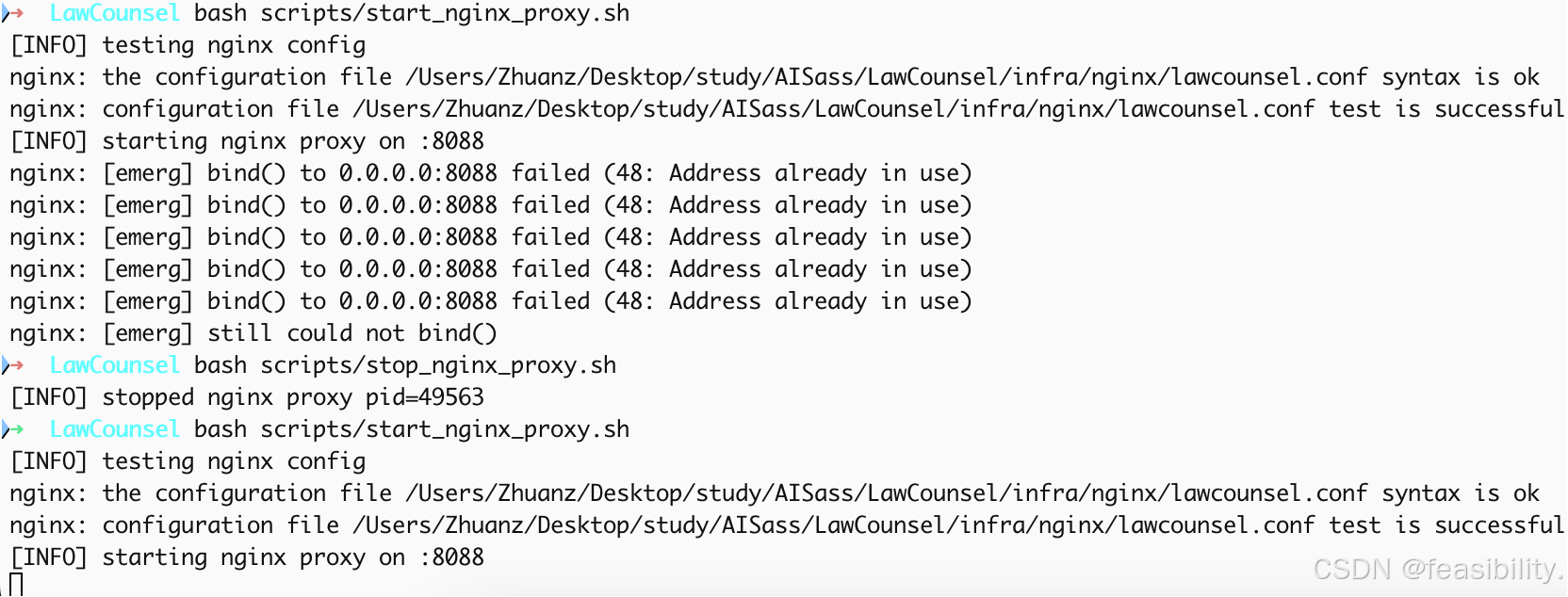
Cloudflare Tunnel 公网暴露
python
# 零成本临时公网演示 (已验证命令在 docs/DEPLOYMENT.md)
TUNNEL_URL=http://127.0.0.1:8088 bash scripts/start_cloudflare_tunnel.sh
# 生成链接示例:
# https://capable-trained-extract-plaintiff.trycloudflare.com
健康自检
python
curl -sS http://127.0.0.1:8000/healthz # 后端
curl -sS http://127.0.0.1:8088/healthz # Nginx 入口
6. 验证与保障
冒烟测试脚本矩阵
| 脚本 | 覆盖场景 | 用途 |
|---|---|---|
workspace_api_smoke.sh |
注册/登录 → 创建案件 → 异步查询 → 报告新增 → PDF 导出 | 完整业务链路 |
retrieval_api_smoke.sh |
基础检索接口字段/格式校验 | API 契约验证 |
public_stack_smoke.sh |
终端一键构建 + 预览 | Demo 流程一致性 |
data_import_modes.sh |
resume/full 模式 + ALLOW_DATA_MUTATION guard | 数据导入安全 |
数据治理
-
自动清理临时用户与报告
-
保持库里只有干净案例,减少数据污染
-
可向投资人演示:每次部署都有自动检查
7. 整体说明演示
从采集到导入命令流程
bash
# ========== 步骤1:采集数据 ==========
cd /Users/Zhuanz/Desktop/study/AISass/LawCounsel
# 方式A:从已有数据源下载(CAIL2018 / LeCaRDv2)
bash scripts/download_legal_data.sh
# 方式B:如果你有200条原始数据文件,直接放入 raw 目录
# cp /path/to/your_new_200_docs.json data/raw/new_batch_200.json
# ========== 步骤2:规范化数据(生成JSONL) ==========
# 生成新的200条数据的JSONL文件
uv run python scripts/normalize_legal_jsonl.py \
--input data/raw/new_batch_200.json \
--output data/processed/new_200_docs.jsonl \
--limit 200
# ========== 步骤3:追加到现有数据文件 ==========
# 将新数据追加到主文件(注意使用 >> 追加,不是 > 覆盖)
cat data/processed/new_200_docs.jsonl >> data/processed/legal_docs.jsonl
# 验证追加后的总行数
wc -l data/processed/legal_docs.jsonl
# ========== 步骤4:导入向量库 ==========
cd backend
# 使用 resume 模式,只导入新增的200条
uv run python manage.py import_legal_data \
--path ../data/processed/legal_docs.jsonl \
--mode resume \
--limit 200
