文章目录
- Pre
- 手写Manus之消息相关性过滤:用LLM管理Agent的上下文记忆
- 引言
- 一、设计接口
- 二、改造Memory
- 三、改造Agent调用链
- 四、LLMRelevanceFilter核心实现
-
- [4.1 过滤逻辑](#4.1 过滤逻辑)
- [4.2 基于LLM的相关性评分](#4.2 基于LLM的相关性评分)
- [4.3 评分提示词设计](#4.3 评分提示词设计)
- [4.4 健壮的评分解析](#4.4 健壮的评分解析)
- 五、启用相关性过滤
- 六、过滤效果示意
- 七、权衡与思考
- 总结
Pre
大模型开发 - 用纯Java手写一个多功能AI Agent:01 从零实现类Manus智能体
大模型开发 - 手写Manus之基础架构:02 用纯Java从零搭建AI Agent骨架
大模型开发 - 手写Manus之Sandbox执行代码:03 用Docker为AI Agent打造安全沙箱
大模型开发 - 手写Manus之Tavily搜索工具:04 让AI Agent接入互联网
大模型开发 - 手写Manus之浏览器操作工具:05 基于Playwright实现网页自动化与多模态交互
手写Manus之消息相关性过滤:用LLM管理Agent的上下文记忆
引言
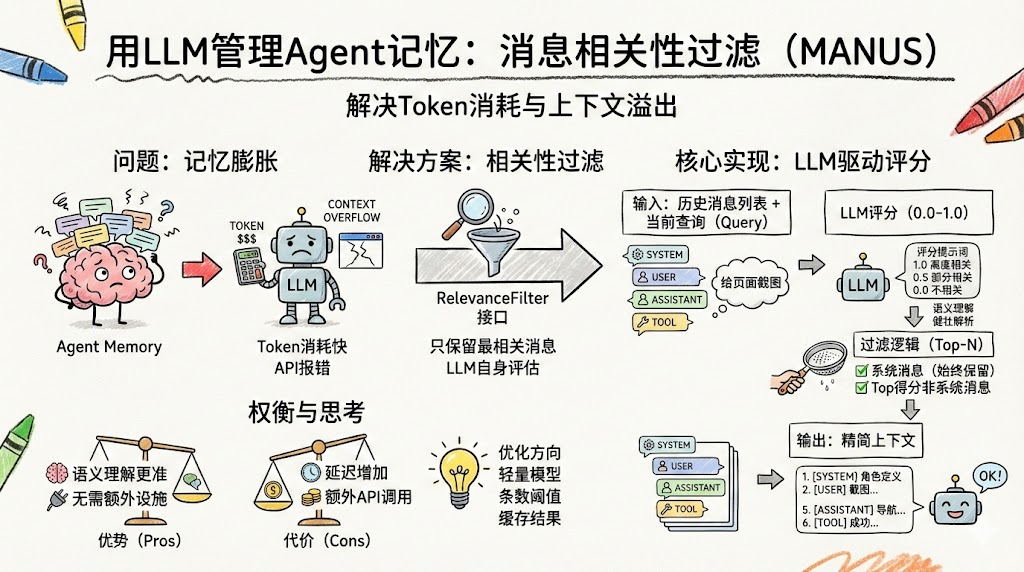
随着Agent执行步骤增多,Memory中的消息会不断累积------系统提示词、用户输入、每次大模型的推理回复、每次工具调用请求、每次工具执行结果......几个复杂任务下来,消息列表可能膨胀到数十条甚至上百条。
这带来两个问题:
- Token消耗:每次调用LLM都会传入所有历史消息,Token消耗快速增长
- 上下文窗口溢出:当消息总量超过模型的上下文窗口限制,API会直接报错
解决方案是:不是所有历史消息都与当前步骤相关,应该只保留最相关的消息。
传统方案通常使用"滑动窗口"(保留最近N条消息)或基于向量的语义相似度。本文采用一个更创新的方法------用LLM自身来评估每条消息与当前查询的相关性,按得分高低保留Top-N。
一、设计接口
首先定义RelevanceFilter接口,作为可插拔的过滤策略:
java
public interface RelevanceFilter {
// 从消息列表中过滤出最相关的maxMessages条
List<Message> filter(List<Message> messages, String currentQuery, int maxMessages);
// 计算单条消息与查询的相关性得分(0.0-1.0)
double calculateRelevance(Message message, String currentQuery);
}接口注释中提到了三种可能的实现方式:
java
// 关键字匹配:简单但不够精确
// 语义相似度:向量模型,需要额外的Embedding服务
// 大语言模型:最智能,但成本最高本文实现第三种------基于LLM的方式。
二、改造Memory
在Memory中集成相关性过滤器:
java
@Data
public class Memory {
private List<Message> messages;
private RelevanceFilter relevanceFilter;
public Memory() {
this.messages = new ArrayList<>();
}
public void addMessage(Message message) {
messages.add(message);
}
// 新增:带过滤的消息获取
public List<Message> getMessages(String currentQuery) {
if (relevanceFilter != null) {
return relevanceFilter.filter(messages, currentQuery, 5); // 最多保留5条
}
return messages;
}
}三、改造Agent调用链
BaseAgent的step()方法签名变化------传入当前查询以支持过滤:
java
// Before
protected abstract StepResult step();
// After
protected abstract StepResult step(String currentQuery);ToolCallAgent中使用新的API:
java
@Override
protected StepResult step(String currentQuery) {
// 带相关性过滤的消息获取
List<Message> contextMessages = memory.getMessages(currentQuery);
List<ToolDefinition> toolDefinitions = toolCollection.getToolDefinitions();
ModelResponse modelResponse = openAIClient.chat(contextMessages, toolDefinitions);
// ...
