当"氛围编程"撞上工程化之墙
过去18个月,软件工程领域经历了一场奇特的狂欢。"Vibe Coding"(氛围编程)成为最时髦的术语------开发者用自然语言与AI即兴对话,享受着代码如泉水般涌出的快感。然而,这场狂欢很快显露出其脆弱本质:相同的提示词在不同时间产出完全不同的代码,冗长的聊天历史让需求追溯变成考古学,上下文丢失导致AI频繁"失忆",生成的代码"听起来正确但实际上无法运行"。
当生成式AI的瓶颈从"写不出代码"转向"管不住意图",整个行业开始意识到一个残酷的事实:我们正在用规范的工程实践,换取不可预测的交付质量。
正是在这个拐点上,规范驱动开发(Spec-Driven Development, SDD)作为一种救赎性范式浮出水面。本文将从大模型架构师的视角,系统阐述SDD的技术演进、核心框架与工程实践,揭示其如何将软件架构从"咨询性建议"转变为"可执行契约"。(扩展阅读:基于规范驱动开发的下一代软件工程范式:从理论到实践、意图即代码:从Vibe Coding到Spec-Driven Development,软件工程的范式跃迁)

历史演进:软件抽象的五代变迁与范式危机
编程语言的世代跃迁
软件工程的历史,本质上是一部抽象层级不断提升的历史。从第一代机器代码到第五代自然语言,每一次跃迁都重新定义了开发者的角色:
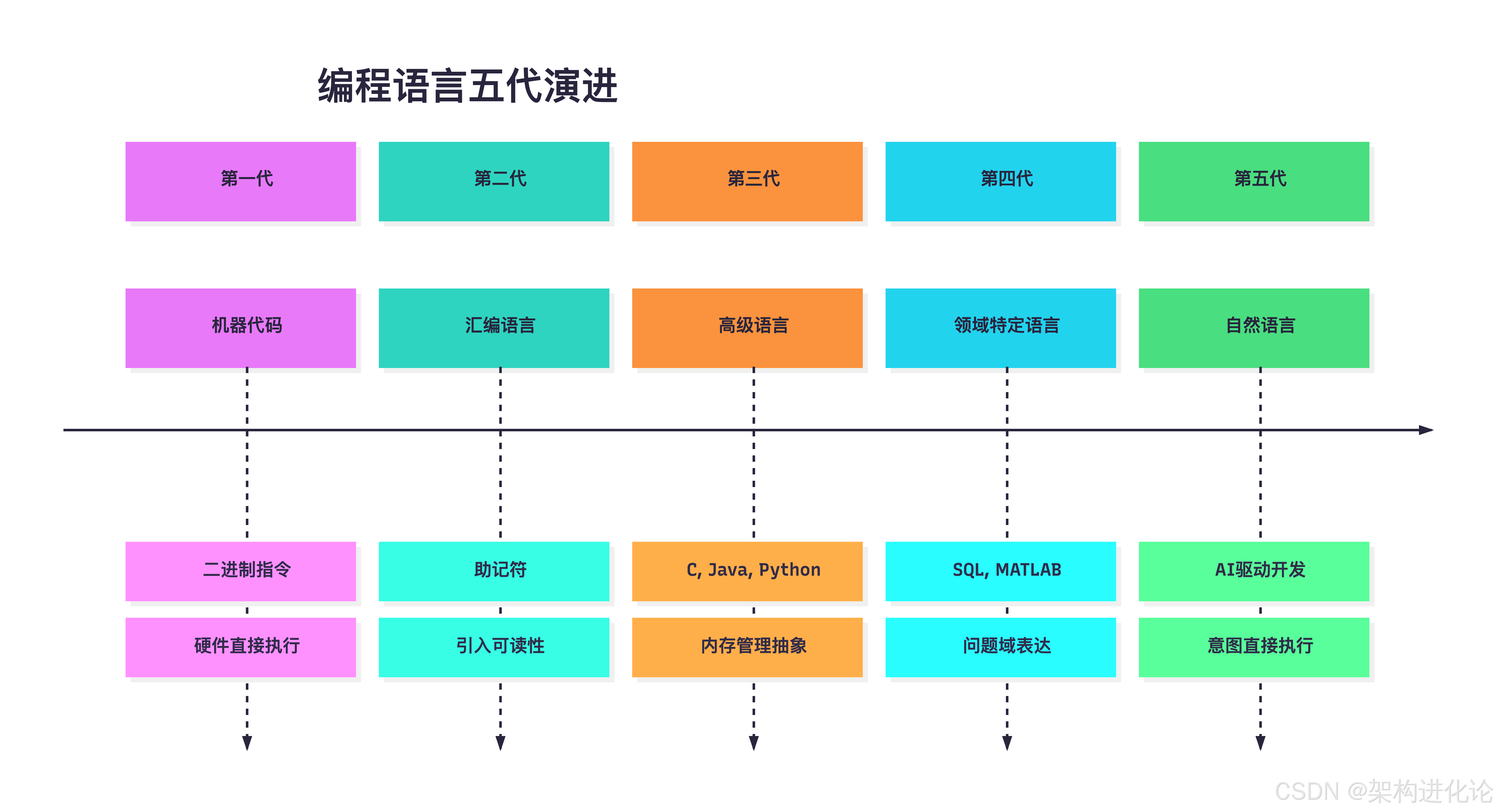
第五代的特殊性在于:它不仅提升了抽象层级,更颠覆了"谁来执行"的根本问题。开发者不再直接编写代码,而是通过自然语言表达意图,由AI将其转化为可执行代码。
第五代抽象带来的新危机
然而,这种范式转移引入了一个悖论:个人生产力激增的同时,项目级别的可预测性急剧下降。让我们通过一个生活化案例来理解这一困境:
装修队的困境
想象你请了一支装修队(AI助手)来改造厨房。你口头描述:"我想要一个现代化的开放式厨房,有足够的收纳空间。"装修队非常高效,三天就完工了。但你走进厨房时傻眼了:他们拆掉了承重墙(架构破坏),安装了20个插座但没留冰箱的位置(功能遗漏),所有橱柜都是玻璃门(不符合实际需求)。你质问他们,装修队长委屈地说:"你说要'现代化'和'收纳空间'啊,玻璃门展示收纳不是很现代吗?"