# ========== 步骤5:验证导入结果 ==========
cat ../data/logs/import_checkpoint.json查看当前数据情况
bash
0. 从已有数据源下载(CAIL2018 / LeCaRDv2)
bash scripts/download_legal_data.sh
1. 对比源文件与向量库
# 检查源文件有多少条数据
wc -l /Users/Zhuanz/Desktop/study/AISass/LawCounsel/data/processed/legal_docs.jsonl
# 检查导入进度(看 offset 是否到达文件末尾)
cat /Users/Zhuanz/Desktop/study/AISass/LawCounsel/data/logs/import_checkpoint.json
2. 快速比对命令
cd /Users/Zhuanz/Desktop/study/AISass/LawCounsel/backend
# 获取统计
echo "=== 源文件统计 ==="
SOURCE_LINES=$(wc -l < ../data/processed/legal_docs.jsonl)
echo "JSONL 总行数: $SOURCE_LINES"
echo ""
echo "=== 向量库统计 ==="
source .venv/bin/activate && python << 'PYEOF'
import os
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings')
import django
django.setup()
from apps.legal.models import LegalDocument, ChunkEmbedding
print(f"已入库文档: {LegalDocument.objects.count()}")
print(f"已生成向量: {ChunkEmbedding.objects.count()}")
missing = LegalDocument.objects.filter(chunks__isnull=True).count()
print(f"缺失分块的文档: {missing}")
PYEOF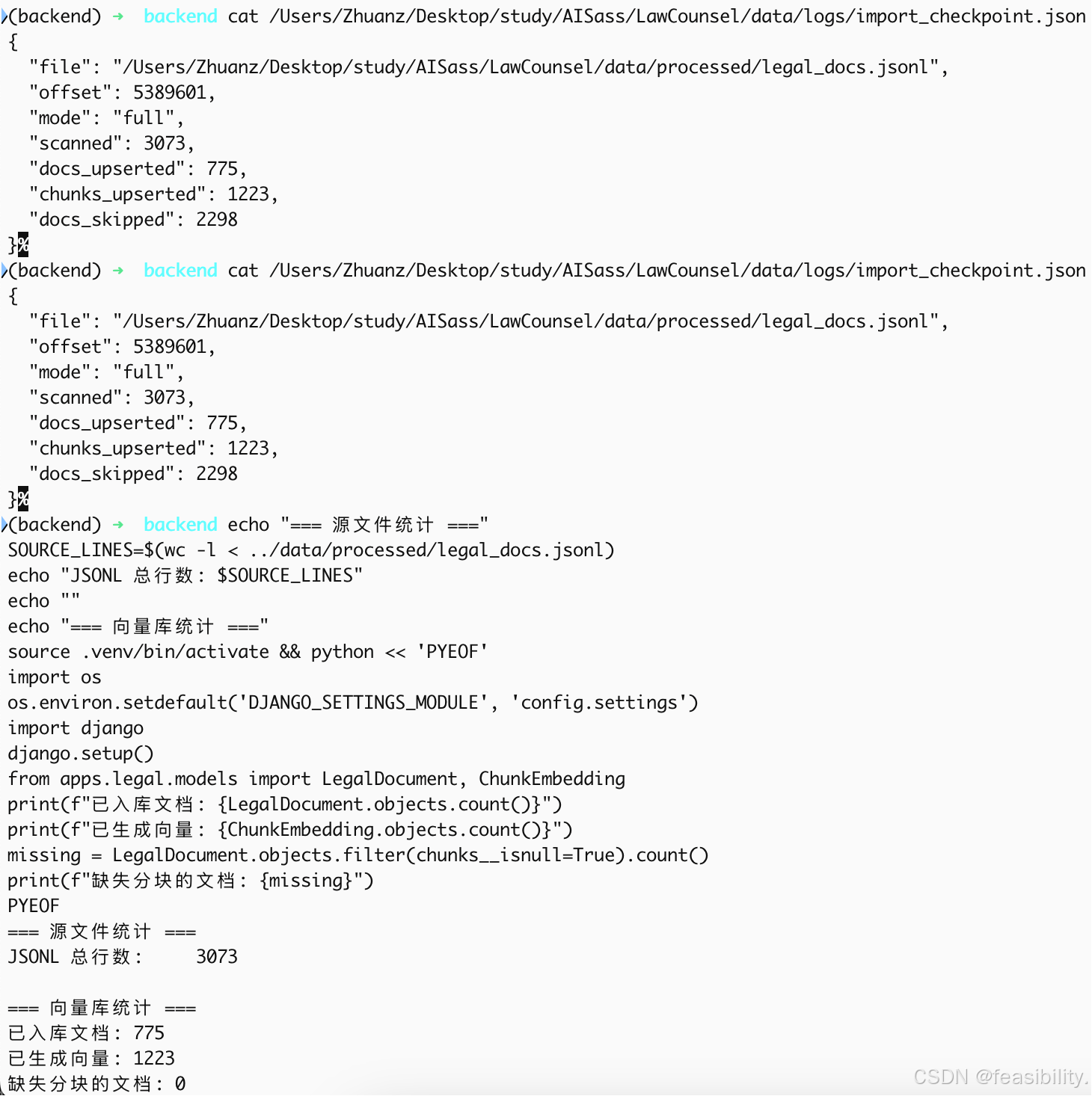
从这些统计看,确实没有剩下的未写入。3073 行已经全部扫描过了,最终只入库了 775,其余 2298 被去重/过滤掉了。
一键停止服务
cleanup_public_demo.sh
bash
#!/usr/bin/env bash
set -euo pipefail
ROOT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")/.." && pwd)"
PID_FILE="/tmp/lawcounsel-nginx.pid"
echo "[STEP] stop nginx proxy"
nginx -c "$ROOT_DIR/infra/nginx/lawcounsel.conf" -s stop -g "pid $PID_FILE;" >/dev/null 2>&1 || true
rm -f "$PID_FILE" || true
echo "[STEP] kill occupied ports 8000/4173/8088 if any"
for port in 8000 4173 8088; do
pids="$(lsof -ti tcp:$port || true)"
if [ -n "$pids" ]; then
