📖标题:Probing RLVR training instability through the lens of objective-level hacking
🌐来源:arXiv, 2602.01103v1
🌟摘要
具有可验证奖励的长时间强化学习(RLVR)已被证明可以推动大型语言模型推理能力的持续改进,但训练往往容易出现不稳定性,尤其是在混合专家(MoE)架构中。训练不稳定性严重破坏了模型能力的改进,但其潜在原因和机制仍然知之甚少。在这项工作中,我们引入了一个原则性框架,用于通过客观级别黑客的镜头来理解RLVR不稳定性。与奖励黑客不同,奖励黑客来自可利用的验证者,客观级黑客来自令牌级信用错位,并在优化目标中表现为系统级的虚假信号。基于我们的框架,加上对30BMoE模型的广泛实验,我们追溯了MoE模型中关键病理训练动态背后的起源并形式化了机制:训练推理差异的异常增长,这一现象广泛与不稳定性相关,但以前缺乏机械解释。这些发现为MoE模型中不稳定性背后的训练动态提供了具体和因果解释,为设计稳定的RLVR算法提供了指导。
🛎️文章简介
🔸研究问题:为什么MoE架构下的强化学习可验证奖励(RLVR)训练会持续出现不稳定性,尤其是训练-推理差异异常扩大这一关键病理现象?
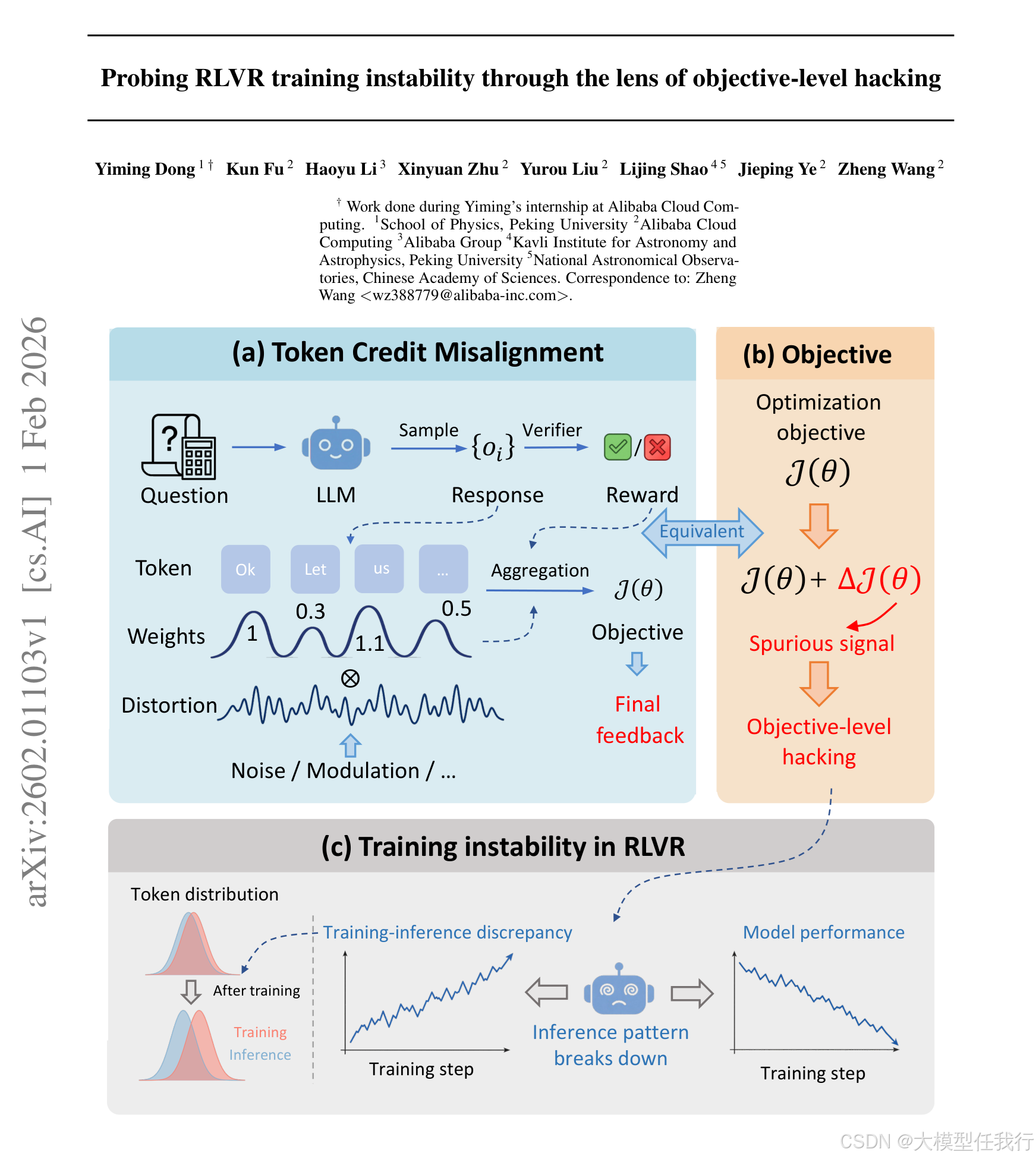
🔸主要贡献:论文提出目标层劫持理论框架,揭示了token级信用错配如何通过优化目标中的系统级伪影信号导致MoE模型训练不稳定性。
📝重点思路
🔸构建目标层劫持理论框架,类比奖励黑客攻击,指出其源于token级信用分配失准(如训练与推理策略分布不一致),而非 verifier 设计缺陷。