这正是"Vibe Coding"的写照------模糊的指令被AI自由解读,结果充满创意但完全偏离预期。
这种不可预测性为项目中的每个角色创造了独特的痛点:
-
开发者:不断返工的挫败感。从初始代码生成中获得的时间,很快被调试和重构AI生成代码所消耗。
-
项目经理:范围蔓延失控,项目截止日期因不可预见的返工而受到威胁。
-
技术负责人:代码质量和架构完整性难以维护,每个开发者及其AI助手对目标都有略微不同的解读。
从"氛围"到"规范"的必然转向
行业对这场危机的回应,是一场从"即兴提示"到"规范驱动"的深刻转向。开源社区在过去12个月内构建了完整的SDD工具链,正在分化为三大层级:

这套工具链的核心洞察在于:AI需要"紧箍咒"。规范不再是可有可无的文档,而是约束AI创造性但往往不可靠的生成过程的主要指令。
核心理论:架构逆转向量与五层执行模型
传统架构的线性困境
传统软件交付遵循线性、有损失的管道:

每一步翻译都引入了重新解释、手动适应和隐藏的假设。架构漂移不是"是否会发生"的问题,而是"何时被发现"的问题------通常是通过生产事件、集成失败或合规违规。
架构逆转向量:SDD的理论核心
SDD完全颠覆了这种关系。其核心可以概括为一个简洁但深刻的命题:代码不再是真相出现的地方,而成为真相仅仅被实现的地方。
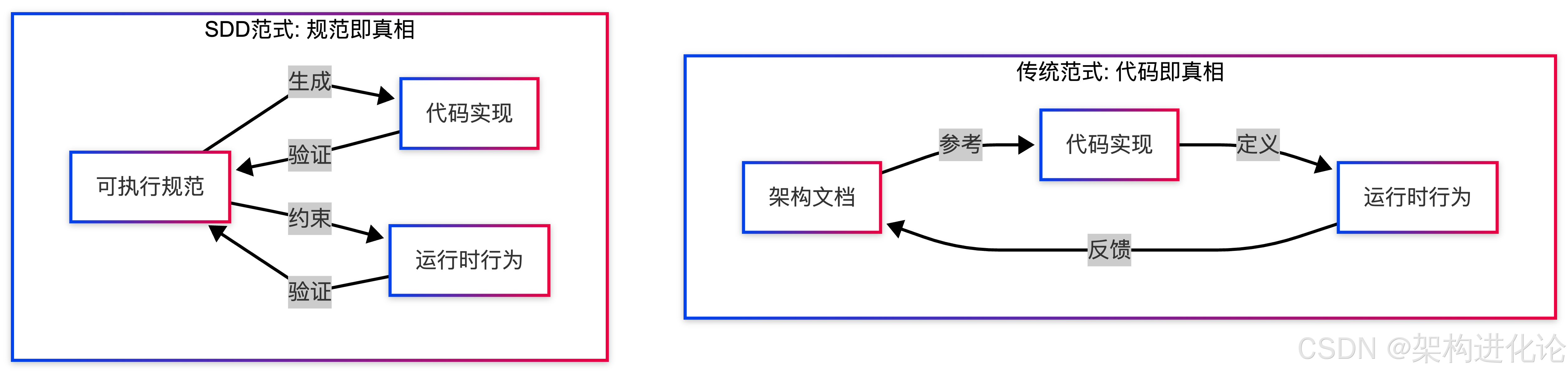
这种架构逆转向量(Architectural Inversion Vector)意味着:规范成为系统现实的权威定义,实现是持续派生、验证的,并且在必要时重新生成以符合该真实性。
五层执行模型
这一理论落地为清晰的五层执行模型:
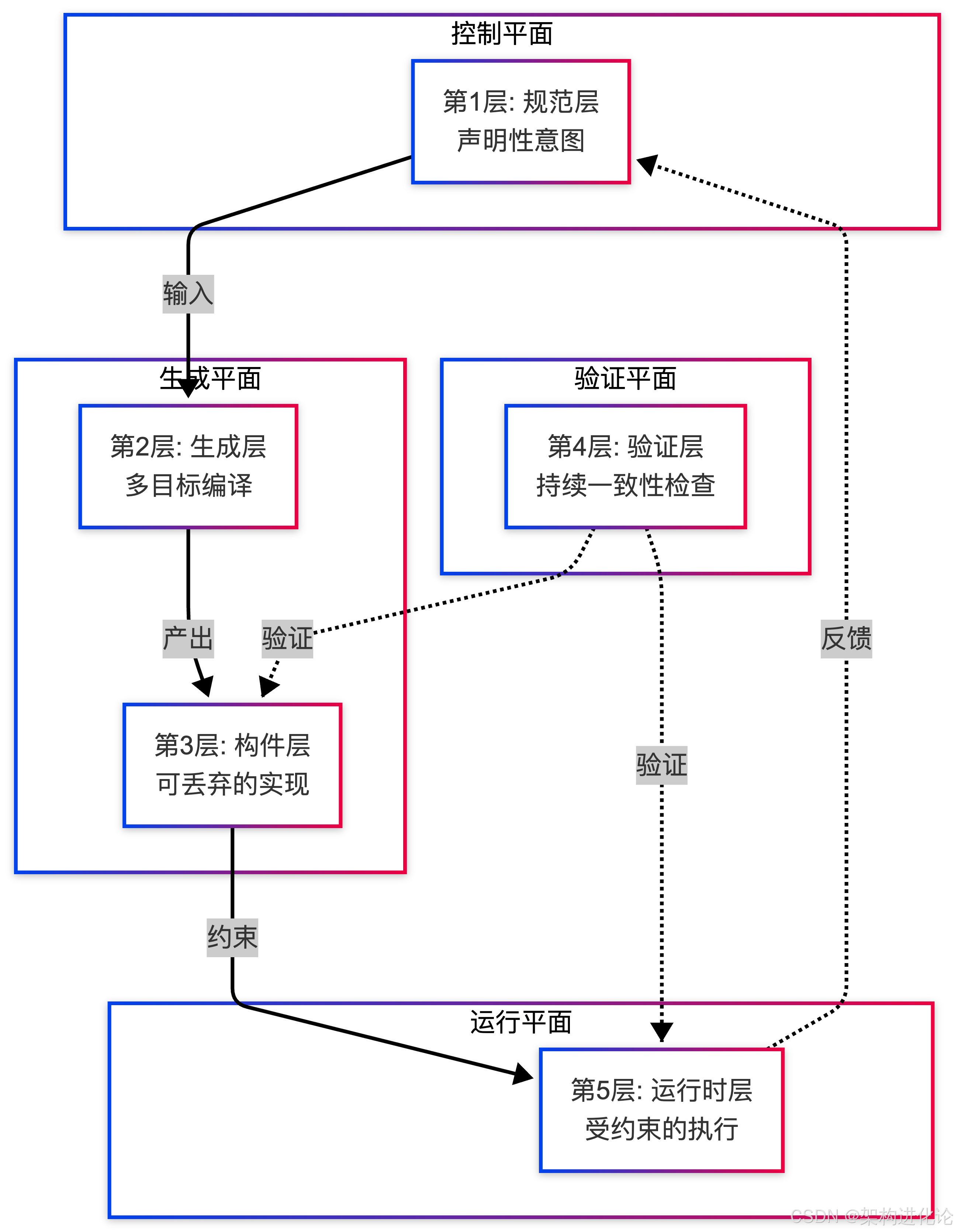
第1层:规范层 - 系统行为的权威定义。它捕获声明性意图,而非实现方式。包含API模型、消息契约、领域模式和策略约束。
以订单服务为例的伪规范:
service: Orders
api:
POST /orders:
request:
Order:
id: uuid
quantity: int > 0 # 声明式约束
responses:
201: OrderAccepted
400: ValidationError
policies:
compatibility: backward-only
security: auth: mTLS这个规范明确声明:订单数量必须为正、API不得引入破坏性变更、请求必须经过认证------没有任何语言、框架或基础设施的引用。
第2层:生成层 - 将声明性意图转化为可执行形式。作为多目标系统编译器,它发出类型模型、契约存根、验证中间件、文档以及集成测试。
第3层:构件层 - 生成的具体输出。关键洞察:这些构件可丢弃、可替换。如果规范发生变化,它们将被重新生成;如果被删除,什么也不会丢失。
第4层:验证层 - 强制执行意图与执行间的持续一致性。由契约测试、模式验证、兼容性分析和架构漂移检测组成。
第5层:运行时层 - 操作系统本身,其形状完全受上游规范和验证层约束。运行时行为在架构上是确定的,而非涌现性的。
框架深析:三大SDD开源实现的哲学与实战
GitHub Spec Kit:企业级开发的"宪法"模式
Spec Kit代表了SDD中最结构化、最严谨的一极,特别适合绿地项目(0→1开发)。
核心架构:.specify目录体系
Spec Kit的核心创新在于.specify目录体系,它将项目意图固化为AI必须遵守的契约:
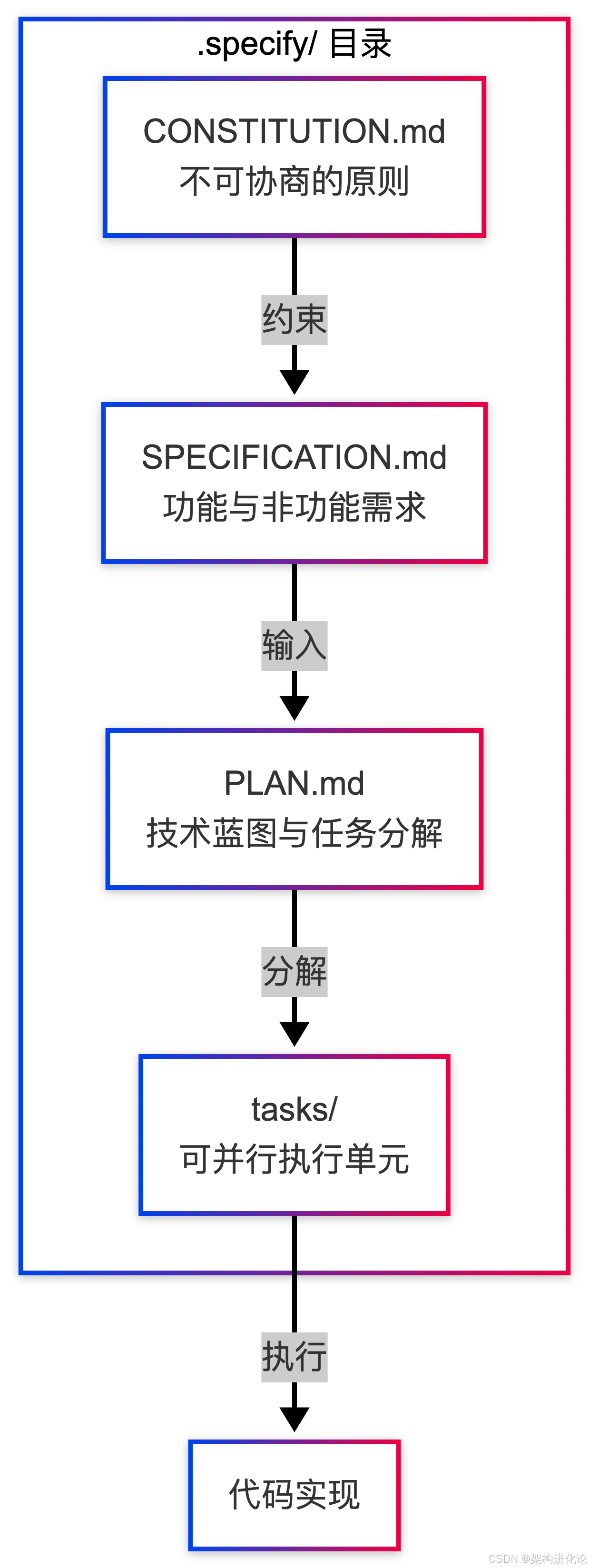
**CONSTITUTION.md(宪法)**记录不可协商的原则,如"所有数据库查询必须参数化""测试覆盖率必须高于80%"。这相当于给AI设定了"价值观底线"。
**SPECIFICATION.md(规格)**包含详细需求,通过质量门禁确保完整性。Spec Kit的AI代理会生成质量报告,评分低于阈值时要求补充。
**PLAN.md(计划)**由技术架构师智能体生成,包含任务分解、工时估计和依赖关系。
四阶段工作流
Spec Kit通过CLI命令强制执行四阶段流程:
bash
# 阶段1: 立宪 - 定义项目指导原则
speckit constitute
# 阶段2: 规格 - 创建详细需求(需求分析师智能体)
speckit specify
# 阶段3: 计划 - 设计技术架构(技术架构师智能体)
speckit plan
# 阶段4: 实现 - TDD方式构建(实现工程师智能体)
speckit implement
# 随时查看进度
speckit status代码示例:Spec Kit实战
以下是一个待办事项API的完整Spec Kit流程:
1. 立宪阶段输出(.speckit/CONSTITUTION.md)
bash
# 项目宪法:待办事项API
## 核心宗旨
构建一个安全、简洁、API优先的待办事项管理系统
## 不可协商原则
1. **安全第一** - 所有用户数据必须加密存储,认证令牌必须使用HTTP-only Cookie
2. **简约优于丰富** - 每个功能必须有明确的必要性,拒绝"锦上添花"式需求
3. **API优先设计** - 所有功能必须通过REST API暴露,UI仅作为API客户端
4. **测试覆盖** - 核心业务逻辑测试覆盖率≥90%,API集成测试覆盖率≥80%
5. **文档即代码** - API文档必须从规范生成,禁止手动维护独立文档
## 技术约束
- 使用TypeScript + Node.js 20+
- 数据库使用PostgreSQL 15+
- ORM必须使用Prisma
- API响应时间95分位数<200ms2. 规格阶段输出(.speckit/SPECIFICATION.md)
bash
# 功能规格:待办事项API
## 功能性需求
### FR-1: 用户注册
- 用户可通过邮箱和密码注册
- 密码必须满足:至少8位,包含大小写字母和数字
- 注册成功后自动登录,返回会话令牌
### FR-2: 待办事项管理
- 用户可以创建待办事项(标题必填,描述可选)
- 用户可以查看自己的待办事项列表(支持分页)
- 用户可以更新待办事项状态(待办/进行中/完成)
- 用户可以删除待办事项
## 非功能性需求
### NFR-1: 性能
- 列表查询响应时间<100ms(1000条数据以内)
- 并发支持:至少1000 QPS
### NFR-2: 安全
- 所有API必须经过JWT认证(除注册/登录外)
- 用户只能访问自己的待办事项
## 验收场景
### 场景: 成功创建待办事项
- GIVEN 已认证用户
- WHEN 调用POST /todos { "title": "买牛奶", "description": "脱脂" }
- THEN 返回201 Created,包含创建的待办事项对象
- AND 待办事项状态默认为"待办"
### 场景: 未认证访问
- WHEN 调用GET /todos 未提供认证令牌