kill $pids >/dev/null 2>&1 || true
echo "[INFO] killed pid(s) on :$port -> $pids"
fi
done
echo "[OK] cleanup done"这个脚本是给项目做一站式环境清理的,使用者不用手动查进程、删文件,运行它就能一键解决 "端口被占、Nginx 进程残留" 的问题,避免启动服务时报错:
1)#!/usr/bin/env bash和set -euo pipefail是脚本基础:前者告诉系统用 bash 执行,后者是防错保护(出错也不会乱执行);
2)ROOT_DIR/PID_FILE:自动找到项目根目录、指定 Nginx 进程文件路径,不用手动输路径;
3)nginx -c ... -s stop:先尝试用项目专属配置停止 Nginx 代理,不管停没停成功都不报错(避免没启动 Nginx 时脚本卡壳),然后删掉 Nginx 进程文件,防止残留;
4)循环清理 8000/4173/8088 端口:自动检查这三个端口(后端 8000、前端 4173、5)Nginx8088)有没有被进程占用,有就直接杀掉,还会提示杀掉的进程号,没占用就跳过;
6)最后提示 "清理完成",整个过程不用手动操作,能彻底清掉项目相关的残留进程和文件。

一键启动脚本
bash
cleanup() {
nginx -c "$ROOT_DIR/infra/nginx/lawcounsel.conf" -s stop -g "pid $PID_FILE;" >/dev/null 2>&1 || true
kill "${FRONT_PID:-}" >/dev/null 2>&1 || true
kill "${BACK_PID:-}" >/dev/null 2>&1 || true
}
trap cleanup EXIT
if [ -f "$PID_FILE" ]; then
echo "[STEP] stop previous nginx pid from $PID_FILE"
nginx -c "$ROOT_DIR/infra/nginx/lawcounsel.conf" -s stop -g "pid $PID_FILE;" >/dev/null 2>&1 || true
rm -f "$PID_FILE"
fi
if lsof -nP -iTCP:8088 -sTCP:LISTEN >/dev/null 2>&1; then
echo "[ERR] port 8088 already in use."
lsof -nP -iTCP:8088 -sTCP:LISTEN || true
echo "[TIP] run: bash scripts/cleanup_public_demo.sh"
exit 1
fi
echo "[STEP] start backend :8000"
cd "$ROOT_DIR/backend"
uv run python manage.py runserver 127.0.0.1:8000 >/tmp/lawc_backend.log 2>&1 &
BACK_PID=$!
echo "[STEP] start frontend preview :4173"
cd "$ROOT_DIR/frontend"
if [ "${SKIP_FRONTEND_BUILD:-0}" != "1" ]; then
echo "[STEP] build frontend dist"
npm run build >/tmp/lawc_frontend_build.log 2>&1
fi
npm run preview >/tmp/lawc_frontend.log 2>&1 &
FRONT_PID=$!