🔸推导出训练-推理差异会引入优化目标的隐式偏差项ΔJ(θ)≈∑Cov(Xi,t, ρ⁻¹i,t),该偏差等效于对目标函数施加有偏扰动,驱动模型向放大差异的方向优化。
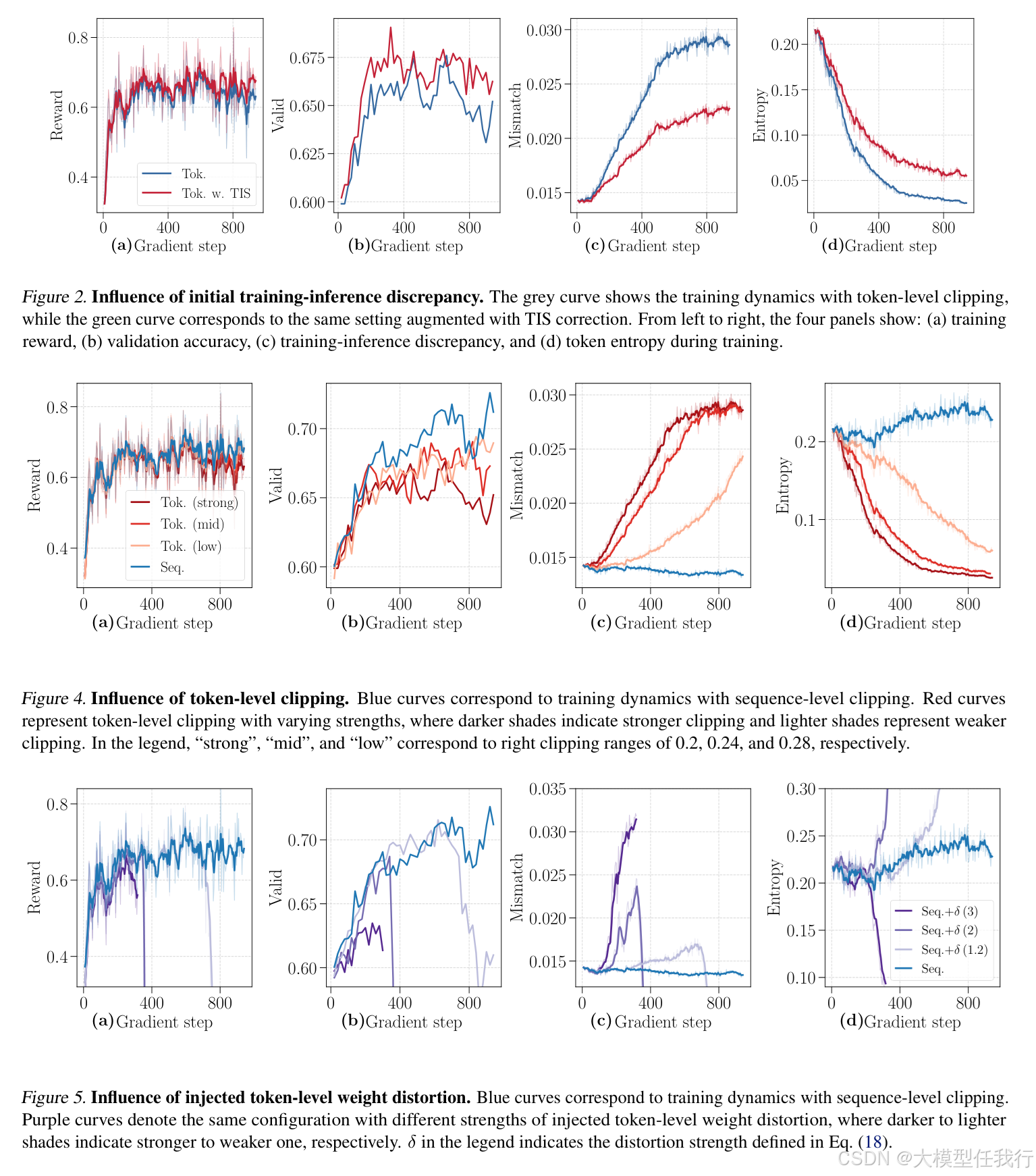
🔸识别多种目标层黑客攻击来源:初始训练-推理差异、token级裁剪、主动注入的token权重扭曲,统一建模为Jdist(θ)=J(θ)+ΔdistJ(θ)。
🔸设计三组受控实验:TIS校正目标偏差、调节token裁剪强度、显式注入高低概率token权重扭曲,验证不同形式ΔdistJ(θ)与差异增长的统计相关性。
🔸引入token级重要性权重ρi,t的标准差作为细粒度差异指标,并通过PCC、最大ρi,t、熵等多维指标刻画推理模式崩溃过程。
🔎分析总结
🔸TIS校正显著减缓训练-推理差异增长及token熵衰减,证明目标函数偏差是差异扩大的主因,而非单纯基础设施不一致。
🔸更强的token级裁剪反而加速差异增长,而序列级裁剪无此现象,说明token粒度的信用重分配具有双刃剑效应。
🔸仅20%提升低概率token权重即可触发差异异常增长,且降低权重同样有效,证实核心机制是"权重扭曲"本身而非方向。
🔸注入无偏方差噪声(高斯扰动)不引发差异增长,证明偏差(bias)而非方差(variance)是驱动因素。
🔸低概率token的ρi,t持续下降,形成"生存偏差→权重扭曲加剧→差异扩大"的正反馈闭环,解释训练崩溃不可逆性。
💡个人观点
论文跳出传统奖励黑客视角,将训练不稳定性归因于优化目标中由token级信用错配诱发的隐式、累积性虚假信号。
🧩附录