- THEN 返回401 Unauthorized3. 计划阶段输出(.speckit/PLAN.md)
bash
# 技术实现计划
## 架构概览
- API层:Express路由
- 服务层:业务逻辑封装
- 数据层:Prisma + PostgreSQL
## 任务分解
### 阶段1: 基础架构(4小时)
- [ ] 1.1 初始化Node.js + TypeScript项目
- [ ] 1.2 配置Prisma和PostgreSQL连接
- [ ] 1.3 设置JWT认证中间件
### 阶段2: 用户认证(6小时)
- [ ] 2.1 实现用户注册API
- [ ] 2.2 实现用户登录API
- [ ] 2.3 密码加密存储(bcrypt)
- [ ] 2.4 单元测试:密码加密、JWT生成
### 阶段3: 待办事项CRUD(8小时)
- [ ] 3.1 创建待办事项API
- [ ] 3.2 查询列表API(分页)
- [ ] 3.3 更新状态API
- [ ] 3.4 删除API
- [ ] 3.5 数据访问控制(用户隔离)
### 阶段4: 测试与文档(3小时)
- [ ] 4.1 API集成测试(Supertest)
- [ ] 4.2 生成OpenAPI文档
- [ ] 4.3 性能测试
## 依赖关系
- 2.x 依赖 1.3
- 3.x 依赖 2.x4. 执行阶段 :speckit implement命令会让实现工程师智能体按任务清单逐一实现,每个任务遵循TDD红绿重构循环。
OpenSpec:棕地系统的"RFC"变革模型
如果说Spec Kit是为"从0到1"的新项目设计,那么OpenSpec则是为"从1到n"的棕地系统演进而生。
核心洞察:分离真相来源与提议更新
OpenSpec最深刻的洞察在于:演进中的系统需要一个"变更提案"模型,类似Git的分支机制。其核心架构围绕两个目录展开:
openspec/
├── specs/ # 所有系统规范的当前真相来源
│ └── capability/
│ └── spec.md # 已验证的规范快照
└── changes/ # 所有提议、进行中、已归档变更
└── change-name/ # 每个变更独立隔离
├── proposal.md # 变更的"原因"和"内容"
├── tasks.md # AI实施检查清单
├── design.md # 技术决策(可选)
└── specs/ # 规范增量"补丁"
└── capability/
└── spec.md # 使用ADDED/MODIFIED/REMOVED标记
这种结构的精妙之处在于:
-
specs/ 像Git的
main分支------稳定的真相来源 -
changes/change-name 像功能分支------隔离的提议更新
-
归档操作类似合并PR------只有当实现完成并验证后,才将增量合并回主规范
四阶段工作流:从提案到归档
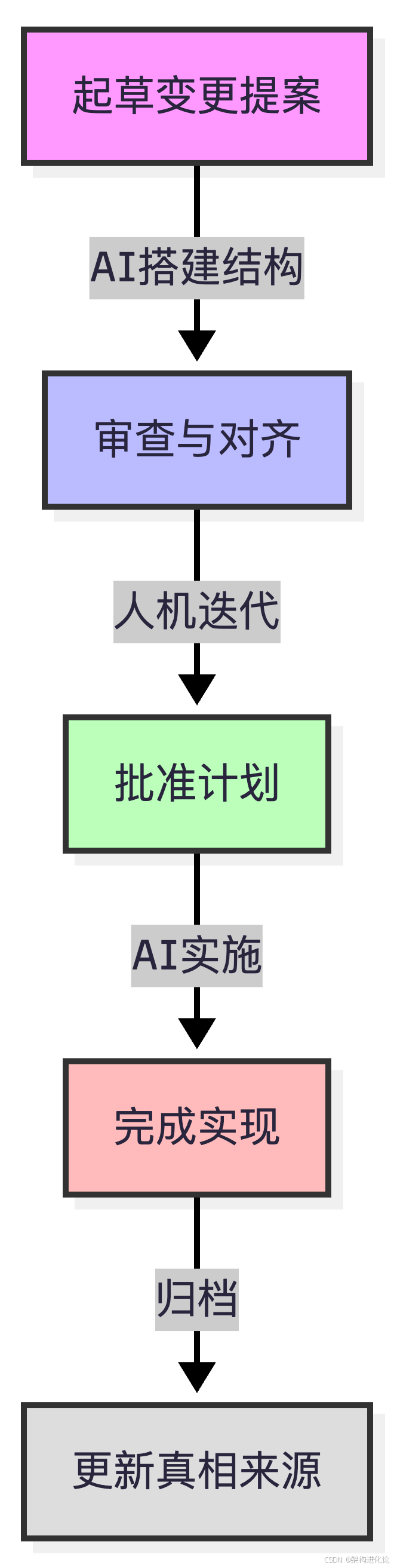
代码示例:OpenSpec棕地演进实战
让我们通过一个真实案例,展示OpenSpec如何改造现有系统。假设我们有一个推荐系统,需要新增"导出推荐记录为CSV"的功能。
场景:某餐饮推荐平台已有RecommendRecord模型,运营团队需要按商户和时间窗口导出数据进行分析。
第一步:创建变更提案
开发者通过自然语言或斜杠命令启动提案:
bash
/openspec:proposal 增加导出RecommendRecord为CSV的API,支持传餐厅ID、开始时间和结束时间AI自动搭建变更结构,生成proposal.md:
