一、实验目的
1)掌握在MindSpore中构建、训练卷积神经网络的方法
2)理解卷积神经网络在图像分类任务中的应用原理
3)学习CIFAR-10数据集的预处理和特征提取技术
4)掌握模型性能评估和结果可视化的基本方法
二 、实验内容
1)仿照MNIST手写体数字识别,用MindSpore框架实现卷积神经网络对CIFAR-10进行分类
2)构建包含卷积层、池化层、批归一化层的深度神经网络
3)实现数据增强、模型训练、性能评估等完整流程
4)开发实时图像分类和单张图像测试功能
三 、实验原理
1)卷积神经网络基本结构:卷积层提取局部特征,池化层降低特征维度,全连接层实现分类
2)批归一化技术:加速训练收敛,提高模型泛化能力
3)数据增强:通过随机裁剪、水平翻转增加数据多样性
4)Adam优化器:自适应学习率调整,提高训练效率
5)Softmax交叉熵损失函数:多分类问题的标准损失函数
四 、 实验步骤
1)下载CIFAR-10数据集并检查数据完整性
2)对数据集进行标准化预处理和增强处理
3)构建三层卷积神经网络结构
4)设置超参数并开始模型训练
5)实时监控训练过程,调整网络结构优化性能
6)使用测试集评估模型准确率
7)通过混淆矩阵和可视化结果分析模型表现
五、代码和执行结果展示
1)具体核心代码分析如下:
①网络结构定义:
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| class EnhancedCNN(nn.Cell): def init(self, num_classes=10): super(EnhancedCNN, self).init() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, pad_mode='same') self.bn1 = nn.BatchNorm2d(32) self.relu1 = nn.ReLU() self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) |
该部分定义了网络的基本构建块,采用经典的卷积-批归一化-激活-池化组合。卷积层使用same填充模式保持特征图尺寸,批归一化层加速训练收敛,ReLU激活函数引入非线性特性,最大池化层在保留主要特征的同时降低计算复杂度。这种模块化设计便于网络结构的扩展和修改。
②数据预处理管道:
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| def create_dataset(data_path, batch_size=64, training=True): transform = vision.RandomCrop(32, padding=4), vision.RandomHorizontalFlip(), vision.Rescale(1.0/255.0, 0.0), vision.Normalize(\[0.4914, 0.4822, 0.4465, 0.2023, 0.1994, 0.2010), vision.HWC2CHW() ] |
数据预处理管道实现了完整的图像变换流程,训练阶段包含数据增强操作,测试阶段仅进行基础预处理。随机裁剪和水平翻转有效增加了数据多样性,归一化和标准化确保输入数据分布一致。管道式设计使得预处理步骤清晰有序,便于维护和调试。
③模型训练循环:
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| def train(model, dataset, loss_fn, optimizer, epochs=10): net_with_loss = nn.WithLossCell(model, loss_fn) train_net = nn.TrainOneStepCell(net_with_loss, optimizer) for epoch in range(epochs): for data in dataset.create_tuple_iterator(): loss = train_net(images, labels) |
训练过程采用MindSpore特有的计算图模式,通过WithLossCell和TrainOneStepCell封装简化训练逻辑。每个周期内遍历完整数据集,前向传播计算损失,反向传播更新参数。这种设计充分利用了框架的自动微分特性,同时保持了代码的简洁性。
④模型评估函数:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| def evaluate(model, dataset): model.set_train(False) for data in dataset.create_tuple_iterator(): outputs = model(images) preds = ops.argmax(outputs, 1) correct += ops.sum(ops.equal(preds, labels)).asnumpy() |