}四、LLMRelevanceFilter核心实现
4.1 过滤逻辑
java
@Slf4j
public class LLMRelevanceFilter implements RelevanceFilter {
private final OpenAIClient openAIClient;
@Override
public List<Message> filter(List<Message> messages, String currentQuery, int maxMessages) {
if (messages == null || messages.isEmpty()) {
return new ArrayList<>();
}
// 消息数量不超过限制,直接返回
if (messages.size() <= maxMessages) {
return new ArrayList<>(messages);
}
// 系统消息始终保留!
List<Message> systemMessages = messages.stream()
.filter(msg -> msg.getRole() == Role.SYSTEM)
.toList();
List<Message> nonSystemMessages = messages.stream()
.filter(msg -> msg.getRole() != Role.SYSTEM)
.toList();
// 为每条非系统消息计算相关性得分
List<MessageScore> scoredMessages = nonSystemMessages.stream()
.map(msg -> new MessageScore(msg, calculateRelevance(msg, currentQuery)))
.sorted((a, b) -> Double.compare(b.score, a.score))
.toList();
// 组合:系统消息 + 得分最高的N条非系统消息
List<Message> result = new ArrayList<>(systemMessages);
int remainingSlots = maxMessages - systemMessages.size();
if (remainingSlots > 0) {
result.addAll(scoredMessages.stream()
.limit(remainingSlots)
.map(ms -> ms.message)
.toList());
}
log.debug("过滤前消息数量: {}, 过滤后消息数量: {}", messages.size(), result.size());
return result;
}
}关键设计:系统消息(System Prompt)始终保留------它定义了Agent的角色和行为规则,任何时候都不能丢弃。
4.2 基于LLM的相关性评分
对每条消息调用LLM进行语义相关性评估:
java
@Override
public double calculateRelevance(Message message, String query) {
if (message == null || message.getContent() == null || query == null) {
return 0.0;
}
try {
String relevancePrompt = buildRelevancePrompt(message.getContent(), query);
List<Message> promptMessages = Arrays.asList(
Message.systemMessage("你是一个专业的语义相关性评估专家。"
+ "请严格按照要求评估消息的相关性,只返回数字评分。"),
Message.userMessage(relevancePrompt)
);
ModelResponse response = openAIClient.chat(promptMessages);
String content = response.getContent();
if (content != null) {
double relevance = parseRelevanceScore(content);
return Math.max(0.0, Math.min(1.0, relevance)); // 限制在[0,1]范围
}
} catch (Exception e) {
log.warn("LLM相关性评估失败,使用默认评分", e);
}
return 0.0;
}4.3 评分提示词设计
提示词提供了明确的评分标准,引导LLM返回准确的数值:
java
private String buildRelevancePrompt(String messageContent, String query) {
return String.format(
"请评估以下消息内容与查询的相关性,返回0.0到1.0之间的数字评分:\n\n" +
"查询:%s\n\n" +
"消息内容:%s\n\n" +
"评估标准:\n" +
"1.0 - 高度相关:消息直接回答查询或包含查询的核心信息\n" +
"0.7-0.9 - 相关:消息与查询主题相关,包含有用信息\n" +
"0.4-0.6 - 部分相关:消息与查询有一定关联,但不是核心相关\n" +
"0.1-0.3 - 微弱相关:消息与查询只有很少关联\n" +
"0.0 - 不相关:消息与查询完全无关\n\n" +
"请只返回数字评分,不要包含其他文字说明:",