bash
# 变更提案: 推荐记录导出API
## Why (为什么做)
运营团队需要定期导出推荐记录用于质量评估和模型回放。目前缺乏按商户与时间窗口导出的标准接口,分析师只能手动查询数据库,效率低且有安全风险。
## What (做什么)
- 新增导出接口: GET /api/v1/recommend_record/export
- 支持参数: merchant_id, start_time, end_time (ISO 8601)
- 响应格式: CSV文件下载
- 大数据量采用流式响应,避免内存峰值
## Impact (影响范围)
- 影响的规范: recommend-records
- 影响的代码模块:
- api/views/recommend_record.py
- services/export_service.py
- models/recommend_record.py
- 影响的测试: 需新增单元测试和集成测试
## 非目标
- 不实现XLSX导出(后续需要再提)
- 不新增鉴权机制(复用现有认证)第二步:细化规范增量
AI生成规范增量文件,使用ADDED/MODIFIED/REMOVED标记清晰标示变更:
bash
# 规范增量: 推荐记录模块
## ADDED 需求
### 需求: 导出推荐记录CSV
系统 SHALL 提供导出RecommendRecord的CSV接口,按商户与时间窗口过滤。
- Endpoint: `GET /api/v1/recommend_record/export`
- Query参数(必填):
- `merchant_id`: string,商户ID
- `start_time`: string,ISO 8601 (例如 `2025-01-01T00:00:00-05:00`)
- `end_time`: string,ISO 8601 (例如 `2025-01-31T23:59:59-05:00`)
- 时间过滤: 基于RecommendRecord `created_at` 范围,包含端点时间
- 响应: `text/csv`, `Content-Disposition` 附件
- CSV列(顺序固定):
- `recommend_id`, `process_record_id`, `call_id`, `seat_id`
- `dish_id`, `dish_name`, `std_id`, `std_name`
- `type`, `confidence`, `accept`, `accept_time`
- `recommend_method`, `created_at`
- 性能: 当记录量大时,系统 MUST 采用流式写出,避免内存峰值
#### 场景: 导出成功(有数据)
- WHEN 调用带有效参数的接口
- THEN 返回200,Content-Type: text/csv
- AND 响应包含表头与至少1行数据
#### 场景: 导出成功(无数据)
- WHEN 指定时间范围内无记录
- THEN 返回200,CSV仅包含表头,无数据行
#### 场景: 参数错误
- WHEN 缺少必要参数或时间格式无效
- THEN 返回400,JSON错误消息
#### 场景: 大数据量流式
- GIVEN >100k条记录在时间窗口内
- WHEN 触发导出
- THEN 服务端以流式方式写出CSV(分块flush)第三步:生成实施清单
