一、SQL 语句的执行过程
-
应用程序在与PostgreSQL服务器创建连接后,将sql查询语句发送 到PostgreSQL服务器。PostgreSQL服务器接收到sql查询语句后,会进行以下操作:
-
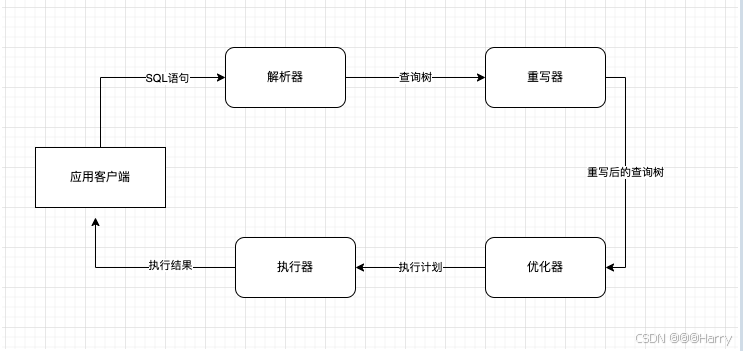
- 1)解析器对sql语句进行语法检查和语义检查,并生成查询树,然后把查询树作为输入参数传给重写器。
- 2)重写器在根据存储在系统表中的规则修改查询树。先把视图重写为对应的基础表,然后把重写后的查询树交给优化器。
- 3)优化器根据查询树产生执行计划,然后交给执行器。
- 4)执行器执行查询计划树并返回查询结果。
- 优化器的分类
- SPJ优化
- 基于选择(select)、投影(PROJECT)、连接(JOIN)3种基本操作的查询优化。
- 非SPJ优化
- 在SPJ基础上,对分组、集合、排序等操作的查询优化。
- SPJ优化
- 优化器的分类
-
二、查询树
-
概念
- 查询优化的对象是查询树。它是一个SQL语句的内部表现形式,组成该语句的每个对立部分都是分别存储的。需要在服务端做一些配置
三、逻辑优化
-
概念
- 逻辑优化的基本理论来源于关系代数。PostgreSQL数据库属于关系性数据库,关系型数据库查询语言的基础就是关系代数,因此,对查询语言的优化就可以通过使用关系代数的运算来进行。
-
逻辑优化的顺序
-
对子查询的优化
-
对子查询的优化分为两个步骤
-
对子查询进行上体尽可能的把子查询提到父查询同一及,这样减少查询的层次,减少嵌套查询,使得查询节点尽可能的在叶子结点完成选择操作。
sql--1带子查询的 explain select * from test.demo where id not in (select demo_id from test.demo_item); --1的查询计划 Seq Scan on demo (cost=18.12..18.12 rows=1 width=64) Filter: (NOT (ANY ((id)::text = ((hashed SubPlan 1).col1)::text))) SubPlan 1 -> Seq Scan on demo_item (cost=0.00..16.50 rows=650 width=32) --2 不带子查询的 explain select * from test.demo a inner join test.demo_item b on a.id =b.demo_id; --2的查询计划 Hash Join (cost=0.01..18.98 rows=3 width=160) Hash Cond: ((b.demo_id)::text = (a.id)::text) -> Seq Scan on demo_item b (cost=0.00..16.50 rows=650 width=96) -> Hash (cost=0.00..0.00 rows=1 width=64) -> Seq Scan on demo a (cost=0.00..0.00 rows=1 width=64)- 很明显【2 不带子查询】没有subplan,这表示b表查询语句不是作为子查询执行的,而是与a表进行了连接操作,就是把b表父查询的同一层,把两者进行了连接。
- 以上两个查询,分别使用了not in 与inner join,查询计划完全不同,代价也是相差很远。
-
把选择出来的少量结果进行表间的连接操作,从而将表连接的操作数量降到最低,提高查询性能。
-
-
-
对where、having、on等条件表达优化及等价谓词重写
-
基于关系代数中的并、交、差等运算规则,用户可以对查询树的条件表达式进行优化。
-
谓词的优化
--查询中如果使用的between and select * from a where a.create_date between '2026-01-01' and '2026-01-02'; --优化为 select * from a where a.create_date >= '2026-01-01' and a.create_date<= '2026-01-02';
-
-
-
对外链接进行优化
- 外连接包括左外链接、右外链接、全外连接等多种连接方式。把外连接转换为内链接,可以使表的连接顺序更随意,提高查询效率。
-