sleep 3
echo "[STEP] start nginx proxy :8088"
nginx -c "$ROOT_DIR/infra/nginx/lawcounsel.conf" -g "pid /tmp/lawcounsel-nginx.pid;"
echo "[STEP] local check"
curl -sS http://127.0.0.1:8088/healthz || true
echo
echo "[STEP] start cloudflare tunnel (Ctrl+C stop all)"
exec cloudflared tunnel --url http://127.0.0.1:8088 --protocol "$TUNNEL_PROTOCOL"这个脚本是项目的一键启动全流程工具,使用者不用手动一步步启动前后端、Nginx,也不用自己配置公网访问,运行它就能自动完成所有步骤,把项目从本地跑起来并暴露到公网:
1)开头的#!/usr/bin/env bash和set -euo pipefail是基础:前者让系统用 bash 执行脚本,后者是 "防错保护",有一步出错就停,避免乱执行;
2)自动找项目根目录、加载.env配置文件(有就加载,没有也不影响),还默认用 http2 协议跑公网隧道,不用手动输路径 / 配参数;
先检查cloudflared(做公网穿透)和nginx有没有装,没装就提示 Mac 用户用brew install安装,装完才能继续;
3)设置了 "自动清理":不管是按 Ctrl+C 退出,还是脚本出错,都会自动停 Nginx、杀掉前后端进程,避免进程残留;
先停掉旧的 Nginx 进程,再检查 8088 端口有没有被占(被占就报错,还告诉运行清理脚本解决);
4)自动启动后端服务(8000 端口):切到后端目录,用 uv run 启动 Django,日志存在 /tmp,后台运行不占终端;
自动启动前端服务(4173 端口):切到前端目录,先判断要不要构建前端(没跳过就先 build),再启动预览,日志也存在 /tmp;
等 3 秒让前后端启动好,再启动 Nginx(8088 端口),把前后端统一到 8088 这个入口;
5)用 curl 简单检查 8088 端口的健康状态,确认服务能访问;
6)最后启动 Cloudflare 隧道,把 8088 端口的服务暴露到公网,按 Ctrl+C 就能停掉所有服务(还会自动清理进程)。
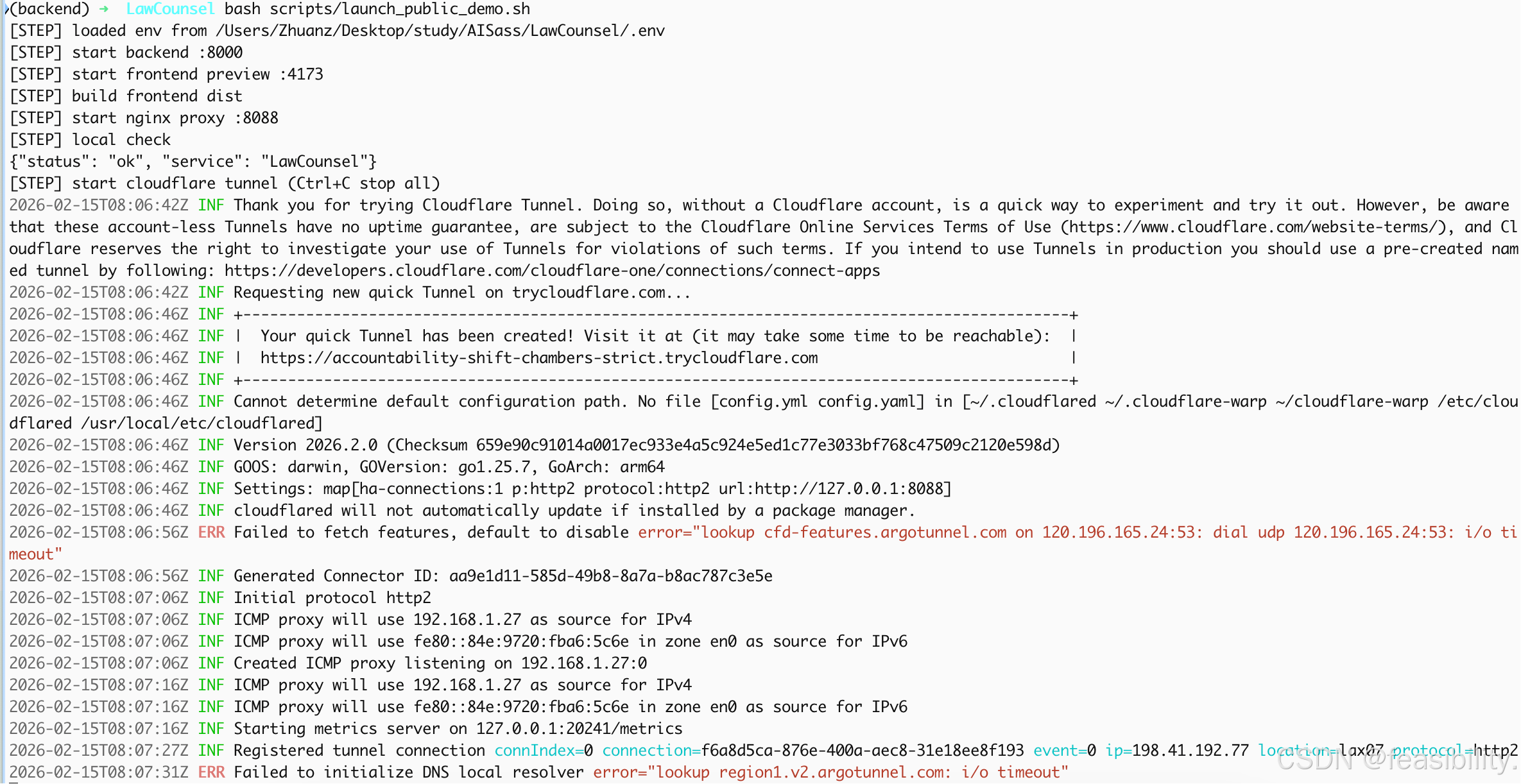
这不是失败,隧道已经创建并注册成功了。
关键行是:
1)Your quick Tunnel has been created! Visit it at: https://accountability-shift-chambers-strict.trycloudflare.com
2)Registered tunnel connection ... protocol=http2
报错 Failed to fetch features 和 Failed to initialize DNS local resolver 是 DNS 超时警告,通常是本地网络对 Cloudflare 域名解析不稳定,但不一定影响访问。
现在的公网地址是:https://accountability-shift-chambers-strict.trycloudflare.com
使用
填写案件信息,点击创建案件
检索
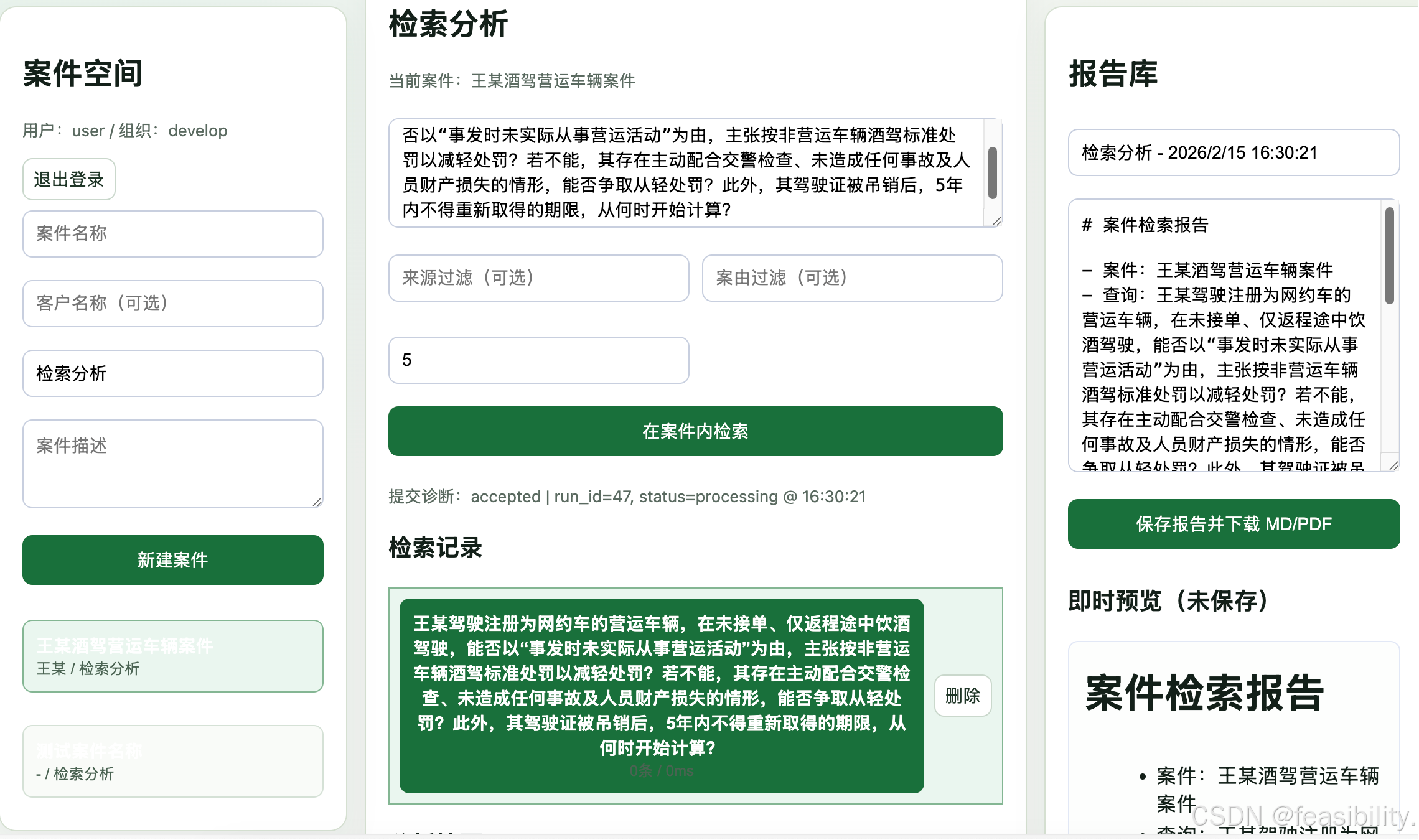
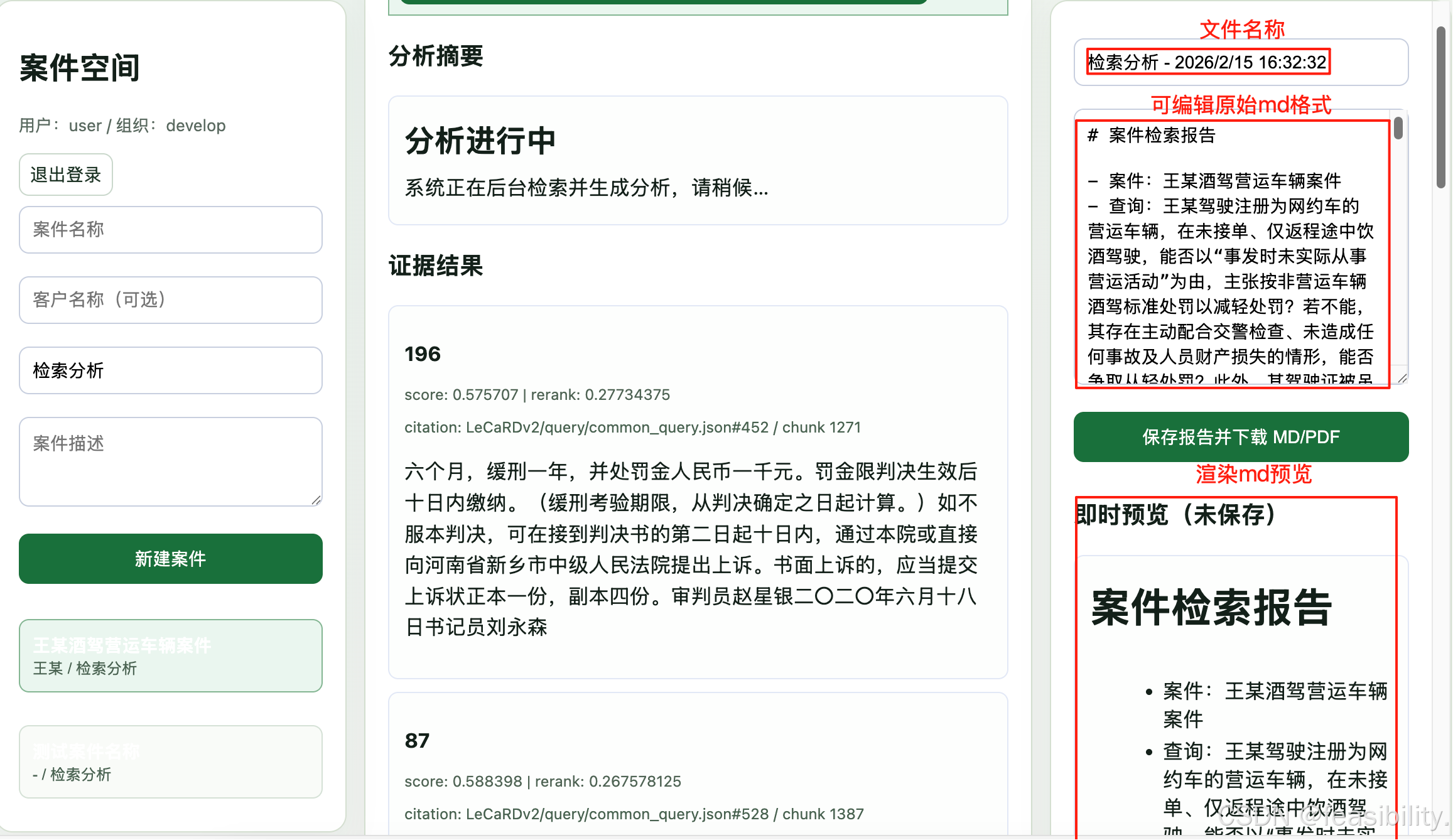
分析,如果回答被截断,可改.env的ANALYSIS_MAX_TOKENS=512为更大的值

点击导出md和pdf文件
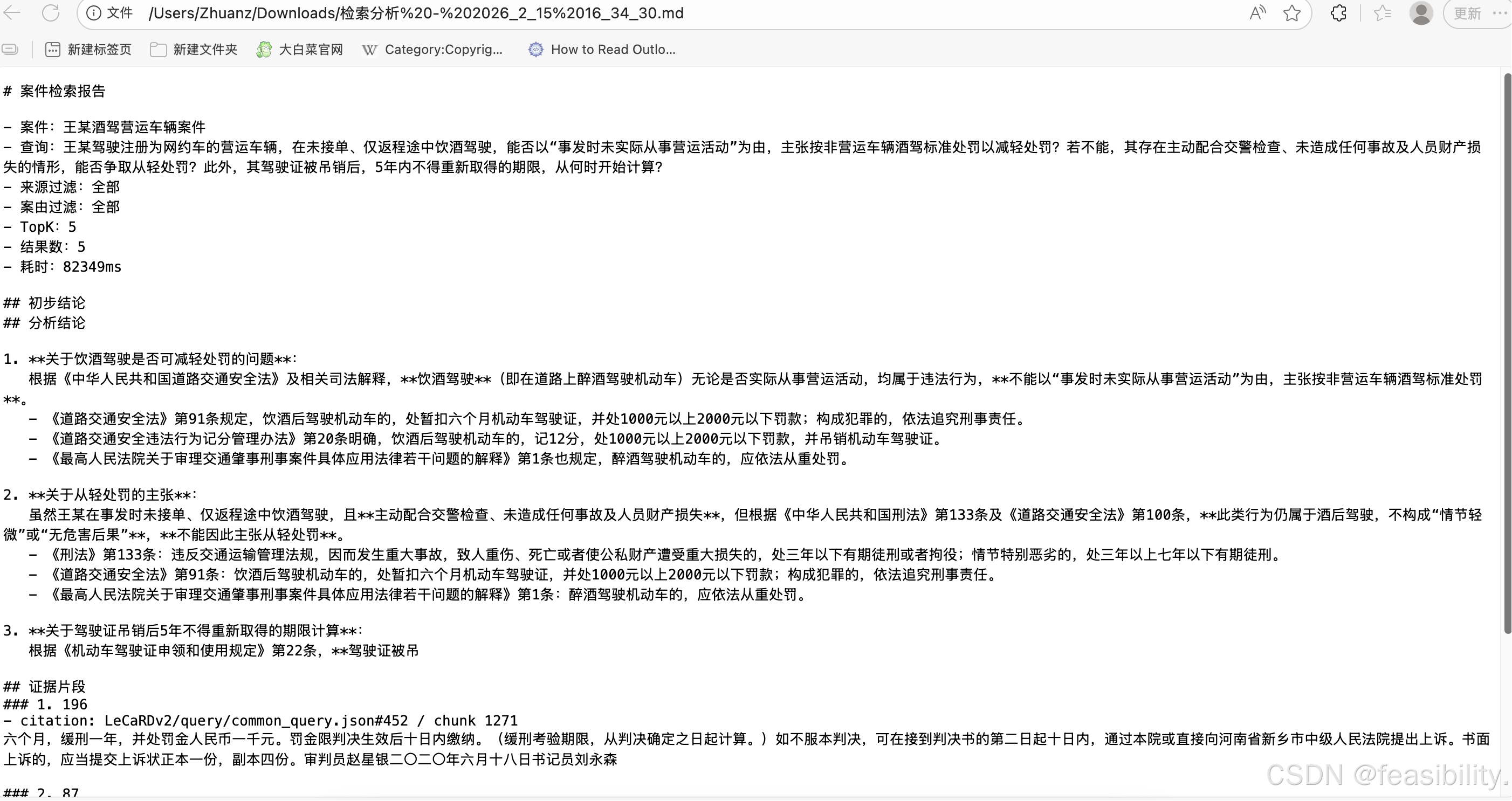