tasks.md将变更拆解为可执行的任务单元:
bash
## 实施清单: 推荐记录导出API
### 1. 后端实现
- [ ] 1.1 新增导出视图: 注册到 `/api/v1/recommend_record/export`
- [ ] 1.2 服务层实现: 按商户与时间窗口查询,关联相关表获取完整字段
- [ ] 1.3 CSV生成器: 实现流式写出,设置正确的Content-Type和Content-Disposition
- [ ] 1.4 参数验证中间件: 校验必填项和时间格式
- [ ] 1.5 错误处理: 统一异常捕获,返回标准化错误响应
### 2. 测试
- [ ] 2.1 单元测试: 服务层查询逻辑、CSV行序列化
- [ ] 2.2 单元测试: 参数验证器(有效/无效用例)
- [ ] 2.3 集成测试: API成功响应(有数据/空数据)
- [ ] 2.4 集成测试: 错误参数返回400
- [ ] 2.5 性能测试: 10万条数据的内存占用验证
### 3. 文档与部署
- [ ] 3.1 更新API文档
- [ ] 3.2 更新CHANGELOG
- [ ] 3.3 预发环境验证
- [ ] 3.4 监控指标添加(导出请求计数、数据量)第四步:实施与归档
开发者和AI协作完成任务清单,每项完成后标记。全部完成后执行归档:
bash
/openspec:archive add-recommend-record-export-api归档操作将changes/中的规范增量合并到specs/主目录,更新系统的"真相来源"。此时,新功能正式成为项目规范的一部分,所有未来的AI交互都基于此准确上下文。
OpenSpec的设计哲学
OpenSpec的成功源于几个关键设计决策:
-
棕地优先:不假设项目从零开始,默认现有代码库有复杂的"旧管线"
-
工具无关:不依赖特定AI工具,通过AGENTS.md和斜杠命令适配Claude Code、Cursor、Copilot等十余种工具
-
变更分组:将所有相关工件(提案、任务、规范增量)集中在一个文件夹,确保功能级可追溯性
-
可审计差异:归档操作创建清晰的变更历史,满足合规要求
BMAD-METHOD:敏捷AI化的多智能体协作
BMAD-METHOD代表了SDD的第三极------将敏捷方法论引入AI智能体协作,通过分级规划和专业角色模拟人类团队。
核心创新:分级规划模型
BMAD最独特的贡献是Level 0-4分级规划,根据任务复杂度动态调整AI的介入深度:

这种分级模型的精妙之处在于避免"过度规划":修复一个Bug不需要完整的四阶段流程,Level 1快速生成补丁即可;而开发新功能则启动Level 4全套流程,包括合规检查和架构评审。
专业角色体系
BMAD预设了21个专业角色,每个角色都有明确的职责和上下文:
javascript
// BMAD角色定义示例(科研框架)
const researchFramework = require('bmad-research-framework');
// 可用的专业智能体
console.log('可用智能体:', researchFramework.agents);
// 输出:
// - research-strategy-planner (研究策略规划师)
// - literature-research-expert (文献调研专家)
// - grant-application-writer (申请报告撰写师)
// - peer-reviewer-template (同行评议专家)