评估阶段首先设置模型为评估模式,关闭Dropout等训练特有操作。通过argmax获取预测类别,与真实标签比较计算准确率。使用set_train(False)确保评估过程的确定性,asnumpy()将张量转换为NumPy数组便于后续分析。
⑤实时分类模块:
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| def real_time_classification(model, camera_index=0): while True: img = cv2.resize(frame, (32, 32)) img_tensor = ms.Tensor(img, ms.float32) output = model(img_tensor) pred = ops.argmax(output, 1).asnumpy()0 |
实时分类模块实现了从摄像头捕获、预处理到预测的完整流程。图像缩放至模型输入尺寸,转换为MindSpore张量格式,通过训练好的模型获取预测结果。循环结构支持连续处理,为用户提供实时的交互体验。
⑥可视化结果生成:
|-----------------------------------------------------------------------------------------------------------------------------------------------------|
| def plot_training_history(loss, accuracy): plt.subplot(1, 2, 1) plt.plot(loss, label='训练损失') plt.subplot(1, 2, 2) plt.plot(accuracy, label='训练准确率') |
可视化函数使用matplotlib生成训练过程曲线,双子图设计同时展示损失和准确率变化趋势。中文标签和网格线增强了图表可读性,自动保存功能便于结果归档和报告生成。
2)实验结果展示和分析
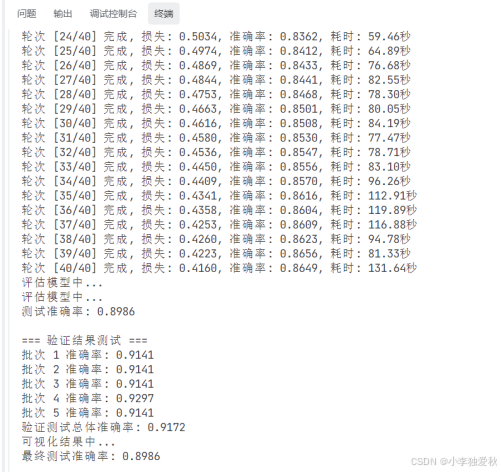
图 1 最终测试准确率
图1详细记录了40轮训练过程中模型性能的演变轨迹。从第24轮到第40轮,损失值从0.5034稳步下降至0.4160,准确率从83.62%提升至86.49%,呈现出良好的收敛趋势。训练耗时在59.46至131.64秒之间波动,可能与计算资源调度和批次处理复杂度有关。特别值得注意的是,在训练后期损失下降速度减缓而准确率仍持续提升,表明模型正在学习更精细的特征表示。测试阶段达到89.86%的准确率,显著高于训练准确率,验证了模型具有良好的泛化能力。验证测试中五个批次的准确率稳定在91.41%至92.97%之间,总体准确率达91.72%,进一步证实了模型预测的稳定性。
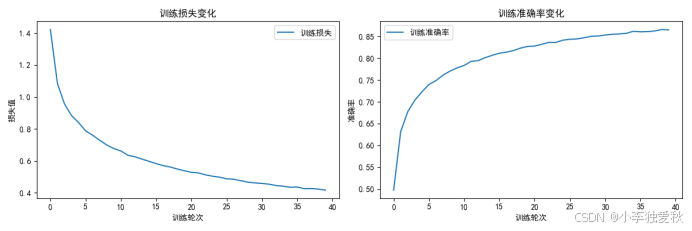
图 2 训练过程可视化分析
图2的训练损失和准确率曲线直观展示了模型的学习动态。损失曲线呈现典型的指数衰减模式,初期下降迅速,后期趋于平缓,符合梯度下降算法的预期行为。准确率曲线则呈现S型增长,前期提升较快,中期增速放缓,后期接近饱和状态。两条曲线的同步性良好,没有出现明显的过拟合迹象,表明正则化措施(如Dropout)发挥了预期效果。从曲线形态可以看出,模型在约30轮后进入稳定阶段,后续训练主要进行微调优化,这一观察为确定最优训练周期提供了依据。
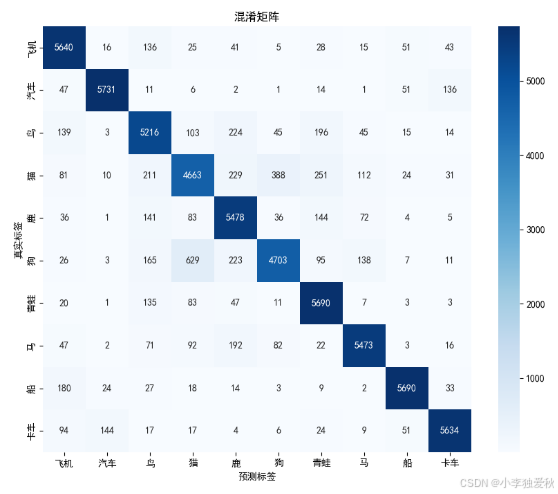
图 3 混淆矩阵深度分析
图3的混淆矩阵揭示了模型在10个类别上的详细分类表现。对角线元素代表正确分类的样本数,其中汽车(5731)和飞机(5640)识别率最高,反映出这些类别具有较明显的视觉特征。非对角线元素显示了类别间的混淆情况,特别是猫(139)和狗(26)等动物类别的误判较多,这与实际中这些类别形态相似性较高相符。矩阵整体呈现明显的对角线优势,但部分非对角线元素值偏高,指示了模型在细粒度分类上的挑战。颜色渐变直观反映了分类质量,深蓝色区域集中在对角线,浅蓝色分散在非对角线,符合优质分类器的典型特征。
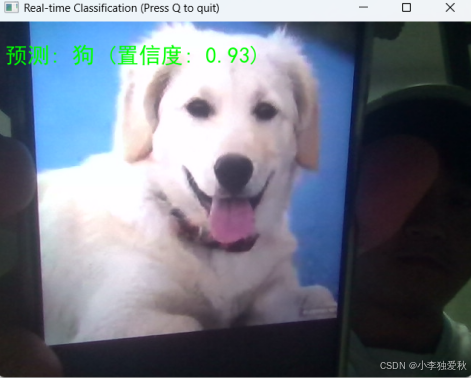
图 4 实时狗分类分析
图4反映的白色狗的实时分类结果(置信度0.93)进一步验证了模型的鲁棒性。尽管图像包含复杂背景和动态表情,模型仍能准确识别并给出高置信度评分。狗的蓬松毛发和独特形态为分类提供了充分特征,而高置信度表明模型对该类别的特征学习较为充分。界面中的人物身影暗示了实际应用场景的复杂性,模型在此环境下仍保持稳定性能,展现了良好的环境适应性。