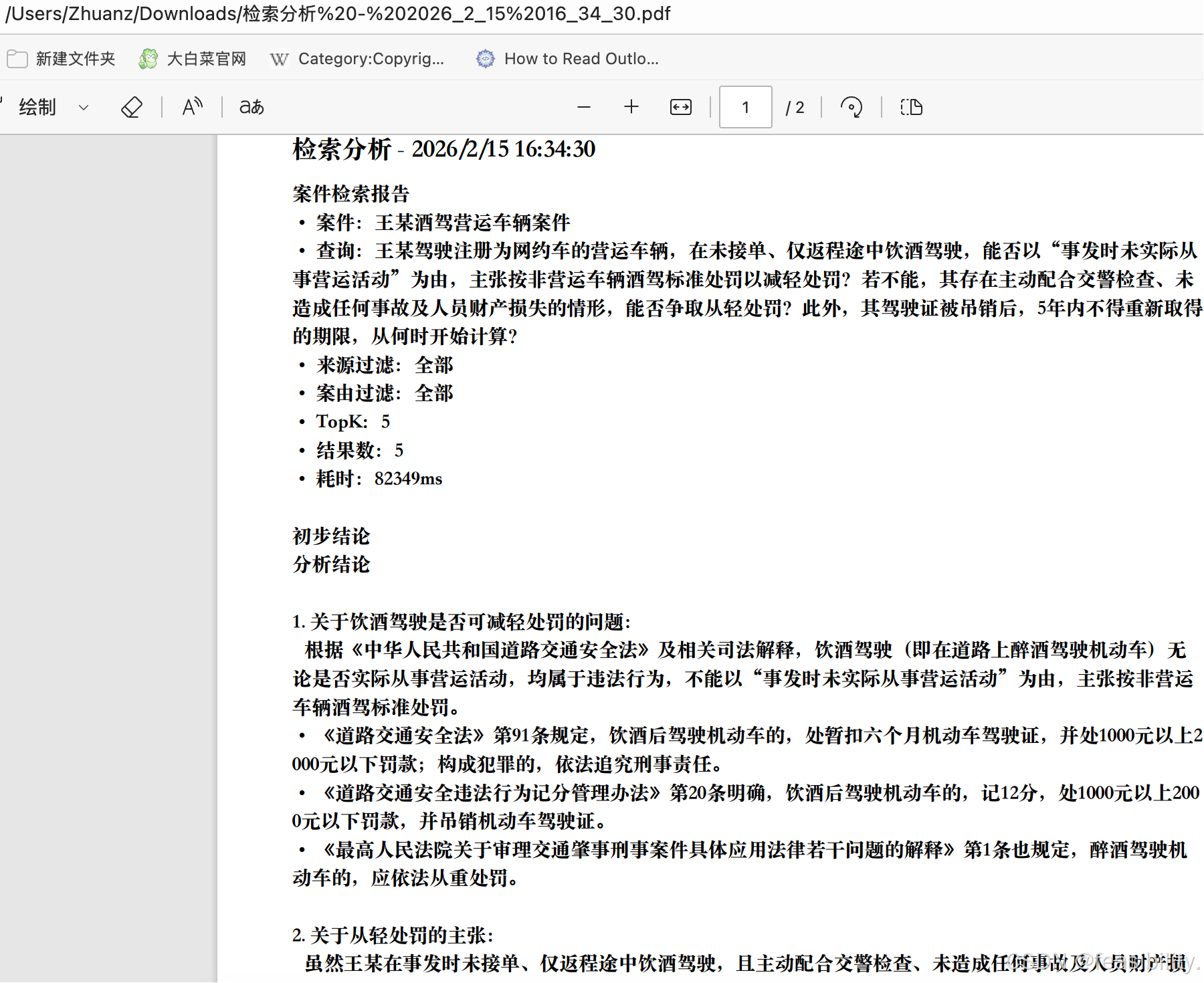
8. 运营建议与成本控制
成本边界控制
| 项目 | 策略 | 成本 |
|---|---|---|
| 硬件 | 本地 16GB MPS 跑 Qwen3-VL | 零租赁成本 |
| 存储 | PostgreSQL + 数据文件 < 1GB | 极低本地存储 |
| 可选组件 | Redis + Celery 按需启动 | 平时不消耗资源 |
| 公网演示 | Cloudflare Tunnel | 零成本 |
多模型支持矩阵
| Provider | Embedding | Rerank | Analysis | 适用场景 |
|---|---|---|---|---|
mock |
✅ | - | - | 开发/测试 |
ollama |
✅ | - | ✅ | 本地快速验证 |
qwen3_vl |
✅ | ✅ | ✅ | 生产级中文法律 |
cloud_api |
✅ | ✅ | ✅ | 高精度/高并发 |
可维护性设计
-
检索链路标准化 :
embedding → pgvector → rerank → markup -
Provider 即插即用: 随时切换模型
-
报告库统一: Markdown (前端渲染) + PDF (客户交付)