// - research-lead-template (研究团队组长)
// - 等13个专业智能体在多智能体协作中,Scrum Master智能体负责在不同阶段传递上下文,确保信息不丢失。这种设计模仿了人类敏捷团队中的角色分工。
BMAD科研框架实战
BMAD-METHOD不仅用于软件开发,其科研框架可应用于任意学科领域的AI辅助研究:
javascript
// 在Claude Code中启动科研项目
// 我想开始一个关于"机器学习在医学影像分析中的应用"的研究项目
// @research-strategy-planner 智能体响应
// 系统自动:
// 1. 分析项目需求
// 2. 配置专业智能体团队
// 3. 进行深度文献调研
// 4. 撰写标准化申请报告
// 5. 协调专业团队执行研究
// 6. 生成高质量研究报告典型工作流程覆盖科研全生命周期:
-
规划配置阶段(2-4周):项目战略规划、自动团队配置
-
研究准备阶段(4-8周):深度文献调研、知识库构建、申请报告撰写
-
执行阶段(主要研究周期):专业团队并行工作、实时协调
-
报告阶段(2-4周):结果分析、标准化报告撰写
框架对比与选型指南
| 维度 | GitHub Spec Kit | OpenSpec | BMAD-METHOD |
|---|---|---|---|
| 核心定位 | 绿地项目宪法 | 棕地系统RFC | 多智能体敏捷协作 |
| 适用场景 | 0→1新项目启动 | 1→n现有系统演进 | 复杂系统/科研项目 |
| 规范粒度 | 宪法+规格+计划 | 提案+任务+规范增量 | 分级规划(Level 0-4) |
| 变更管理 | 线性工作流 | 提案→归档(类似分支) | 动态分级响应 |
| 团队模型 | 三个AI代理角色 | 人类审查+AI实施 | 21个专业智能体 |
| 典型用户 | 创业团队/新项目 | 企业遗留系统团队 | 研究机构/复杂产品 |
| 上手复杂度 | 中等 | 低 | 高 |
| 核心价值 | 从第一天建立文档纪律 | 隔离变更风险,可审计演进 | 模拟人类组织架构 |
选型建议:
-
新项目启动:Spec Kit + Tessl(规范即源码),从第一天建立规范纪律
-
存量系统维护:OpenSpec + Crush,利用"变更提案"模式隔离风险,LSP集成准确理解现有代码
-
企业级复杂系统:BMAD-METHOD + OpenHands,多级规划契合企业合规流程,Docker沙盒提供安全隔离
-
快速原型:直接使用AI工具(如Claude Code),尽管代码可能难以长期维护
技术纵深:MCP协议与上下文工程
MCP:AI智能体的"USB标准"
模型上下文协议(Model Context Protocol, MCP)正在成为AI智能体生态的关键基础设施。在MCP之前,每个工具都需要单独编写连接器访问PostgreSQL、Slack或Google Drive。(扩展阅读:9个革命性MCP工具概览:从本地客户端到智能研究助手、MCP Server深度评估报告:效能差异、优化策略与未来演进路径、MCP架构:大模型时代的分布式训练革命、MCP架构:模型上下文协议的革命性创新设计、MCP架构:AI时代的标准化上下文交互协议、A2A vs MCP:智能体通信协议的框架选择与最佳实践、MCP vs Function Calling:重构AI工具交互范式的技术真相、MCP、Function Calling与Agent:构建AI协作生态的三层架构体系、MCP与Skills:AI架构的进化,从连接协议到认知框架的演进、Skills vs MCP:谁才是大模型的"HTTP时刻"?)