query, messageContent
);
}4.4 健壮的评分解析
LLM不一定总是返回纯数字,我们需要健壮的解析逻辑:
java
private double parseRelevanceScore(String content) {
if (content == null || content.trim().isEmpty()) {
return 0.0;
}
String trimmed = content.trim();
// 优先尝试直接解析数字
try {
String numberStr = trimmed.replaceAll("[^0-9.].*", "");
if (!numberStr.isEmpty()) {
double score = Double.parseDouble(numberStr);
return Math.max(0.0, Math.min(1.0, score));
}
} catch (NumberFormatException e) {
log.warn("无法解析LLM返回的相关性得分: {}", content);
}
// 回退方案:从文本关键词推断
String lowerContent = content.toLowerCase();
if (lowerContent.contains("高度相关") || lowerContent.contains("very relevant")) {
return 0.9;
} else if (lowerContent.contains("相关") || lowerContent.contains("relevant")) {
return 0.7;
} else if (lowerContent.contains("部分") || lowerContent.contains("partial")) {
return 0.5;
} else if (lowerContent.contains("微弱") || lowerContent.contains("weak")) {
return 0.2;
} else if (lowerContent.contains("不相关") || lowerContent.contains("not relevant")) {
return 0.0;
}
return 0.0;
}两层解析策略:
- 先尝试提取数字(理想情况:LLM直接返回"0.8")
- 失败则通过关键词推断(退化情况:LLM返回"这条消息高度相关")
五、启用相关性过滤
在ManusAgent中添加设置方法,并在入口处启用:
java
// ManusAgent
public void setRelevanceFilter(RelevanceFilter relevanceFilter) {
memory.setRelevanceFilter(relevanceFilter);
}
// ManusApplication
ManusAgent manusAgent = new ManusAgent(openAIClient);
manusAgent.setRelevanceFilter(new LLMRelevanceFilter(openAIClient));六、过滤效果示意
假设Memory中有12条消息,当前查询是"给打开的页面截图":
java
消息1 [SYSTEM] 角色定义... → 系统消息,始终保留
消息2 [USER] 创建HTML并截图... → 相关性: 0.8
消息3 [ASSISTANT] 调用write_file → 相关性: 0.3
消息4 [TOOL] 文件写入成功 → 相关性: 0.2
消息5 [ASSISTANT] 调用browser.navigate → 相关性: 0.7
消息6 [TOOL] 导航成功 → 相关性: 0.6
消息7 [ASSISTANT] 调用sandbox.execute → 相关性: 0.1 ← 被过滤
消息8 [TOOL] Python执行结果 → 相关性: 0.1 ← 被过滤
消息9 [ASSISTANT] 调用tavily_search → 相关性: 0.1 ← 被过滤
消息10 [TOOL] 搜索结果 → 相关性: 0.1 ← 被过滤
...
过滤结果(maxMessages=5):
消息1 [SYSTEM] - 始终保留
消息2 [USER] - 得分 0.8
消息5 [ASSISTANT] - 得分 0.7
消息6 [TOOL] - 得分 0.6
消息3 [ASSISTANT] - 得分 0.3与截图无关的代码执行、搜索等消息被过滤掉,LLM只看到最相关的上下文。
七、权衡与思考
优势
- 语义理解:LLM能理解消息的深层含义,比关键词匹配或简单的向量相似度更准确
- 零额外基础设施:不需要向量数据库或Embedding模型
代价
- 额外API调用:每条消息需要一次LLM调用来评分,N条消息就是N次调用
- 延迟增加:评分过程增加了每个step的响应时间
优化方向
- 可以使用更轻量的模型(如qwen-turbo)来做评分
- 可以设置消息条数阈值,消息不多时跳过过滤
- 可以缓存评分结果,避免重复计算
总结
消息相关性过滤解决了Agent长期运行中的上下文管理问题。通过LLM驱动的语义评估,Agent可以在每一步只关注与当前任务最相关的历史信息,既节省了Token消耗,又提高了决策质量。
核心设计原则:
- 系统消息永不过滤------角色定义和行为规则是Agent的"灵魂"
- 按相关性排序保留Top-N------最相关的信息优先保留
- 健壮的评分解析------双层策略应对LLM不确定的输出格式