9. 总结与演进路线
当前能力
LawCounsel 将多模态模型、本地数据库与轻量前端 连接起来,构建一个可控、透明、面向中文法律的 AI+准 SaaS:
-
✅ 自动化数据清洗 (断点续传、去重)
-
✅ 异步检索与报告导出
-
✅ Smoke tests 保障部署质量
-
✅ Cloudflare 快速隧道实现零成本公网演示
未来演进
| 方向 | 具体动作 |
|---|---|
| 模型热切换 | 打通 Ollama/Cloud API/纯本地模型运行时切换 |
| 数据切块优化 | 让模型按语义灵活切块数据 |
| 数据源扩展 | 引入地方法院判例等更多中文法律数据源 |
LawCounsel 的核心价值在于:用工程约束(1GB 数据、低成本硬件、自动化测试)换取商业可信度(企业级体验、可验证的 Demo、即时可用的报告输出)。这是一个典型的"约束驱动创新"案例,非常适合法务科技领域的 MVP 验证与早期客户演示。
如果对项目的代码有兴趣,打算研究或优化,可以通过网盘分享的文件获取:Law-Counsel.zip
链接: https://pan.baidu.com/s/1KKykitAlzOFNzKTsrNydJA?pwd=3hrc 提取码: 3hrc
创作不易,禁止抄袭,转载请附上原文链接及标题