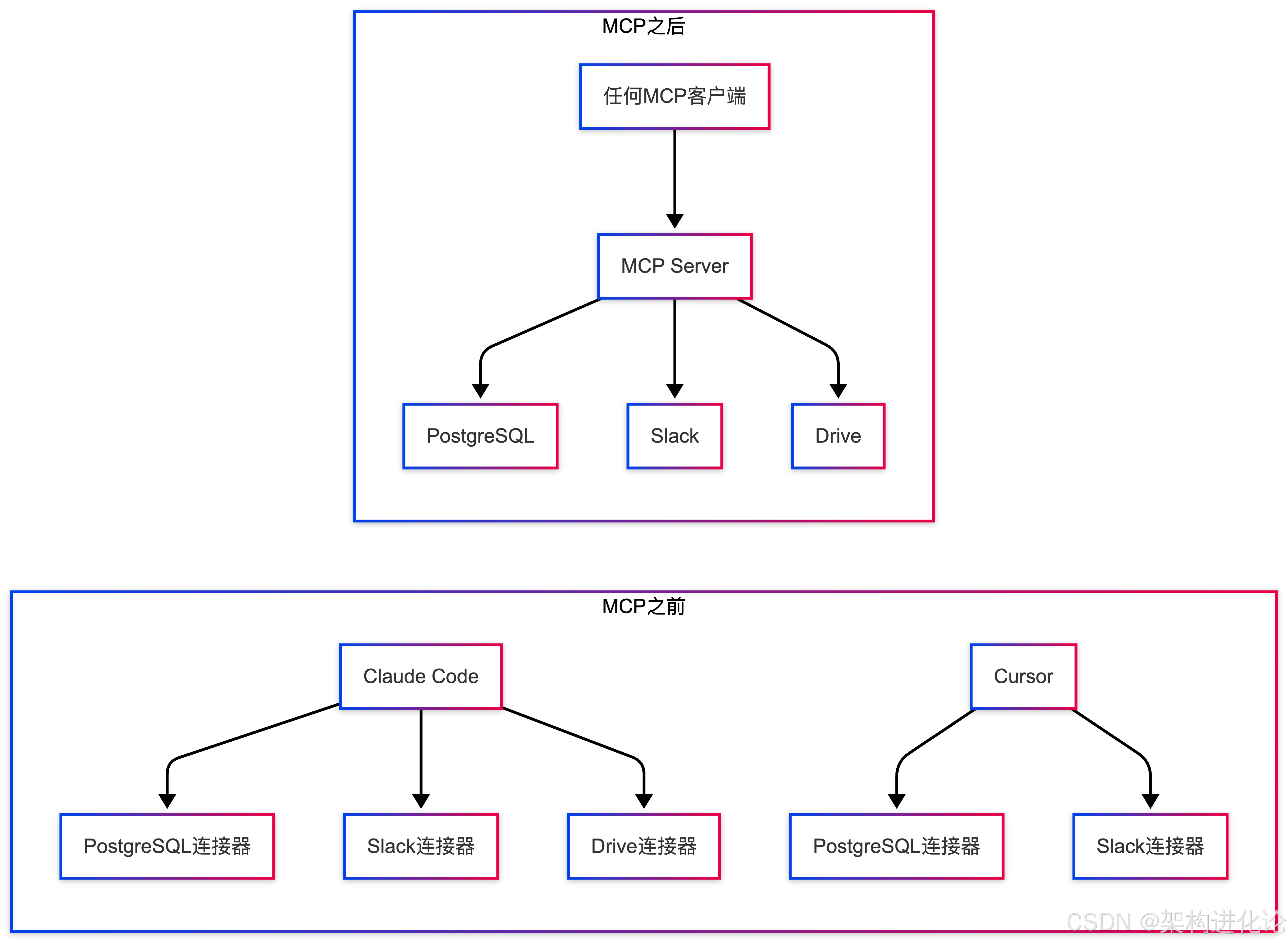
现在,OpenSpec、Kiro、PromptX等工具都采纳了MCP。开发者只需运行一个MCP Server,所有AI工具都能安全、受控地访问特定数据源。这极大地降低了AI与外部系统集成的复杂度。
上下文工程:从文本拼接到语义理解
上下文工程已成为SDD的显学。工具们开始结合多种技术构建高密度"上下文摘要":
-
AST分析:理解代码结构,提取函数、类、依赖关系
-
LSP信息:利用语言服务器协议获取符号定义、引用、类型信息
-
向量检索(RAG):从文档库中检索相关规范片段
这不再是简单的文本拼接,而是对代码语义的深度理解。当AI实施/openspec:apply时,它获得的不仅是规范文件,还有通过上下文工程构建的完整项目心智模型。
范式展望:从"写语法"到"定义意图"
开发者角色的必然分化
开源AI编程工具生态正在经历从"玩具"到"工具"的蜕变。未来,软件工程师的角色将不可避免分化:
AI架构师 - 专注于编写高质量的Spec和Constitution,通过SDD框架指挥AI军团。他们的核心能力是"清晰地定义意图"------将模糊的业务需求转化为机器可执行的规范契约。
工具制造者 - 优化ACI(Agent-Computer Interface)接口和智能体运行时环境。普林斯顿大学的研究揭示:人类使用的Shell对AI效率极低,需要为AI设计专用接口。SWE-agent提出的file_viewer提供带行号的折叠代码视图,极大节省Token上下文。
领域专家 - 提供规范中所需的领域知识,确保生成的代码符合业务逻辑和行业规范。
需求即资产:规范库的复利效应
当规范成为可版本化、可测试、可执行的一等公民,企业可以积累规范资产库:
-
新项目不再从零开始,而是复用已验证的规范模式
-
AI代理能够基于历史规范自动推荐最佳实践
-
通过规范差异分析预测变更影响范围
-
同一套规范可生成多种技术栈的实现,实现"一次定义,多端输出"
摩根大通技术团队的反馈显示,将企业级约束融入规范后,生成代码的合规率从传统开发的65%提升至92%。
架构即契约
SDD不是对瀑布模型的回归,而是对软件工程本质的重新发现。正如一位敏捷实践者担忧的:"SDD是否在倒退回瀑布模型?" 答案是否定的。
瀑布模型的失败在于规划的不可变性 ------试图在编码前完成所有文档,然后线性执行。而SDD的核心是规范的适应性------规范是"活的契约",通过Plan-Execute闭环持续演进。它不是在编码前完成所有思考,而是把最容易在长程任务中出错、最值得被验证和沉淀的部分显式化。
当AI能写出95%的代码,人类的价值在于决定"做什么"和"为什么做"。规范驱动开发不是束缚,而是让AI在正确轨道上狂奔的加速器。在这个新时代,架构不再是咨询性建议,而是可执行的契约。
 这场变革的核心隐喻是:我们正在从"建造者"转变为"立法者"。代码不再是手工打造的建筑,而是遵循宪法的自动产物。当每一行代码都能追溯到一条规范,当每一次变更都留下可审计的轨迹,软件工程终于迎来了它的"法治时代"。
这场变革的核心隐喻是:我们正在从"建造者"转变为"立法者"。代码不再是手工打造的建筑,而是遵循宪法的自动产物。当每一行代码都能追溯到一条规范,当每一次变更都留下可审计的轨迹,软件工程终于迎来了它的"法治时代"。